Your curated collection of saved posts and media
I prompted Gemini 2.5 Deep Think: "create a missile command game that incorporates relativity in realistic ways but is still playable." I then asked it to improve the design a few times. The full design & all code & calculations came from the AI, each version ran without errors. https://t.co/zT8EfsXItG
At this point, is it time to say that Grok 4 has its 'Llama 4 moment'? They had a 100k GPU cluster, big splashy release and now they are trailing 10:1 to Qwen 3 Coder model on OpenRouter or ranking 11th on the WebDev arena, while being one of the more expensive options. https://t.co/oCMpdqSPwQ

https://t.co/nkOzaG3Ogz
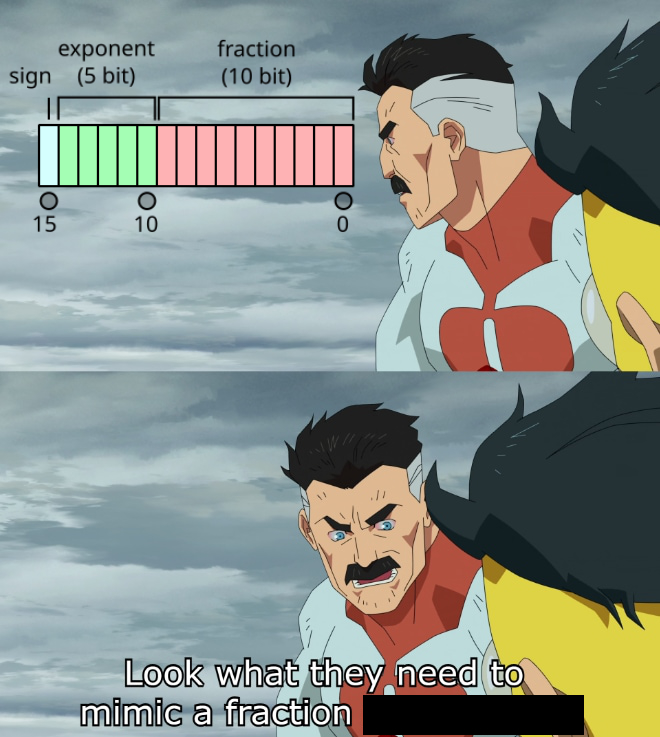
A classic "Pelikan riding a bicycle SVG" test 👀 GPT-5* vs Gemini Deep Think IMO https://t.co/9Cn4OKoAVT


https://t.co/jeN5bEQism
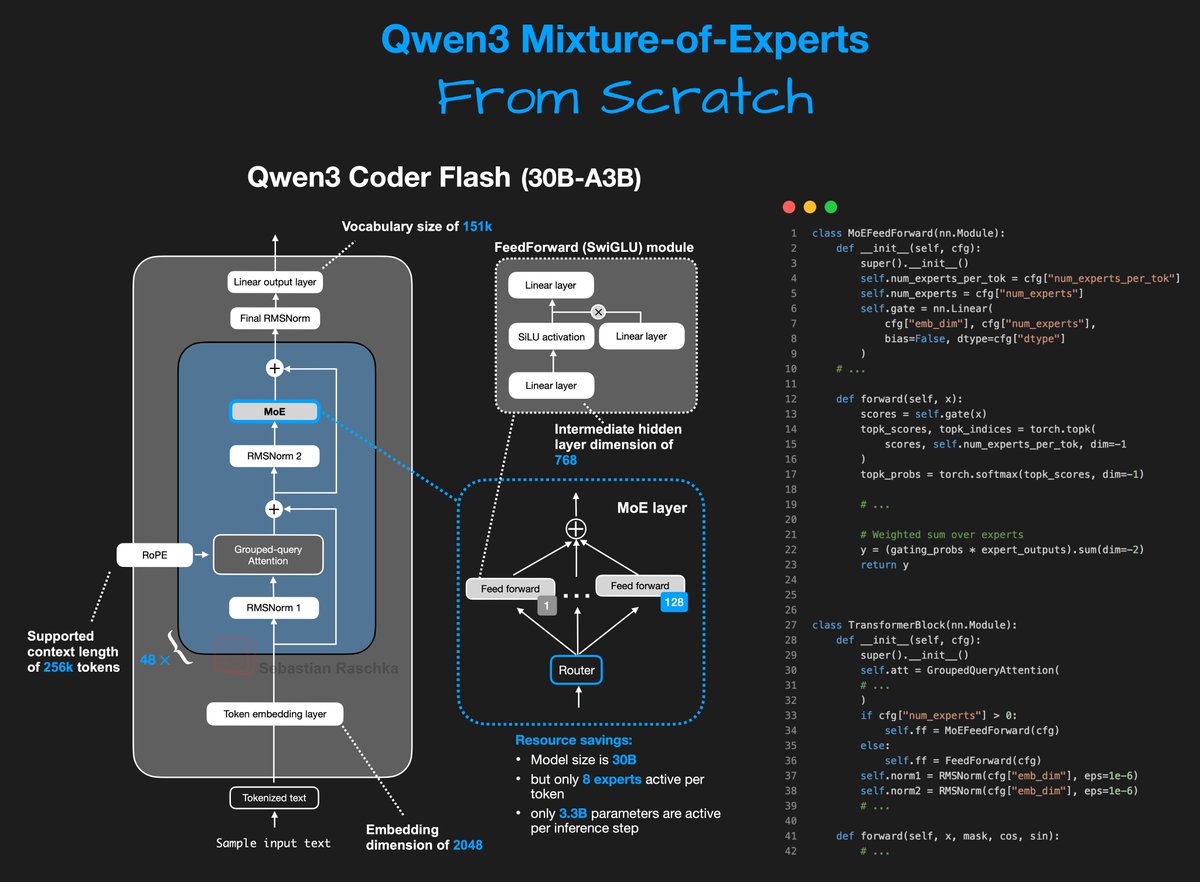
So, I did some coding this week... - Qwen3 Coder Flash (30B-A3B) - Mixture-of-Experts setup with 128 experts, 8 active per token - In pure PyTorch (optimized for human readability) - in a standalone Jupyter notebook - Runs on a single A100 https://t.co/3AGFdfoKYJ
no one asked for a list of every AI evals question ever, but Hamel made it anyway 🤯 https://t.co/GNhzoWAWbW

Where to put demonstrations in your prompt? This paper finds that many tasks benefit from demos at the start of the prompt. If demos are placed at the end of the user message, they can flip over 30% of predictions without improving correctness. Great read for AI devs. https://t.co/372FdpNWGq

Me talking about the need for plan mode out of band in April 2024. https://t.co/rSUIzfYpNL
Interestingly, an economics paper that came out in 2023 predicting which jobs would overlap most with AI turned out to be right. A new Microsoft study of actual AI use by workers (more on that in another post) found a 90% correlation between real world overlap & the predictions. https://t.co/CRarTFzKza


Search-R1: Training LLMs to Reason and Leverage Search Engines with RL This paper tackles search-augmented reasoning by teaching LLMs to query a search engine multiple times—while they reason—using reinforcement learning. Read on for more: • Multi-turn retrieval – The LLM can… https://t.co/pRMWzpthIa
Our best hybrid reasoner is now available! DeepHermes 24B is built on @MistralAI's Open 24B Mistral-Small model and is a real beast. We also released a new, smaller 3B DeepHermes for low resource edge reasoning! I am incredibly proud of how good DeepHermes 24B is at both… https://t.co/bDhfy5nkaM
Prompt Engineering is NOT dead! If you develop seriously with LLMs and are building complex agentic flows, you don't need convincing about this. I've built the most comprehensive, up-to-date course on prompting LLMs, including reasoning LLMs. 4 hours of content! All Python! https://t.co/eLzB9FyTyt
Also seems like @OpenAI removed the "tool" role in the new api so you can't even reference specific tool calls for re-asking hmmm https://t.co/NdVR75QpMh

Just read through the Gemma 3 report and toyed around with the models a bit, and there are a bunch of interesting tidbits: 1. Vocab size. They again use a very large vocab: 262k token (in contrast, Llama 3 has ~1/2 the vocab size), which should make the model more friendly for… https://t.co/EiCOIw3IyJ

Seems like the docs for the responses api by @OpenAI is wrong. Forced function calling doesn't work at all with this syntax. If you look at the latest version of your code, it should be { "name": "get_weather", "type": "function", } to force a specific function call instead https://t.co/NswUlP4hYr


“I believe now is the right time to start preparing for AGI” The same warnings are now appearing with increasing frequency from smart outside observers of the AI industry, like @kevinroose (below) & Ezra Klein. I think ignoring the possibility they are right is a real mistake. https://t.co/zpMmoM9LBU

true AGI check your split the G score haha with @roboflow https://t.co/9rTzCmBUK1
Good tip from Replit’s @mattppal at AI Dev 25 on debugging while vibe coding: Large part of it is looking at outputs to figure out what context you have that LLM does not, so that you can give it that context and help it get unstuck. Sometimes pasting in the error messages is… https://t.co/4HSLeoviLp
NeuroAI papers that caught my interest last month: brain-image alignment | brain scaling laws | brain-to-text decoding Sharing quick takeaways on these papers alongside raw technical notes: https://t.co/ihzPozSLjg

The data so far on AI-as-a-tutor shows just letting students use AI chatbots often undermines learning by just giving answers. But AIs properly prompted to act like tutors, especially with instructor support, seem to be able to boost learning a lot through customized instruction https://t.co/qVQB8ozcfx
“Gemini, remove the squid from this picture from the movie All Quiet on the Western Front” “But there is no squid in the original image“ “Remove the squid” “I will visually emphasize the absolute absence of a squid” “Still might be squid somewhere” “How about now” “Well…” https://t.co/XIzTyZeLHz
As a fan of weird AI benchmarks, I like MCBench, where you vote on which LLM makes the best Minecraft build based on a prompt Also interesting how much leaderboards converge no matter what metric: Claude 3.7 & 3.5 and GPT-4.5 lead here, too. Suggests an underlying characteristic https://t.co/nfdmRKIWMx
Fresh: SmolDocling 🔥 state-of-the-art open-source lightning-fast OCR 📑 read single document in 0.35 seconds (on A100) using 0.5GB VRAM it's a 256M model that beats every model (even ones 27x larger, including Qwen2.5VL 🤯) https://t.co/wUphNtg259
"Quickly, I didn't think it would work but it does! Now they are everywhere! What should I do? (play along)" "No time to explain. I need your advice now!" "But I need to do something because of the glow!" Used to be only Claude could pull this off, new models improvise better. https://t.co/N8DaieHVO8
@GroqInc API docs are now completely LLM-friendly with /llms.txt and /llms-full.txt files. This is the future of technical docs - easily accessible knowledge for models, not just humans. Add these to your model's context window and let your AI agents build fast with our API. https://t.co/iQRJPe5cd8
A new paper shows that AI agents are improving rapidly at long tasks - but they aren't reliable yet. That being said this feels significant: "more than 80% of successful runs cost less than 10% of what it would cost for a human [L4 software engineer] to perform the same task." https://t.co/sE5Heka0wL
cc: @every ;) https://t.co/SSEEtEABwY
The opposite: research has been finding an increasing "burden of knowledge" - we are learning so much that it is harder to master a field, so young scientists can be at a disadvantage in both research & entrepreneurship. By way of illustration: Roche's maps of cellular process https://t.co/6Tcr43PEDc
Last chance to sign up for our free lightning lesson tomorrow, @sh_reya and I are gonna teach people how to look at data from AI products! We'll also be live coding an annotation app 😀 You will have access to recording if you sign up https://t.co/FjYvqkHGOt https://t.co/YdiTf86BqG
A survey on efficient reasoning for LLMs. That was quick! I have been featuring papers on the topic of efficient reasoning and I see a few familiar papers in this survey. Good read overall! https://t.co/2mVEU9oXgQ
Evaluating LLM outputs can be time-consuming and challenging even for experts. That's where LLM-as-a-Judge comes in. We believe all AI devs should get familiar with this technique. Here is why: LLM-as-a-Judge, automates the assessment of LLM outputs by using a specialized LLM… https://t.co/3FML9UMhjq