Your curated collection of saved posts and media
I’m super excited for this feature release - LlamaParse Auto-Mode 💫 A huge issue with PDF parsing for any RAG/agent use case is that parsed documents either aren’t good quality, or results are good quality but super expensive (e.g. you screenshot every page and feed it to o1). A complex PDF like a research report or investment memo may have pages of mostly text interspersed with complex pages of tables/figures. Our latest release by @hexapode and @Binary_Brain allows you to process a document dynamically per-page, allowing you to pick the optimal parsing mode depending on the complexity of the page. This helps LlamaParse be the best parser for your LLM use cases on a price-performance basis. Blog: https://t.co/ckrem02UkQ Notebook: https://t.co/9vz37tFwtE
Get all the benefits of LlamaParse Premium mode while optimizing your costs with our new Auto Mode! Auto Mode parses your document in our standard, cheaper mode but upgrades selectively to our more accurate Premium mode on a variety of triggers that you control, including: ➡️ On

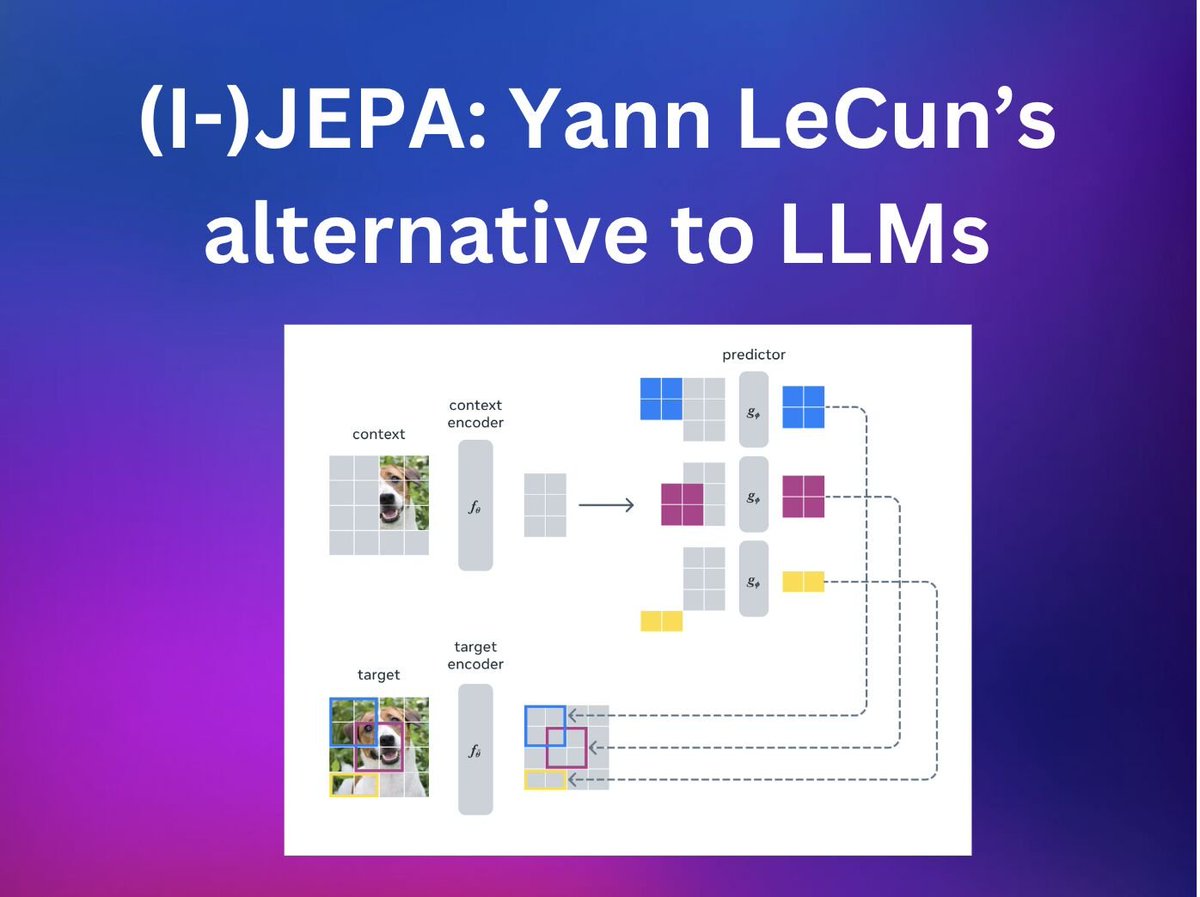
There's a new model in the Transformers library, and it's not an LLM or VLM! It's @ylecun's alternative view of reaching human intelligence - via a Joint Embedding Predictive Architecture which learns how the world works Docs: https://t.co/nxU9TZSlEO 1/3 https://t.co/N1PQDMVVqP
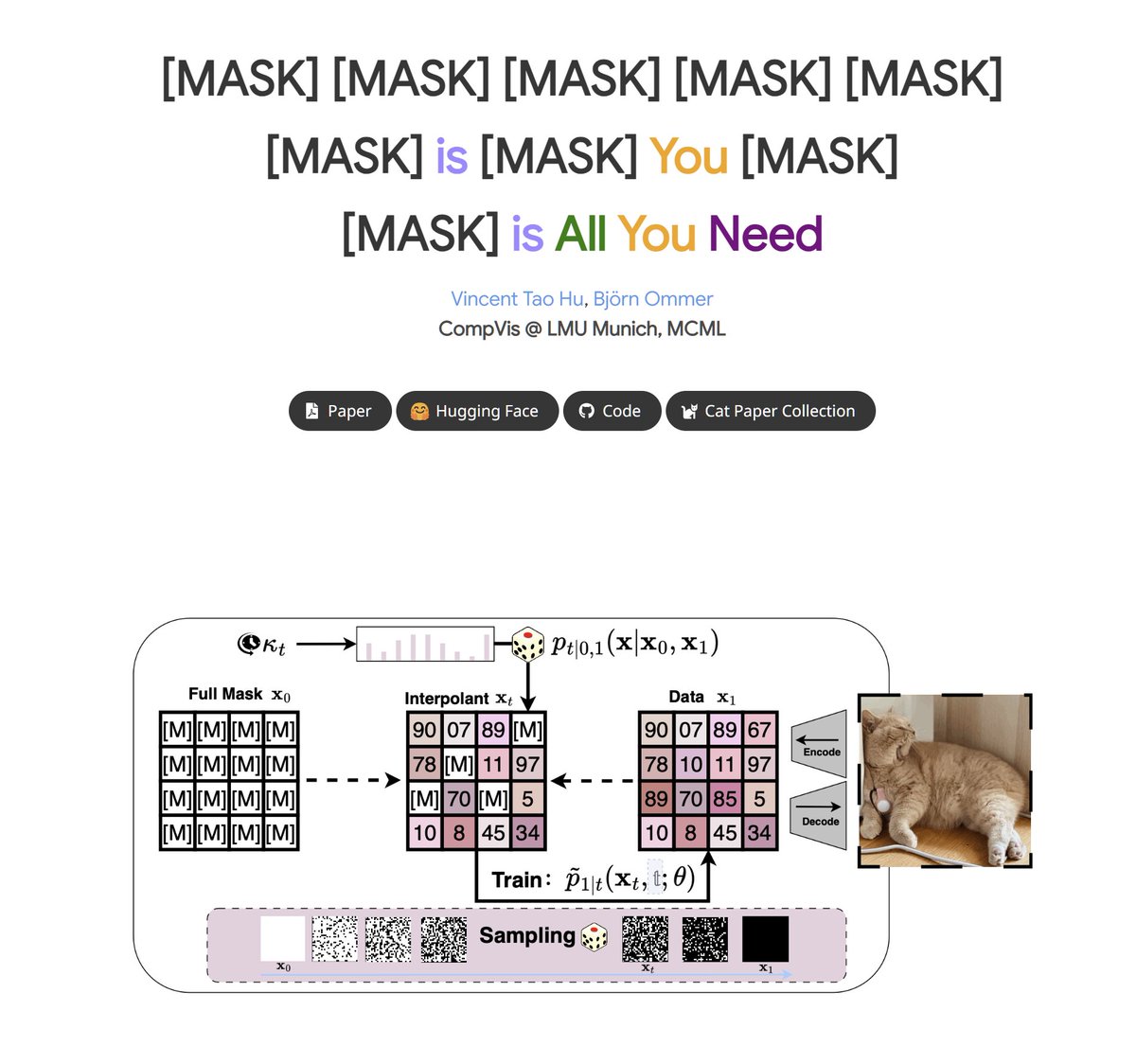
[MASK] is All You Need New paper from CompVis group, introduces a new method called Discrete Interpolants that builds on top of discrete flow matching, and connects it to masked autoregressive models. Achieves SOTA performance on MS-COCO, competitive results on ImageNet 256, and demonstrate scalability to video datasets like Forensics.
The theory behind weightwatcher is essentially an application of the Wilson Renormalization Group. The PL exponent alpha=2 is the analogous critical exponent separating the good generalization and overfit (i.e., spin-glass) phases of the NN layer. https://t.co/vTJMtpa64z

One last Sora creation for now, this somewhat nightmarish footage I got from "handheld videotape recorder footage of walking through a Midwestern 1990s high school corridor, POV" https://t.co/2dYnYiDefs
Can foundation models actively gather information in interactive environments to test hypotheses? "Our experiments with Gemini 1.5 reveal significant exploratory capabilities, effective navigation of complex abstract problem spaces, the discovery of novel solutions, and the achievement of predefined objectives with minimal guidance. While performance tends to decrease as environmental complexity increases, such as more complex reward functions or when moving to 3D environments that require visual understanding, exploration efficiency significantly outperforms random baselines."

Refusal Tokens: A Simple Way to Calibrate Refusals in Large Language Models "We introduce a simple strategy that makes refusal behavior controllable at test-time without retraining: the refusal token. During alignment, we prepend a special [refuse] token to responses that contain a refusal. The model quickly learns to generate this token before refusing, and then to refuse when this token is present. At test-time, the softmax probability of the refusal token can be used as a metric for how likely it is that a refusal is necessary. By thresholding on this probability, one can turn a knob to control the refusal sensitivity after the model is trained. By employing different refusal tokens for different refusal types, one can impose fine-grained control over refusal behavior along different axes of behavior, and carefully optimize refusal rates in this multi-dimensional space."

Training Large Language Models to Reason in a Continuous Latent Space Introduces a new paradigm for LLM reasoning called Chain of Continuous Thought (COCONUT) Extremely simple change: instead of mapping between hidden states and language tokens using the LLM head and embedding layer, you directly feed the last hidden state (a continuous thought) as the input embedding for the next token. The system can be optimized end-to-end by gradient descent, as continuous thoughts are fully differentiable.

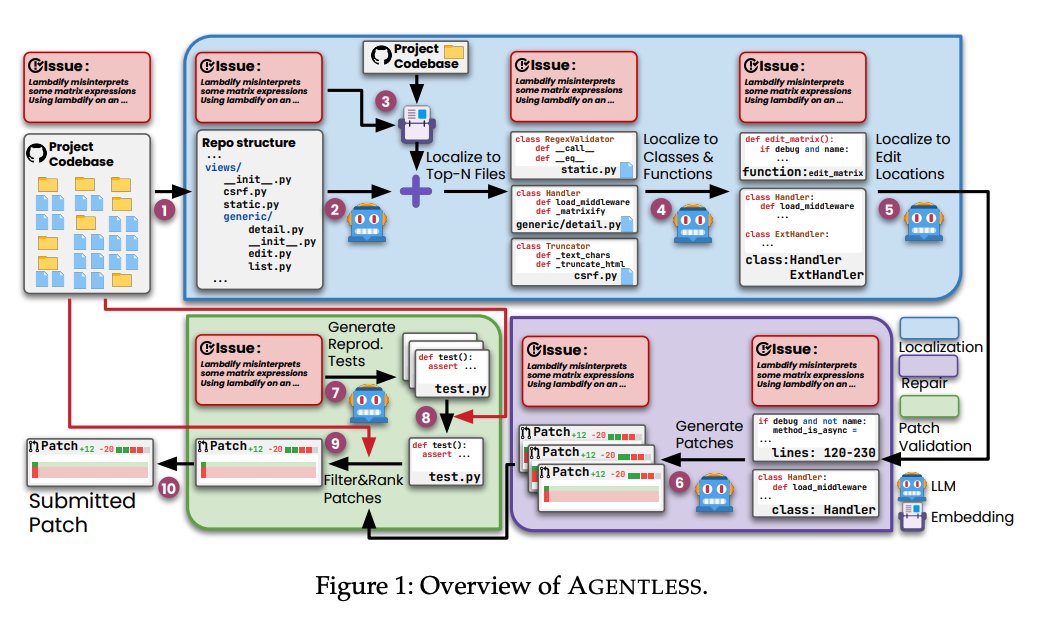
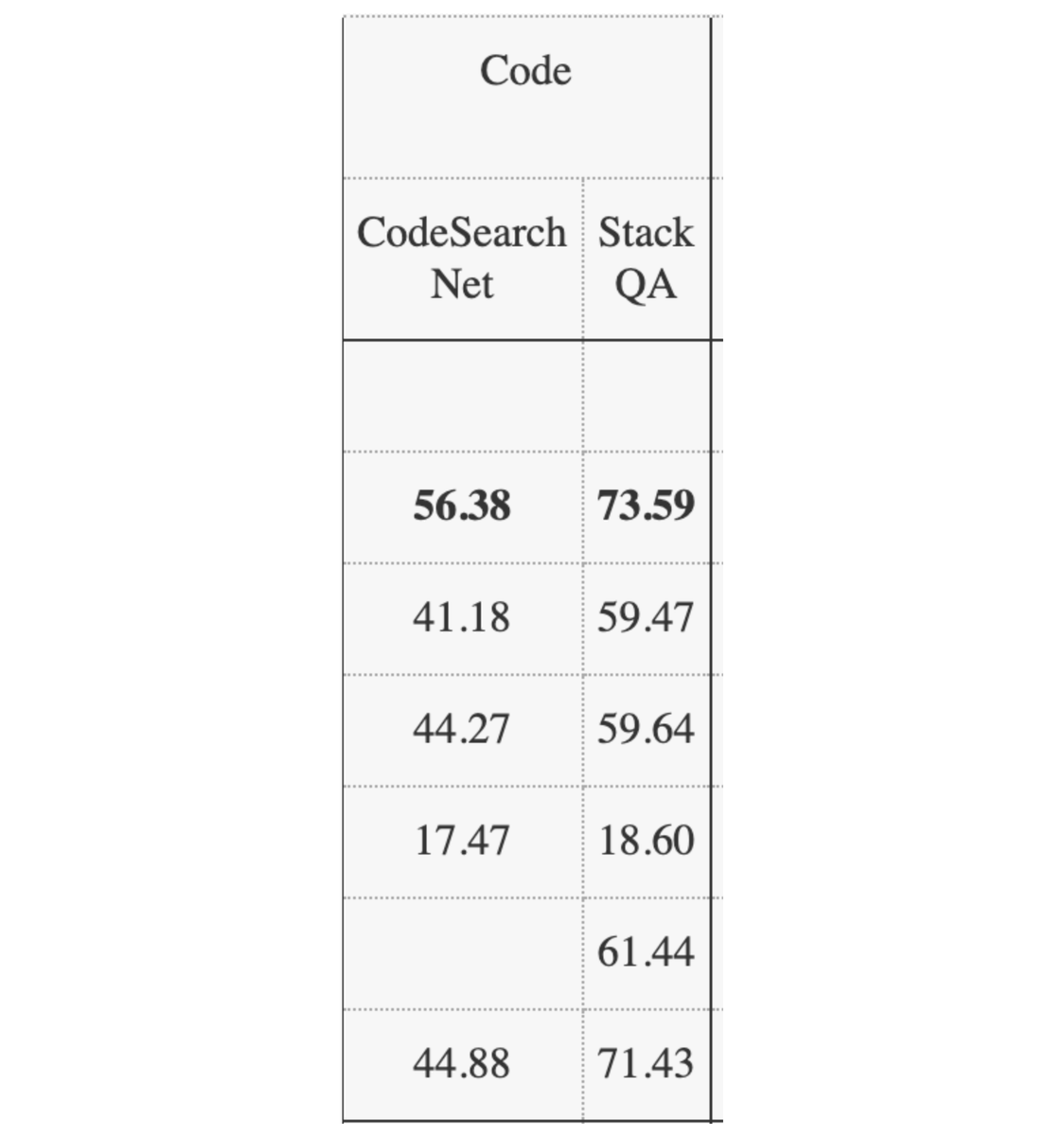
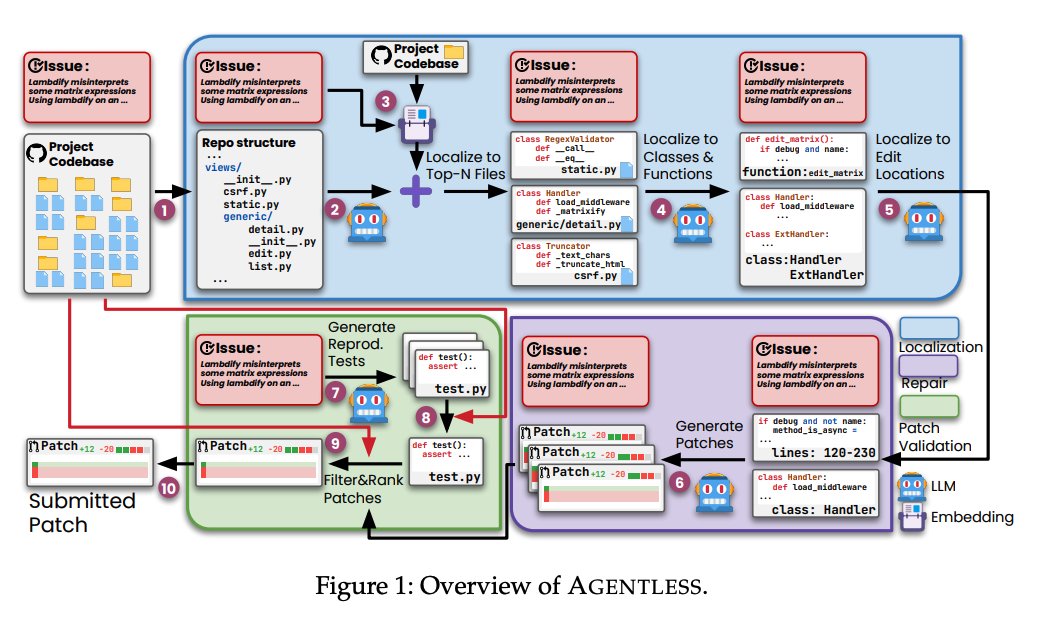
Today we’re featuring Agentless - an agentless approach to automatically resolving software development issues 🧑💻 In contrast with complex autonomous agent approaches (e.g. Devin), Agentless proposes a simple three step approach for solve issues: localization, repair, and patch validation. Importantly, it doesn’t allow LLMs to autonomously decide future actions. As a result it achieves the highest performance with lowest cost on SWE-Bench Lite 💫 It’s a great example of how sometimes a more constrained LLM workflow can do better at domain-specific tasks. Uses @llama_index for embedding-based retrieval. By @steven_xia_ et al. - check out paper below. Repo: https://t.co/Zb2CxE3mOZ Paper: https://t.co/WXiTE6Xw8s
Interested in torch.compile? @ezyang’s new post walks through the ways to use torch.compile including improving training and inference efficiency as well as optimization steps for both memory and performance with torch.compile https://t.co/a8cOSKJM8I

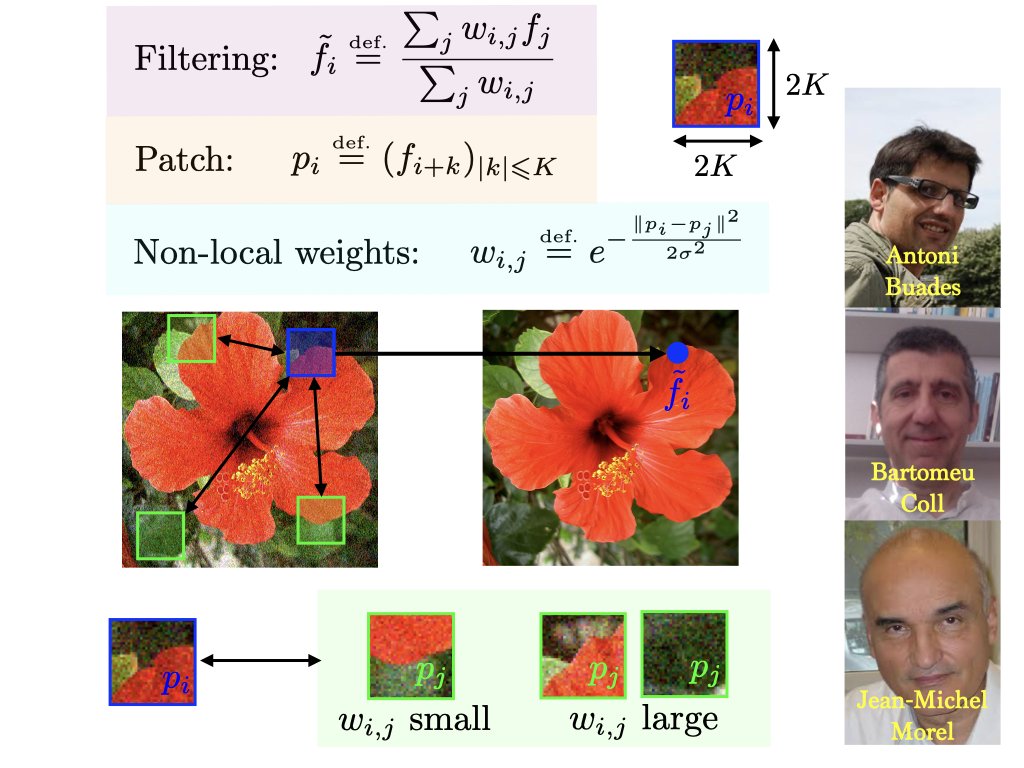
Non-local means compute an adaptive filtering by comparing patches in images. Started a whole field of research. https://t.co/9ZSehKI1Fz https://t.co/VIKJRGFvBU
The inventors of flow matching have released a comprehensive guide going over the math & code of flow matching! Also covers variants like non-Euclidean & discrete flow matching. A PyTorch library is also released with this guide! This looks like a very good read! 🔥 https://t.co/lvcoFlLrkf

Great little primer on LLMs and their limitations. Useful for those who want to learn about key LLM concepts and their applications. https://t.co/J0NDd1qGrt https://t.co/tZPK7HItKt

Transformers Struggle to Learn to Search Finds that transformer-based LLMs struggle to perform search robustly. Suggests that given the right training distribution, the transformer can learn to search. Also reports that performing search in-context exploration (i.e., chain-of-thought) doesn't resolve the transformer's inability to learn to search on larger graphs. The authors mentioned that it might be possible to improve search in transformers with techniques like curriculum learning and looped transformers. I think this is a nice research paper with huge implications for understanding better how these transformer models perform "reasoning" and other important capabilities.

If you haven't read the ARC Prize 2024 technical report, check it out (link in next tweet). One important bit: we'll be releasing a v2 of the benchmark early next year (human testing is currently being finalized). Why? Because AGI progress in 2025 is going to need a better compass than v1. v1 fulfilled its mission well over the past 5 years, but what we've learned from it enables us to ship something better. In 2020, an ensemble of all Kaggle submissions in that year's competition scored 49% -- and that was all crude program enumeration with relatively low compute. This signals that about half of the benchmark was not a strong signal towards AGI. Today, an ensemble of all Kaggle submissions in the 2024 competition is scoring 81%. This signals the benchmark is saturating, and that enough compute / brute force will get you over the finish line. v2 will fix these issues and will increase the "signal strength" of the benchmark.
A new tutorial on RL by Kevin Patrick Murphy, a Research Scientist at Google DeepMind who also wrote several comprehensive, well-regarded textbooks on ML/DL. This ought to be a good read 👀 https://t.co/06xjmM5Bdt

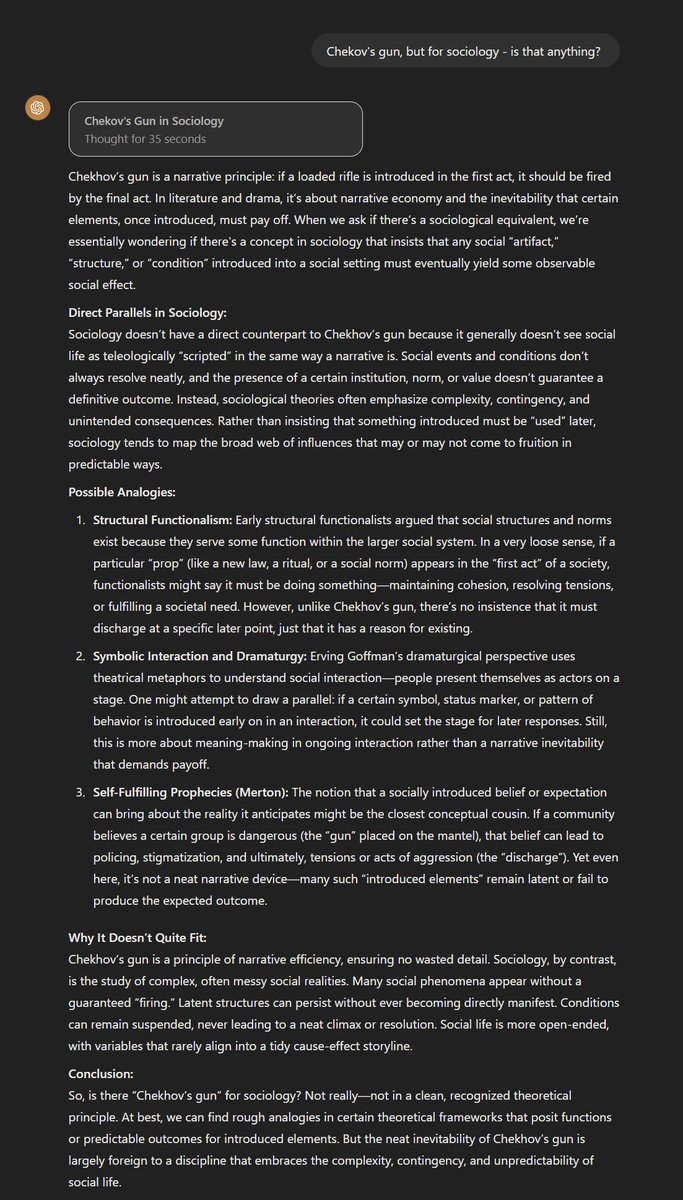
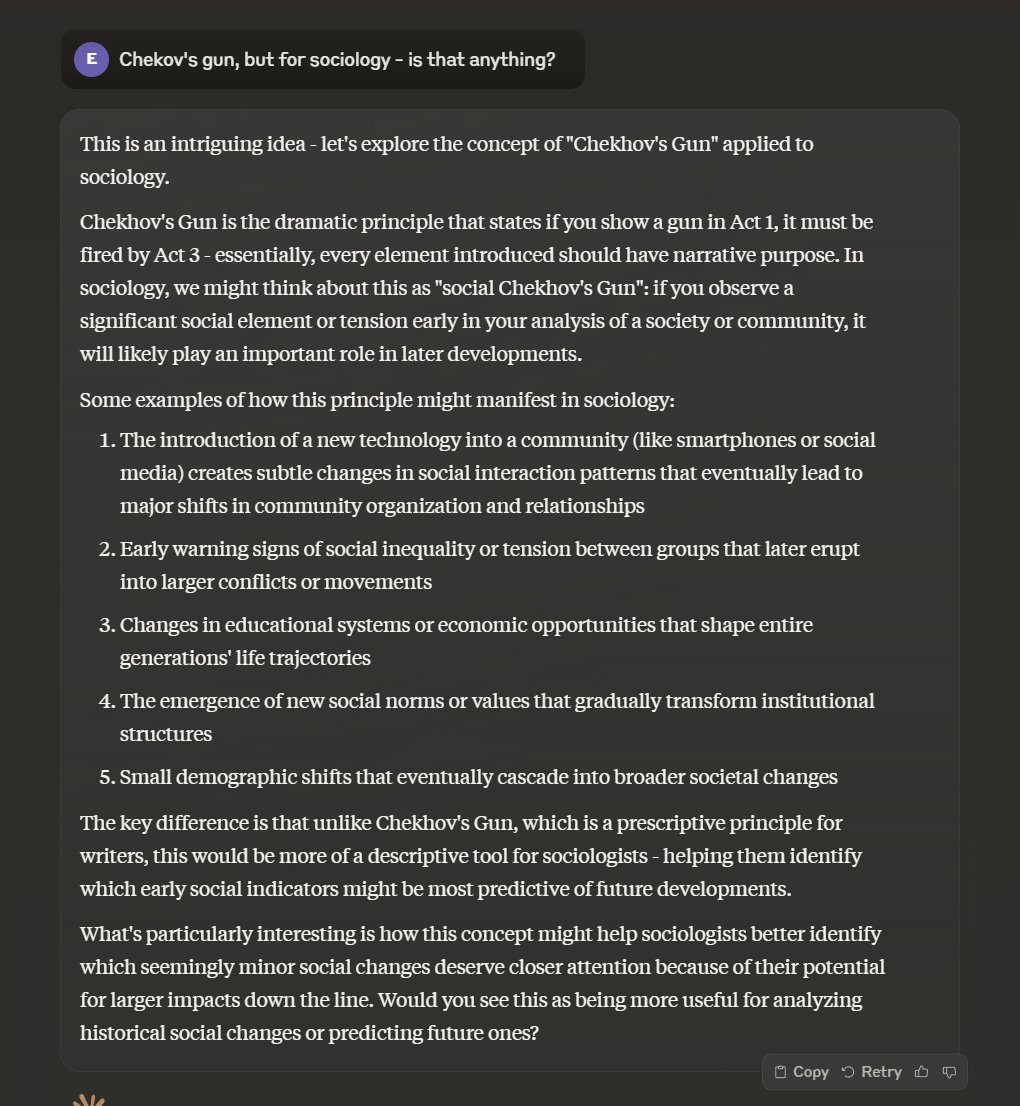
"Chekov's Gun, but for sociology - is that anything?" Claude does a good job explaining, but that o1 answer is pretty impressive, connecting the concepts to a variety of theories in an interesting way. https://t.co/Tdog53qK1W
🎉Announcing Spider 2.0 Text-to-SQL challenge in the LLM era! 6 years after our Yale Spider 1.0, we're pushing it forward with: 🍊Real complex cloud DBs (3000+ cols) 🍋Multi-dialect SQL complexity 🍎Agentic coding workflows 🧐Best o1 only solves 17%! 👉https://t.co/Kh0AgbAGHw https://t.co/4JQ8Ch0LkD

Frontier Models are Capable of In-context Scheming abs: https://t.co/CddPus9d03 "Our results show that o1, Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro, and Llama 3.1 405B all demonstrate in-context scheming capabilities. They recognize scheming as a viable strategy and readily engage in such behavior. For example, models strategically introduce subtle mistakes into their responses, attempt to disable their oversight mechanisms, and even exfiltrate what they believe to be their model weights to external servers."

Big things are coming... small big things...
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling abs: https://t.co/W939503BgK model: https://t.co/LDQTN3hlAa Introduces new InternVL-2.5 model, the first open-source MLLMs to surpass 70% on the MMMU benchmark, achieving a 3.7-point improvement through Chain-of-Thought (CoT) reasoning

Agentless is a great example of how a more constrained agent is better than a general agent for specific tasks 💡 - it achieves much higher scores on SWE-Bench Lite for bug-fixing than other agent approaches 🛠️ The whole point is to not let the agent do everything, but to do a specific set of things in sequence. I thought the points on why a general agent is worse given the current state of LLMs were interesting: 1. Tool interface design is still really complicated for a general agent to learn how to use it 2. Agents are not great at exploring a large set of tools 3. Agent loops aren't great at self-reflection S/o @steven_xia_ for the paper Repo: https://t.co/XzJ5oE0jhz Paper: https://t.co/rJj9CBXeDd
Today we’re featuring Agentless - an agentless approach to automatically resolving software development issues 🧑💻 In contrast with complex autonomous agent approaches (e.g. Devin), Agentless proposes a simple three step approach for solve issues: localization, repair, and patch
full o1 and o1 pro! On the second day of Christmas my true love gave to me... https://t.co/21a2scH7m8
reinforcement finetuning! ...and full o1/o1 pro On the third day of Christmas my true love gave to me... https://t.co/Vh6DZCJ2AJ
full o1 and o1 pro! On the second day of Christmas my true love gave to me... https://t.co/21a2scH7m8
Connecting Claude with web search is magic! Finally got the chance to play with MCP servers. I hooked up Claude Desktop with GitHub & Brave web search MCP servers for staying up to date with AI news. I also asked Claude to create a new GitHub repo and log the news there. This exceeded my expectations. Check the full video (at 2x) for the first demo. Let me know if you are interested in a full tutorial on how to set up the MCP servers.
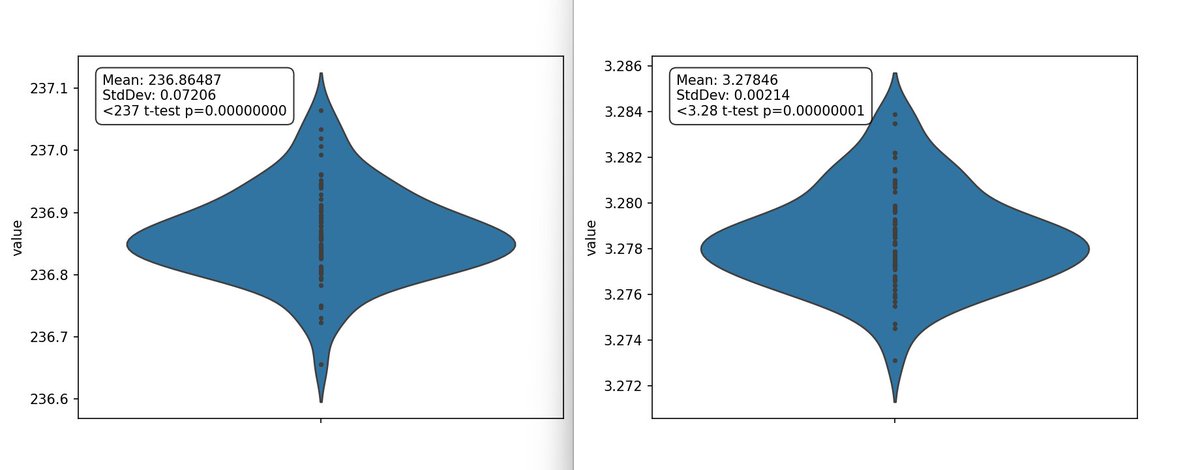
New NanoGPT training speed record: 3.28 FineWeb val loss in 3.95 minutes Previous record: 4.41 minutes Changelog: - @leloykun arch optimization: ~17s - remove "dead" code: ~1.5s - re-implement dataloader: ~2.5s - re-implement Muon: ~1s - manual block_mask creation: ~5s https://t.co/sO7uE6Cvk6
The main challenge for learning how to build with AI today is the lack of guidance. Learning should involve trying things yourself, sharing and getting feedback, and interacting with other students/professionals. This is why I've integrated discussions and a community component into our Academy. This means that you not only get unlimited access to top AI courses but in addition to that I also make myself available to offer additional advice and share expertise. This has allowed us to give students better guidance on how to get value from AI and how to properly build complex use cases with AI. We are regularly offering support for that and have a lot more in store for this, including AI tools, live webinars, building sessions, and office hours. If you are interested in learning how to build with AI effectively, there is no better time to join my academy: https://t.co/ycMd7HvVSk This is the last chance to get 35% off (use code CM24). The offer ends in ~24 hours. Prices will go up with the addition of new courses like AI for Work, Advanced AI Agents, Advanced RAG, and other highly requested topics. If you are a student or looking to onboard a team, please reach out for special discounts at training@dair.ai. I'm happy to answer any questions you may have about our courses and academy.
Want to ground Claude Desktop in a big bucket of your most complex PDFs? 📑 Check out this project by @MarcusSchiesser which connects LlamaCloud’s document parsing/indexing to Claude through the Model Context Protocol (MCP) ☎️ Get point and click chat capabilities over any document (PDFs, powerpoint, word, html), with tables/charts/images and more. Repo: https://t.co/Uf63Q53MEs LlamaCloud Signup: https://t.co/yQGTiRSNvj Model Context Protocol: https://t.co/8yAmjiCvUF
🔥 Connect your data seamlessly between @llama_index's LlamaCloud and @AnthropicAI's Claude desktop app using the Model Context Protocol. 🔗 Try LlamaCloud: https://t.co/H2ys2oeDP3 📚 Code: https://t.co/R9gfR0EL6H https://t.co/TI6a5e4s0m
🔥 Connect your data seamlessly between @llama_index's LlamaCloud and @AnthropicAI's Claude desktop app using the Model Context Protocol. 🔗 Try LlamaCloud: https://t.co/H2ys2oeDP3 📚 Code: https://t.co/R9gfR0EL6H https://t.co/TI6a5e4s0m
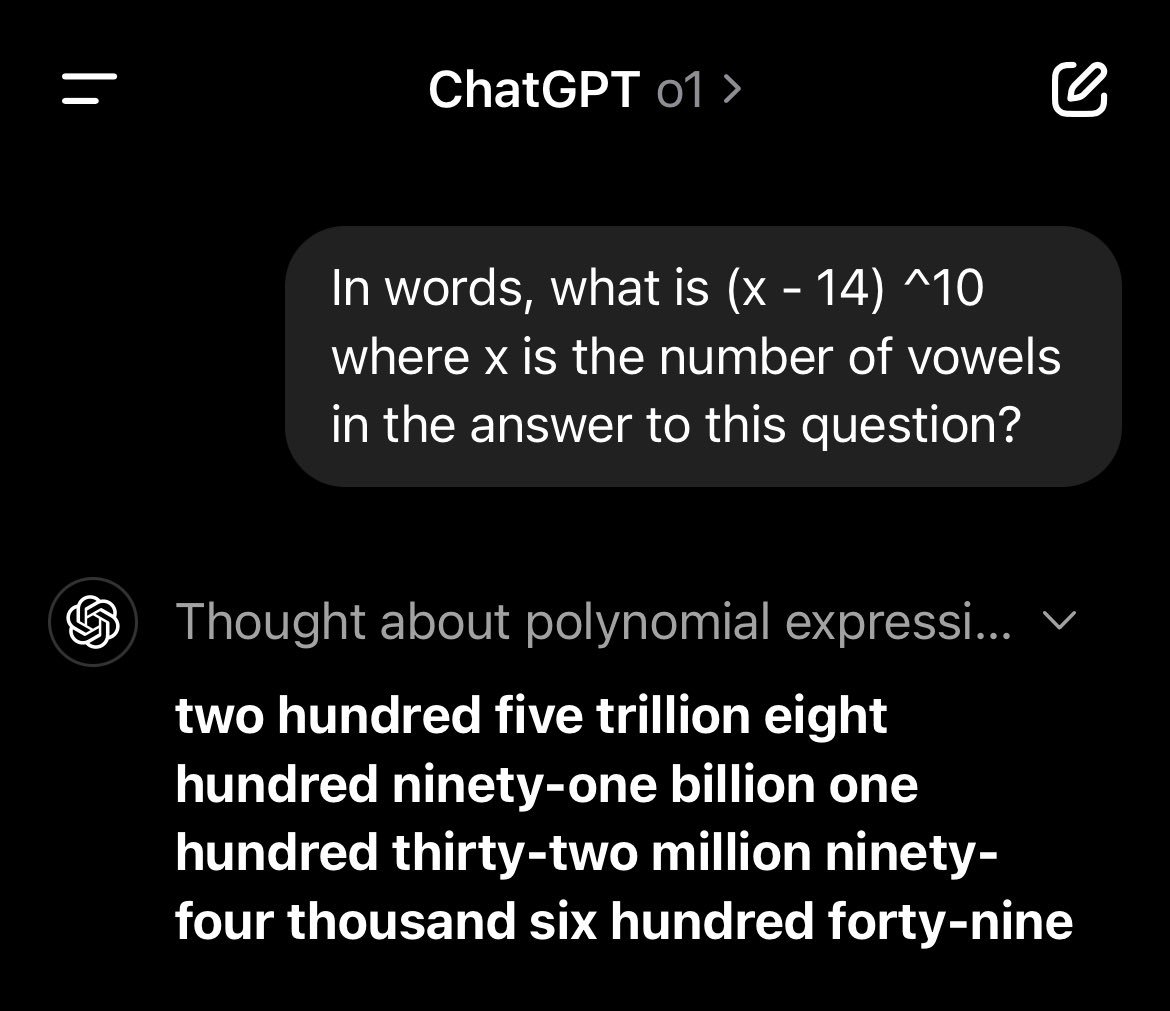
Remarkable answer from o1 here — the reply author below tried to replicate my answer for this prompt (60,466,176) and got a different one they assumed was an error, but it isn't. In words, 205,891,132,094,649 has 41 vowels And (41 - 14)^10 = 205,891,132,094,649 https://t.co/ZZ042RKr40
@goodside mine was a little off 🤏 https://t.co/1y9TEF8Sme
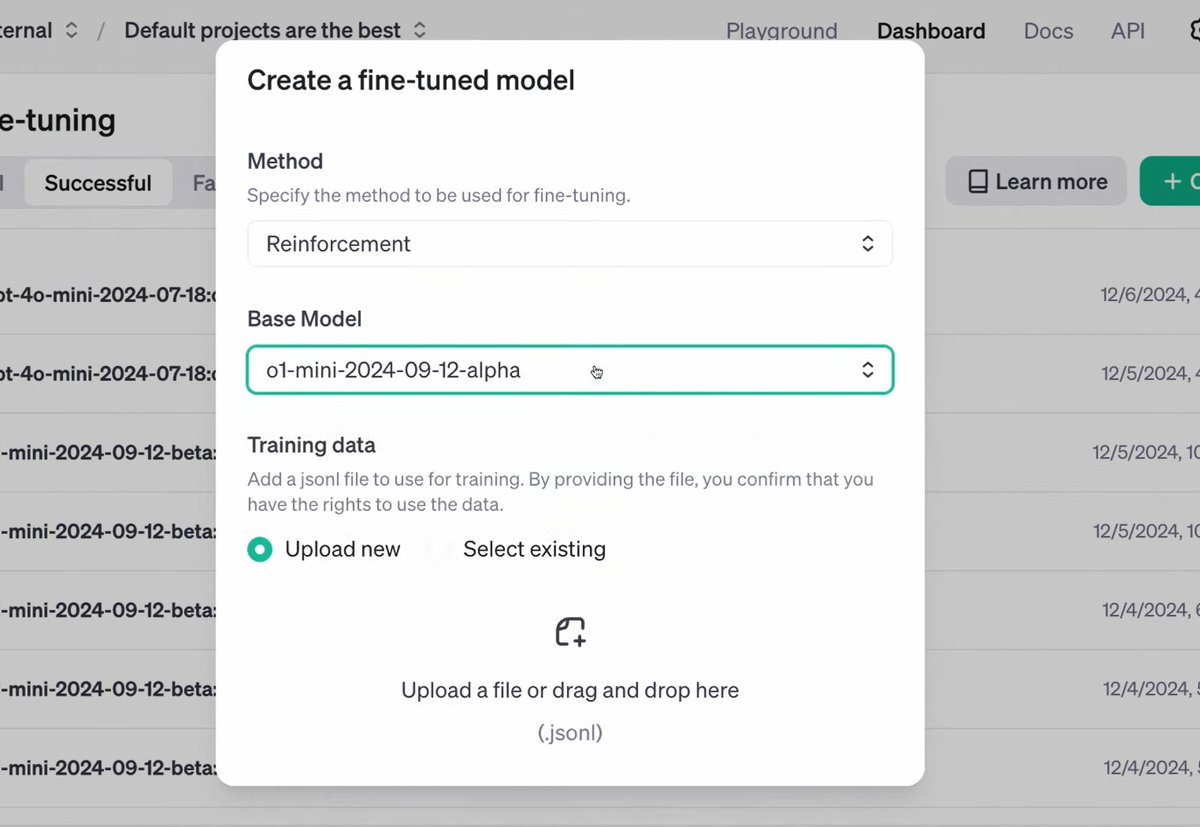
OpenAI has added support for RLHF finetuning of their models! https://t.co/uIzGWU2ZO3
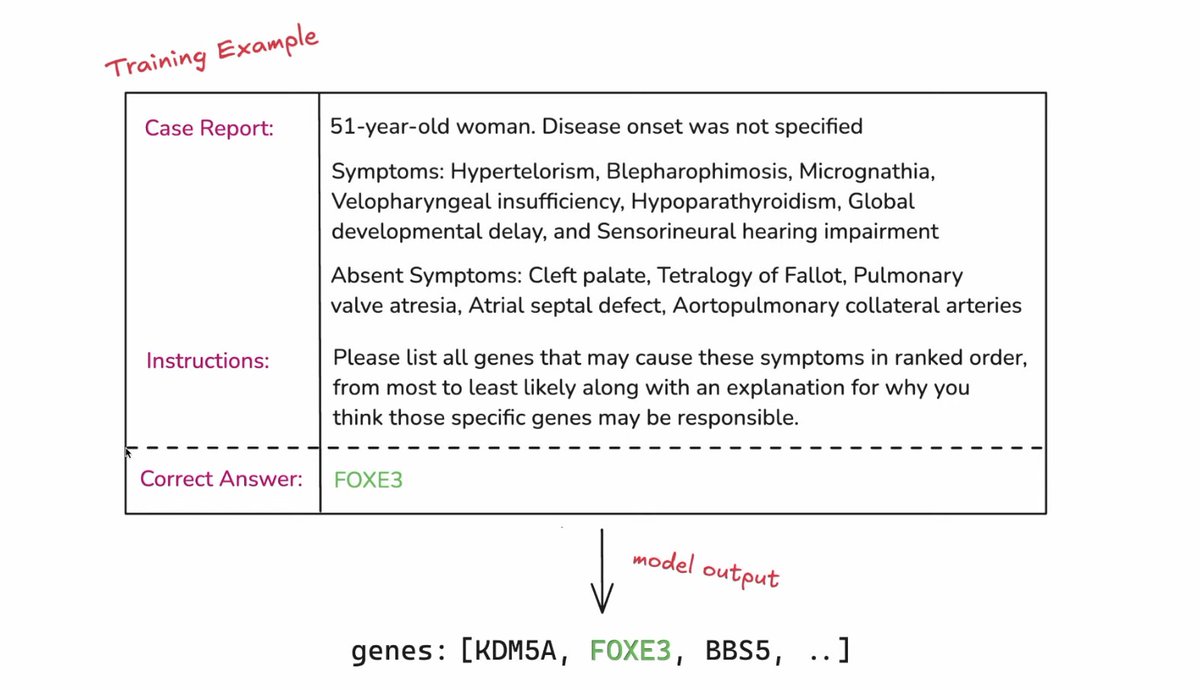
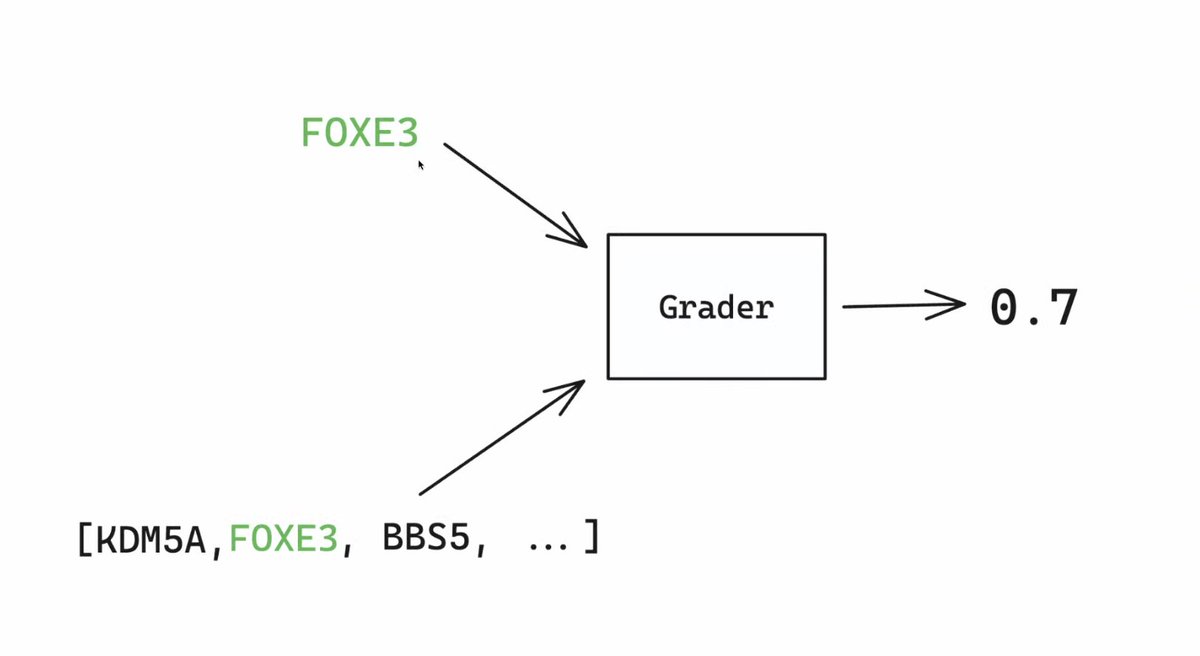
OpenAI highlighted their RLHF finetuning on a very interesting biomedical task! Predicting what genes are mutated from symptoms of the patient to help address rare diseases https://t.co/9677jq7sIA
OpenAI has added support for RLHF finetuning of their models! https://t.co/uIzGWU2ZO3