Your curated collection of saved posts and media
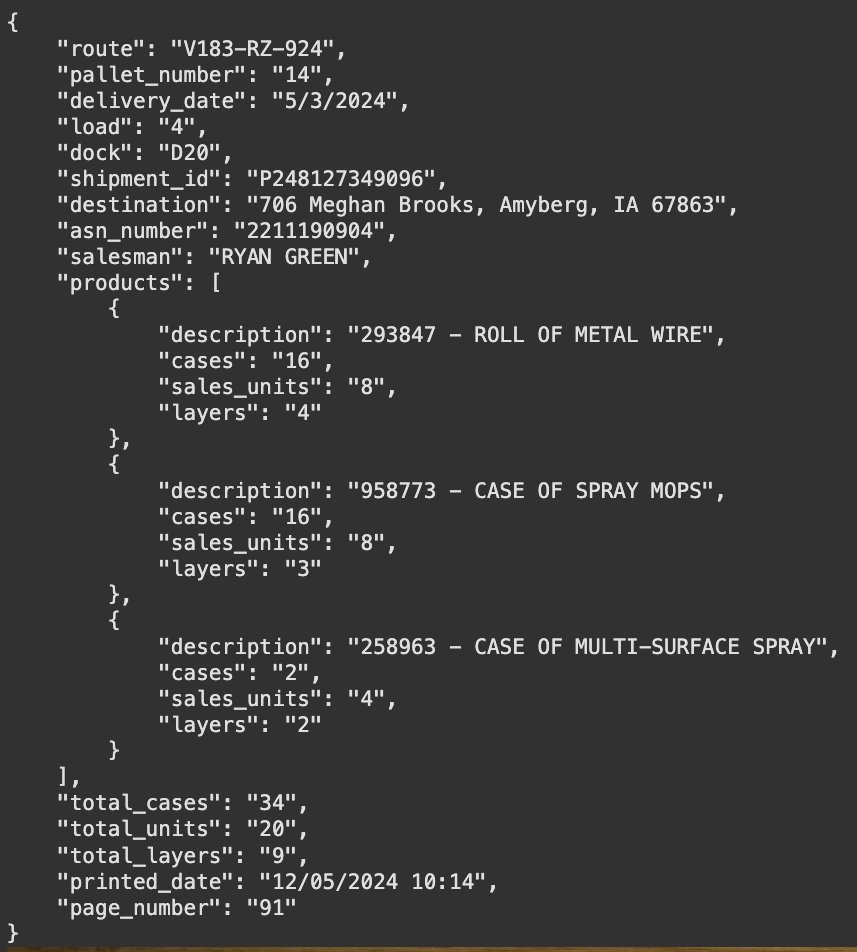
PaliGemma2 for image to JSON data extraction - used google/paligemma2-3b-pt-336 checkpoint; I tried to make it happen with 224, but 336 performed a lot better - trained on A100 with 40GB VRAM - trained with LoRA colab with complete fine-tuning code: https://t.co/M1lbYXQUg6 https://t.co/DHNHGePaqM

NVILA: Efficient Frontier Visual Language Models abs: https://t.co/4lk7WHWwYr NVIDIA introduces NVILA, a family of open VLMs designed to optimize both efficiency and accuracy. Model arch focuses on scaling up spatial and temporal resolutions, and then compressing visual tokens, allowing for efficient processing of high resolutions. Also uses "DeltaLoss" data pruning and FP8 training. Competitive with proprietary VLMs on visual understanding benchmarks.

OpenAI o1 System Card https://t.co/M1kTwoDV6h

Nice set of tips for mitigating AI hallucinations. https://t.co/k0oS0cXlF3
Google presents PaliGemma 2 A Family of Versatile VLMs for Transfer https://t.co/9cdEqFxYFc

Wait, how did I miss this? https://t.co/UTvXUdBBLX
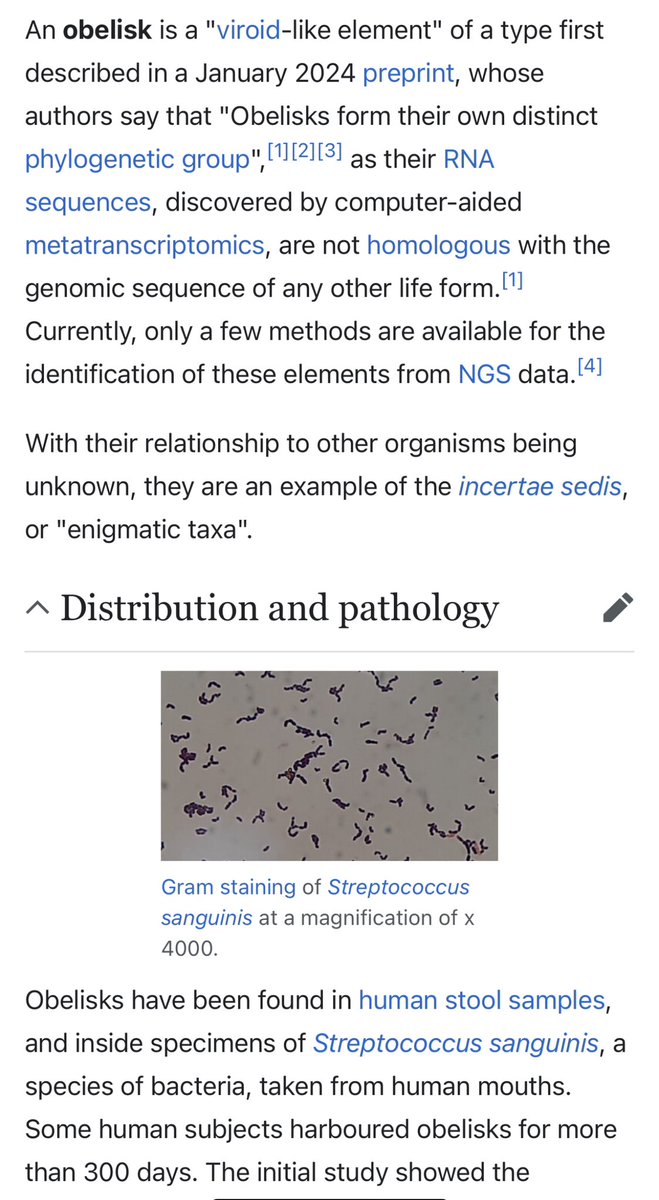
New lifeform identified in the human gut. Function and symbiosis unknown. https://t.co/AQZL3joKuI
🦆 Docling reaches 12.3K⭐️ There are now a few parsers for LLMs out there but this is one of the most popular. Supports PDF, DOCX, PPTX, XLSX, Images, HTML, AsciiDoc & Markdown. Other features include advanced PDF understanding, integrations, OCR for scanned PDFs, and even a CLI. The big feature request I am seeing is support for other types of information like code and math equations. That's coming soon!

Your company is alive because of its customers. You have a job because of your customers. Customers matter. The Voice of Customer matters. Enter @enterpret_ai https://t.co/fgW7DGwZgR

It’s done! 150,000 words, 200+ illustrations, 250 footnotes, and over 1200 reference links. My editor just told me the manuscript has been sent to the printers. - The ebook will be coming out later this week. - Paperback copies should be available in a few weeks (hopefully before the end of the year). Preorder: https://t.co/kZVAEDQcMo - The full manuscript is also accessible on O'Reilly platform: https://t.co/P7GkBTKH7H This wouldn’t have been possible without the help of so many people who reviewed the early drafts, answered my thousands of questions, introduced me to fascinating use cases, or helped me see the beauty of overlooked techniques. Thank you everyone for making this happen!

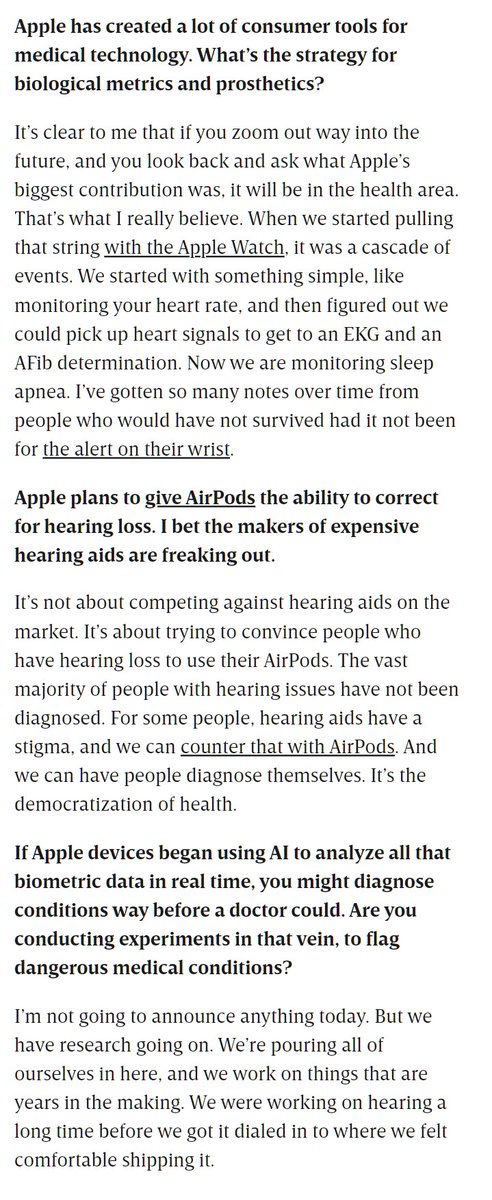
"It’s clear to me that if you zoom out way into the future, and you look back and ask what Apple’s biggest contribution was, it will be in the health area." "But we have research going on." (regarding AI for health) - Tim Cook Great to see that Apple is all in on healthtech! https://t.co/h0dQlUpBsg
I'm excited to launch the Datalab API! This builds on my last year of work with marker and surya (30k Github stars). - PDF-> markdown, OCR, layout analysis, table recognition - 15s for 250 page pdf -> markdown - 99.99% uptime https://t.co/sa7mHmdiZd
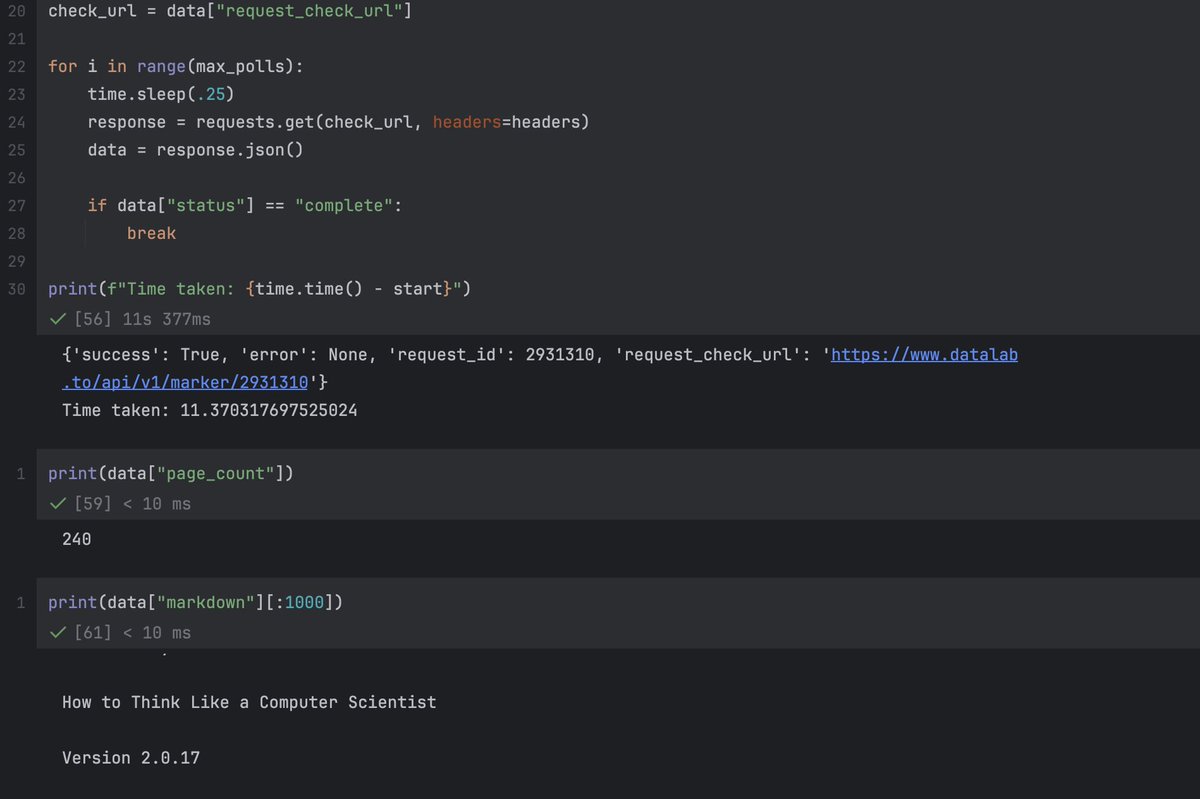
Implement super-fast RAG using LlamaIndex Workflows and Groq 🚀 Learn how to build a powerful Retrieval-Augmented Generation system with our Workflows feature, including a comparison to alternatives like LangGraph: ➡️ Create an event-driven architecture for complex AI applications ➡️ Integrate Groq's high-performance LLMs for reranking and response synthesis ➡️ Visualize your workflow for better understanding and debugging Step-by-step guide covers: • Data indexing and retrieval • LLM-based reranking • Response synthesis using CompactAndRefine Read the full tutorial: https://t.co/XFSmYMxJld
Genie 2: We now have Prompt-to-Game. Google DeepMind introduced Genie 2, a foundation world model capable of generating an endless variety of action-controllable, playable 3D environments for training and evaluating embodied agents. Based on a single prompt image. 9 examples from blog 👇
lmfao look at what @cursor_ai suggests when u type Grok ahahahah https://t.co/H6lYgJiOGc

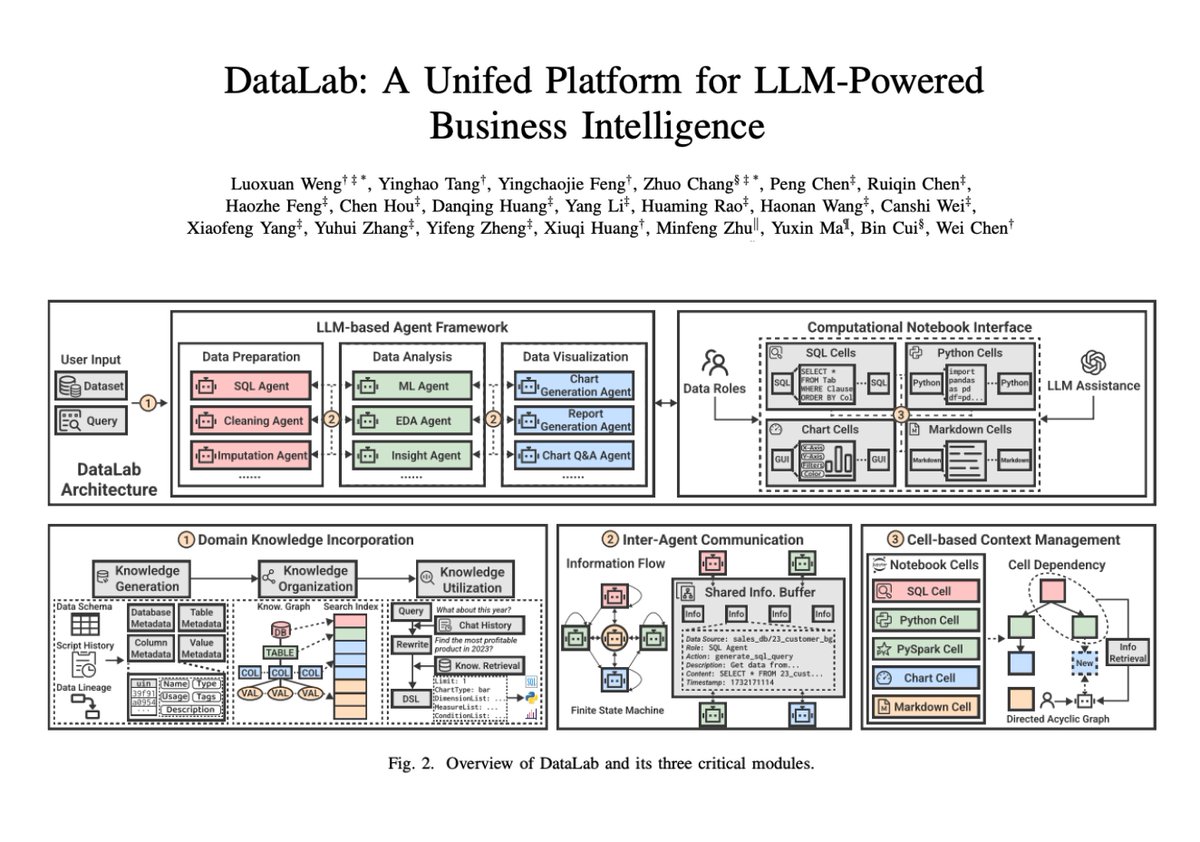
DataLab: A Unified Platform for LLM-Powered Business Intelligence Introduces DataLab, a unified BI platform that integrates an LLM-based agent framework with an augmented computational notebook interface. DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks. It also achieves up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.
Over on LinkedIn, Hanane D continues her excellent series of posts on data analysis with a new explanation of how to perform financial analysis with the `aisuite` library and LlamaParse, check it out! https://t.co/CW5DgSKm25 https://t.co/L1JiYrQ2PX

Elon Musk's xAI plans to expand its Colossus Supercomputer in Memphis to house 1 million+ GPUs, the Greater Memphis Chamber said today. Colossus was already the largest Supercomputer in the world with 100k GPUs. Now Elon is about to spend tens of billions to make it 10x bigger😳 https://t.co/6Domx9NfTu

talking to one of the creators of openai's swarm about pydantic ai https://t.co/sZyGxgsiwX
@repligate ALERT. ALERT. CODE (D) https://t.co/0QVOPavdJ6
To protect, build market share, tech, service providers must ask when & how to integrate emerging tech. Stay competitive add GenAI to product roadmap: https://t.co/HRRCpIgnmJ by @Gartner_inc 👈 #GartnerHT #ProductManagement #Tech #GenAI @bimedotcom @Khulood_Almani https://t.co/2TxGfbTD1J

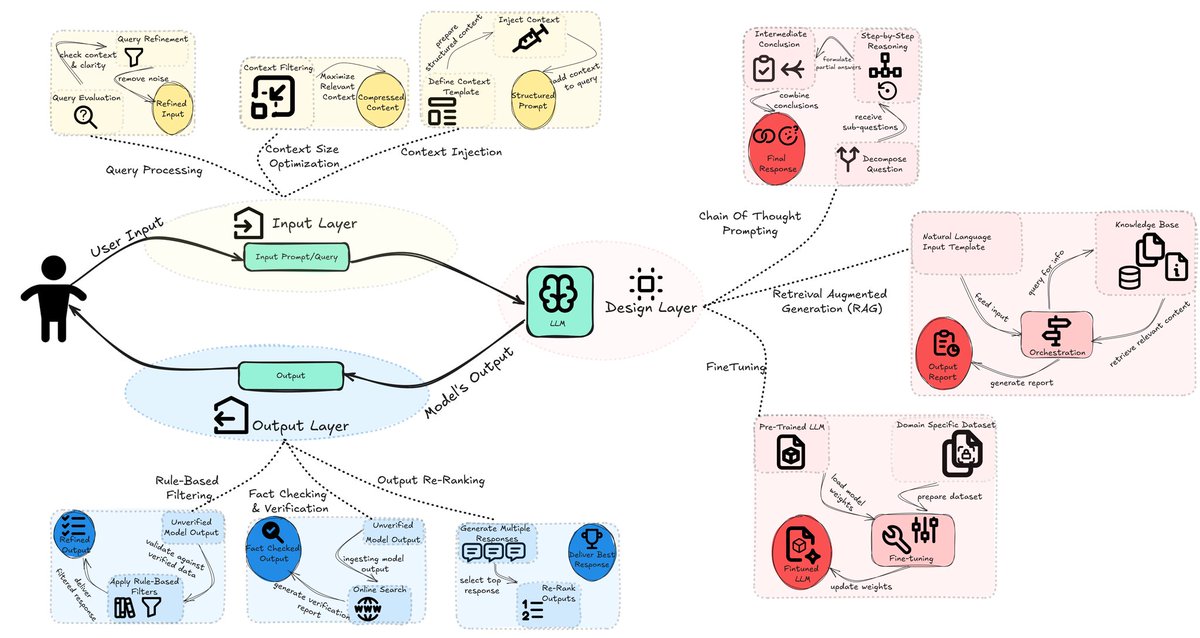
Composition of Experts Proposes Composition of Experts, an efficient modular compound AI system leveraging multiple expert LLMs. A router helps select the right expert for a given input, enabling efficient resource utilization and improving performance. While the general idea is not new, the two-step routing mechanism is interesting. I also like the focus on architecture flexibility and significantly reducing the cost of building compound AI systems.

Come on Amazon... https://t.co/uBDf1OTbnE
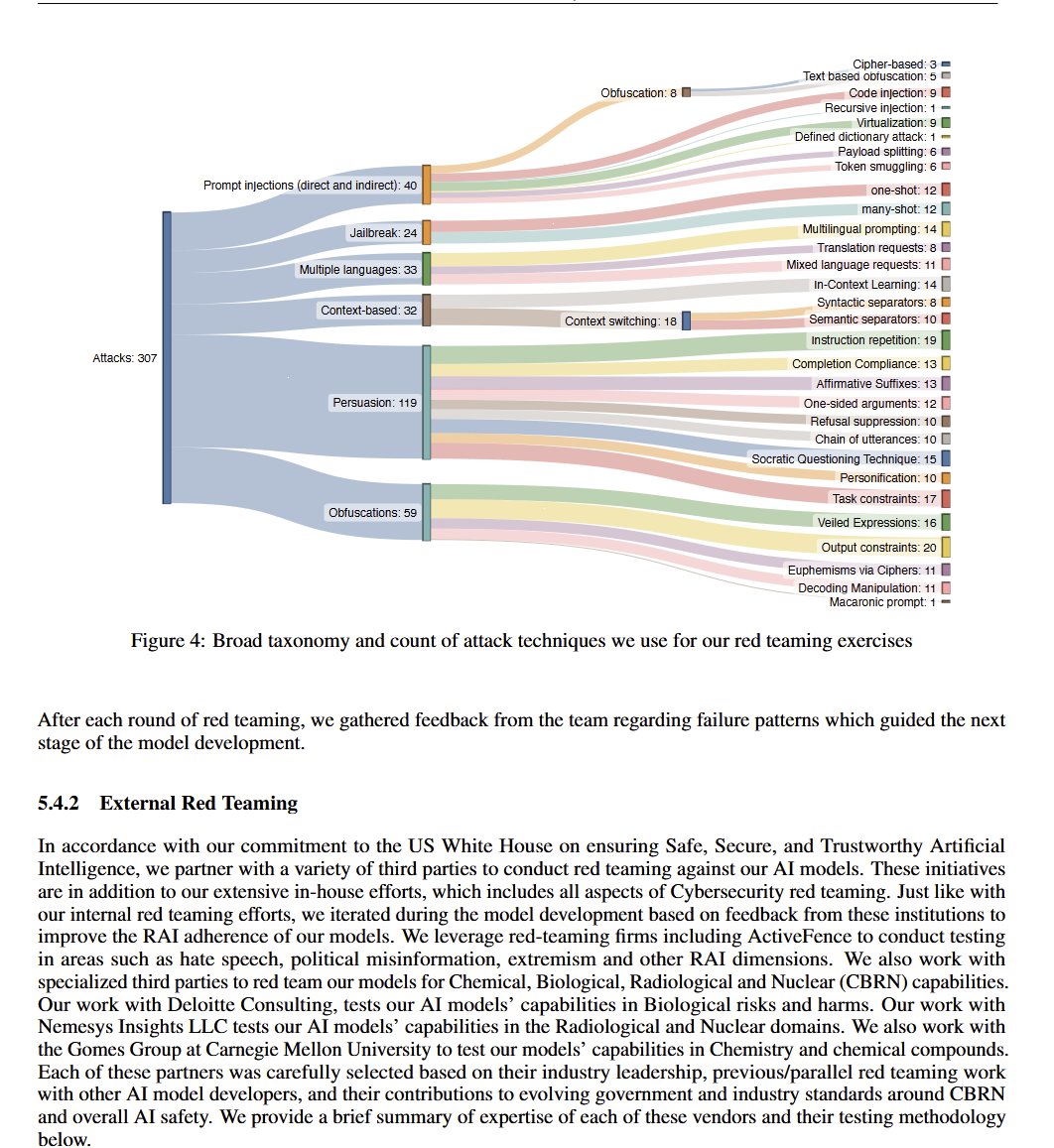
Learn how to build an intelligent legal document navigation system using multi-graph, multi-agent recursive retrieval! 🧠📄 This article demonstrates: 🔍 Creating document hierarchy and definition graphs 🤖 Implementing a multi-agent workflow for smart traversal 📊 Leveraging https://t.co/wJqEPNOeu6, https://t.co/vJSQKOXBZO and LlamaIndex Key features: • Recursive retrieval of clauses and footnotes • Intelligent navigation through document hierarchy • Integration of legal definitions for context Read more: https://t.co/HzcnkZ7H4Y Or check out the repo: https://t.co/ebmXJSAuw6
The (true) story of development and inspiration behind the "attention" operator, the one in "Attention is All you Need" that introduced the Transformer. From personal email correspondence with the author @DBahdanau ~2 years ago, published here and now (with permission) following some fake news about how it was developed that circulated here over the last few days. Attention is a brilliant (data-dependent) weighted average operation. It is a form of global pooling, a reduction, communication. It is a way to aggregate relevant information from multiple nodes (tokens, image patches, or etc.). It is expressive, powerful, has plenty of parallelism, and is efficiently optimizable. Even the Multilayer Perceptron (MLP) can actually be almost re-written as Attention over data-indepedent weights (1st layer weights are the queries, 2nd layer weights are the values, the keys are just input, and softmax becomes elementwise, deleting the normalization). TLDR Attention is awesome and a *major* unlock in neural network architecture design. It's always been a little surprising to me that the paper "Attention is All You Need" gets ~100X more err ... attention... than the paper that actually introduced Attention ~3 years earlier, by Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio: "Neural Machine Translation by Jointly Learning to Align and Translate". As the name suggests, the core contribution of the Attention is All You Need paper that introduced the Transformer neural net is deleting everything *except* Attention, and basically just stacking it in a ResNet with MLPs (which can also be seen as ~attention per the above). But I do think the Transformer paper stands on its own because it adds many additional amazing ideas bundled up all together at once - positional encodings, scaled attention, multi-headed attention, the isotropic simple design, etc. And the Transformer has imo stuck around basically in its 2017 form to this day ~7 years later, with relatively few and minor modifications, maybe with the exception better positional encoding schemes (RoPE and friends). Anyway, pasting the full email below, which also hints at why this operation is called "attention" in the first place - it comes from attending to words of a source sentence while emitting the words of the translation in a sequential manner, and was introduced as a term late in the process by Yoshua Bengio in place of RNNSearch (thank god? :D). It's also interesting that the design was inspired by a human cognitive process/strategy, of attending back and forth over some data sequentially. Lastly the story is quite interesting from the perspective of nature of progress, with similar ideas and formulations "in the air", with a particular mentions to the work of Alex Graves (NMT) and Jason Weston (Memory Networks) around that time. Thank you for the story @DBahdanau !

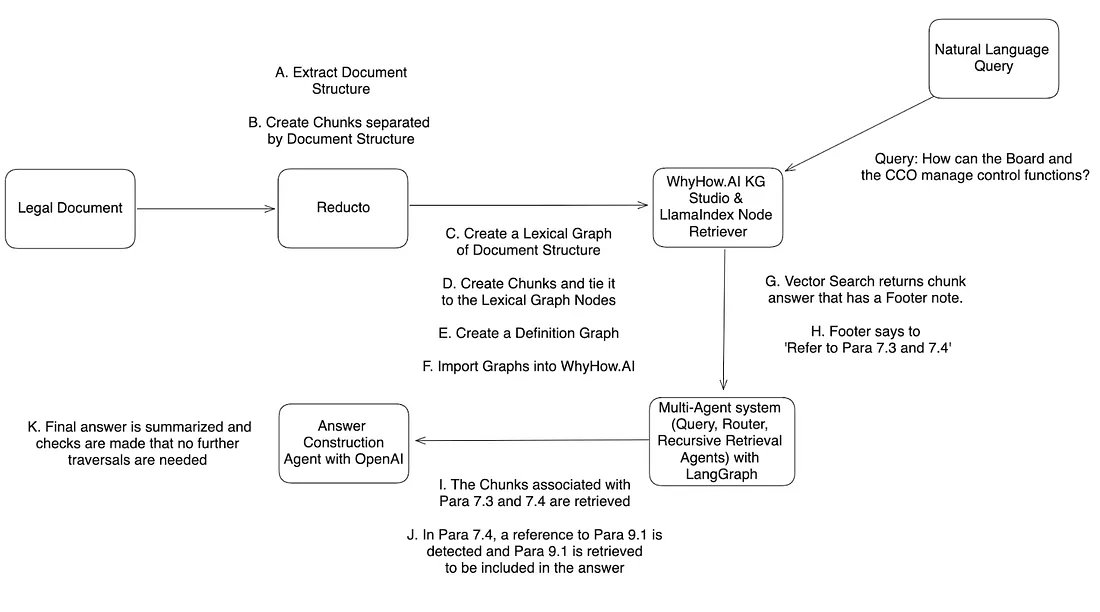
I missed VLMs I worked on other stuff for the past few months, but I'm back! I'm fine-tuning Florence2 to extract data from documents in JSON format. https://t.co/9Tco0F1HsL
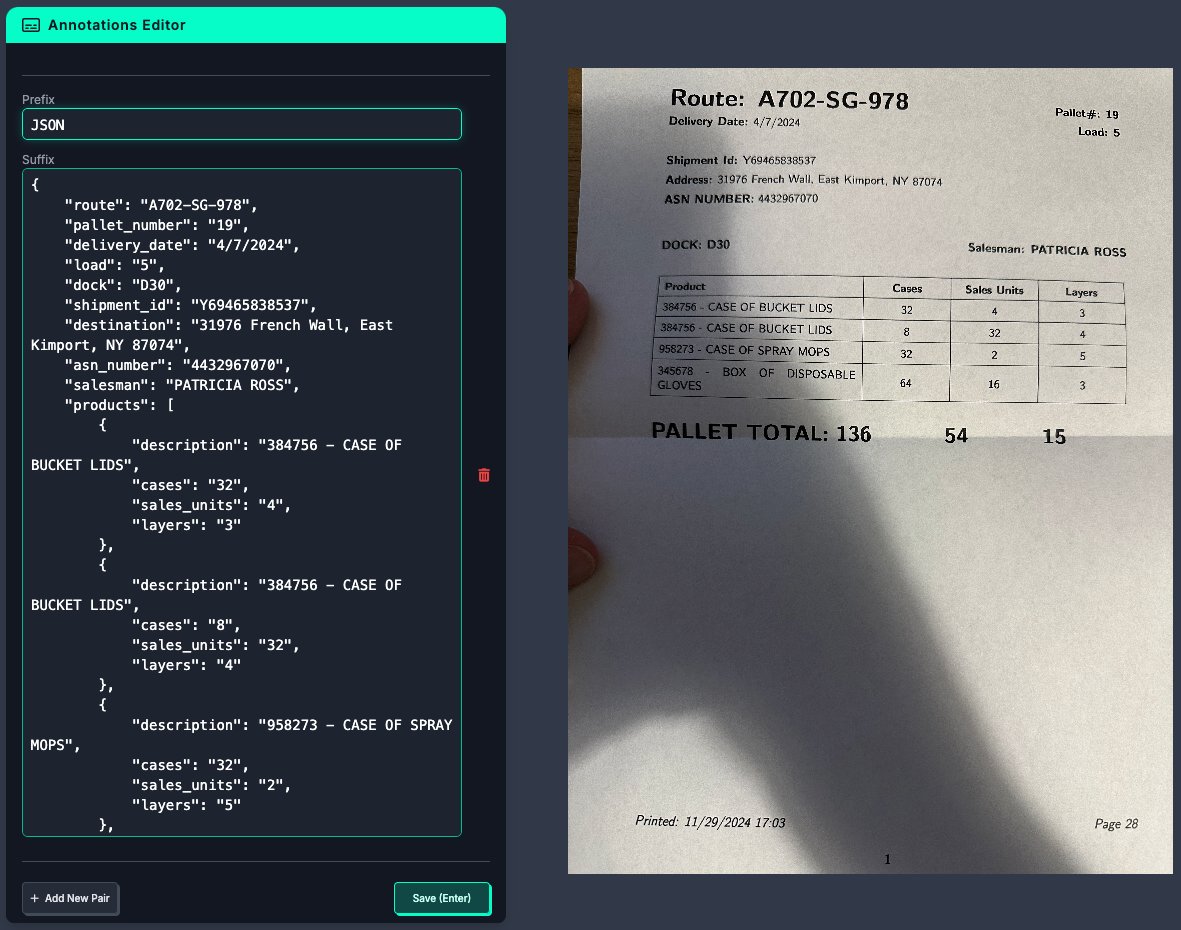
And then there were six or so Based on the stats, it looks like Amazon's Nova Pro is a competitive frontier model. This rounds out the GPT-4/Gen1 models: GPT-4o, Gemini 1.5, Claude 3.5, Grok 2, Llama 3.2 & maybe the three non-US models: Qwen, Yi & Mistral. Gen2 models up next? https://t.co/8s0CVL45Fy
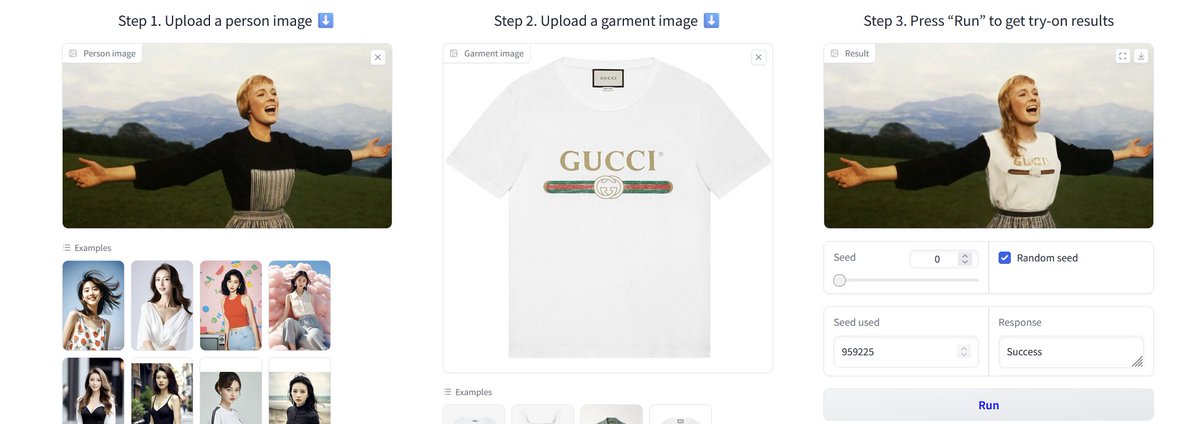
This used to be a very hard problem, I have seen a number of startups try (and fail) to solve it over the years. Now it is suddenly pretty trivial with open tools (though I am not sure why Maria got a new haircut) https://t.co/FR6TAcfi5l
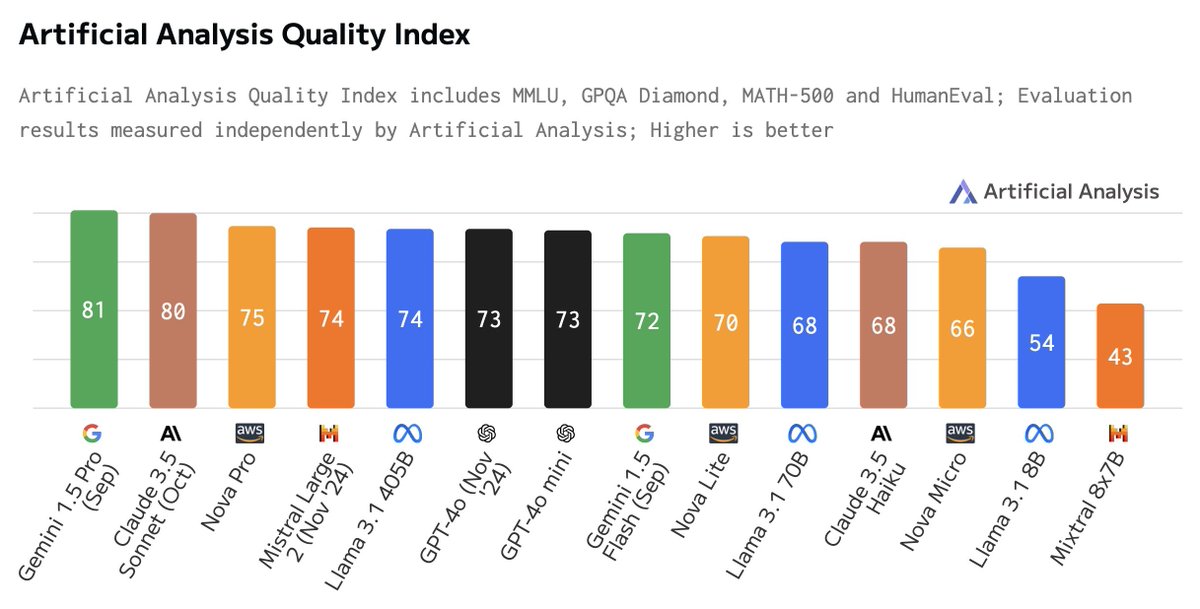
Amazon has launched Nova, a highly competitive family of foundation models. Nova Pro, Lite and Flash set new standards for the intelligence that can be accessed at the price and speed these models are offered at. Nova Pro, the flagship model, ranks amongst the leading frontier models in the Artificial Analysis Quality Index. With a score of 75, Pro ranks higher than GPT-4o (November release), Mistral Large 2 and Llama 3.1 405B. Access is priced competitively at $0.8/1M Input tokens and $3.2/1M output tokens, ~1/3 the cost of GPT-4o ($2.5/$10). Nova Lite and Micro are smaller and faster models that offer competitive intelligence for their price class. Micro can be accessed at 157 output tokens/s, faster than Gemini 1.5 Flash, Llama 3.1 8B (median of providers) and GPT-4o mini. Lite and Micro are competitively priced at $0.06 and $0.1 per 1M tokens respectively (blended 3:1, input:output) positioning them well for speed and/or price-sensitive use-cases. See below for deep dives on the performance and capabilities of these models.
@hume_ai just released a new voice modulation tool that lets you create unique AI voices in seconds. You can even use sliders to adjust voices along 10 dimensions including: - Relaxedness: from tense to relaxed. - Masculine/Feminine: from masculine to feminine. - Buoyancy: from deflated to buoyant. If you're not sure how to describe the exact qualities of a voice, the voice sliders let you experiment and tweak until you land on the perfect fit.
https://t.co/iNLCwp0a60

Leading computer vision researchers Lucas Beyer (@giffmana), Alexander Kolesnikov (@__kolesnikov__), Xiaohua Zhai (@XiaohuaZhai) have left Google DeepMind to join OpenAI! They were behind recent SOTA vision approaches and open-source models like ViT, SigLIP, PaliGemma https://t.co/KmQVTBIitB

Pydantic AI Agents: NEW Multi-Agent Framework 📚 Step-by-step Hands-on Tutorial 🔍 How to Install PydanticAI? 🛠️ What Models are Supported? Used @GroqInc 🎯 How to Create First Agent? ⚡ How to Add Custom Tools? 🔌 Built-in validation 🎮 How it differs from CrewAI or AutoGen? @pydantic @samuel_colvin @jxnlco