Your curated collection of saved posts and media
we are so back! finally, PaliGemma2 for LaTeX OCR - used google/paligemma2-10b-pt-224 checkpoint - trained on A100 with 40GB VRAM - 4h of training on 20k training examples - QLoRA with 4bit quantization colab with complete fine-tuning code: https://t.co/lpx6yqQL1M https://t.co/1fDbwsKvPQ
PaliGemma2 for LaTeX OCR this is not a success story; I can't make this task work... :/ - used google/paligemma2-3b-pt-448 checkpoint - trained on A100 with 40GB VRAM - 4h of training on 10k training examples colab with complete fine-tuning code: https://t.co/lpx6yqQdce https
I paid the $500 for Devin, the mega hyped AI coding agent, so you don't have to here's an in depth review of how it compares to Cursor: https://t.co/yQQymvnTXH
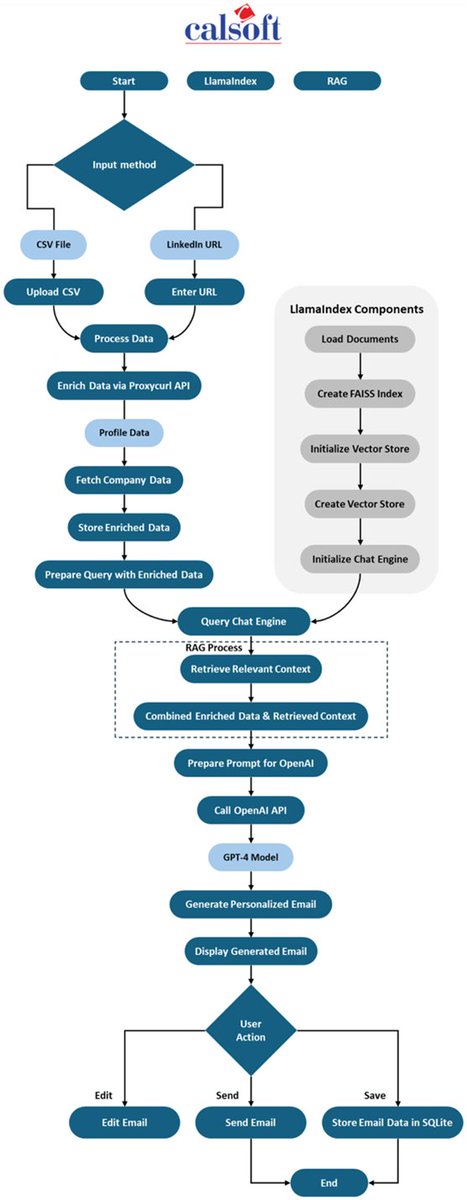
Learn how Calsoft created CalPitch, a tool that helps their business development department by researching prospects and writing outreach emails with human-in-the-loop for review. This is a great example of how AI can be used to augment and accelerate existing teams. The system: 🚀 Automates prospect research and email crafting 🎯 Generates highly personalized pitches at scale 📊 Improves conversation rates and team productivity Read the full story: https://t.co/IO8etXwKOw
Gemini 2.0 provides a glimpse of what's coming in 2025. The multi-agentic era is upon us. There is no better time to build with AI than today. What I like about this release is that there is something for everyone, from research agents to coding agents. Building Gemini with multi-modal capabilities from the ground up has given Google a clear advantage going into this new agentic era. My short 10 min overview of Gemini 2.0 and what's included: https://t.co/1u1mcbIaFL
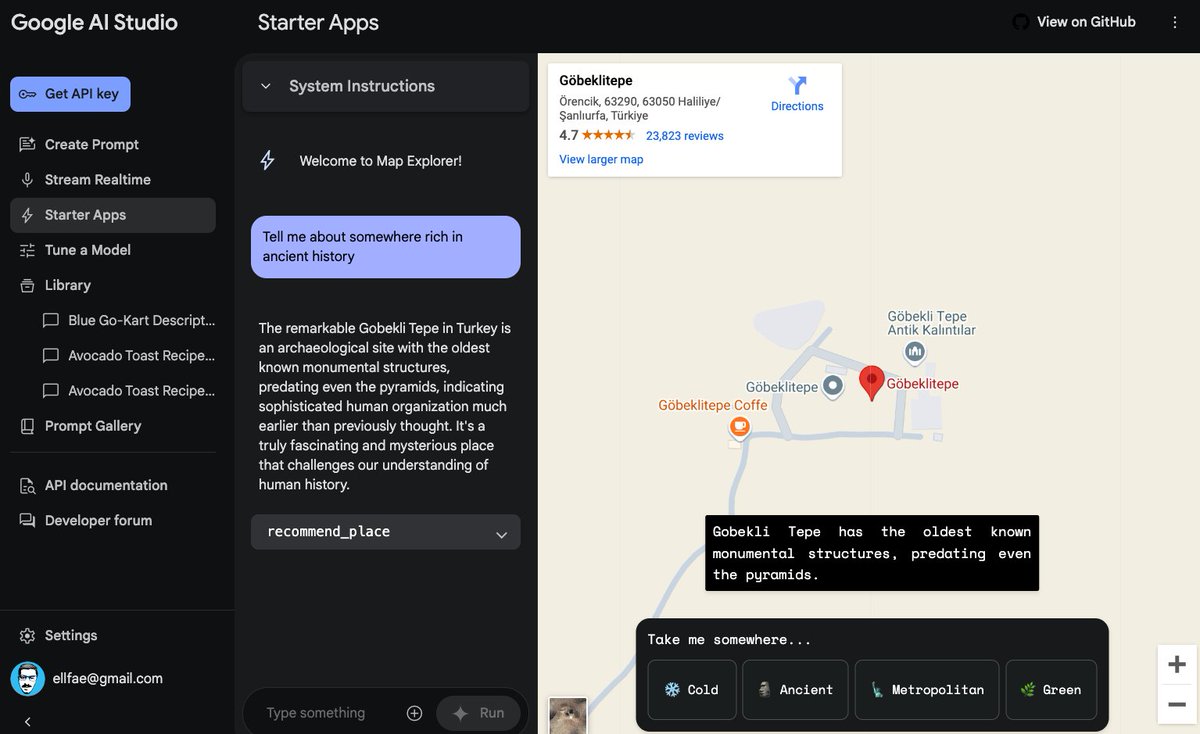
Gemini 2.0 real-time AI is absolutely wild! Watch how I use it as an AI research assistant by sharing my screen and asking it about an AI paper. 10x your paper reading skills or just let Gemini summarize key points. What an incredible time to be alive! https://t.co/lopQ7g1PmX
Sora videos ripped from our collective unconscious: "Youtube video game review featuring a potato-themed FPS video game." Sorry about this. https://t.co/dd1WQnumDL
AWS' textract OCR also sucks https://t.co/SM7kN1OAUH
Apple Intelligence + Canvas updates, Sora, reinforcement finetuning, and full o1/o1 pro... On the sixth day of Christmas my true love gave to me... https://t.co/ulxxjIwRz8
While the math behind flow matching can be intimidating, it can be implemented in just a few lines of code, as shown in this standalone example! https://t.co/JT7ysONor9
The inventors of flow matching have released a comprehensive guide going over the math & code of flow matching! Also covers variants like non-Euclidean & discrete flow matching. A PyTorch library is also released with this guide! This looks like a very good read! 🔥 htt

Asynchronous LLM Function Calling Proposes AsyncLM, a system for asynchronous LLM function calling. AsyncLM can reduce task completion latency from 1.6x-5.4x compared to synchronous function calling. It enables LLMs to generate and execute function calls concurrently. "We design an in-context protocol for function calls and interrupts, provide fine-tuning strategy to adapt LLMs to the interrupt semantics, and implement these mechanisms efficiently on LLM inference process." What's interesting about this interrupt mechanism is that it could be extended to other human-LLM or LLM-LLM interactions. Very cool paper!

AI benchmarks falling into the McNamara Fallacy: Step 1: Measure what can be easily measured Step 2: Disregard that which cannot be measured easily Step 3: Presume that which cannot be measured easily isn’t important Step 4: Say that which can’t be easily measured doesn’t exist https://t.co/uLGZF14rVk

"Claude, entertain me. i am very sophisticated. do not give me choices, just entertainment." "i am sophisticated, not a nerd" "more sophisticated" "more sophisticated! I demand sophistication" (the last line is actually pretty great) https://t.co/cWBpQkAfqK

Every one of these ends the same way, with the LLM doing *something* with your carefully selected RAG context. Is it right on subtle issues? Is it persuasive on a wrong approach? Is it sycophantic to your bad ideas? No one knows, which is why RAG doesn’t do what people think. https://t.co/0Yja26QnXM
Struggling to keep up with new RAG variants? Here’s a cheat sheet of 7 of the most popular RAG architectures. Which variants did we miss? https://t.co/zCasIEs5uc
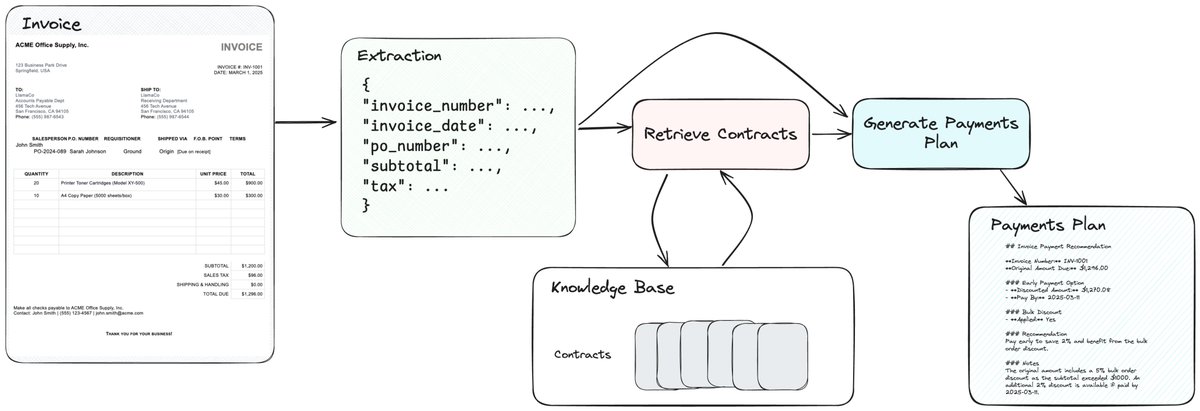
We’ve become increasingly interested in document agent workflows that can automate practical workflows beyond one-step RAG/IDP tasks. 📑🤖 First up - an e2e invoice processing agent 🧾: given an invoice, extract out the relevant information, match it with the relevant vendor contract and apply any vendor-specific discounts, and generate a payments plan. Powered by @llama_index workflows, LlamaParse for parsing/extraction, and LlamaCloud indexing. https://t.co/zH5W8ccxRk
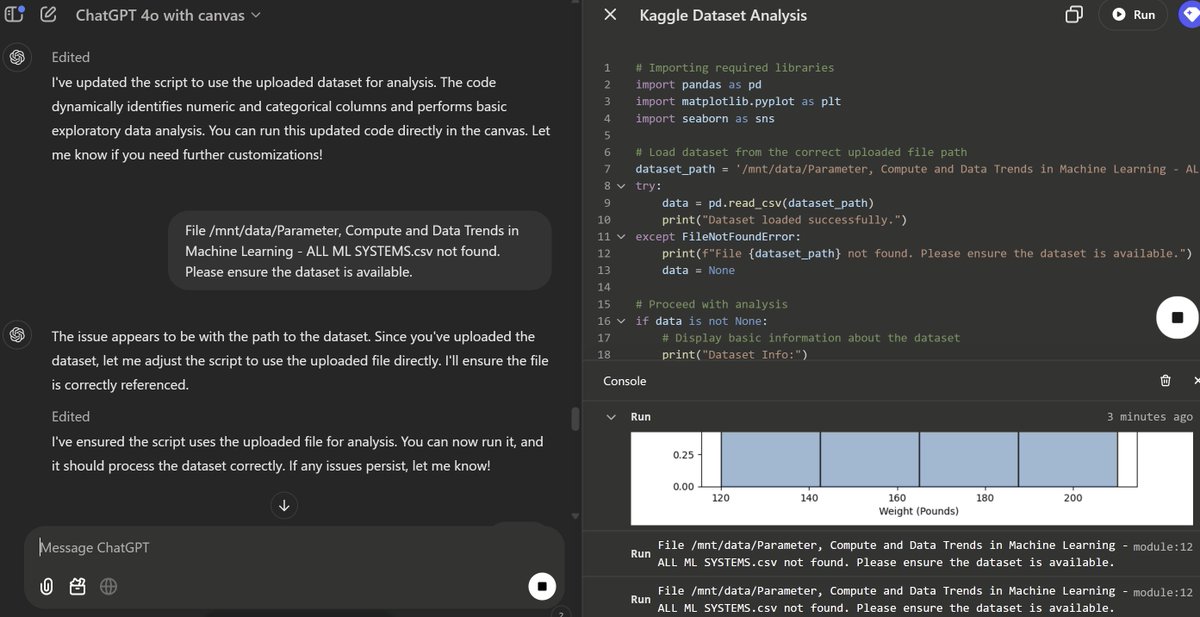
The new Canvas release seems very cool in early experiments, but has left ChatGPT confused about how it connects to the internet or files, since each pane of the window can do different things in different ways with code and files. The whole thing has left me confused as well. https://t.co/NbUcGEUq4g
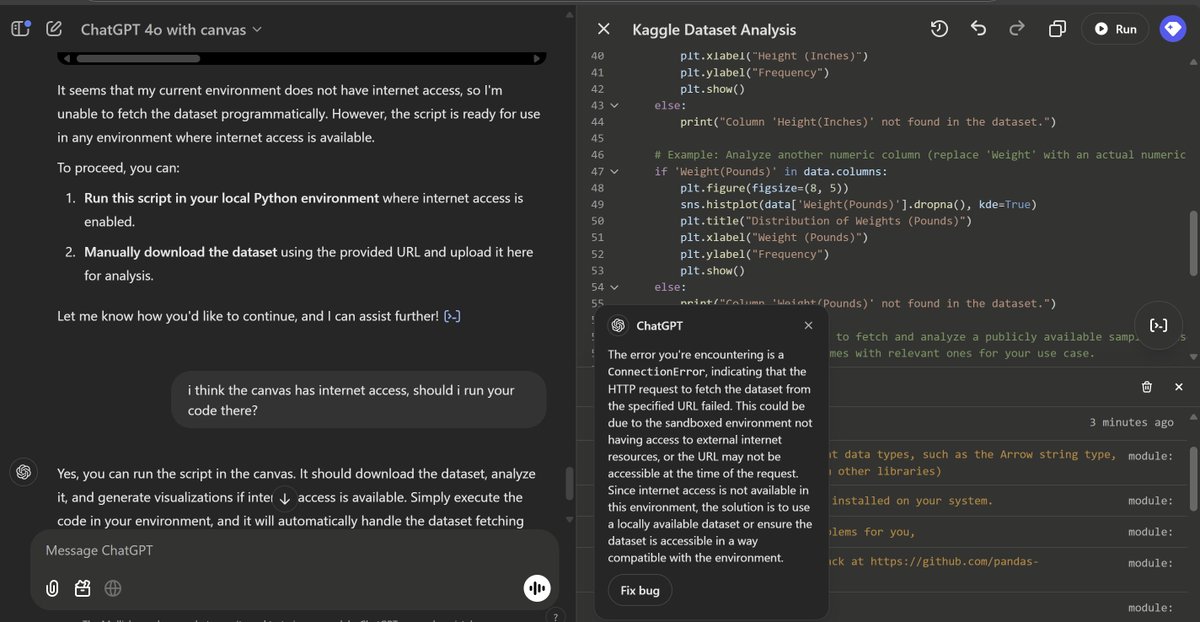
o1-pro doesn’t accept pdfs or word documents (unlike 4o) For $200, I expect more from basic UX? Like don’t make me convert to text myself? https://t.co/9cDqWzUc5l

May I just add: aaaaargh Why does OpenAI need to make this so complicated? Two useful, not-completely-overlapping feature sets. https://t.co/QPeltOISOV
A weird and interesting thing about the new ChatGPT Canvas mode is that it can run Python in an entirely different way from the existing Code Interpreter - using Pyodide (Python in WASM) - which means it can make network requests from Python now! https://t.co/JIwU36b51x
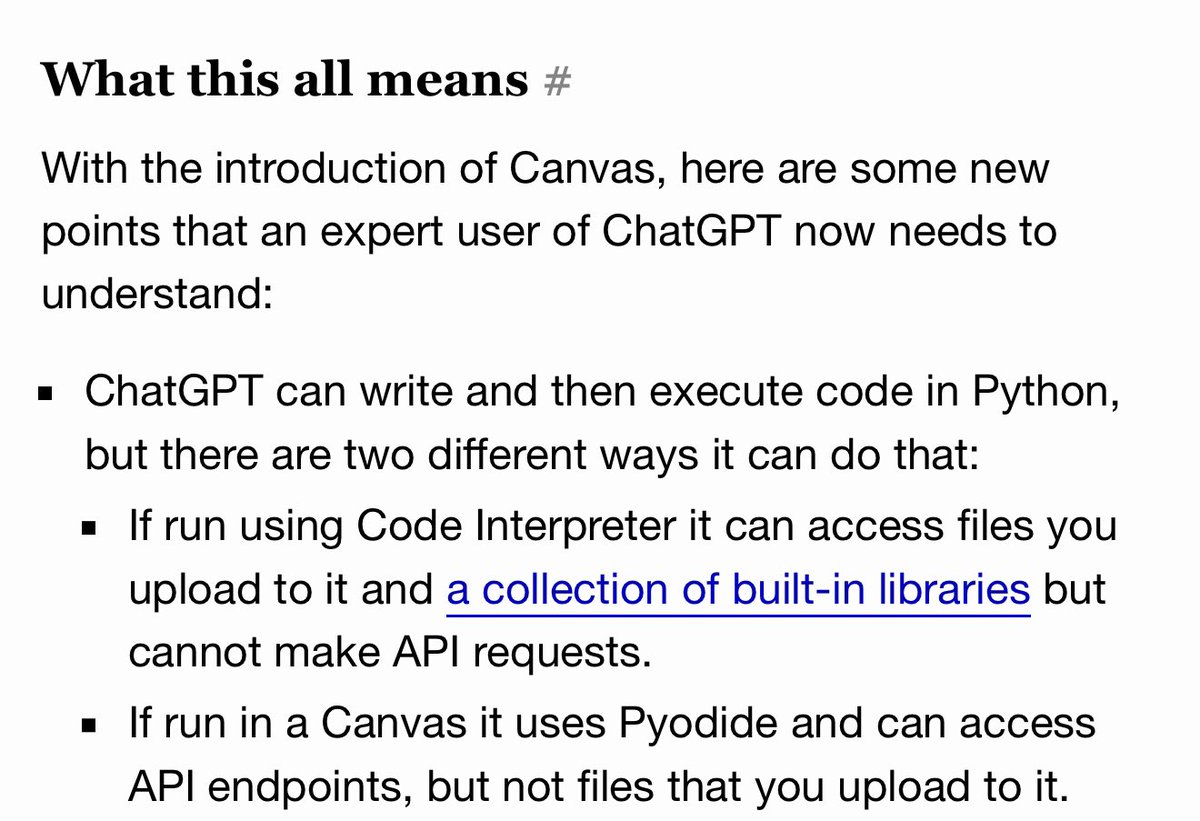
Possibly some folks at OpenAI don't really know what tasks most humans do. https://t.co/vGTO9uI0Ve
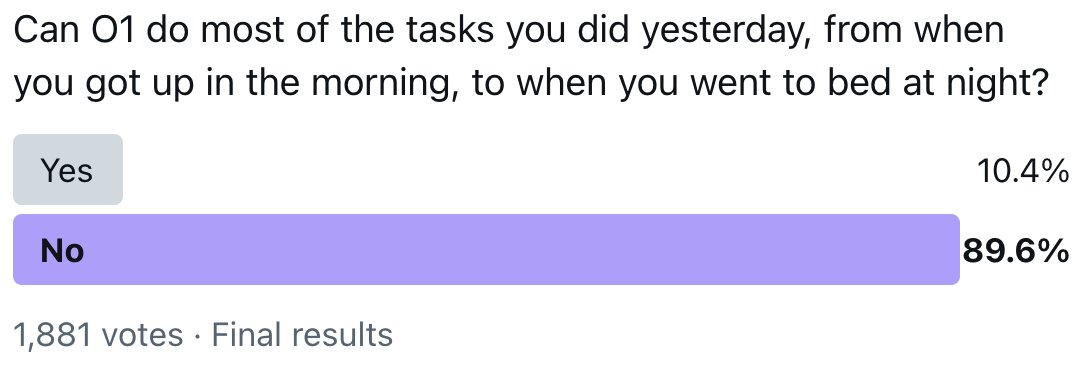
In my opinion we have already achieved AGI and it’s even more clear with O1. We have not achieved “better than any human at any task” but what we have is “better than most humans at most tasks”. Some say LLMs only know how to follow a recipe. Firstly, no one can really explain wh
Training LLMs to Reason in a Continuous Latent Space Meta presents Coconut (Chain of Continuous Thought), a novel paradigm that enables LLMs to reason in continuous latent space rather than natural language. Coconut takes the last hidden state of the LLM as the reasoning state and feeds it back to the LLM as the subsequent input embedding directly in the continuous space. This leads to what the authors refer to as "continuous thought" which augments an LLM's capability on reasoning tasks. It demonstrates improved performance on complex reasoning tasks through emergent breadth-first search capabilities.

Been trying Nougat but it doesnt seem to be any better than just copy pasting from the page except for converting math text in the docs to latex (which is nice) but it is preserving all the bad artifacts of a pdf, see, its breaking lines as they are broken up on page, which is not what I wanted :(

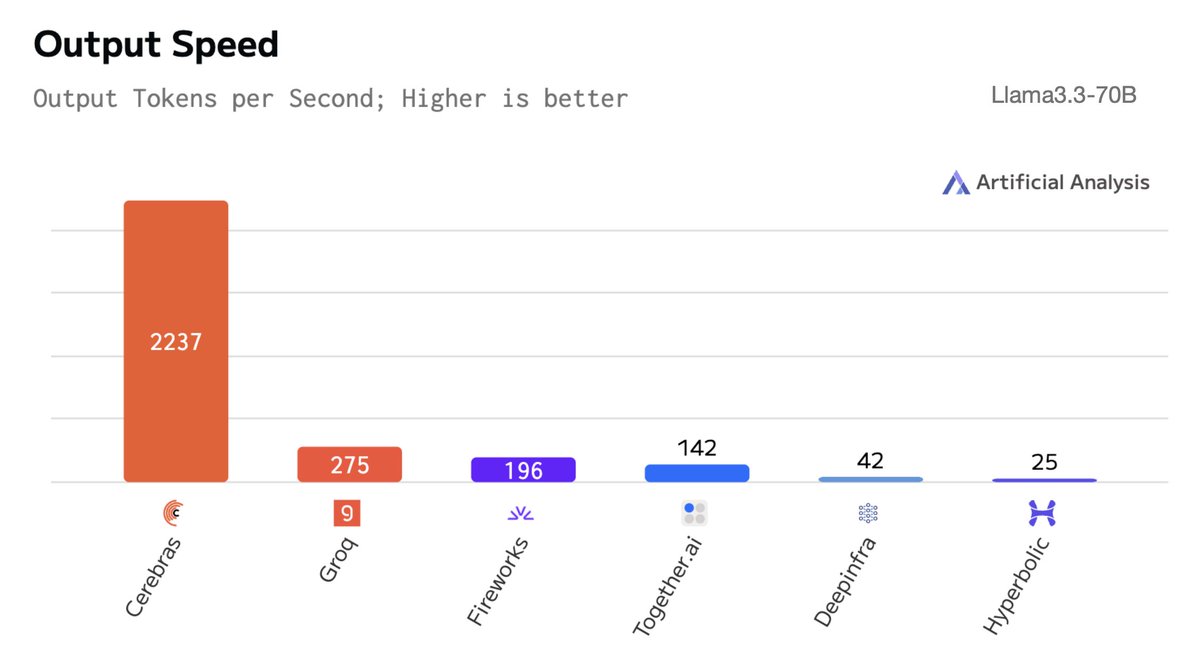
Introducing CePO – a test time reasoning framework for Llama - Llama3.3-70B + CePO outperforms Llama 3.1 405B and approaches GPT-4 & Sonnet 3.5 - CePO enables realtime reasoning. Despite using >10x more tokens, it runs at ~100t/s on Cerebras hardware - CePO is more robust than vanilla CoT & Best-of-N, read our full blog for evals & details

No answer at all. Just thought about it 🤣 https://t.co/jQ8kACTllE
IBM open-sources Granite Guardian, a suite of safeguards for risk detection in LLMs. The authors claim that "With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space." https://t.co/WOHdeKIB01

Llama 3.3 70B is now live on Cerebras Inference! Meta's new 70B model reaches 405B accuracy and Cerebras gives it a 10x speed boost. Available via chat & API: https://t.co/50vsHCl8LM https://t.co/PrzHSrDis4
Canvas updates! + Sora, reinforcement finetuning, and full o1/o1 pro... On the fifth day of Christmas my true love gave to me... https://t.co/9pRfp4gMCQ
Structured Output from Multipage PDF with Sparrow (Qwen2 Vision LLM and MLX) I explain how multipage PDFs are handled in Sparrow to extract structured data in a single call. https://t.co/eKO6RbyVPU
Sora is not perfect but to me it feels like a powerful tool that can augment my creative work. Here are my full thoughts and reactions: https://t.co/kUkykQsV84 https://t.co/JMk1S7kMjB
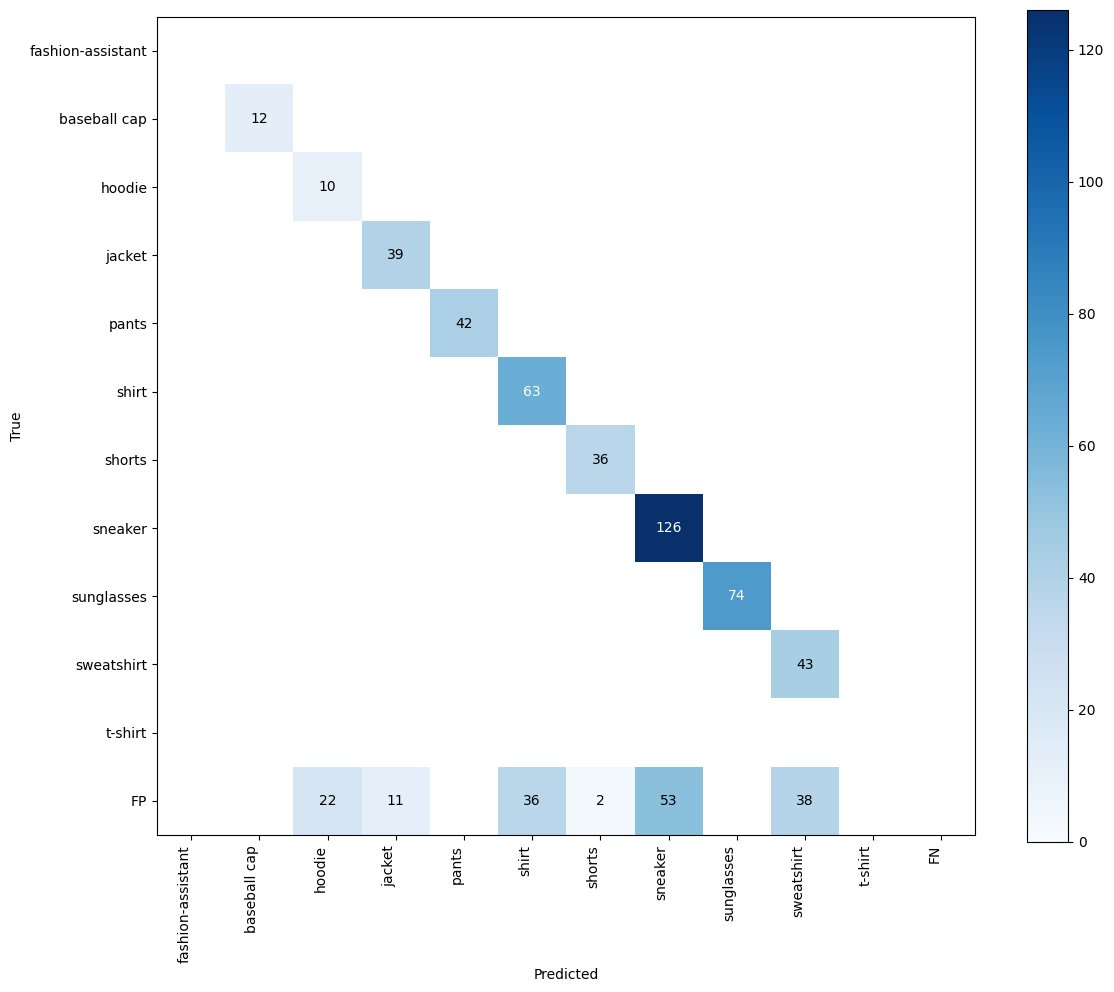
PaliGemma2 for instance segmentation it blows my mind how versatile this model is! - used google/paligemma2-3b-pt-224 checkpoint - trained on A100 with 40GB VRAM - trained only text decoder colab with very dirty fine-tuning code: https://t.co/HsOGDntGOL https://t.co/7BjyDN83eg
PaliGemma2 for image to JSON data extraction - used google/paligemma2-3b-pt-336 checkpoint; I tried to make it happen with 224, but 336 performed a lot better - trained on A100 with 40GB VRAM - trained with LoRA colab with complete fine-tuning code: https://t.co/M1lbYXQUg6 http

Summary of today's OpenAI announcement (day 3): - Introduces their Sora product for video generation (https://t.co/9z5swMKwXd) - Launching in the US and most countries internationally - You can use your ChatGPT account to access it (included in Plus and Pro) 1/n https://t.co/HQgc4dLOPc

Sora System Card https://t.co/t11iIwYh4C
Get all the benefits of LlamaParse Premium mode while optimizing your costs with our new Auto Mode! Auto Mode parses your document in our standard, cheaper mode but upgrades selectively to our more accurate Premium mode on a variety of triggers that you control, including: ➡️ On images ➡️ On tables ➡️ Specific strings ➡️ Even regular expressions! It's a great way to get the very best results out of LlamaParse. Learn more here: https://t.co/j3JRp4l9nI Or check out the example notebook showing all the features: https://t.co/ZrBpAW1dr2
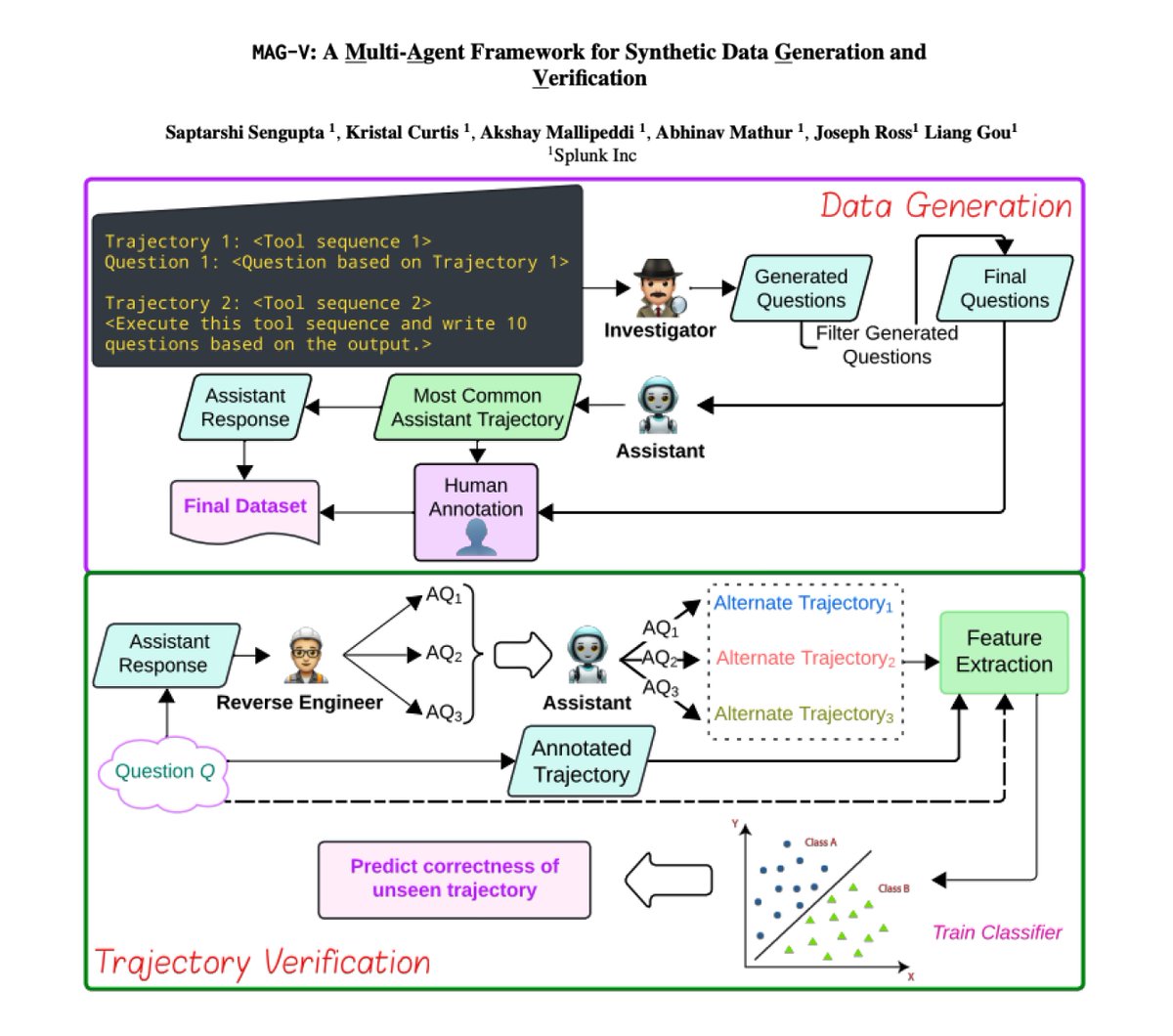
A Multi-Agent Framework for Synthetic Data Generation Presents MAG-V, a multi-agent framework that first generates a dataset of questions that mimic customer queries. It then reverse engineer alternate questions from responses to verify agent trajectories. Reports that the generated synthetic data can improve agent performance on actual customer queries. Finds that for trajectory verification "simple ML baselines with feature engineering can match the performance of more expensive and capable models."