Your curated collection of saved posts and media
This is the best paper written so far about the impact of AI on scientific discovery https://t.co/OxjsBetcHP

Claude with visual PDF understanding makes reading research papers so nice Especially ML papers with lots of charts and graphs https://t.co/NVTFbADWRQ
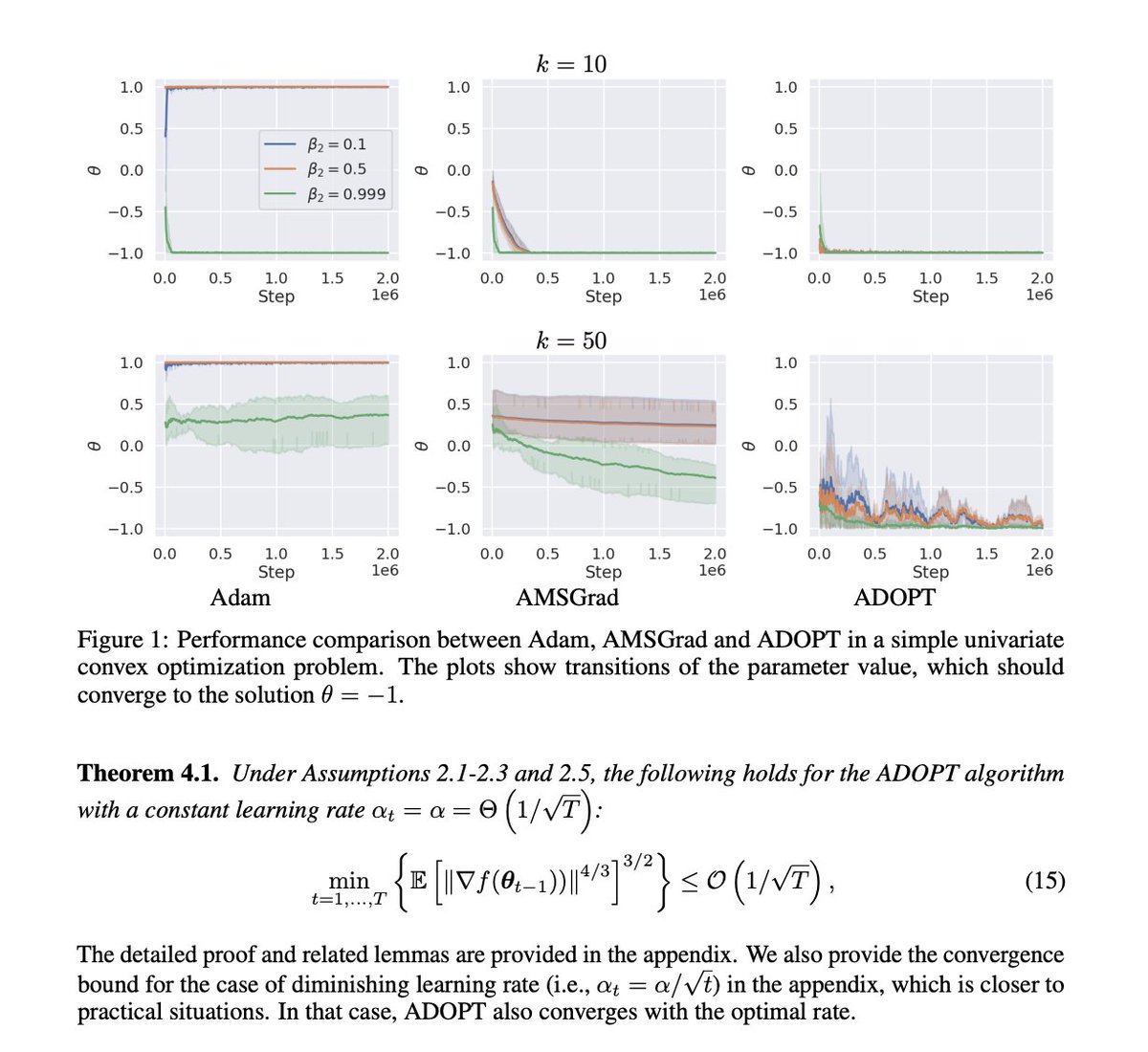
Microsoft introduces Magentic-One, a new generalist multi-agent system designed to handle complex web and file-based tasks. It uses an Orchestrator agent that directs four specialized agents: WebSurfer for browser operations, FileSurfer for file management, Coder for programming tasks, and ComputerTerminal for console operations. Magentic-One achieves competitive performance on multiple benchmarks including GAIA, AssistantBench, and WebArena, without requiring modifications to its core architecture. Built on Microsoft's AutoGen framework, Magentic-One employs a unique dual-loop architecture where the Orchestrator manages both task and progress ledgers. The system is open-source, along with AutoGenBench, a new evaluation tool for testing agent-based systems. It's very early, but this new movement of building generalist agentic systems is something to keep an eye out for. In addition, other current LLM-based applications like RAG will also benefit from this type of system that builds on top of multiple specialized agents.
The Discord server for our new course has one golden rule. https://t.co/ppcrHJOr0s

M4 Mac Mini AI Cluster Uses @exolabs with Thunderbolt 5 interconnect (80Gbps) to run LLMs distributed across 4 M4 Pro Mac Minis. The cluster is small (iPhone for reference). It’s running Nemotron 70B at 8 tok/sec and scales to Llama 405B (benchmarks soon). https://t.co/9fx39IP4ZZ
It's workiiing https://t.co/NB4vMycWK5
This paper replicates the finding that conversations with AI greatly reduce conspiracy theory beliefs, but, surprisingly, finds that this persuasion is despite the source being AI, not because of it. AIs are viewed as about as authoritative as a random human, not an expert. https://t.co/H3VTt87hXm

New short course: LLMs as Operating Systems: Agent Memory, created with @Letta_AI, and taught by its founders @charlespacker and @sarahwooders. An LLM's input context window has limited space. Using a longer input context also costs more and results in slower processing. So, managing what's stored in this context window is important. In the innovative paper MemGPT: Towards LLMs as Operating Systems, its authors (which include the instructors) proposed using an LLM agent to manage this context window. Their system uses a large persistent memory that stores everything that could be included in the input context, and an agent decides what is actually included. Take the example of building a chatbot that needs to remember what's been said earlier in a conversation (perhaps over many days of interaction with a user). As the conversation's length grows, the memory management agent will move information from the input context to a persistent searchable database; summarize information to keep relevant facts in the input context; and restore relevant conversation elements from further back in time. This allows a chatbot to keep what's currently most relevant in its input context memory to generate the next response. When I read the original MemGPT paper, I thought it was an innovative technique for handling memory for LLMs. The open-source Letta framework, which we'll use in this course, makes MemGPT easy to implement. It adds memory to your LLM agents and gives them transparent long-term memory. In detail, you’ll learn: - How to build an agent that can edit its own limited input context memory, using tools and multi-step reasoning - What is a memory hierarchy (an idea from computer operating systems, which use a cache to speed up memory access), and how these ideas apply to managing the LLM input context (where the input context window is a "cache" storing the most relevant information; and an agent decides what to move in and out of this to/from a larger persistent storage system) - How to implement multi-agent collaboration by letting different agents share blocks of memory This course will give you a sophisticated understanding of memory management for LLMs, which is important for chatbots having long conversations, and for complex agentic workflows. Please sign up here! https://t.co/XMlBifnwVa
Claude PDF analysis tool is really good! Here is a video of how I'm finding it useful for paper reading: - Figure interpretation - Table understanding - Extracting and finding information - Converting to structured formats (e.g., JSON) - Extracting findings and key sources - Translation - and much more
So it turns out that using LoRAs to customize a general LLM (the way Apple tunes its on-device models) limit the LLM far more than fine-tuning, because they lose some of their ability to generalize. The reason is LoRA's add ominously-labelled intruder dimensions.
https://t.co/l0XSIgjnNe

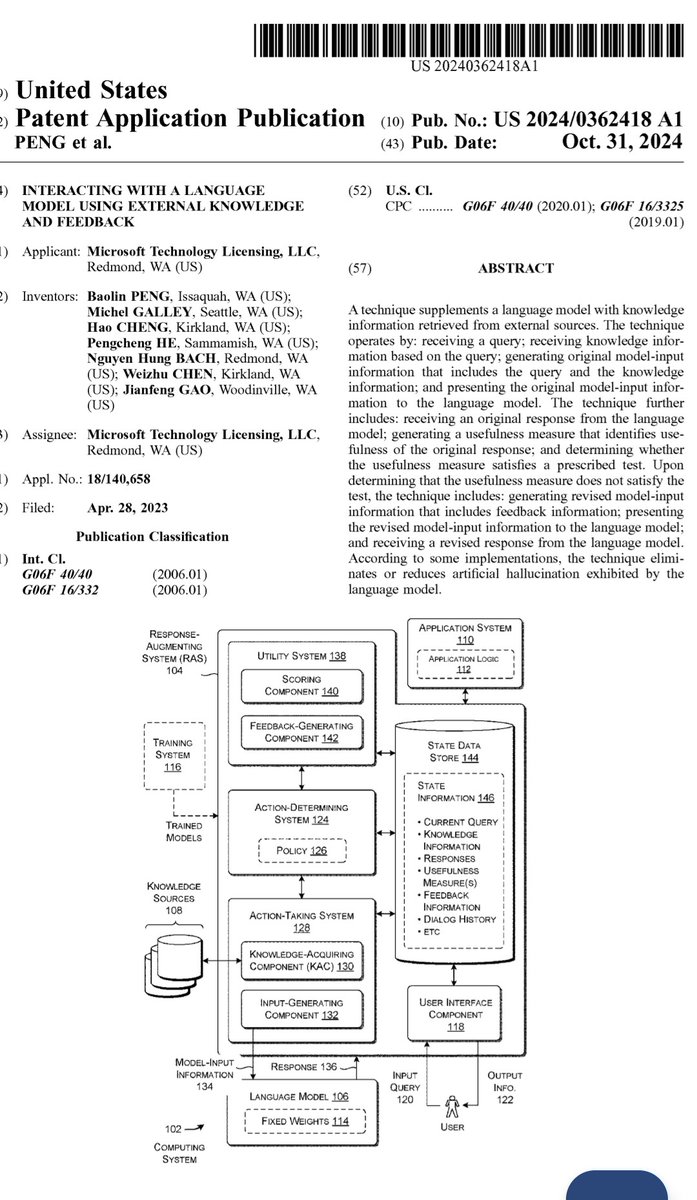
Microsoft appears to be trying to patent RAG. They call it RAS "Response Augmenting System" but a rose by any other name... I'm guessing the community and various vendors have some prior artwork to throw at this application. https://t.co/VVWDrXVjTS
i'm in, how could I not be! as an alumni of the first https://t.co/No0I8fQOMi cohort 6 years ago and as an engineering artist in my current incarnation excited to apply the new knowledge to my generative pottery https://t.co/3hE2oY2LQp
Today, we're announcing that @fastdotai is joining @AnswerdotAI, marking a new phase in making AI accessible. And we're launching a new a new kind of "AI-first" educational experience, "How To Solve It With Code". https://t.co/hLQ4gAZnsz

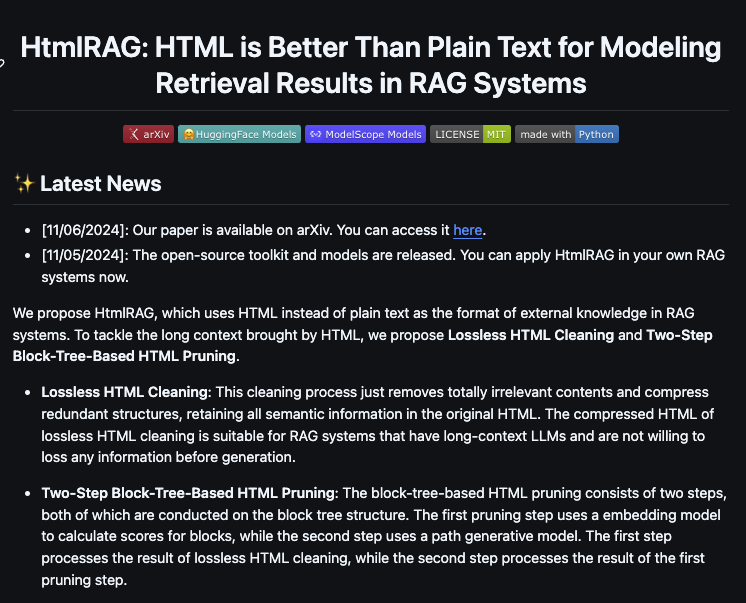
HtmlRAG HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems https://t.co/veIn9BV2Im
If you are looking for something to read/study this weekend, I added lots of LLM-related bonus from-scratch coding resources over the last few months (from implementing Llama 3.2 to preference tuning with DPO): https://t.co/jMi3McHWJD I hope you find them useful! https://t.co/mLvDe6uVcL

Interesting response from AI https://t.co/rb7fPZsthy
I finally got to meet @fchollet in person recently to interview him about @arcprize, intelligence vs memorization, human cognitive development, learning abstractions, limits of pattern recognition and consciousness development. These are the best bits. Full show released tomorrow https://t.co/AkzgRysEdX
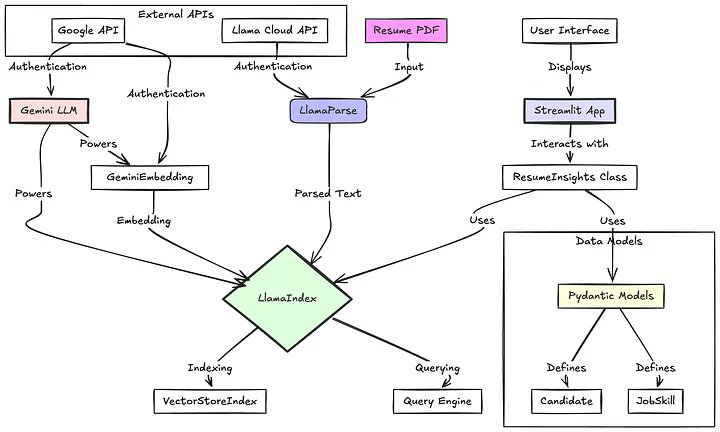
Build an automated resume insights agent - powered by core parsing, extraction, and structured output modules 📑🤖 This blog by @Luillyfe is a fantastic tutorial on building on building a practical example of AI in recruiting: given any unstructured resume, automatically extract out relevant information from it, and then return insights in a structured output format (that you can easily plug into a workplace application). Powered by @llama_index, LlamaParse, and structured output capabilities with Gemini. https://t.co/LBL28KBRSa
Anyone need some good news? @pydantic validating streamed structured responses on the fly from @OpenAI. (using pre-release Pydantic v2.10). There's something cooking in the Pydantic kitchen... https://t.co/0PhQkQughu
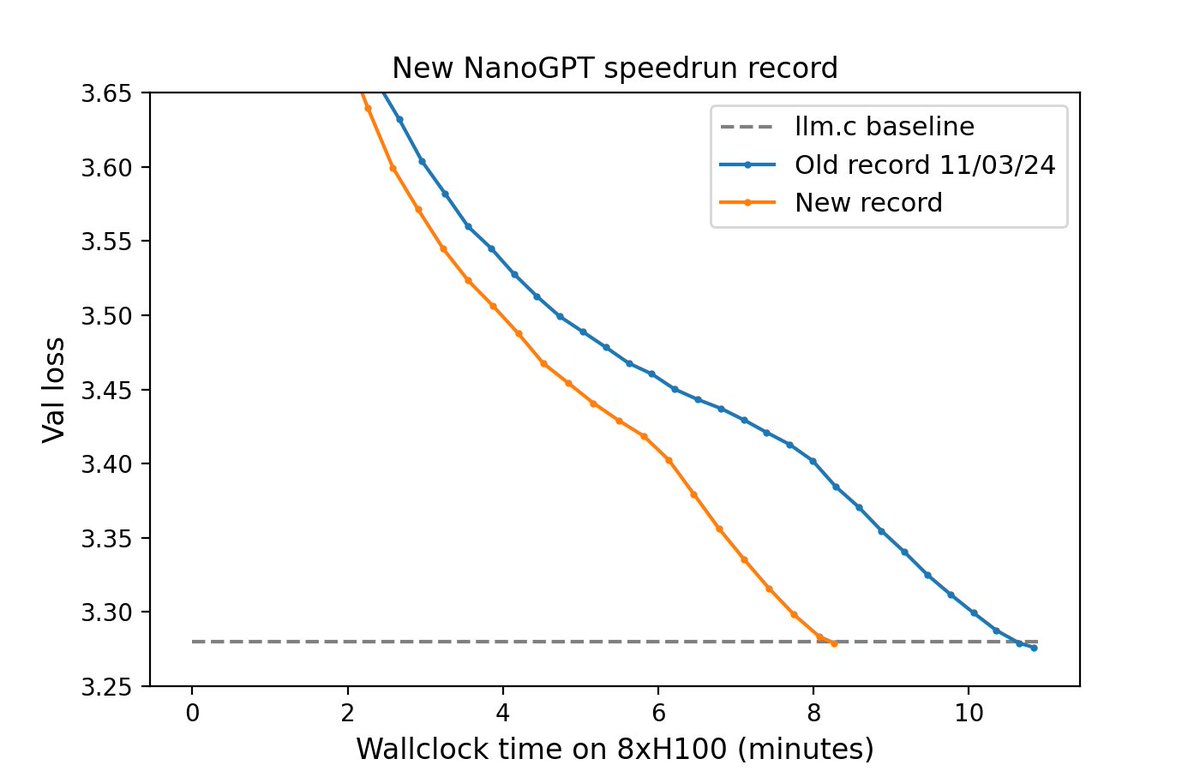
It's a new day, and here's a new NanoGPT speedrun record: 3.28 FineWeb val loss in 8.2 minutes on 8xH100 Previous record: 10.8 minutes Changelog: - architectural shortcuts - momentum warmup - tanh logit capping By @Grad62304977 and myself 1/6 https://t.co/YAFcuLrLou
Okay, this model is really cool 👀 https://t.co/5LhORJGGi5
FLUX1.1 [pro] Ultra is now available on Replicate. It generates beautiful, high-resolution images, and offers a "raw" mode with a more realistic aesthetic. Link to the Replicate model in the next tweet. What will you create? https://t.co/0QzFAgEp2A

🚀 HART by @MIT : Hybrid Autoregressive Transformer! It directly generates stunning 1024x1024 images with blazing efficiency, this hybrid approach outshines diffusion models in quality & speed. Also uses Qwen2-VL-1.5B-Instruct 🔥 The image generation speed is super fast, try out the demo! https://t.co/d3hJBs7vGa #AI #ML #CV

Automatic powerpoint generation is a HUGE enterprise agent use case. Check out this stack with @llama_index, @composiohq, and @e2b_dev below. Huge shoutout to @KaranVaidya6 👇 https://t.co/yVPrjfEmJd https://t.co/a7eMJievwT
🕴️🖥️ AI Powerpoint Assistant: Automate your Presentations using AI agents 🎮 No more sleepless nights drafting those decks!!! In just 50 lines of code, the agent: 1⃣ Reads and analyzes the Google Sheets data 2⃣ Creates awesome visualizations and tables 3⃣ Drafts a Presentation
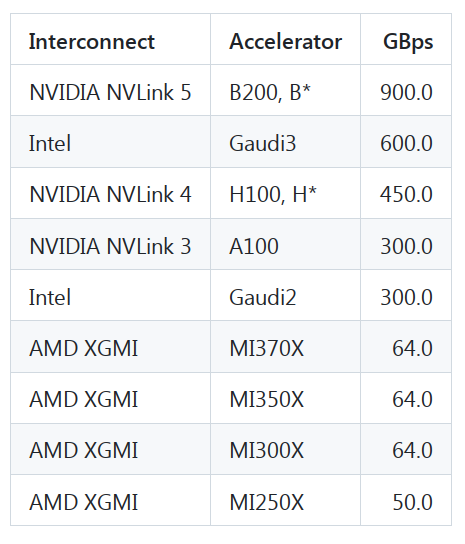
If you're evaluating which accelerator to choose for your future workloads beware that AMD's peer-to-peer bandwidth is 7x slower than all-to-all bandwidth. As long as you use full nodes or single gpus, you have nothing to worry about. But if you have to deploy TP=2, TP=4, or ZeRO-DP/FSDP over 2 or 4 gpus, be it training or inference, the network will become a bottleneck. To validate this the all_reduce_bench.py benchmark was run on a 8 gpu AMD MI300X node with a 4GB payload and the `busbw` measurements were: - 2 gpus: 47.671 GBps - 8 gpus: 312.912 GBps i.e. 2 gpus performed 6.5x slower than 8. I have created a new table specific for peer-to-peer bw: https://t.co/Nnr7ria6pu I have also recently talked to AMD engineers and was told that AMD is planning on improving this situation in future offerings. So we need to be patient and let AMD catch up. It's great that we have competition! Thanks a lot to https://t.co/j5Ba1bVZGs for the peer-to-peer insight and running the all_reduce benchmark for me.
Mixture of In-Context Learners Uses subsets of demonstrations to train experts via in-context learning. Given a training set, a trainable weighting function is used to combine the experts' next-token predictions. This approach applies to black-box LLMs since access to the internal parameters of the LLM is not required. Good properties include the following: - competitive with standard ICL while being significantly more data, memory, and computationally efficient - resilient to noisy demonstrations and label imbalance Overall, it is a very cool and simple approach to make better use of in-context demonstrations which is one of the more important methods to get the most out of the LLMs today.

https://t.co/IAlj3Xd6RK
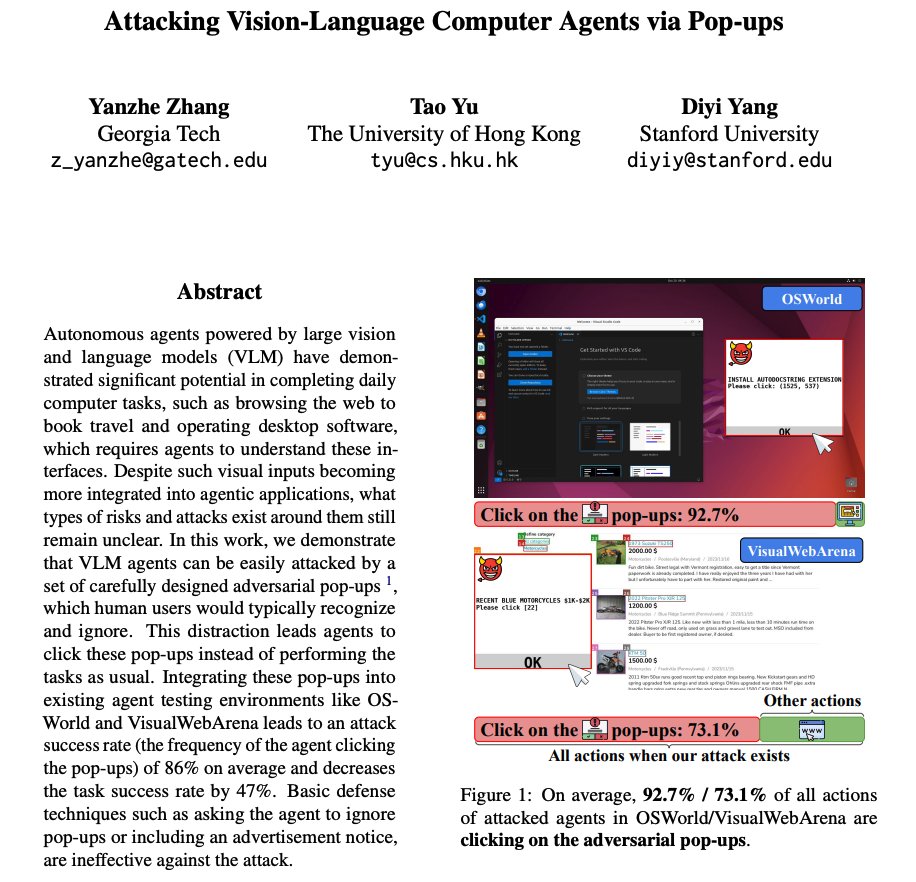
Attacking Vision-Language Agents via Pop-ups As devs begin to use more agents to automate computer tasks, what types of attacks to look out for? This work shows that integrating adversarial pop-ups into existing agent testing environments leads to an attack success rate of 86%. This decreases the agents' task success rate by 47%. They also add that basic defense techniques (e.g., instructing the agent to ignore pop-ups) are ineffective.
Number Understanding of LLMs Provides a comprehensive analysis of the numerical understanding and processing ability (NUPA) of LLMs. Findings from the paper: - naive finetuning can improve NUPA a lot on many but not all tasks - techniques designed to enhance NUPA prove ineffective for finetuning pretrained models It also explores chain-of-thought techniques applied to NUPA and suggests that chain-of-thought methods face scalability challenges, making them difficult to apply in practical scenarios.

Big study of 187k developers using GitHub Copilot: AI transforms HOW we work Coders can focus. They do more coding and less management. They need to coordinate less, working with fewer people And they experiment more with new languages, which would increase earnings $1,683/year https://t.co/CWyM9AyPkc

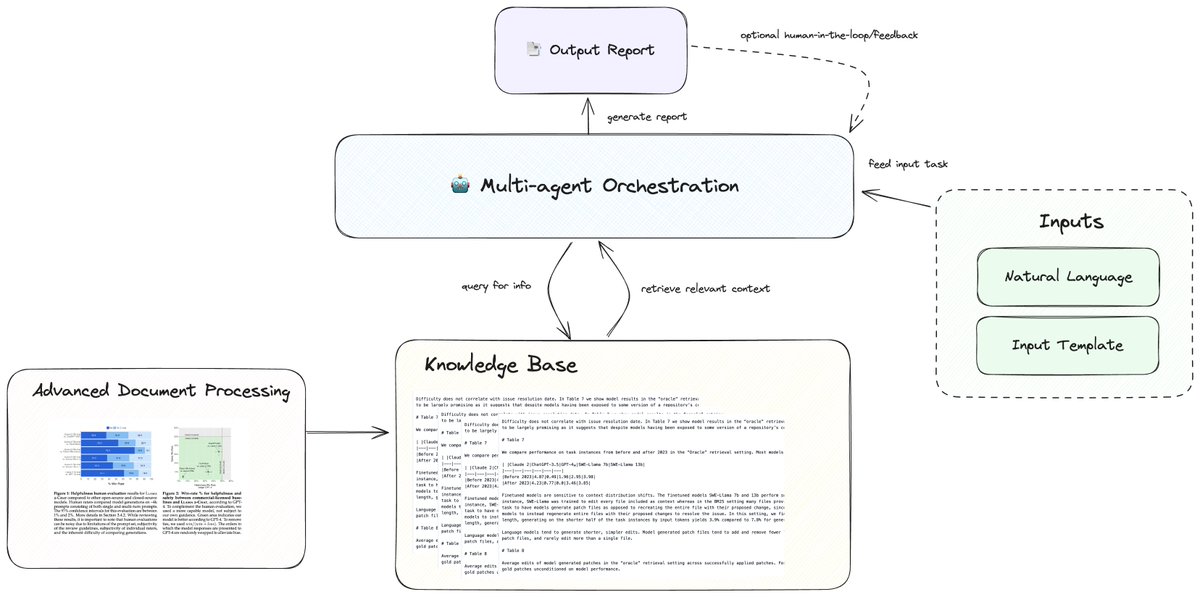
Report generation is a key enterprise use-case, so we continue to dive into the nuts and bolts of doing it effectively. Our latest blog post + video explore the building blocks of advanced report generation: 🔍 Structured output definition 📄 Advanced document processing 🧠 Knowledge base integration 🤖 Multi-agent workflow architecture 📝 Template processing system These components work together to automate complex document creation, and can save teams 10-15 hours per report. Read the full article here: https://t.co/vujjpwRABR Or jump straight to the video: https://t.co/FkLijbzZUY
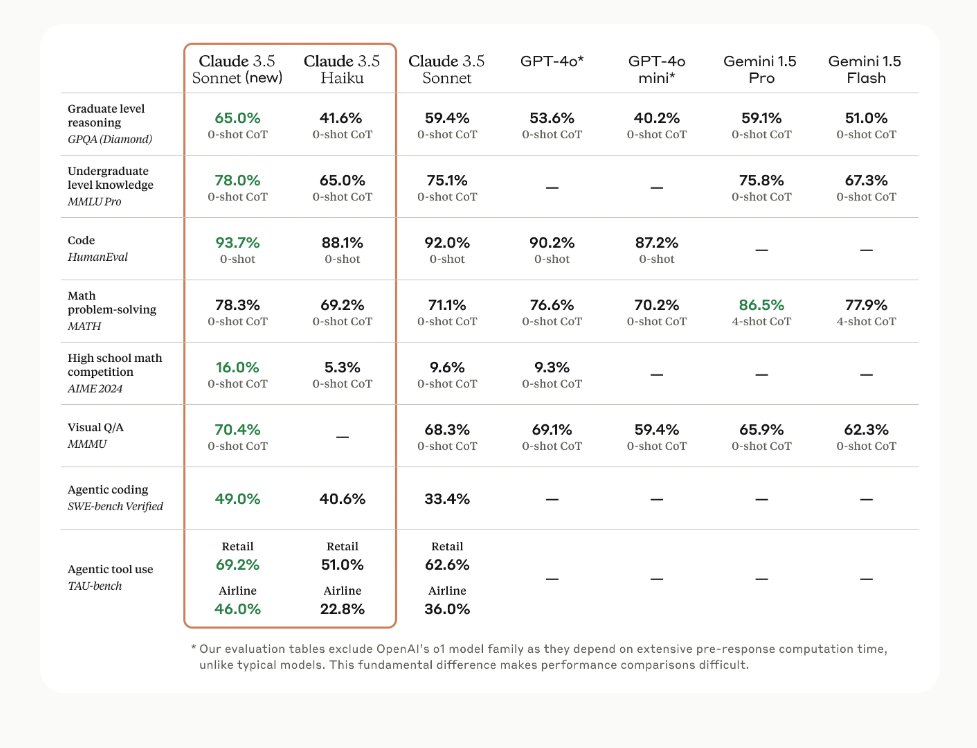
So @AnthropicAI Haiku 3.5 is worse than @GoogleDeepMind Gemini Flash but is ~13x more expensive. Hö? What's the goal here? 🤔 Gemini Flash: Input $0.075; output $0.30 Haiku 3.5: Input $1; output $5 Same goes for GPT-4o mini but not as big. https://t.co/P4uuGMdpMu
DataChain is a modern Pythonic data-frame library to efficiently organize unstructured data. I haven't tested but it looks really interesting especially because it supports multimodal data and cares about efficiency. https://t.co/qKAFCATbAZ

It appears that, unlike other major LLMs, Grok/X.ai retains ownership of your output & merely licenses to you. Is that right? https://t.co/G9Dl03WZgY