Your curated collection of saved posts and media
https://t.co/P5GRV4YxlT

@jxnlco https://t.co/Ihw7pzdpA9

@jxnlco https://t.co/Ihw7pzdpA9

@jxnlco another one https://t.co/BBe498Q62K

@jxnlco another one https://t.co/BBe498Q62K

@jxnlco https://t.co/c5BTpk4FHx

@jxnlco https://t.co/c5BTpk4FHx

@jxnlco https://t.co/wWpUrUsmBx

@jxnlco https://t.co/wWpUrUsmBx

https://t.co/0u8rPnt7ej
https://t.co/cD8D44aGFh

https://t.co/0u8rPnt7ej

@jxnlco https://t.co/MfkgB2Kvh8

@jxnlco https://t.co/MfkgB2Kvh8

@jxnlco https://t.co/bQU5MJOUWs

@jxnlco https://t.co/bQU5MJOUWs

@Akumunokokoro @NousResearch https://t.co/pYe7FCY9cL

@cobi_bean @NousResearch @OpenRouter https://t.co/pYe7FCY9cL

@vincent_koc @morganlinton @steipete You had literally just agreed we did you right instantly banning that insane person, and now you're turning around continuing this. I literally only ever RESPOND to your personal attacks. Your new mod couldve just made us aware of this person being in our discord before we added 7 mods and we'd have banned him, like we did today, when you brought it to our attention. You yourself agreed we did you right
@Aleks13053799 @vincent_koc I've never subscribed to anyone in my life on this platform https://t.co/cHbytr8pd6
A trillion tokens isn't cool. You know what's cool? https://t.co/FUKe9GKc3F
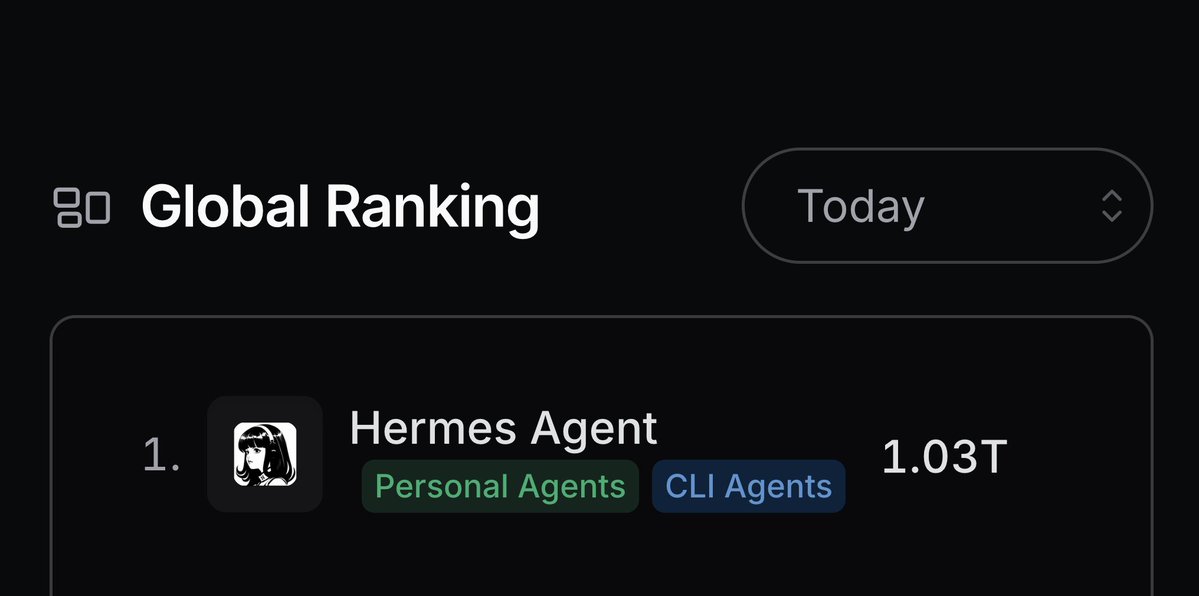
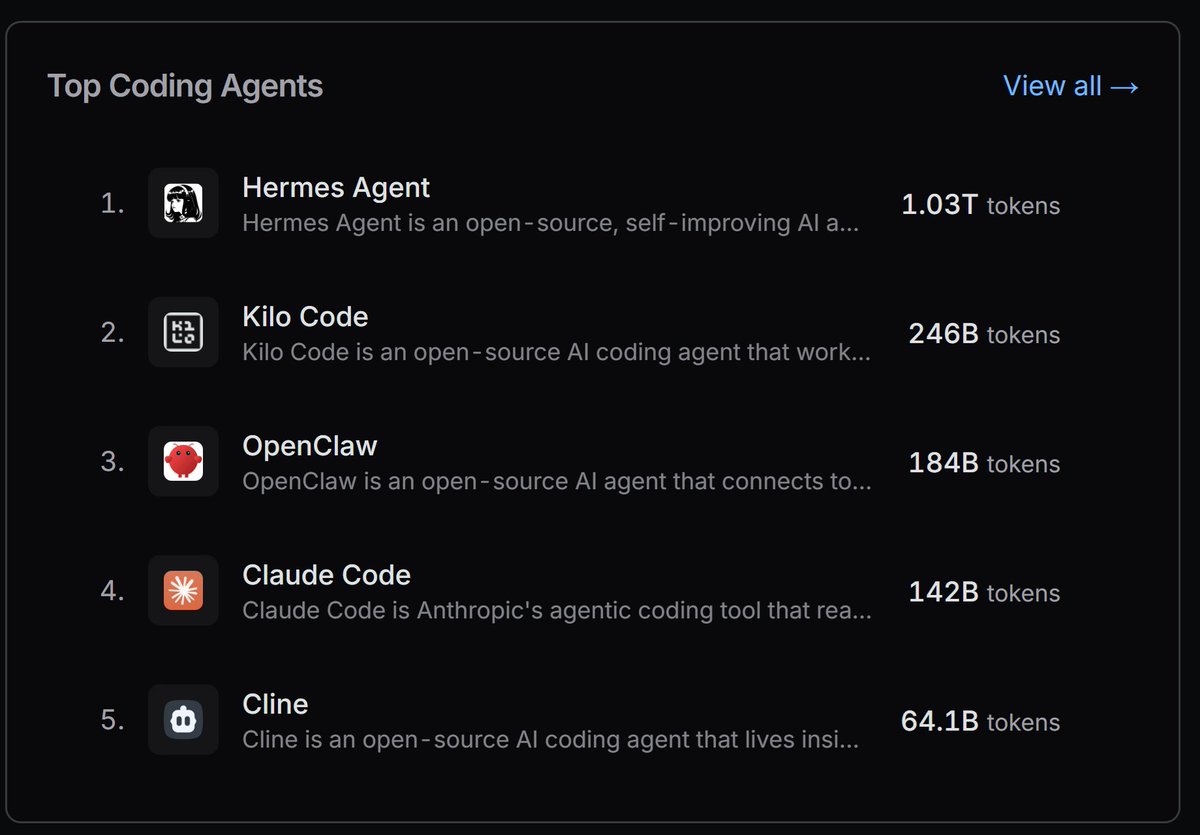
Wait we actually just broke 1T tokens in a day for the first time on OpenRouter :O Please keep contributing to the most awesome project I've ever worked on to help make Hermes Agent the best software stack on the planet! Thank you contributors🍻🍻 https://t.co/BSYK9sYGGD
A trillion tokens isn't cool. You know what's cool? https://t.co/FUKe9GKc3F
@jxnlco https://t.co/TpnRSlvVII


@jxnlco https://t.co/TpnRSlvVII

@jxnlco https://t.co/oIghNYNfVy

@jxnlco https://t.co/oIghNYNfVy

Enough monkeys typing with codex and one of them will build openclaw https://t.co/56JtOQkTQs

https://t.co/soGI2rNlTl

@jxnlco https://t.co/pjDmdmDbYG

@jxnlco https://t.co/pjDmdmDbYG

https://t.co/soGI2rNlTl

https://t.co/N9pVbDLyAO
https://t.co/soGI2rNlTl
@jxnlco @ajambrosino https://t.co/HrDuT6pbM5
