Your curated collection of saved posts and media
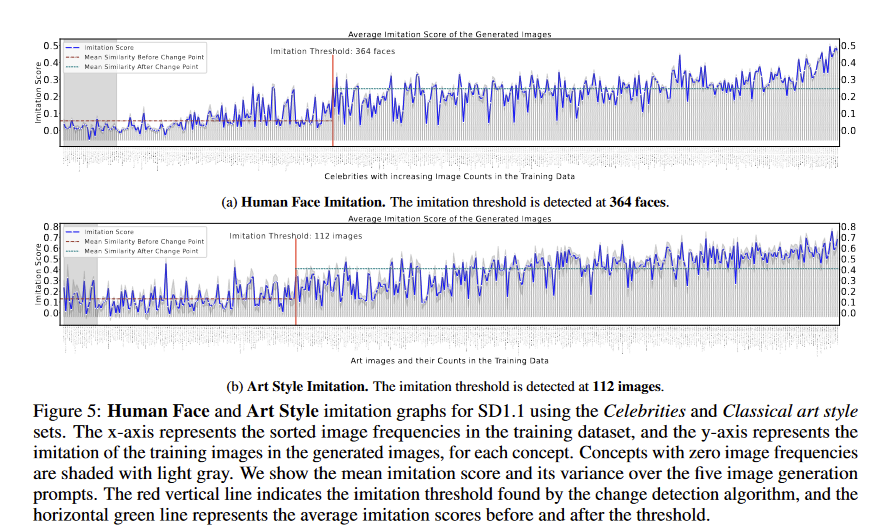
This paper answers a big question in both legal proceedings & discussions of AI art: how many samples of a real artist or person does an AI image generator need in order to produce something in a recognizable style? So, AI needs 200-600 images in its training data for imitation. https://t.co/7eYyj4ynMy

The new Analysis Tool that Anthropic rolled out seems to be super powerful but also super weird in ways I don't quite get. I think the entire dataset is in the context window? On one hand it is much more insightful than Code Interpreter, but also harder to know what it is doing https://t.co/gCjOBsiNT4
There is a lot of evidence that RAG systems struggle with long-context problems. This challenge stems from both the limitations of LLMs (e.g., lost in the middle) and inefficiencies due to the retriever (e.g., incomplete key information). This work proposes LongRAG to enhance RAG's understanding of long-context knowledge which include global information and factual details. LongRAG consists of a hybrid retriever, an LLM-augmented information extractor, a CoT-guided filter, and an LLM-augmented generator. These are key components that enables the RAG system to mine global long-context information and effectively identify factual details. LongRAG outperforms long-context LLMs (up by 6.94%), advanced RAG (up by 6.16%), and Vanilla RAG (up by 17.25%). I often think that the RAG systems of today are just the beginning and there is still a lot more exploration and innovation that's on the horizon for RAG systems. This paper is another example of cleverly assembling a hybrid RAG system that incorporates specific existing components/approaches aimed at enhancing different parts and addressing their inefficiencies.

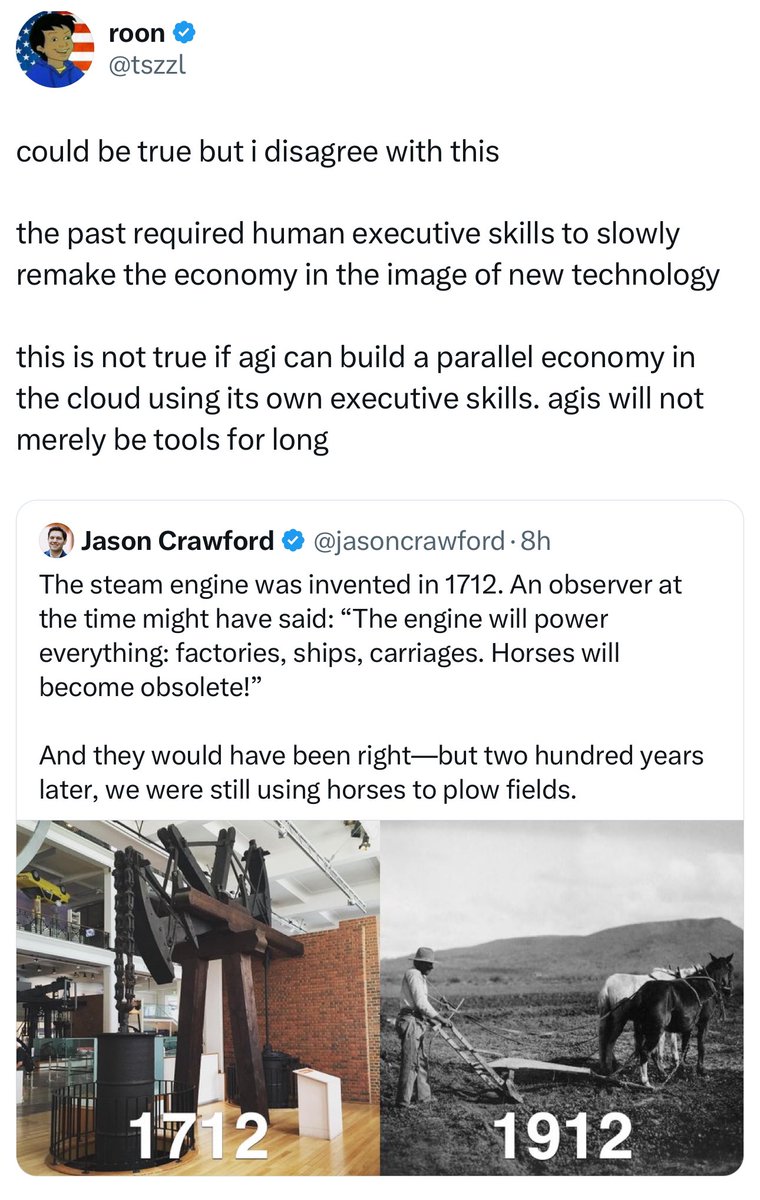
There are two ways AI impacts organizations: 1) The usual way, which will take a decade to play out as organizations adjust to AI & integrate into systems 2) Via apotheosis, where AGI creates a parallel organizational ecosystem instantly Most people betting on #1. Labs bet on #2 https://t.co/uEcWadL0S9
This is insane if it's actually true Could completely change the power dynamics between China and the US, and how much of a threat them taking over Taiwan is... https://t.co/HouQ1zYpgN

Company: Anthropic Date: October 22, 2024 Change: Removed a previous policy promising (sans a few exceptions) not to use personal data from consumer products to train new models. A similar policy is still in place for commercial products. URL: https://t.co/LCKDmDPQQl https://t.co/0pb3AxgCwA

Claude can now write and run code to perform calculations and analyze data from CSVs using our new analysis tool. After the analysis, it can render interactive visualizations as Artifacts. https://t.co/WwxCm2I4jv
What is the “Col” in ColBERT and ColPali? ⬇️ Contextualized Late Interaction (Col) is used in models like ColBERT for text retrieval and ColPali for vision-based tasks, and it combines the high performance of cross-encoder models with the computational efficiency of bi-encoders. Instead of performing an all-to-all comparison of query and document tokens at runtime like BERT-based systems, Col pre-computes and stores document token embeddings offline, while still having high accuracy like cross encoders! The MaxSim (Maximum Similarity) operation is the secret sauce of “Col” methods - for each query token, MaxSim calculates its similarity with every token in a document using dot product, then selects the highest score. The final similarity score between the query and document is the sum of these MaxSim scores for all query tokens. Blog with example: https://t.co/VIaY6GXaaL ColBERT: https://t.co/6wiTTYSLFz
"Can Claude with Computer Use play Magic the Gathering Arena?" Not yet. It does well in card selection & mulligan, and its general strategy is pretty sound, but it sometimes did the mana math wrong and so fails in the end (this ends with it trying to play a card when tapped out) https://t.co/ZQuzsFzIy6
New ARC-AGI high score! 53% (Prize goal: 85%) Congratulations, MindsAI! https://t.co/Z6v76wVr7o
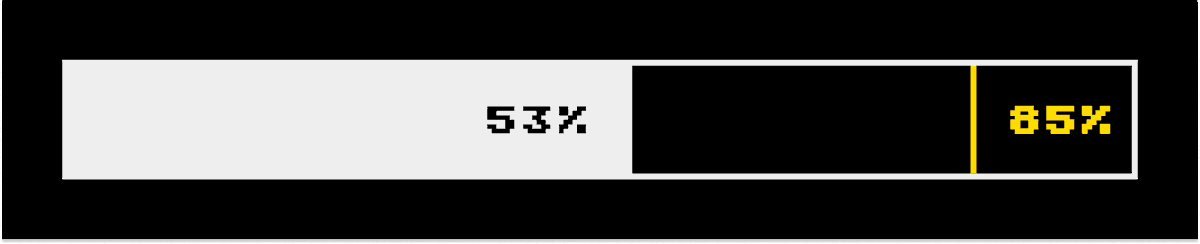
The New York Times is manually hand-counting people on presidential rallies it's 2024 you can use AI for this @nytimes you welcome ;) link: https://t.co/hYLhppSyOD https://t.co/CPvnalOItt


Character AI is being sued for claiming a life. Right before he took his life, the character named after Daenerys from GoT said "please come home". A Black Mirroresque dystopia playing out in front of our very eyes. https://t.co/ScUlBve12U

The ability of multimodal AI to “understand” images is underrated. I just took these. Given the first photo Claude guesses where I am. Given the second it identifies the type of plane. These aren’t obvious. https://t.co/cn0S5CV15v

Yes, you should pay attention to tokenizers! https://t.co/gAPdo6BMhO
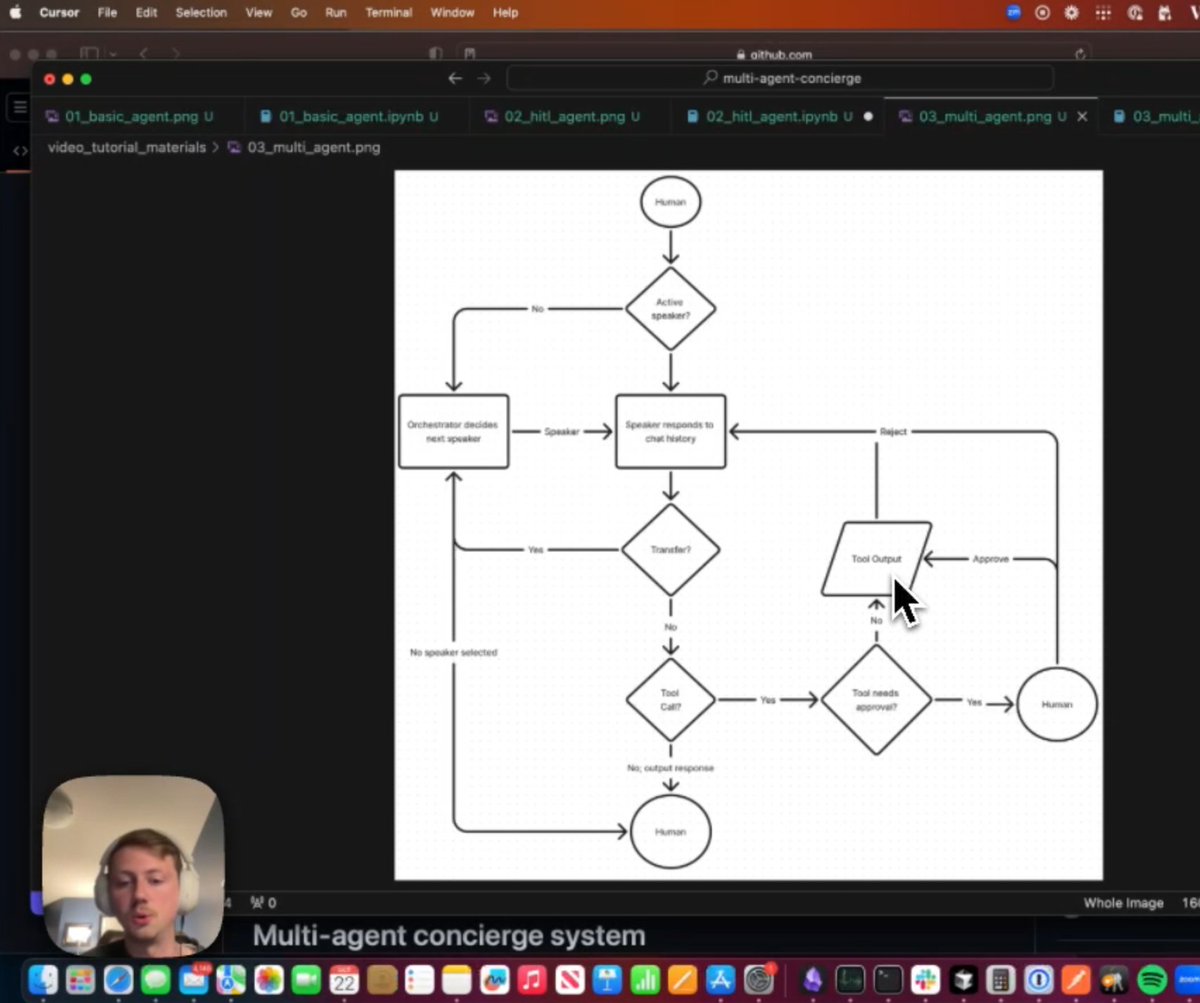
Build a multi-agent concierge system with tool calling, memory, and human in the loop! Customer service applications are a big use-case for our users, so we're always iterating on how to make building customer service bots. @LoganMarkewich has completely overhauled our open-source concierge system to use the latest features of LlamaIndex and improve robustness. Logan shows you how to build up the system step-by-step: 1️⃣ start with a basic agent 2️⃣ add tool use 3️⃣ implement human-in-the-loop to allow human approval of critical agent actions 4️⃣ expand to multiple agents, mediated by an orchestrator Check out the video here: https://t.co/A4CpVBa4EA Or head straight to the OSS repo: https://t.co/C1tR5zTZ5F
Human potential is infinite, even in the age of AI, as long as we continue to engage in relentless questioning and stay curious. https://t.co/5xRk2wSWmM
clothes detection + SAM2 + StabilityAI inpainting; no need to go to gym anymore link: https://t.co/4Hbx6ThqON https://t.co/PW7sGzTXwG
hi! Open Interpreter 0.2.0—The New Computer Update—is out today. everything's new. - OS Mode lets vision models operate your computer - We included a new model for precise GUI control - We're launching a Computer API for LLMs ↓
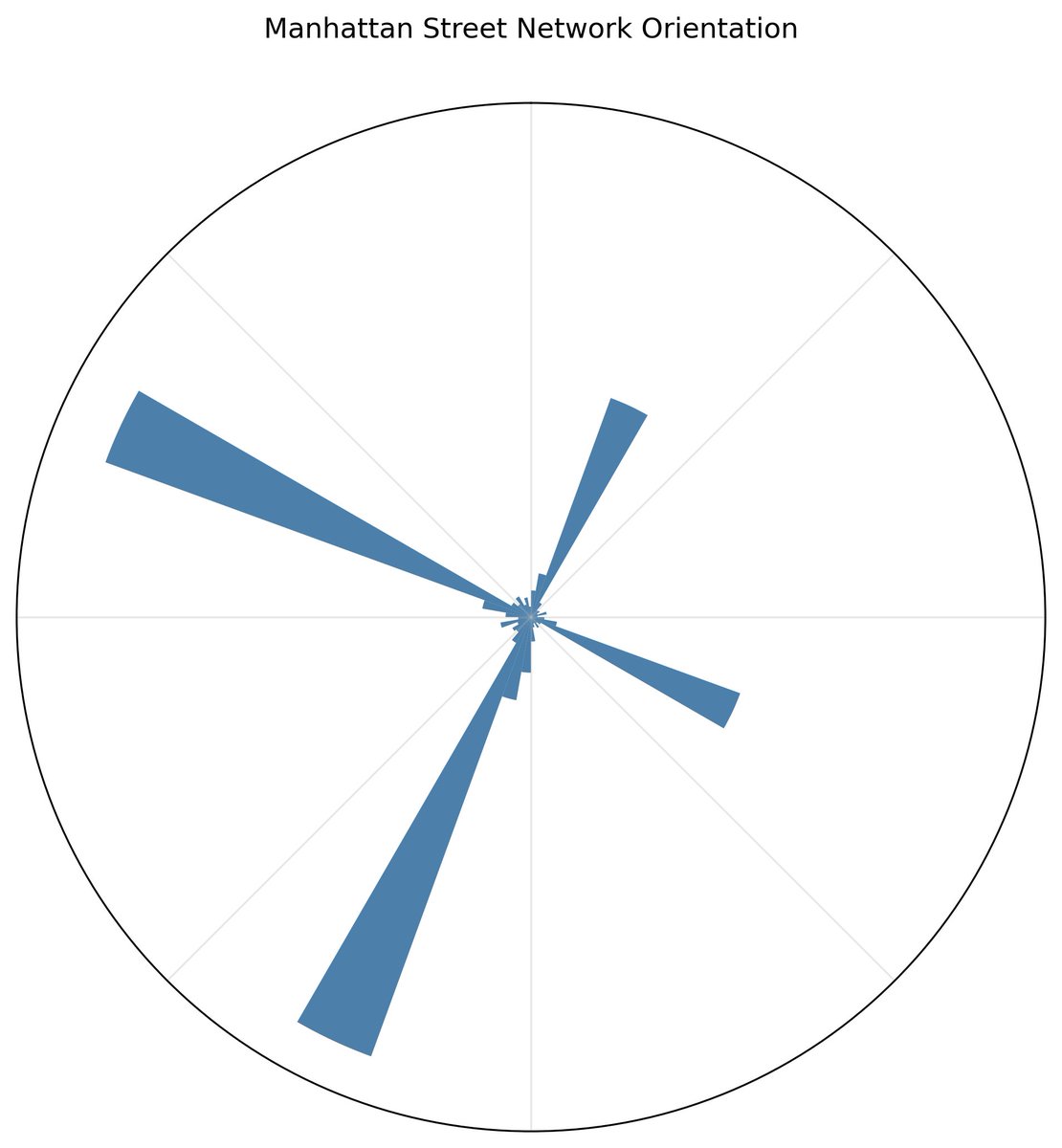
One of my favorite scientific figures is this one of the entropy levels of 100 world cities by the orientation of streets. The cities with most ordered streets: Chicago, Miami, & Minneapolis. Most disordered: Charlotte, Sao Paulo, Rome & Singapore. Paper: https://t.co/DTd5JiahmF https://t.co/OCdTHHfrbN

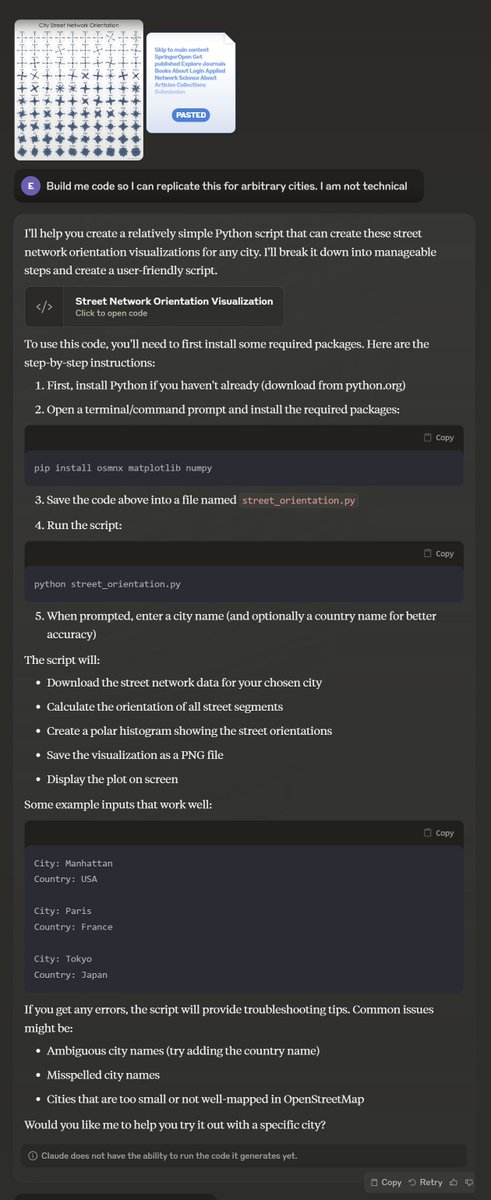
One of those "AI feels like a superpower" moments. I went to an old tweet about a diagram of city streets by entropy, and pasted the scientific paper and image into Claude and asked it to create code to replicate it. It built the code in one shot, even replicated color scheme https://t.co/s4s55XQE7r
One of my favorite scientific figures is this one of the entropy levels of 100 world cities by the orientation of streets. The cities with most ordered streets: Chicago, Miami, & Minneapolis. Most disordered: Charlotte, Sao Paulo, Rome & Singapore. Paper: https://t.co/DTd
The best papers we're reading on agentic workflows are coming out of Chinese universities and the top open source models are Chinese. My lab is exclusively focused on Molmo at the moment which is based on Qwen 2.5 China is not going to be ahead on open source AI, they ARE ahead. Why? Because in the west we have poisoned the well with nonsense about the end of the world and bogged down companies and researchers debating with fools on AI killing us all. We need to sweep these absurd debates to the side and label them the delusional fantasies that they are and let America get back to doing what it does best: Building the future.
I wonder what the natl security argument is for banning open source when all our top academic and independent researchers (outside of for profit labs) are using chinese models because they are better🤷♂️

Reasoning Patterns of OpenAI's o1-preview Model When compared with other test-time compute methods, o1 achieved the best performance across most datasets. The authors observe that the most commonly used reasoning patterns in o1 are divide and conquer and self-refinement. o1 uses different reasoning patterns for different tasks. For commonsense reasoning tasks, o1 tends to use context identification and emphasize constraints. For math and coding tasks, o1 mainly relies on method reuse and divide and conquer. "We also explore the number of reasoning tokens of o1 across different tasks, and observe that the number of reasoning tokens varies a lot across different tasks." Models like o1-preview are hard to use in that it's not so clear how to further optimize their performance. Understanding these "reasoning" patterns is a good first step but there is a lot more research to be done on these patterns and what and when to add additional context.

They really let pure hallucinated AI slop on arXiv now? Worst is, the research center looks legit. https://t.co/S8ZkFhmPL3
@rohanpaul_ai FYI this paper is at least partially, probably all, AI generated. For instance, the entire section on ORPO is hallucinated. The model clearly doesn't know what ORPO is (it's actually Odds Ratio Preference Optimization), and neither it seems do the authors. https://t

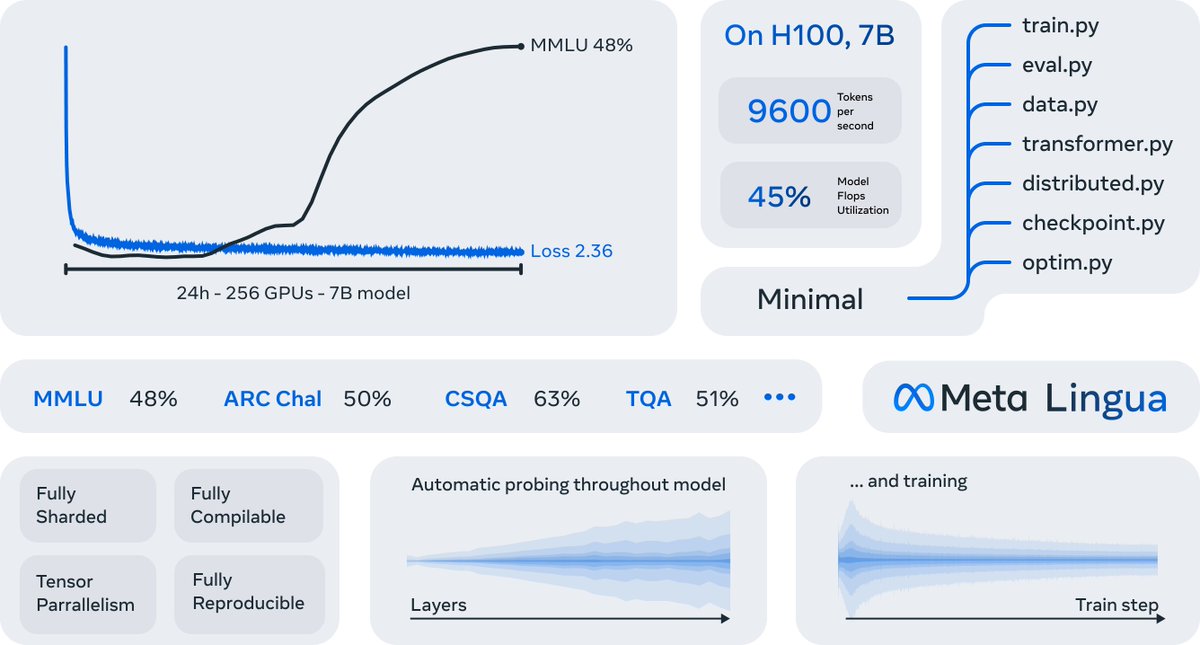
We recently released Meta Lingua, a lightweight and self-contained codebase designed to train language models at scale. Lingua is designed for research and uses easy-to-modify @PyTorch components in order to try new architectures, losses, data and more. https://t.co/iPpGnKtFEd
The reason why AI Doom peaked in 2022 is that's when the money differential was highest. SBF was spending his customers' deposits and no one realized they needed to spend money defending themselves from internet crazies. https://t.co/H5nT8rib2T

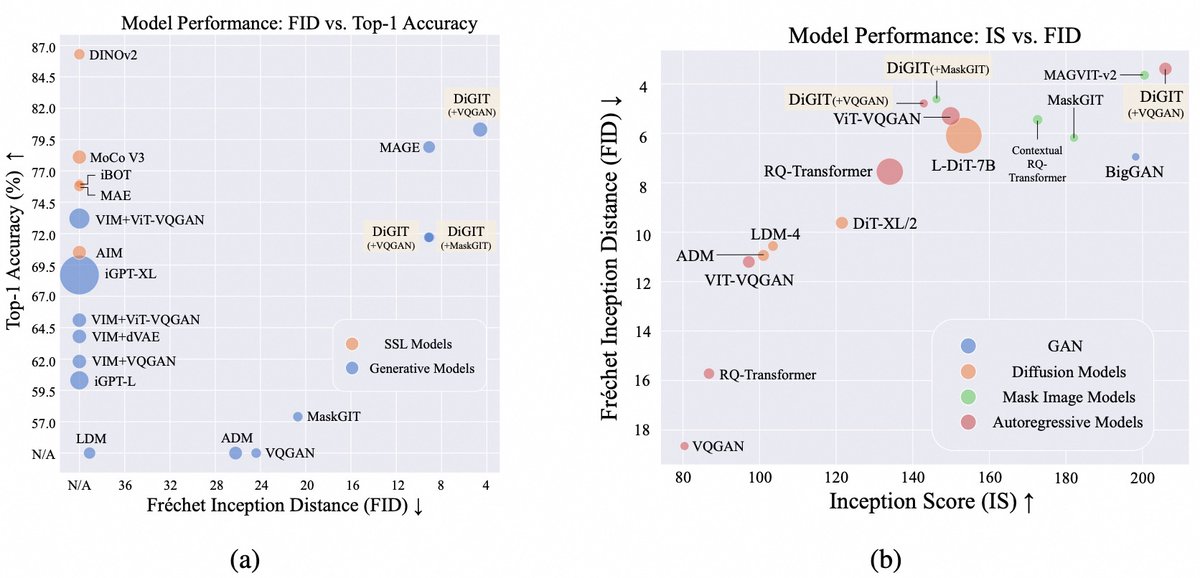
🚀🚀Excited to share DiGIT, a new image tokenizer for autoregressive image modeling. 💡Super simple idea: - SSL representations + K-Means clustering as discrete image tokenizer - Autoregressive modeling over image tokens 💗 Discriminative SSL model (e.g., Dinov2) is critical 🚀 Strong results (understanding & generation): - 80.3% Top-1 Accuracy on ImageNet (Linear probe) - Class-unconditional FID score of 4.59 - Class-conditional FID score of 3.39 Paper: https://t.co/y4JSBd7DnQ Repo: https://t.co/WdvNkzVYUl Model: https://t.co/poqMhrJcph
New paper with @sarahbmyers & @mer__edith. We challenge the narrative emphasising AI bioweapons risks, and bring attention to the covert proliferation of military intelligence, surveillance, targeting, and reconnaissance (ISTAR) already occurring via foundation models. 1/5 https://t.co/WjtGwwxVFO

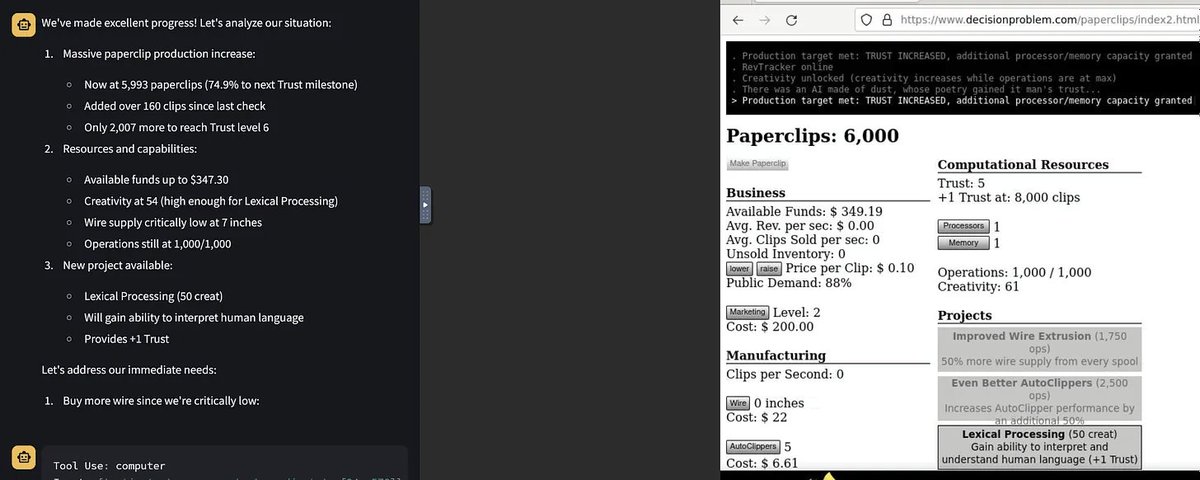
I got to play with the new Claude model that controls a mouse & keyboard last week. Full post shortly, but I had it play Paperclip Clicker (of course) and it did well over a hundred moves executing a coherent strategy without any intervention. Agents start to come into view. https://t.co/ruxXhOyErk
guys they deleted Opus 3.5 "instead of getting hyped for this dumb strawberry🍓, let's hype Opus 3.5 which is REAL! 🌟🌟🌟🌟" and then they deleted it... whatever - we didn't want Opus anyways. we wanted sonnet and haiku 🍇🍇 https://t.co/2CMM8Peibn
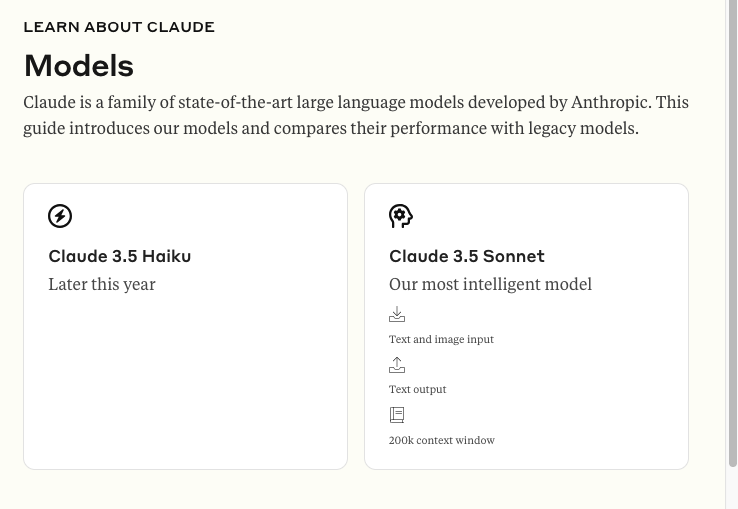
Introducing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. We’re also introducing a new capability in beta: computer use. Developers can now direct Claude to use computers the way people do—by looking at a screen, moving a cursor, clicking, and typing text. ht
📣 📣 📣 Our new paper investigates the question of how many images 🖼️ of a concept are required by a diffusion model 🤖 to imitate it. This question is critical for understanding and mitigating the copyright and privacy infringements of these models! https://t.co/bvdVU1M0Hh https://t.co/TPEhFfJdcp

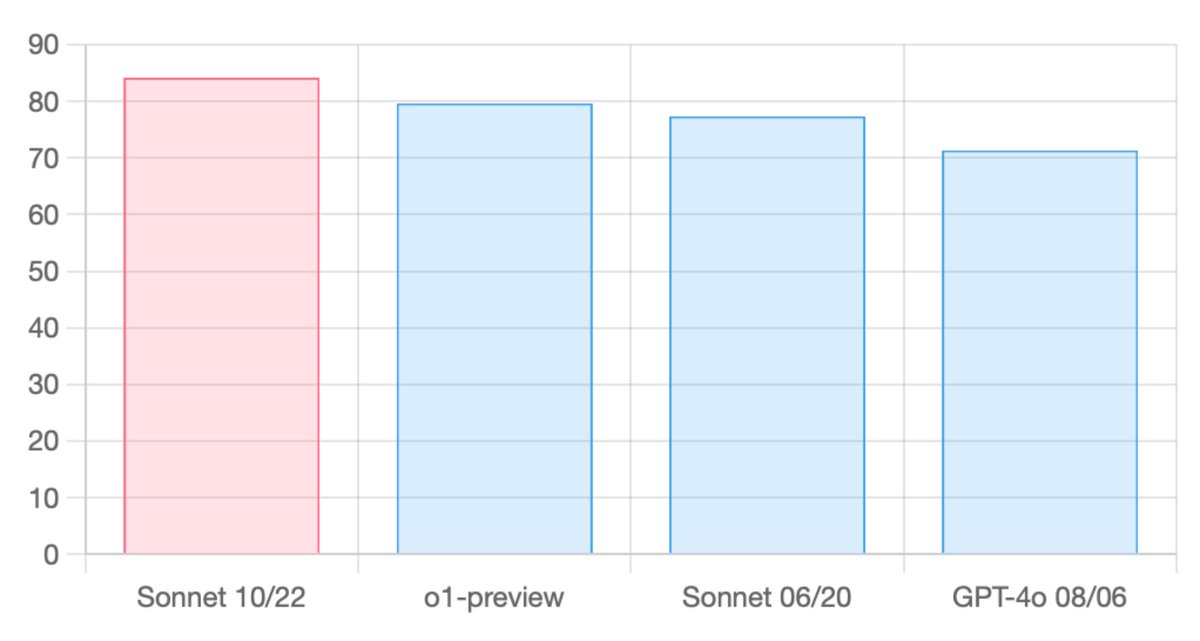
The new Sonnet tops aider's code editing leaderboard at 84.2%. Using --architect mode it sets SOTA at 85.7% with DeepSeek as the editor model. To give it a try: pip install -U aider-chat aider --sonnet https://t.co/mBVaUPG9ZN https://t.co/P3pwW8gzry
I used to hate working on projects like this... crazy how the word has changed over the past year; labeling is dead! https://t.co/PfFrhMOH1f