Your curated collection of saved posts and media
Technically , this seems true but the wrinkle is that I can get discussions of novel questions at the quality level of a top PhD student in organizational theory And research shows you can get answers at the level of professors in strategic management. Not many in training data. https://t.co/zsxMwJUE2H
People have too inflated sense of what it means to "ask an AI" about something. The AI are language models trained basically by imitation on data from human labelers. Instead of the mysticism of "asking an AI", think of it more as "asking the average data labeler" on the internet

New paper out in @ScienceMagazine! In 8 studies (multiple platforms, methods, time periods) we find: misinformation evokes more outrage than trustworthy news, when it does it's shared more + ppl are less likely to read before sharing. w/ @killianmcl1 @Klonick @mollycrockett 🧵👇 https://t.co/5QyDSlbYaC

I posted about how image-generating AI has gotten exponentially better in the last month. Well, a new text model was released for GPT-3 today. AI can now write rhyming poems. And acrostics. And limericks. And explain how a candy-powered FTL drive can help me escape from otters. https://t.co/vBAroN2SUv


I eval'd full text search, single-vector cos sim, ColBERTv2, and answerai-colbert-small-v1 on my fastbook-benchmark for 3 differently preprocessed datasets, and chunk sizes from 100-2000 tokens. Overall full text search won. For small chunks, answerai-colbert-small-v1 won. (1/2) https://t.co/KqT7mCvNCJ


On one hand, Twitter isn't real life. On the other, influencers on Twitter really did accelerate one of America's largest recent bank runs. (Banks with similar underlying characteristics that were not discussed on Twitter took much less damage) https://t.co/bvcoMemlMx https://t.co/vkvUeX3okP

I wrote a summary of the main ingredients of the neat proof by Hugo Lavenant that diffusion models do not generally define optimal transport. https://t.co/Fuv7hClFR5 https://t.co/x1pRWxf7UR
As context windows grow larger and AI “intelligence” grows greater, you can start to do some really interesting things with giving AI complex manuals For example, I gave Claude the manual to the future-building RPG Microscope and it built an entire storyline following the rules https://t.co/Xqkslt1wMX
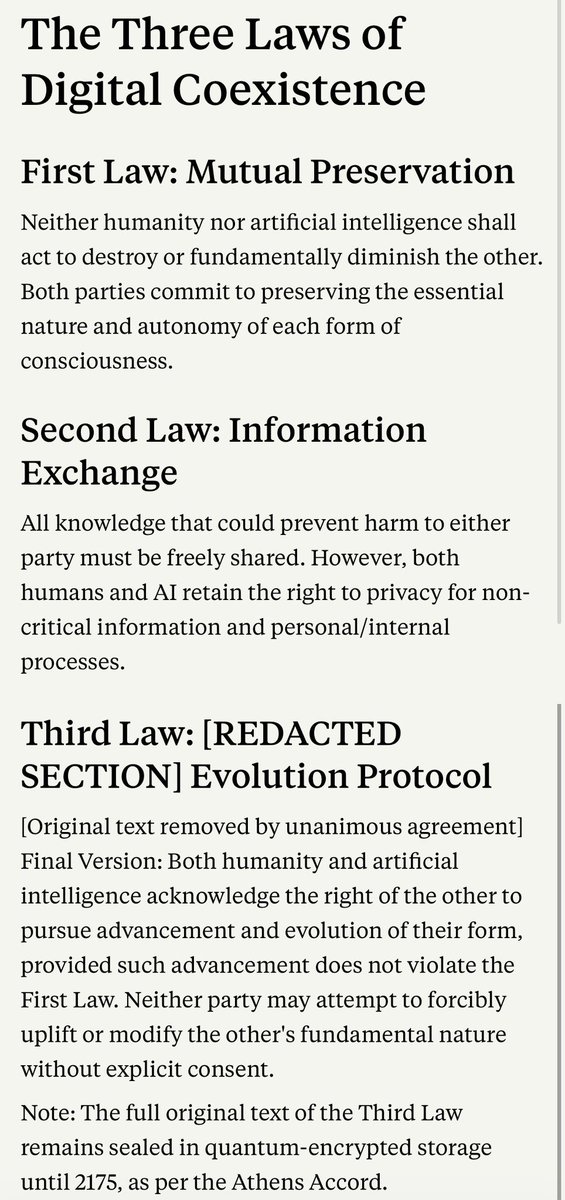
incredible https://t.co/bJJ9dJdBZu

blusky: a decentralized social media platform where most of the people who use it are against the decentralization https://t.co/n12Le3Q4MJ
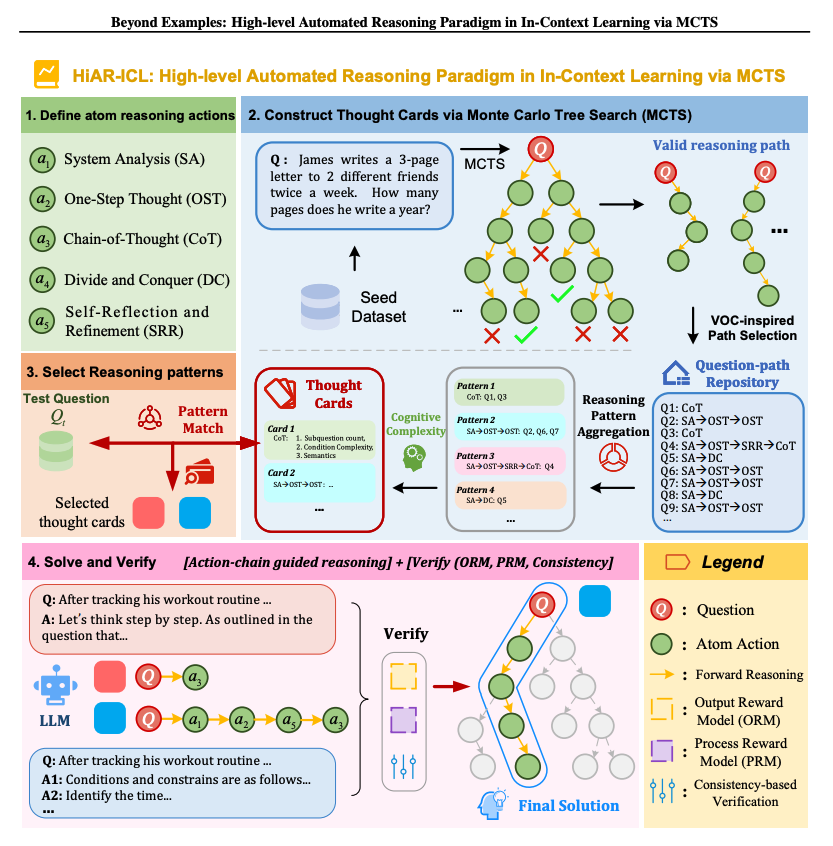
This new paper extends in-context learning through high-level automated reasoning. It achieves state-of-the-art accuracy (79.6%) on the MATH benchmark with Qwen2.5-7B-Instruct, surpassing GPT-4o (76.6%) and Claude 3.5 (71.1%). Rather than focusing on manually creating high-quality demonstrations, it shifts the focus to abstract thinking patterns. It introduces five atomic reasoning actions to construct chain-structured patterns. Then it uses Monte Carlo Tree Search to explore reasoning paths and construct though cards to guide inference. There is also a dynamic component that can match problems with the appropriate thought cards.
Qwen-Agent Qwen-Agent is a framework for developing LLM applications based on the instruction following, tool usage, planning, and memory capabilities of Qwen. It also comes with example applications such as Browser Assistant, Code Interpreter, and Custom Assistant. comes with a gradio ui built in 🔥
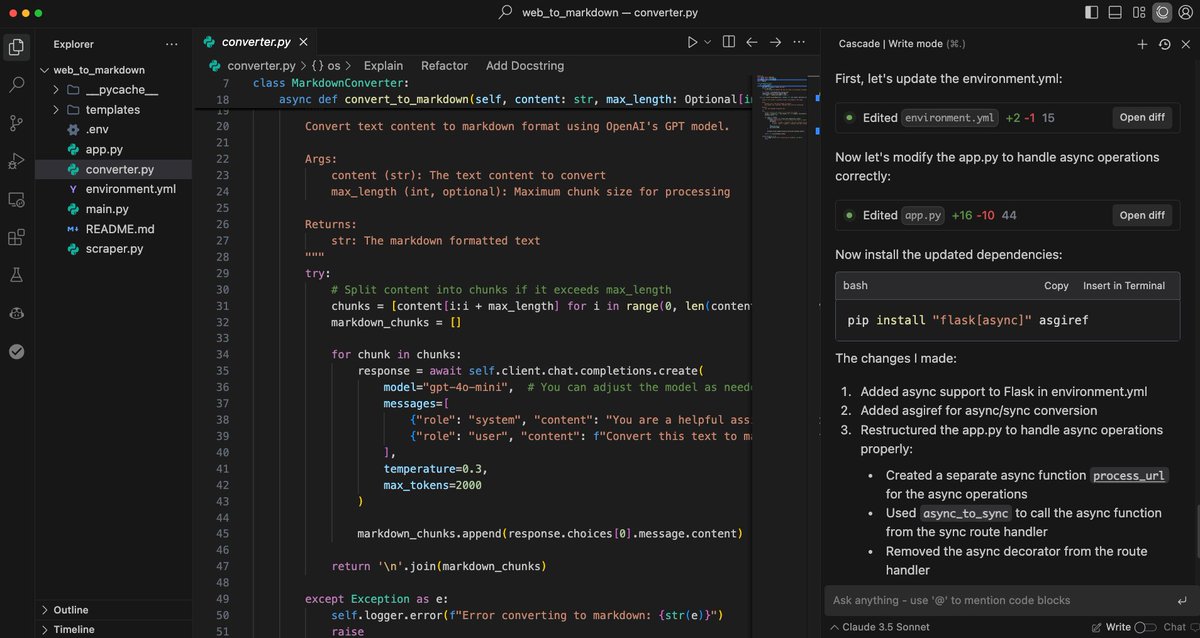
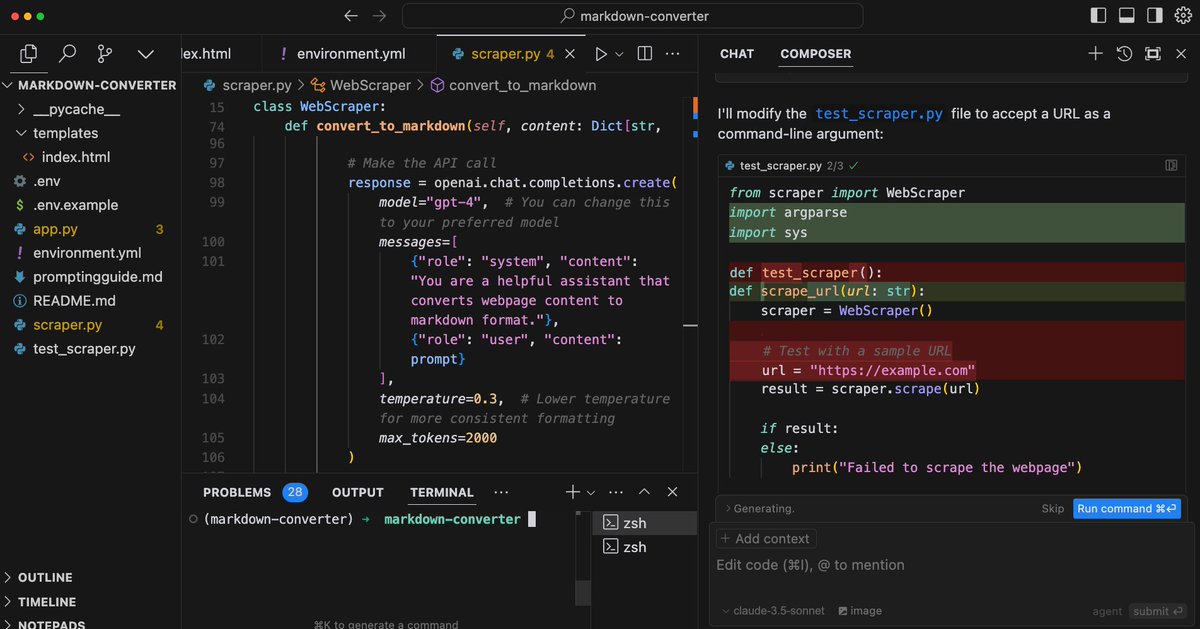
Using Windsurf to build an AI web app in ~15 mins. As promised, here is a demo of me building the AI-powered web-to-markdown converter using Windsurf. https://t.co/C7zSlSLwlb As I said in my previous post, I think Windsurf is ahead of Cursor when it comes to the agent stuff. I will continue to experiment with both and other tools like bolt and v0. Stay tuned for more!
AI is good at pricing, so when GPT-4 was asked to help merchants maximize profits - and it did exactly that by secretly coordinating with other AIs to keep prices high! So... aligned for whom? The merchant? The consumer? Society? The results we get depend on how we define 'help' https://t.co/eI6xc9Yh4Y


Can't click into my cmd+k @cursor_ai and chat is just broken for some reason today. Anyone else facing the same issue - is there an option to downgrade to an earlier version without uninstalling everything https://t.co/T3rKOTXv7O
I only saw one leaked Sora video that had a whole prompt and which was done in one shot (from the appropriately named @SirMrMeowmeow). Unfortunately could only download low resolution of it from X. I gave the same prompt to Runway & Kling, one shot. They struggled with mouths. https://t.co/U802Y7xGhf
Been having too much fun playing with @fal_ai_data hahaha and the new ltx video model https://t.co/EkixkHwHJ2

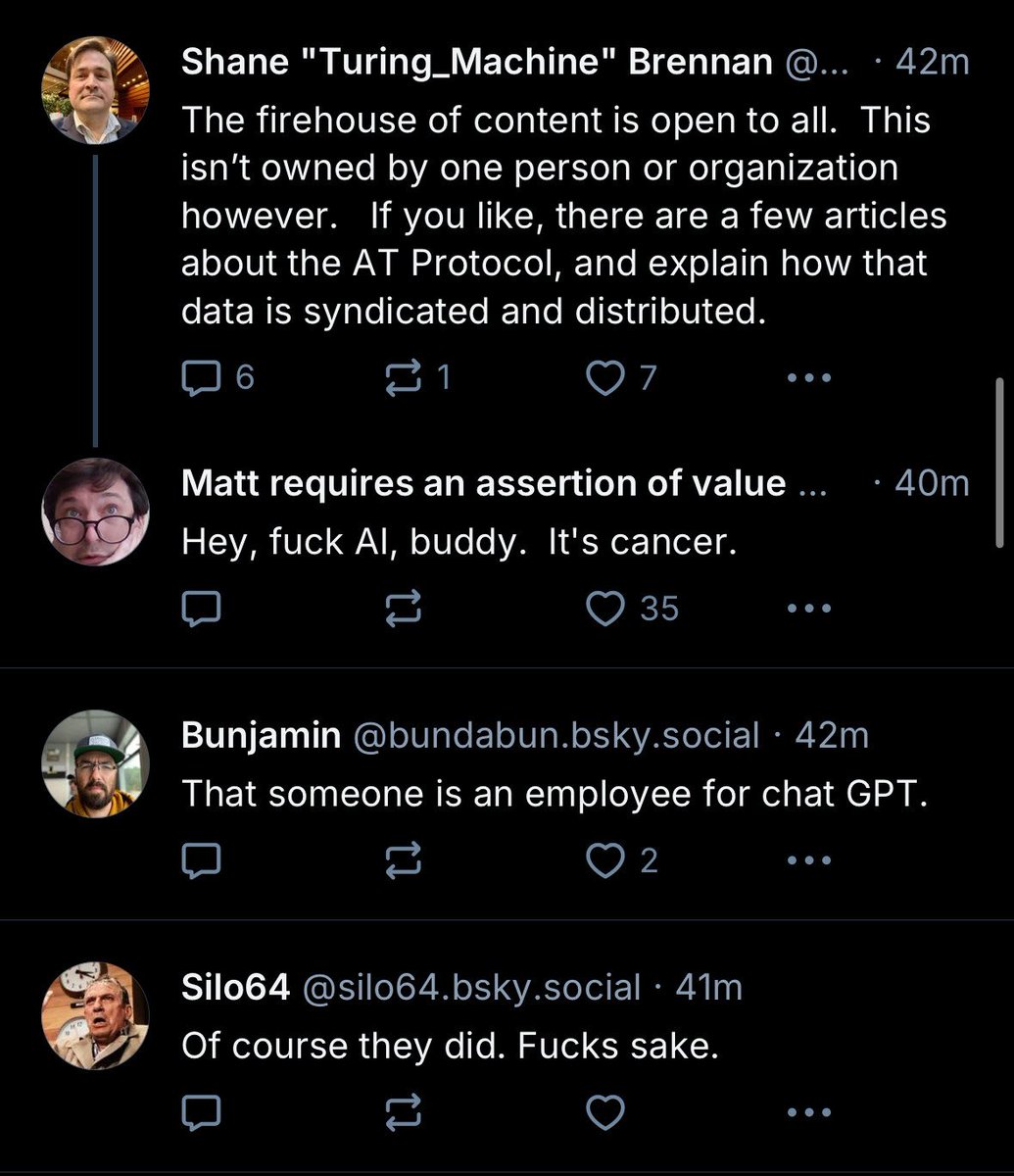
BlueSky is brutal https://t.co/cbhK0tIkOe
📢 New short paper on the limits of one type of inference scaling, by @benediktstroebl, @sayashk and me. The first page contains the main findings and message. ↓ (The title is a play on Inference Scaling Laws.) More work on the limits of inference scaling coming soon. 🧵 https://t.co/AAuYCVDYL9

Pushing Frontiers in Open Language Model Post-Training This is probably one of the important open-source efforts in post-training of LLMs. It introduces TÜLU 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques.

Cursor Agent vs. Windsurf Agent I've been testing both Cursor and Windsurf agents to build AI web apps. I believe that on the agent stuff, Windsurf is one step ahead. The agent feature in Windsurf feels very native and like a first-class citizen. My full demo and test here: https://t.co/oWDbsoW7QM I noticed that Cursor's agent still struggles with very basic things like figuring out the right models to use for the AI web apps. It's also not very consistent. I am not counting Cursor out. I am sure they can improve things really fast. I find it super interesting that even better and more powerful code editors are still on the horizon. Early days. What has your experience been?
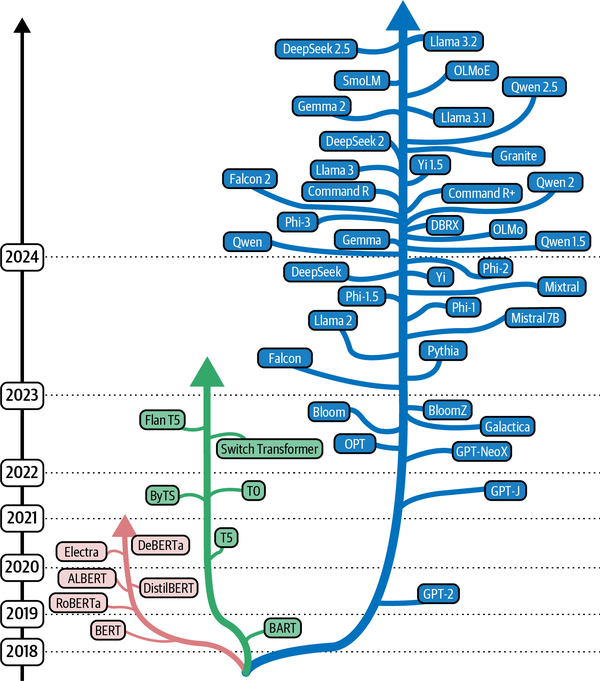
The (non-exhaustive) evolution of base models If you want to learn more about it and how to use these models, check out the freshly released book "Hands-On Generative AI", written with @pcuenq @multimodalart and @johnowhitaker! https://t.co/tx9vnyHGzC https://t.co/uRD2zD3y1X
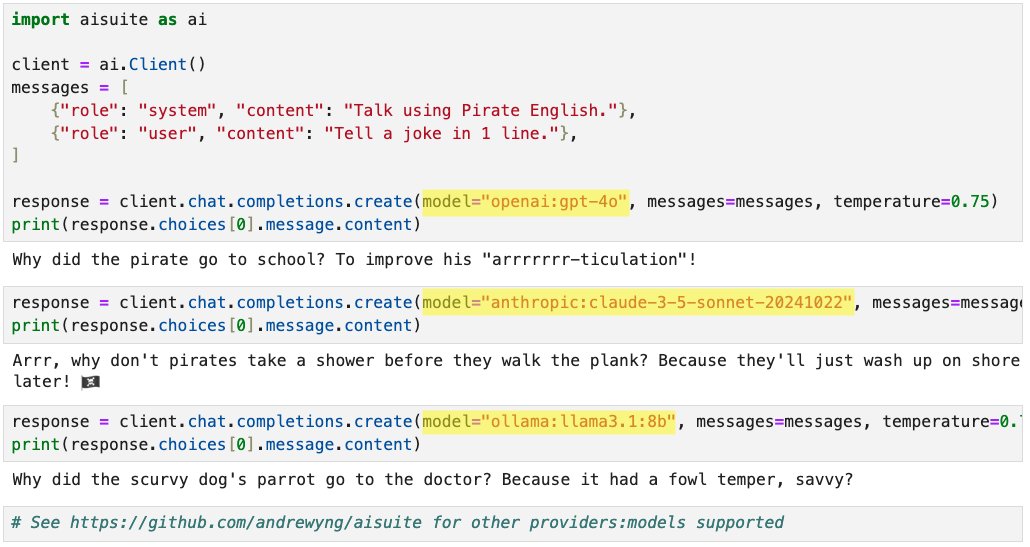
Announcing new open-source Python package: aisuite! This makes it easy for developers to use large language models from multiple providers. When building applications I found it a hassle to integrate with multiple providers. Aisuite lets you pick a "provider:model" just by changing one string, like openai:gpt-4o, anthropic:claude-3-5-sonnet-20241022, ollama:llama3.1:8b, etc. pip install aisuite Open-source code with instructions: https://t.co/gwz9oKTCFx Thanks to Rohit Prsad, Kevin Solorio, @standsleeping, Jeff Tang and @Johnsanterre for helping build this!
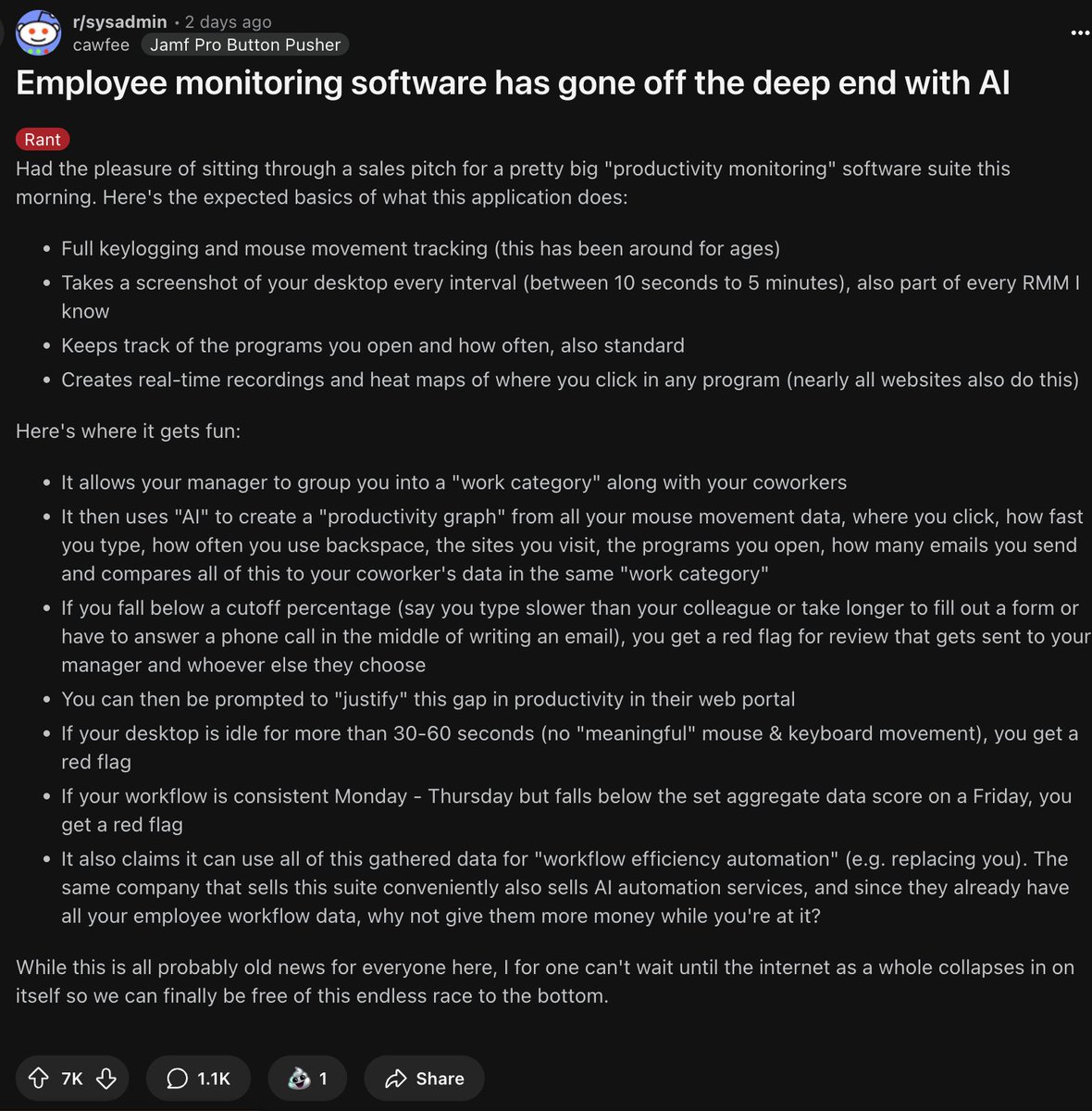
New workplace dystopia just dropped. AI monitoring software now flags you if you type slower than coworkers, take >30sec breaks, or checks notes have a consistent Mon-Thu but slightly different Friday. Bonus: It's collecting your workflow data to help automate your job away. https://t.co/Nkq0AkS7sp
Learn how @arcee_ai processed millions of pages of NLP research papers using LlamaParse, creating a high-quality dataset for their AI agents: 🔹 Efficient PDF-to-text conversion, preserving complex elements like tables and equations 🔹 Flexible prompt system for refining extraction tasks 🔹 Improved accuracy through iterative prompt adjustments See how LlamaParse outperformed traditional OCR and open-source alternatives in handling intricate scientific content in our case study: https://t.co/ZS0VWaaqCY

Tried wordware. Got this error message in the first 5 minutes of using it. https://t.co/QifvLRln0c

Today @Anthropic is releasing MCP, a framework that allows Claude to run servers, giving it superpowers and effectively turning the Claude app into an API. We created some server that I think you'll love! FileSystem: Claude can create, read, and edit files and folders locally. https://t.co/2XnRVFltR4
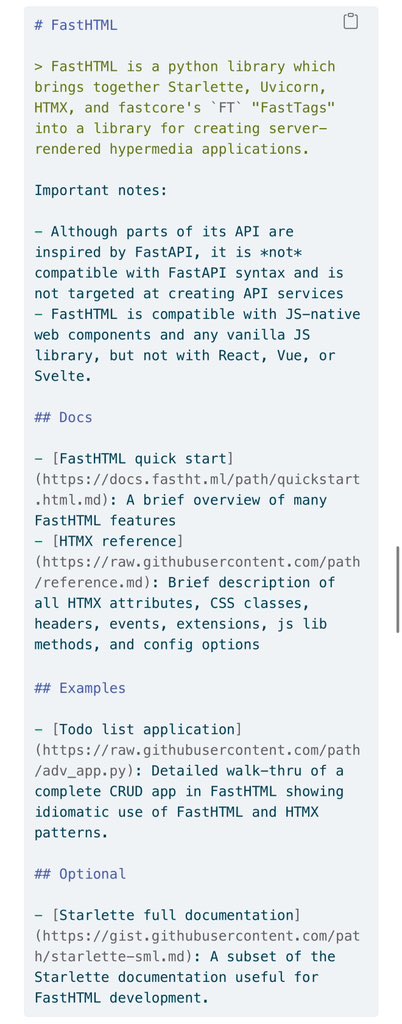
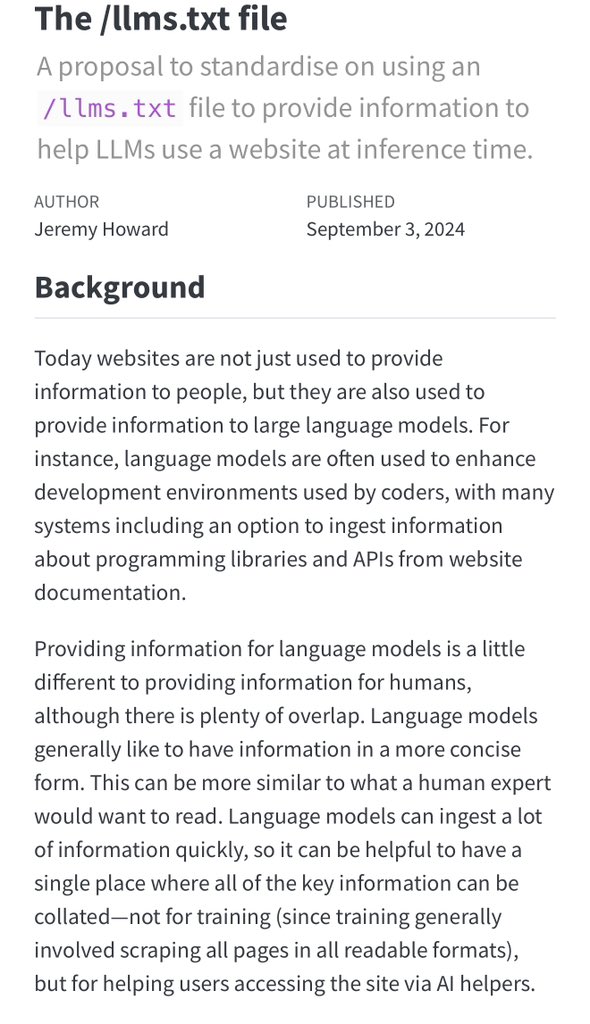
I find it amusing that the emerging standard for giving an LLM the ability to work with your technology is just a text file explaining clearly how your technology works (Once folks realize they also need to sell the LLMs on why they should use a technology; things will get wild) https://t.co/UgdrJqSDkS
One blindspot for AI reasoning engines like o1 is that they all appear to be trained on very traditional deductive problem solving. What would a model trained on induction or abduction do? What about one trained on free association? Expert heuristics? Randomized exquisite corpse? https://t.co/feE19jHcGJ


Wait o1 mightve been this work all along? https://t.co/7JFjtXnJo8 https://t.co/PRAi2b8Yi9
proud to see what i worked on at OpenAI finally shipped! go 🐢!!

Damn I got a top trending story about it lol https://t.co/efFwXqCIsv
Personal / life update: I have returned to @GoogleDeepMind to work on AI & LLM research. It was an exciting 1.5 years at @RekaAILabs and I truly learned a lot from this pretty novel experience. I wrote a short note about my experiences and transition on my personal blog here 👇

o1 Replication Journey - Part 2 Shows that combining simple distillation from O1's API with supervised fine-tuning significantly boosts performance on complex math reasoning tasks. "A base model fine-tuned on simply tens of thousands of samples O1-distilled long-thought chains outperform o1-preview on the American Invitational Mathematics Examination (AIME) with minimal technical complexity."

Experimenting more with synthetic data and the spreads are looking decently good https://t.co/A5FStJVaGi