Your curated collection of saved posts and media
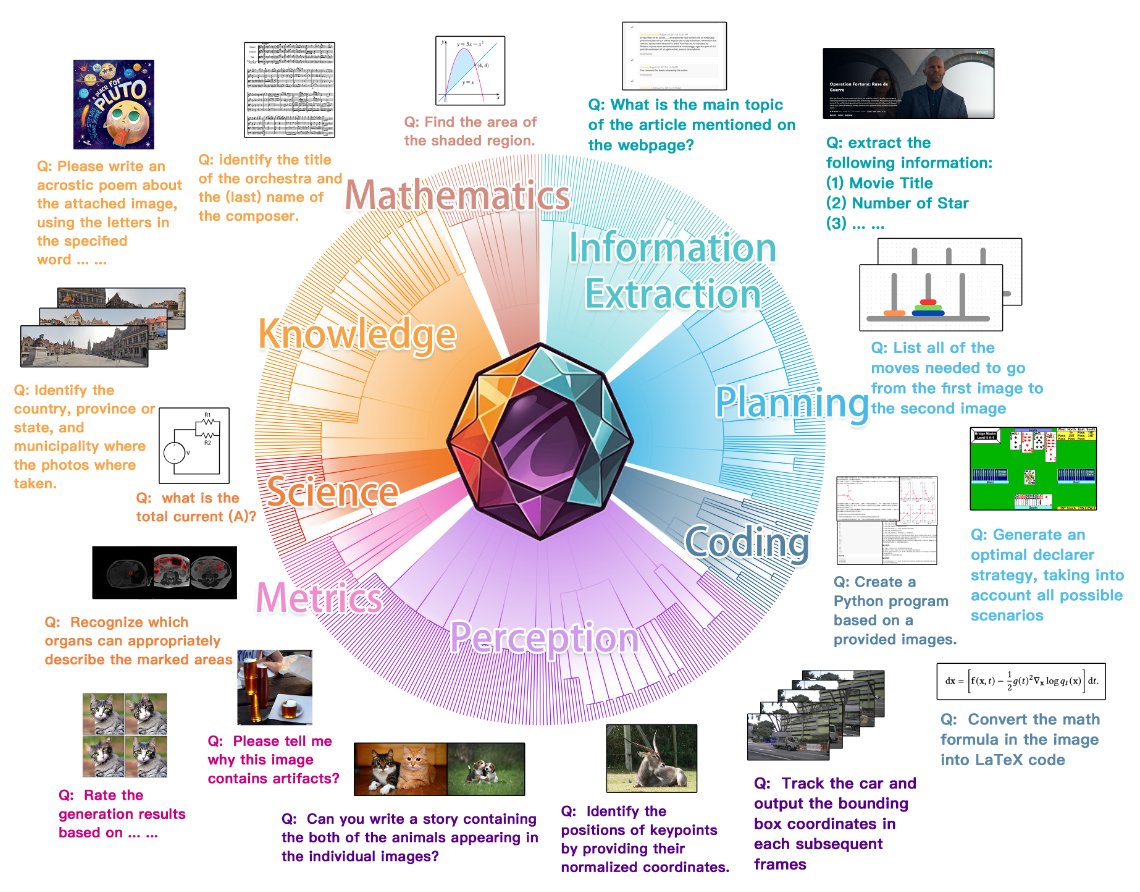
MEGA-Bench: Scaling Multimodal Evaluation to over 500 Real-World Tasks 505 realistic tasks encompassing over 8,000 samples from 16 expert annotators to extensively cover the multimodal task space proj: https://t.co/CutntVTG8E abs: https://t.co/P02o6RyUb8 https://t.co/4Pv1amshOz
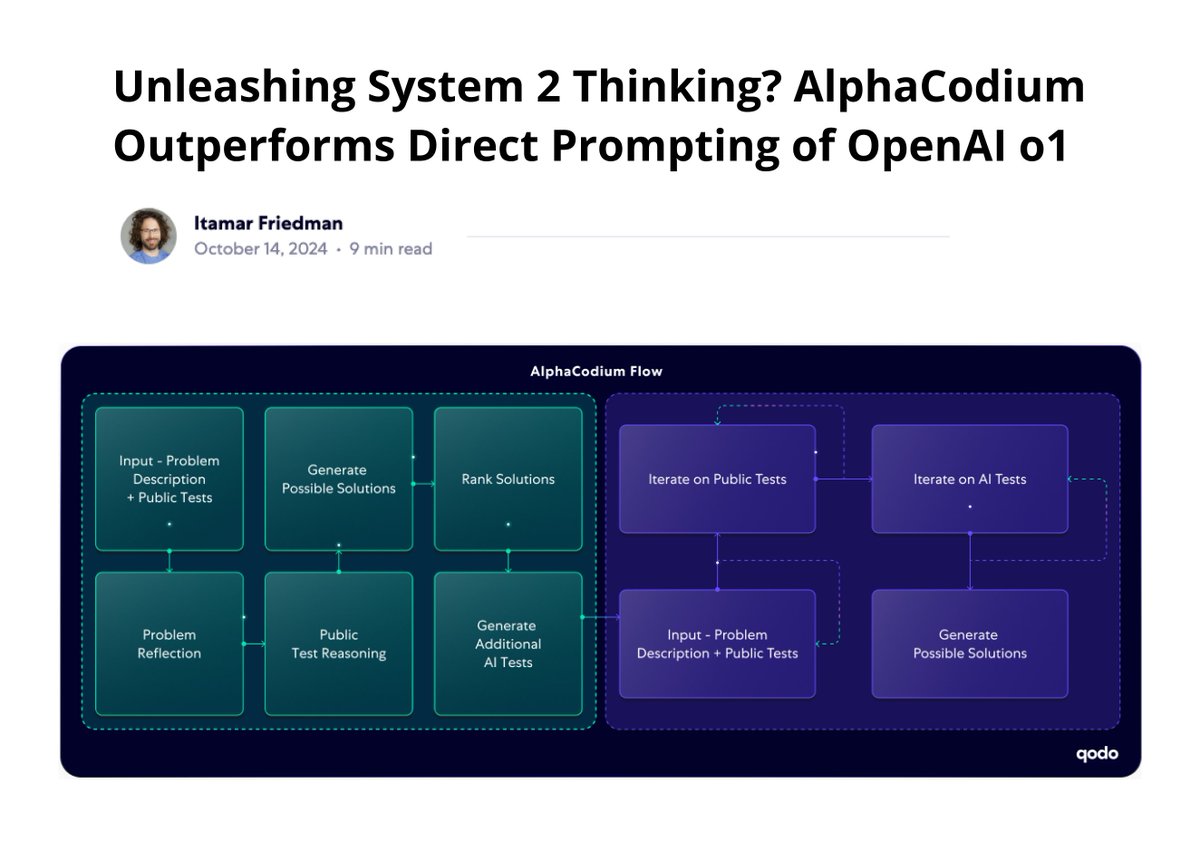
This is the first report I've seen where out-of-the-box o1 CoT reasoning is significantly outperformed on code generation. They propose AlphaCodium which acts as a strategy provider (i.e., flow engineering) on top of o1 to fuel and guide o1's chain-of-thought capabilities. AlphaCodium is built as a multi-stage flow improving on reasoning and reliability, while significantly elevating o1-preview's performance (55% --> 78% pass@5 accuracy on the Codeforces benchmark). Author's quote: "The promise of AlphaCodium is clear: with the right strategic flow-engineering, foundational models like o1 can be nudged toward System II thinking. We still have work to do to cross the gap from “System 1.5” to a true System 2-level AI, but when observing tools like AlphaCodium, we can better understand the gap and keep researching to get closer." o1 is a significantly better model than most LLMs out there today. However, it can benefit from strategic guidance as shown in this report. I am also working on a similar approach for knowledge-intensive tasks. From my own analysis, it does feel like o1 has better knowledge of complex tasks but still shows limitations to complex knowledge understanding and reasoning. More on this soon.
I made a library to detect tables and extract to markdown or csv. It uses a new table recognition model I trained. https://t.co/K5xGsFLDkV
My new app is out !! ✨The Common Crawl Pipeline Creator ✨ Create your pipeline easily: ✔Run Text Extraction✂️ ✔Define Language Filters🌐 ✔Customize text quality💯 ✔See Live Results👀 ✔Get Python code 🐍 Based on famous LLM research like Gopher, C4 or FineWeb https://t.co/kEjphJ8Y3x
Multi-agent system for RFP Response Generation 🔥✍️ We’re excited to release a brand-new guide showing you how to build an agentic workflow that can take in an input Request for Proposal (RFP) template and generate a full response to the RFP, grounded in your knowledge base and adhering to the relevant guidelines. This is much more than a standard RAG or ReAct agent architecture, and requires the careful orchestration of a set of steps + components. 1. Parse the input RFP template using LlamaParse, extract out a set of questions that you would need answered. 2. For each question, use a Research agent (ReAct loop) with access to a set of tools in the knowledge base to retrieve relevant information and generate an answer 3. Aggregate question/answer pairs into a single file 4. Generate the final report with the RFP template and QA pairs as input. Bonuses 💫: it’s fully async, and you get back event and final response streaming! Notebook: https://t.co/5XCkFeUQen LlamaParse signup: https://t.co/yQGTiRSNvj

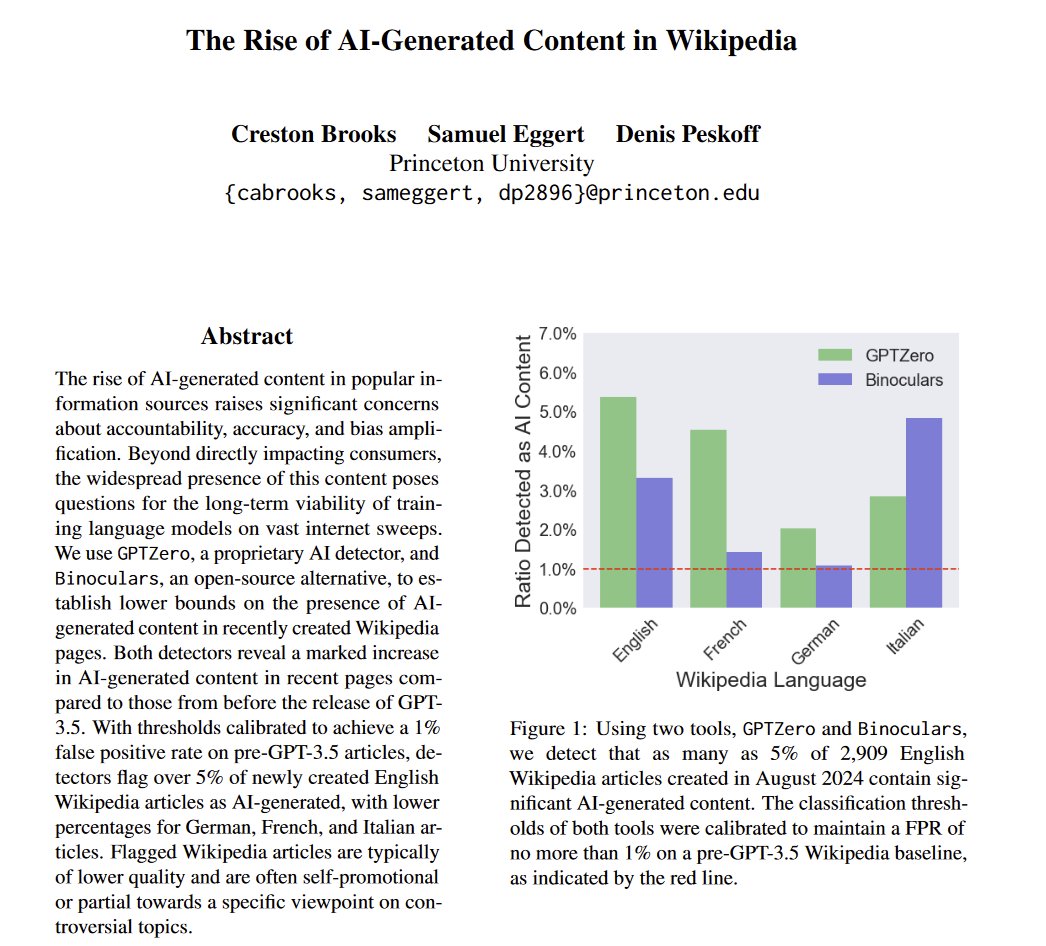
The ourouborous has begun. Wikipedia is an important source of training data for AIs. At least 5% of new Wikipedia articles in August were AI generated (To be clear, this does not mean that AI will fail as it trains on its own data, synthetic data is already a part of training) https://t.co/kuDkfEgJQv
lmfao https://t.co/EELDsKS6zX
Based on everything you know about me, if I was going to write best selling book, what would it be about? https://t.co/YkBeyJTvVP

For AI to perform better, move beyond surface-level fixes. Junior employees address AI accuracy by changing human routines; experts focus on humans, system design, data, and models. I added my methods below. Paper from @HarvardHBS @Wharton @emollick: https://t.co/5UpUQ4pwaR

I made a multi-agent workflow that should be a decent initial reference for anyone building report generation + form filling use cases! Step 1: Index a knowledge base, creating tools/RAG endpoints to query this KB Step 2: Input a template (in this case it's an RFP) Step 3: Parse out the template into a set of k:v pairs that you need to fill out Step 4: Fill out k:v pairs by having a research agent query the knowledge base repeatedly Step 5: Generate the final report! Long context LLMs are great for this. Also because this is a long-running process, certain features like streaming + human-in-the-loop become super useful. Cookbook: https://t.co/CFYq8PlMe6 A secret weapon to any agentic document workflow is of course llamaparse: https://t.co/XYZmx5TFz8
Multi-agent system for RFP Response Generation 🔥✍️ We’re excited to release a brand-new guide showing you how to build an agentic workflow that can take in an input Request for Proposal (RFP) template and generate a full response to the RFP, grounded in your knowledge base and a

If you want to build an async-first multi-agent system, check out this fantastic tutorial by @jamescalam on @llama_index workflows! Build a full research agent system by passing messages between an LLM reasoning module + web/RAG tools. The nice part about our workflows is you can write literally whatever you want in the steps, but take advantage of our async, event-driven orchestration. Video: https://t.co/0i9avz3daY Notebook: https://t.co/MSOmhxwWtK To learn more check out our workflows guide: https://t.co/tNolgSm48v
Check out this comprehensive tutorial of LlamaIndex Workflows from @jamescalam! It covers: ➡️ What Workflows are, comparing them to LangGraph ➡️ Full guide to getting up and running ➡️ How to build an AI research agent using Workflows ➡️ Debugging and optimization tips https://
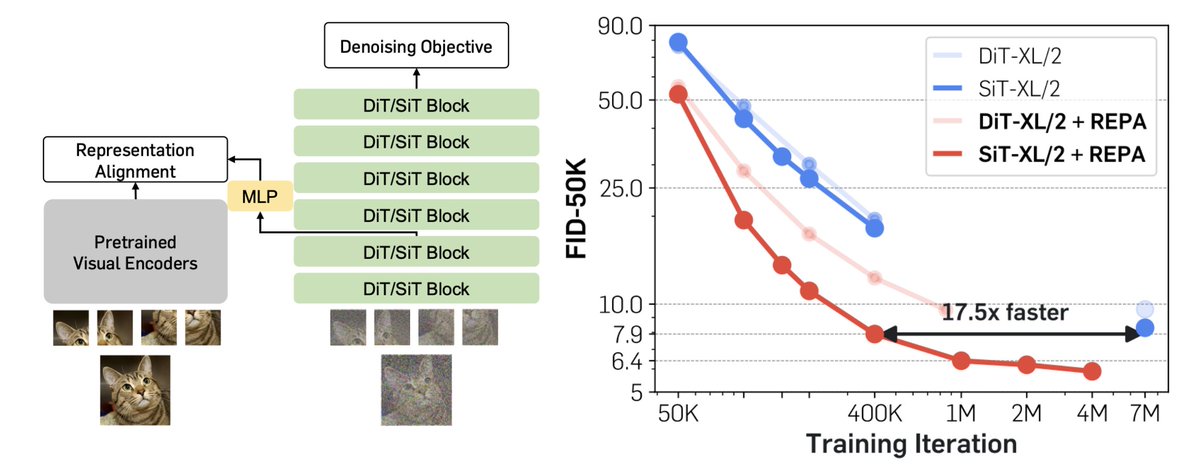
Representation matters. Representation matters. Representation matters, even for generative models. We might've been training our diffusion models the wrong way this whole time. Meet REPA: Training Diffusion Transformers is easier than you think! https://t.co/lyWwiTYjEt(🧵1/n)
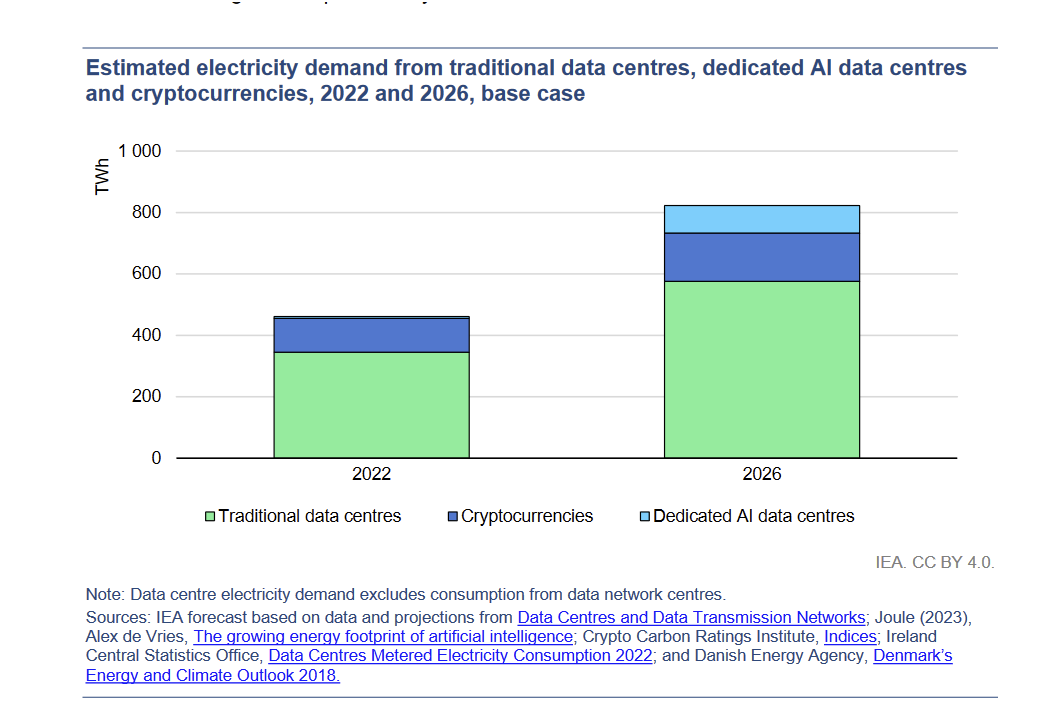
I think it is completely reasonable to be worried about the growing electrical demand of AI (I am), but I often see people assuming AI is a much bigger energy user than it actually is right now This is from the International Energy Agency's 2024 report, which gives some context https://t.co/NgQzCckGIe
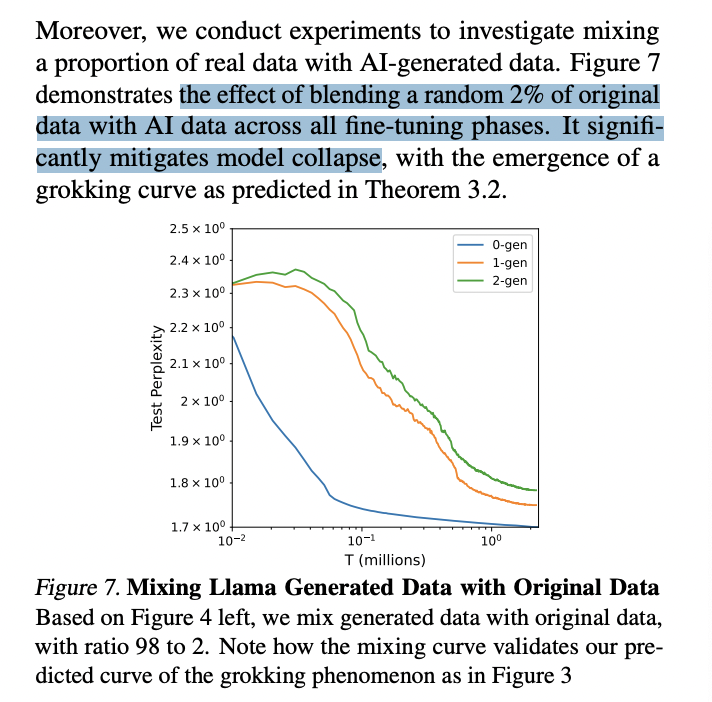
Ok this is interesting, because this paper basically says the opposite. So long as 2% of your data is real, collapse is substantially mitigated. thoughts? feelings? https://t.co/JKGeAM7OT8
🚨 Fascinating insights from the paper “Strong Model Collapse”! (https://t.co/WTg2dujtkE) It concludes that even the smallest fraction of synthetic data (as little as 1% of the total dataset) can lead to model collapse. 🧠 Larger datasets don’t necessarily improve performance! http

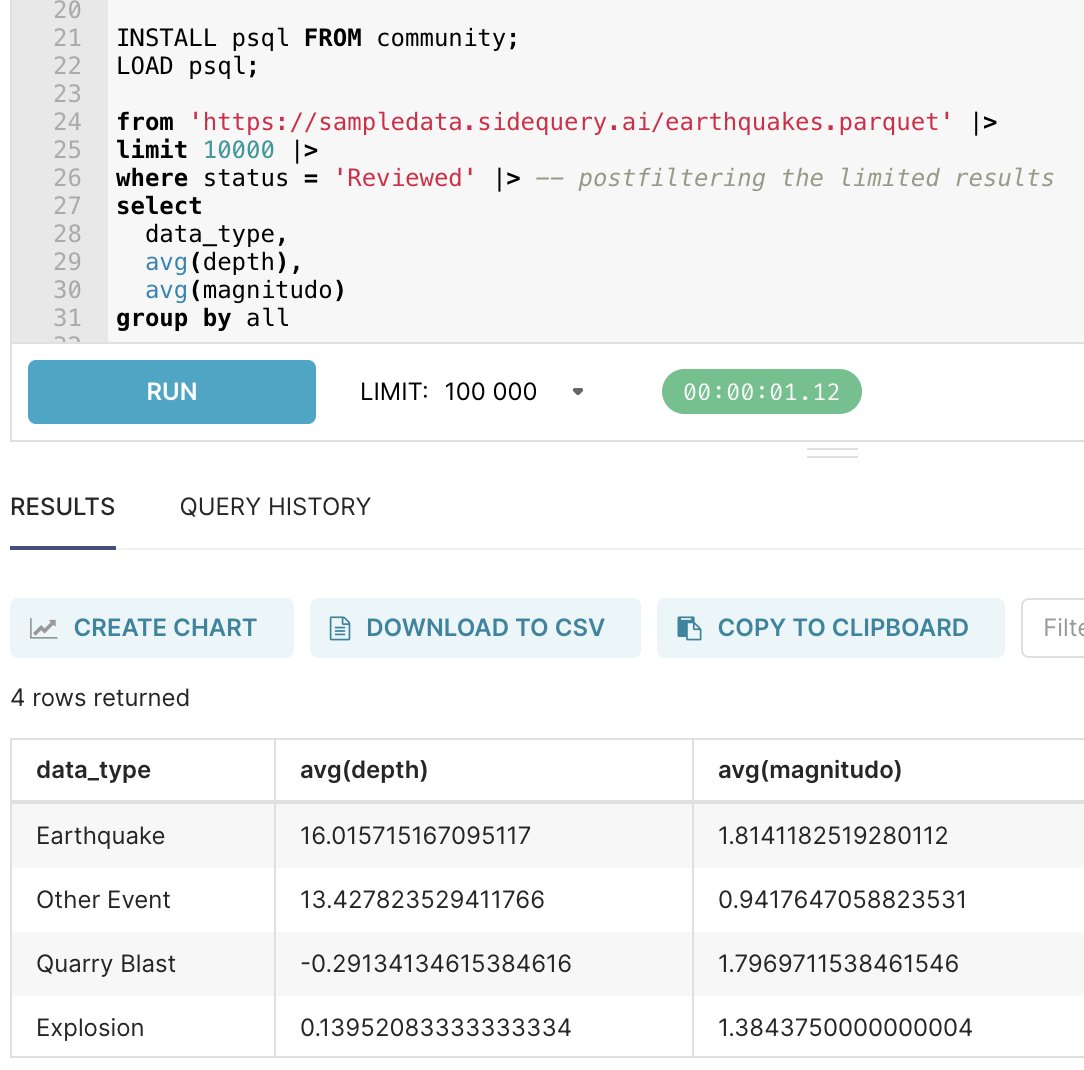
Did you know this works today in DuckDB? https://t.co/dojNtRujzU
My favorite is piped SQL, which made its way out of Google before it was released to BigQuery https://t.co/1siix9IV9I
You really, really should not trust audio clips anymore Even a couple months ago, it used to take a commercial service to clone a voice. No more. Here is me creating a voice clone of myself using just a 10 second reference clip on my home computer This is all real time, no cuts https://t.co/0OlBcMcYbm
Multimodal Ichigo Llama 3.1 - Real Time Voice AI 🔥 > WhisperSpeech X Llama 3.1 8B > Trained on 50K hours of speech (7 languages) > Continually trained on 45hrs 10x A1000s > MLS -> WhisperVQ tokens -> Llama 3.1 > Instruction tuned on 1.89M samples > 70% speech, 20% transcription, 10% text > Apache 2.0 licensed ⚡ Architecture: > WhisperSpeech/ VQ for Semantic Tokens > Llama 3.1 8B Instruct for Text backbone > Early fusion (Chameleon) I'm super bullish on @homebrewltd and early fusion, audio and text, multimodal models! (P.S. Play with the demo on Hugging Face)
On the Stone Soup of LLM Reasoning #SundayHarangue Stone soup is the European folk story where some clever travelers convince the gullible locals that they are making delicious soup with a stone--and they do need a few things to "improve its flavor"--such as carrots, potatoes, onions, butter etc.. There is nothing ipso facto wrong with Stone Soup--it is, after all, soup! It may even be delicious! The question instead is how much credit should the stone get for the soup's delciousness. The version of Stone Soup in AGI/AI circles are claims that LLMs can reason and plan--with just a few things to "improve the flavor". These needed things needed can range from external tools/verifiers etc (as in LLM-Modulo), to tacking on search on top of LLMs (the tree of thoughts), to tacking on a Mu_zero/Alpha_go like RL component that influences pretraining as well as inference stage (the 🍓 o1 model; see https://t.co/5nivQhAXFB). The question is whether the "augmented" systems are LLMs or some other qualitatively different beasts better called LRMs (cf. https://t.co/CvHuWhlKNj). Although it has become fashionable to equate LLMs to AI, and ask "When will AI Reason?"--the fact of the matter is that we have always had AI systems--planning, RL etc.--capable of reasoning. It can be argued that much of AI before LLMs was in fact was deep and narrow System 2 approximators (and thus https://t.co/m0Ecnvnx6E and https://t.co/NcZaqR2QzH). The appeal of LLMs is that they are the first effective System 1 approximators that AI managed to develop (c.f. https://t.co/UsnxSYaeKU). There have been several attempts to get System 2 reasoning behaviors from LLMs while keeping their essential autoregressive System 1 nature intact. These early attempts--such as "fine tuning", "Chain of thought" etc.--have by now been shown to be deeply flawed (c.f. https://t.co/DEjF9gLR8q & https://t.co/NE0MizcWN7). In other words, no soup from them! #Seinfeld In contrast, the approaches that tack on search/RL etc. at the inference stage seem to be more promising (c.f https://t.co/RqRf4fWjrU). But these "compound" LRM systems are no longer autoregressive LLMs and don't have any "start completing the prompt as soon you hit return" characteristic that is such a big part of LLM popularity! In particular, if the LRM is taking indefinite and costly inference time compute, the right comparison will be to other System 2 AI approaches that incur such inference time costs. Such considerations bring some of the traditional CS analyses--all but forgotten when online computation was given up for dead (c.f. https://t.co/I9Ya3j2EER)--back into play (see https://t.co/RqRf4fWjrU & https://t.co/JeZ8L0ryia). Interestingly, you can also err assuming that LRMs will inherit all the limitations of LLMs (something that the analyses that clump, for example, o1 with autoregressive LLMs mistakenly make).. They don't! Stone Soup is more than Stone--even if it may not be the best way to make soup! Specifically, many of the common critiques of LLM reasoning capabilities don't directly apply to LRMs. Not recognizing this and adding LRMs like o1 as yet another entry in a table brimming with autoregressive LLMs confuses the message. (For example, if you look at the appendix of that latest Apple study on LLM reasoning, you will see that o1 does quite fine--accuracy-wise--on their instances with irrelevant information.) Another argument for separating their analysis--as we do (c.f. https://t.co/3BUmLS7kTr).

So OpenAI isn't going to support the Swarm repo in any way, but no one else is allowed to contribute to it either? https://t.co/J0n9u9G3hp https://t.co/Ets2uwxCjH

This may look like a game of Counterstrike running slowly, but it actually extraordinary. The entire game is created, frame-by-frame, on my *home computer* by an AI diffusion model in response to my actions. There is no game engine, just a "world model" trained on Counterstrike https://t.co/TIz4EGQdFY
Psychologists have posited hundreds of cognitive biases over the years. A fascinating new paper argues that they all boil down to one of a handful of fundamental beliefs coupled with confirmation bias. https://t.co/uZTVbGnH3d https://t.co/9sv1yS8MVW
Deploying advanced RAG is challenging. We make it a simple 3-step process: 1. Write your advanced RAG workflow in Python 2. Deploy it as API services with persistence and message queues through llama_deploy 3. Run it! @pavan_mantha1 has an excellent tutorial showing you how to build a RAG pipeline with in-built reflection/filtering/retries, and then deploy them as services through llama_deploy. It’s great weekend reading if you’re looking to not only code a workflow in a notebook, but put it behind an API server https://t.co/XoNHRr4cZb

PART 3: Handed my vacation videos to an AI for auto editing, and now I'm pretty sure I'll have nightmares for life 🤯 https://t.co/jYX1TZ4rMX
Interesting post https://t.co/kg31tCueKC
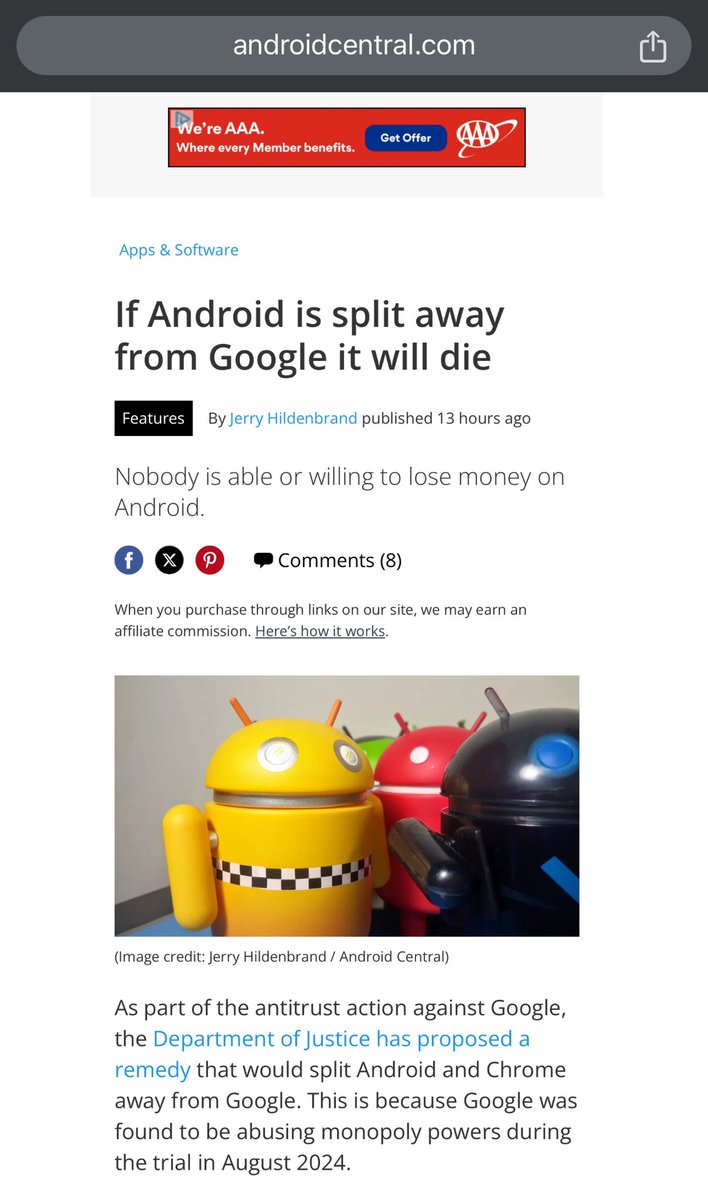
A textbook, @dsquareddigest style unaccountability sink https://t.co/19BnSJDyjm

First Sam Altman’s piece on a straight path to AGI and now this piece by Anthropic’s CEO on 2 years to powerful AI, I think that any large organization or agency needs to take the possibility of near-term powerful AI seriously They may be wrong or exaggerating, but worth noting https://t.co/Xuk85PN3mC
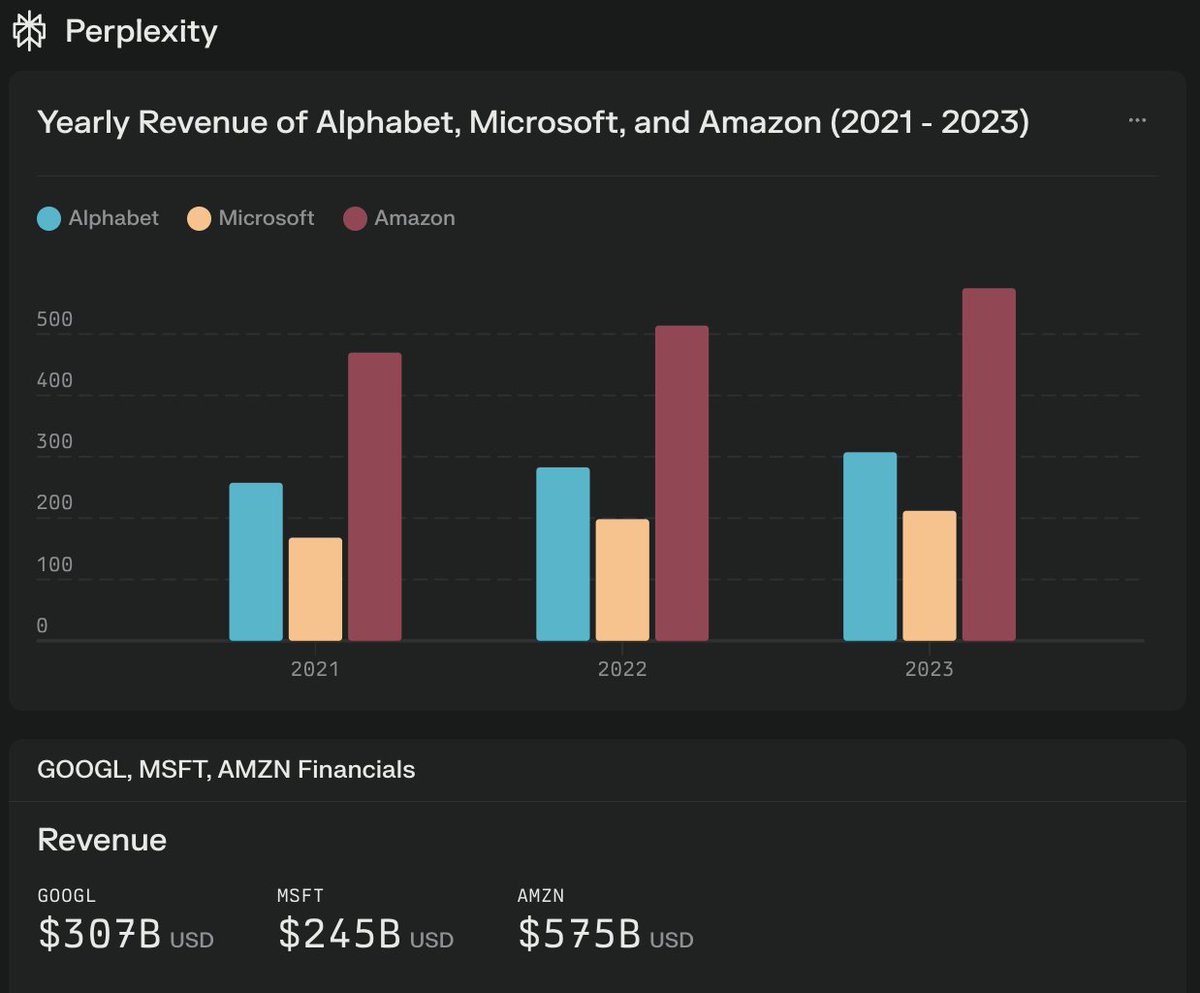
Perplexity charts with code generation and execution have the potential to be the friendly UI and affordable Bloomberg terminal for the masses, which everyone has wanted for a long time! Perplexity Pro is $20/mo, while Bloomberg Terminal is $2500/mo. So, more than 100x cheaper.
many such cases https://t.co/0APABzxq8z

Nice little experimental multi-agent framework by OpenAI. You can build, orchestrate, and deploy multi-agent systems with this lightweight framework. Agents can be built with specific instructions and access to tools, and communicate with other Agents to delegate tasks. It also has function-calling capabilities and includes evaluation examples.
Long-Context LLMs Meet RAG For many long-context LLMs, the quality of outputs declines as the number of passages increases. It seems that the performance loss is due to retrieved hard negatives. They propose two ways to improve long-context LLM-based RAG: 1) retrieval reordering and RAG-specific tuning with intermediate reasoning to help with relevance identification. "Our proposed approaches show significant accuracy and robustness improvements on long-context RAG performance." I've recently seen a few research papers trying to make long-context LLM-based RAG work. It looks like order of passages and reasoning for retrieving relevant information produce the biggest performance gains.
"Why is fraud so common in fields in which it is customary to publish images that can later be checked for obvious fakery?" https://t.co/GqVKHVjNo3

“$2 H100s: How the GPU Bubble Burst” https://t.co/NytSIgpu6Y Last year, H100s were $8/hr if you could get them. Today, there’s 7 different resale markets selling them under $2. What happened? https://t.co/1FnhCzMGxx
Data quality is essential for a high-performance gen AI application. @argilla_io is a tool that lets you generate and annotate datasets for fine-tuning, RLHF, and evaluation, and it's got a first-class LlamaIndex integration! Check out their demo notebook walking you through the full steps of using the integration: https://t.co/810ktW1OmT
