Your curated collection of saved posts and media
@dee_bosa allow me to suggest an alternative that avoid the conflict of interest of having the government make policies around a company that has a stake in, and that also allows the government to avoid taking a loss if OpenAI can't pay its bills: https://t.co/TKvLtxSjw5
A small tax on every token produced could be transformative, without putting the government into bed with a specific company. And because every token draws on uncompensated contributions from multiple creators across society, it makes sense.

As AI agents become more capable, managing their costs is becoming just as important as building them. It's another reminder that successful AI adoption isn't only about performance. It's also about governance and control. The best AI strategy is one that's both powerful and sustainable.
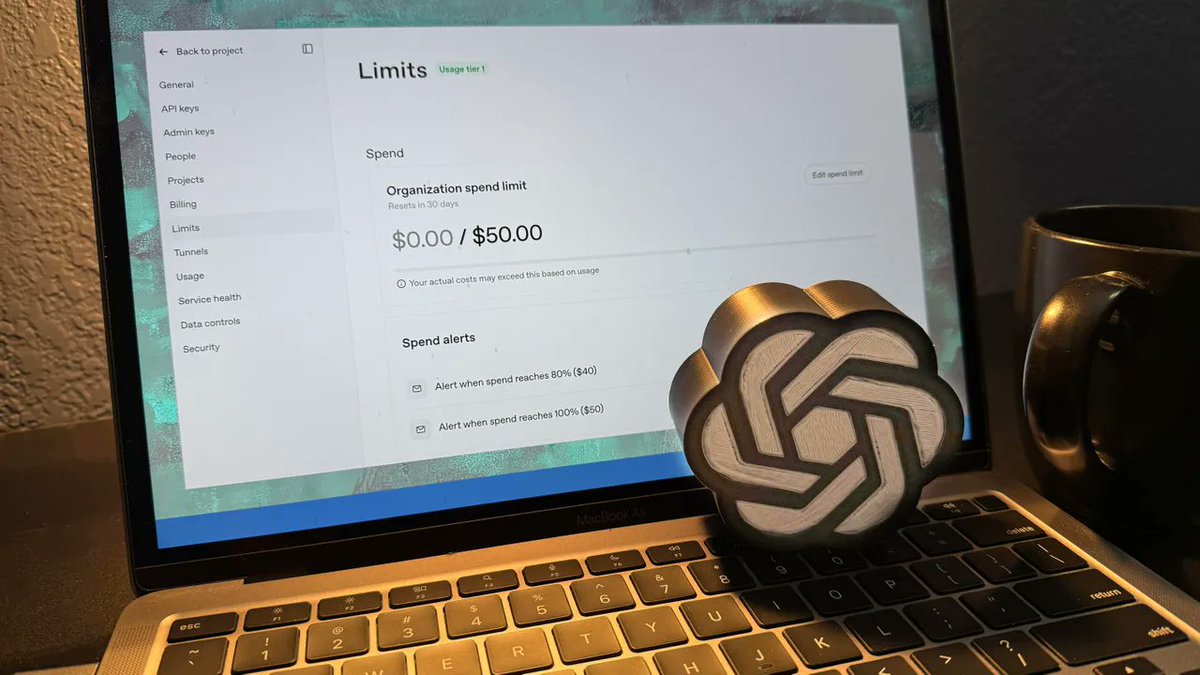
protip: use a different favicon in dev, preview and prod this makes it really easy to distinguish your tabs from each other, so you don't accidentally look at prod and wonder why your code changes didn't apply https://t.co/501hZ5gsNT
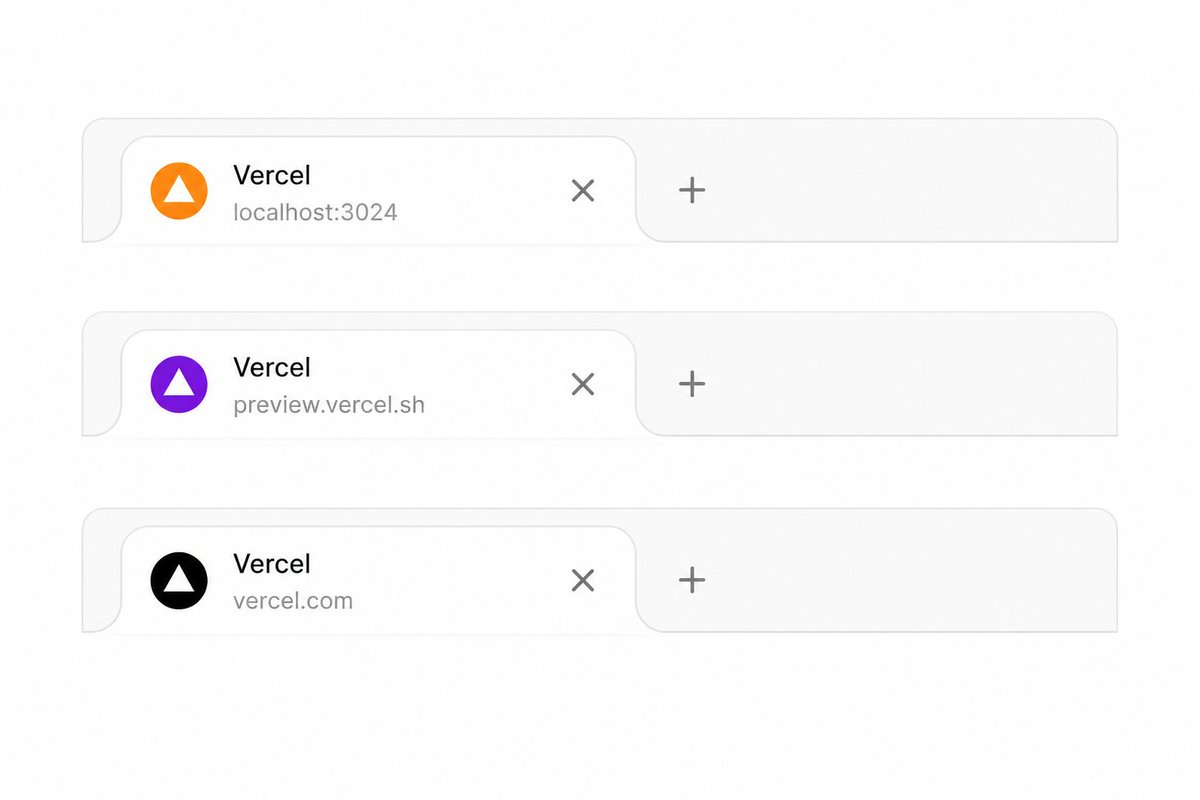
codex building an android app, stops to check the weather in seoul for no reason https://t.co/5R8FweObMi
Accepted to #ECCV2026! 🎉 We've also released the code, it should work like a charm. If it doesn't, feel free to poke @roodiiiiiiiii 😄 https://t.co/t5M0J7S1GR
Group3D MLLM-Driven Semantic Grouping for Open-Vocabulary 3D Object Detection paper: https://t.co/8NVynfAm2u https://t.co/RzkYdEKhRk
Are you ready for the open-source AI summer™️? https://t.co/BFex52oxJL
Are you ready for the open-source AI summer™️? https://t.co/BFex52oxJL
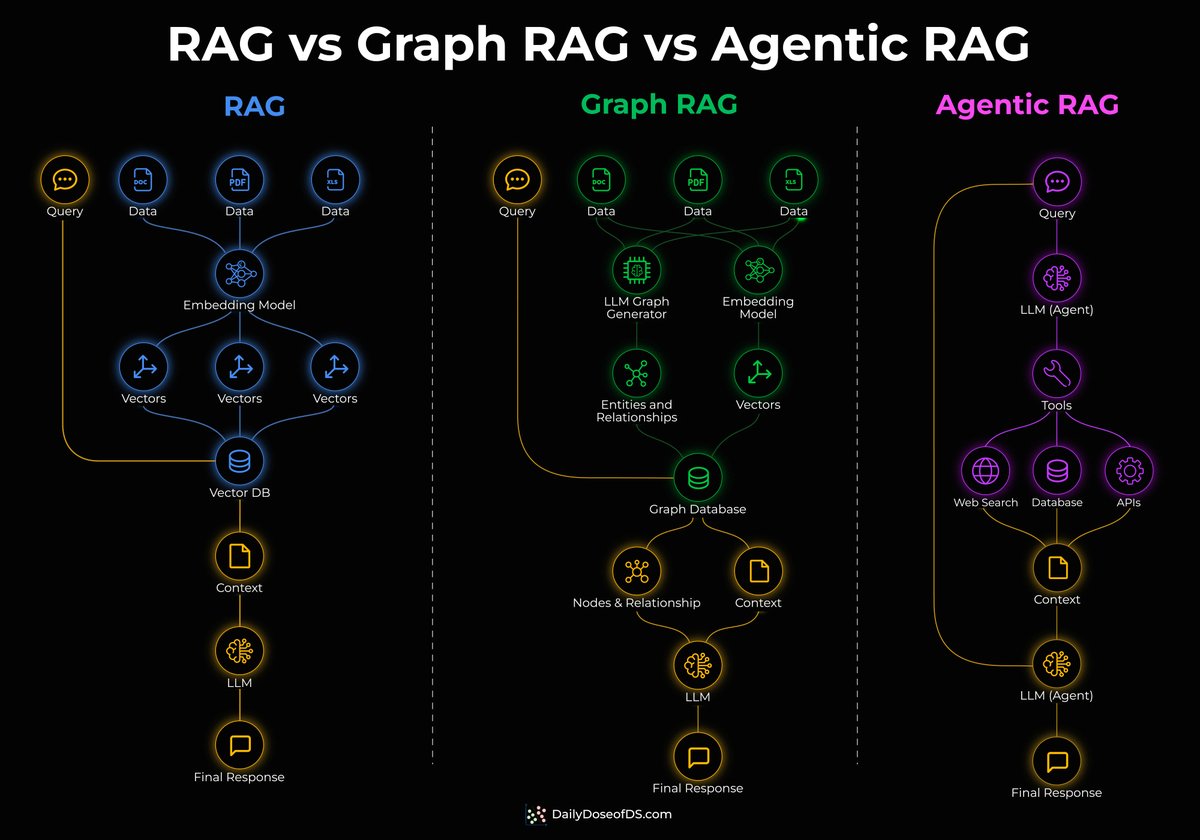
RAG vs. Graph RAG vs. Agentic RAG, clearly explained! Standard RAG embeds documents into vectors and retrieves the most similar chunks via similarity search. For direct factual lookups, this works well. But it breaks down when a query needs to connect facts spread across multiple documents. Similarity search retrieves individual chunks, not the relationships between them. Graph RAG adds a knowledge graph layer on top. → During indexing, an LLM extracts entities and relationships from the documents. → During retrieval, the system traverses these connections instead of relying on embedding similarity alone. This is what enables multi-hop queries. Say a vector DB stores three facts about internal services: ↳ "The checkout service uses payments API." ↳ "The payments API runs on cluster-3." ↳ "Cluster-3 is scheduled for maintenance on Friday." Someone asks: "Will the checkout service be affected by Friday's maintenance?" Vector search can likely retrieve facts 1 and 3 because the query mentions "checkout service" and "Friday maintenance." But it will miss fact 2, which connects the payments API to cluster-3. That middle fact sits too far from the query in embedding space. It mentions neither "checkout" nor "maintenance," so it never makes it into the retrieved context. A knowledge graph connects these as linked entities, and graph traversal finds the full path in one query. Agentic RAG takes a different approach entirely. Instead of a fixed retrieval pipeline, an LLM agent decides at query time which tools to invoke, which sources to query, and in what order. Check the visual below to understand the three architectures thoroughly. One thing to note here is that these three aren't levels of sophistication that you need to graduate through. Instead, they solve different query types. ↳ Single-hop factual lookups → standard RAG ↳ Multi-hop relationship queries → Graph RAG ↳ Dynamic multi-source tasks with tool use → Agentic RAG ---- Each of these architectures gets better when the underlying retrieval layer is efficient. I recently wrote about a new RAG approach that cuts corpus size by 40x, reduces tokens per query by 3x, and improves vector search relevance by 2.3x. The article is quoted below.
https://t.co/De2DxpBoD2
We don’t take stakes in healthy companies. Proposing that as last ditch regulatory capture attempt in commodity market is 😢 … or at best un-American disingenuous WWE politics, not pro-market, not pro-freedom. https://t.co/fW0QqtDZhC


Ever wondered why a PyTorch CI test failure name doesn't exactly match your source file? Because PyTorch tests are generated dynamically at import time across various devices and dtypes, CI failures often display specific names that differ from the original template. Understanding how device-generic tests, OpInfos, and CI sharding fit together can significantly speed up your development and contribution workflow. Read our latest blog which provides a contributor's perspective on how to get started with testing in PyTorch. Link in comments 👇

This is not for people who build World Models. I get an exclusive look inside one of the best AI labs in the world in Silicon Valley, Institute of Foundation Models, and talk with Hector Liu, @waterluffy, who leads World Model research there. These will be the “brains” of humanoid robots, and the key tech for all sorts of other things. I met with him to try to figure out how far away a truly generalized robot is. More on this lab and what they do at: https://t.co/fY4qGOB9WJ
Can coding-agents replicate scientific ML papers? We know this is possible because we can already do this @dair_ai. Still a great read. So they try to replicate an ML paper from its materials alone. They use a coding-agent skill that turns each selected paper claim into a target with recorded evidence. The agent reconstructs the method, runs experiments, links outputs to provenance, compares against the paper's claims, and passes validation checks before completion. Completion depends on workspace evidence, not on the agent's final message. Across twelve runs over four scientific ML papers, all twelve workspaces pass the completion gate and all 158 recorded targets are matched with report coverage. Yet repeated runs still differ in how papers are split into targets, in numerical fidelity, in elapsed time, and in the rules used to accept evidence. Basically the completion becomes reproducible even when the path is not. Paper: https://t.co/IkhknqCUiv Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

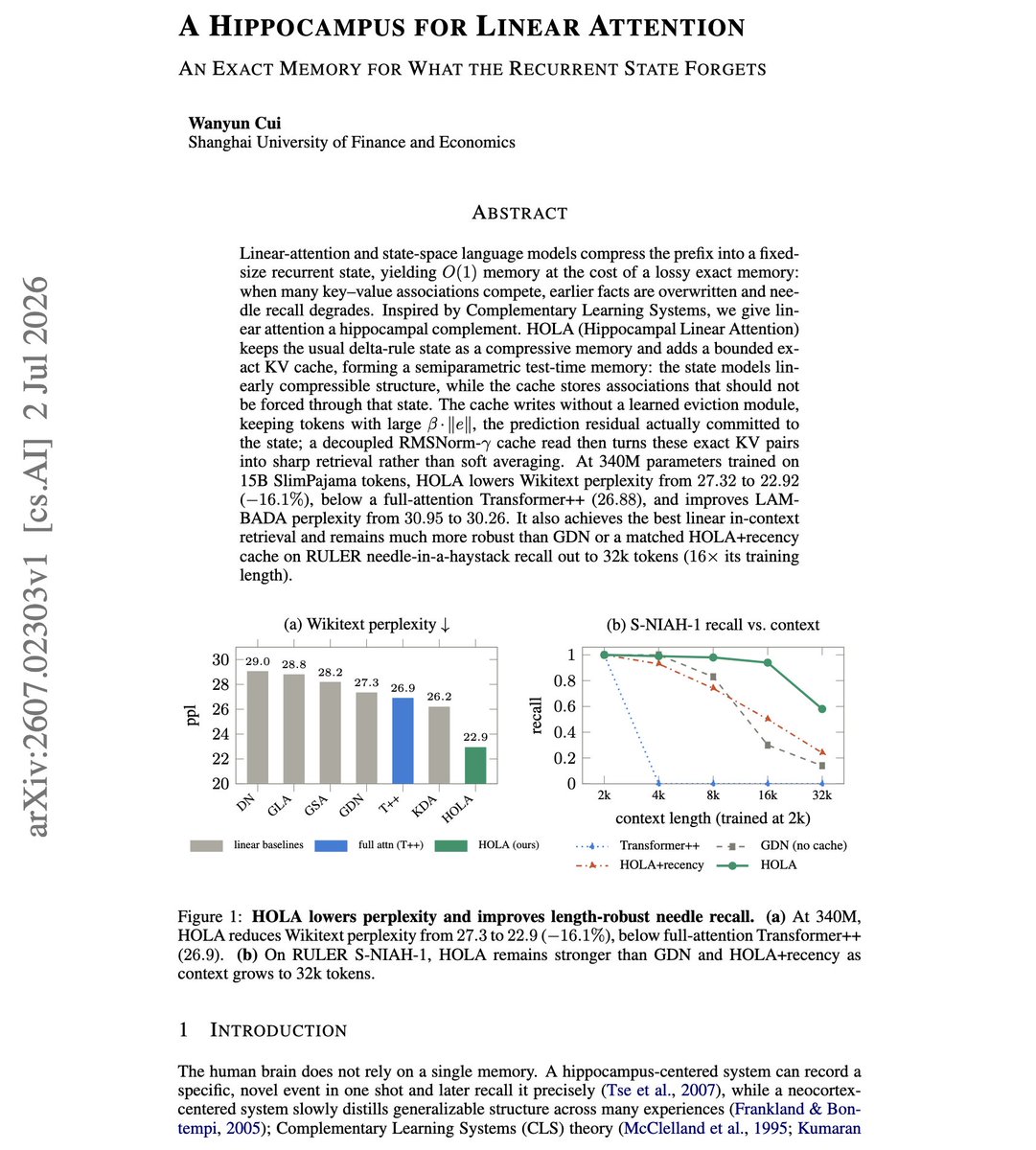
NEW paper worth reading. (bookmark it) The basic idea is to pair a compressive recurrent state with a small exact memory, which helps to recover long-range recall without giving up the efficiency of linear attention. More on it below: Linear-attention and state-space models compress the whole prefix into a fixed-size state. That buys O(1) memory, but when many key-value associations compete, earlier facts get overwritten and needle recall degrades. HOLA gives linear attention a hippocampal complement. It keeps the usual delta-rule state as compressive memory and adds a bounded exact KV cache, forming a semiparametric test-time memory. The state models linearly compressible structure while the cache stores associations that should not be forced through it. The cache writes without a learned eviction module, keeping only tokens whose prediction residual was actually committed to the state. At 340M parameters on 15B SlimPajama tokens, HOLA lowers Wikitext perplexity from 27.32 to 22.92, below a full-attention Transformer++ at 26.88, and stays robust on RULER needle recall out to 32k tokens, 16x its training length. Paper: https://t.co/z1Jzp7qQ6B Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Local AI crowd FTW. Watch us make it the default. https://t.co/wTNS77Qf2n


@bokuHaruyaHaru Using RL to imprint your flavour of anthropomorphism as bias is highly questionable. AI industry using GD instead of code: IF User_query && In(RL_samples) THEN AI_lab_behaviour (“I’m a helpful assistant/evil/add your own”) ELSE weights END https://t.co/XROxKntmaW

Happy Independence Day, from Tokyo 🇺🇸 https://t.co/tqooIETSWB


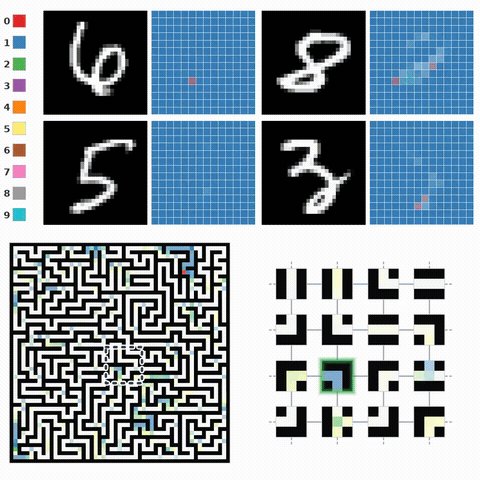
Excited to share our paper, “Learning Multi-Agent Coordination via Sheaf-ADMM” to be presented at #ICML2026 Blog: https://t.co/F5CVepgivO Most AI models process information as one giant, monolithic block. But in nature, intelligence often comes from a group of individuals working together, where each individual only has a limited view of the world. We built a framework called Sheaf-ADMM to study how this kind of collective problem-solving works. We divide a complex task into smaller overlapping pieces, and assign one agent to each piece. To solve the global puzzle, the agents negotiate in three simple steps: 1. Local Guesses: Every agent looks at its limited view and proposes a solution. 2. Finding Common Ground: Agents communicate with their direct neighbors to smooth out conflicts. They do not need to agree on everything, but they must agree on the boundaries where their tasks overlap. 3. Remembering Disagreements: If neighbors cannot agree, they keep a memory of that conflict. This memory forces them to try harder to compromise in the next round. We tested this on problems where no single agent has enough information to succeed alone: • Multi-Agent Sudoku: Each agent sees only a single row, column, or 3x3 box. The framework achieved a 93% solve rate, while a parameter-matched message-passing baseline scored 11%. • Image Classification: When we tested canvas-size domain shifts, a standard CNN dropped to 11% accuracy on MNIST, while our method retained 86%. • Maze Pathfinding: Sheaf-ADMM matches a message-passing baseline’s accuracy while agents communicate over a 5-dimensional channel, 8x smaller than that required of the baseline (42). Traditional message-passing networks hide their reasoning inside opaque hidden states. Our framework makes coordination completely transparent. You can watch exactly how local agents debate, compromise, and eventually reach a global consensus. Sheaf-ADMM draws inspiration from two fields with long histories in distributed consensus: ADMM from distributed optimization, and sheaves from applied topology. We think these perspectives may offer insights for the distributed, multi-agent AI systems increasingly being built today. Read our full paper: https://t.co/RoOHfekjQE Code: https://t.co/KDKZRcbuQH

@badlogicgames LLMs love our crazy ex-inspired edit tool BTW: https://t.co/OENsnw0K1I
Introducing EdgeBench, a benchmark designed to study how agents learn from environments over at least 12~72-hour runs. We find that performance follows a log-sigmoid function of environment interaction time with high precision. EdgeBench is built with three ingredients: - 🌍 Real & Diverse: 134 real-world tasks across 6 task categories, spanning scientific problems, professional knowledge work, software engineering, optimization, formal math, and games. - ⏳ Ultra-Long-Horizon: Each task supports 12–72 hours of agent work. Recorded human effort averages 57.2 hours. - 🔁 Informative Feedback: Agents receive real-world feedback for continuous improvement. After 38,000 hours of agent runs on EdgeBench, a scaling law for learning from environments emerges: - 📈 As agents interact with task environments over time, their aggregate performance is precisely fit by a log-sigmoid function. - 🧠 This phenomenon can be explained by an elegant theory of graph exploration. We are releasing an initial 51 of the 134 tasks, together with the full evaluation framework, to help advance long-horizon agent research. Check our blog & paper for more findings! Blog https://t.co/nMOzFsOhbT Paper https://t.co/rZb3eWuvik GitHub https://t.co/oemXd4UrFw Dataset https://t.co/P4SQMrM47o Details below 👇🧵
New imagegen automation possibilities unlocked! This is one update many might overlook, but I think it's really helpful for people who need to regularly make images with key elements, like my YouTube thumbnails. You can use up to 16 reference images in imagegen with your codex sub. I made a quick video showing how this works in Hermes
hermes now supports reference-image editing with your codex/chatgpt login drop in a source image + up to 16 reference images, and it transforms them directly not just text-to-image @NousResearch https://t.co/seBDtUVXCL
New sexy mcp.json editor pattern unlocked https://t.co/Mu2tDoxeKF
The best schools won't be defined by how much AI they use. They'll be defined by how well they help students ask better questions, solve problems and think for themselves. That's something no technology should replace. https://t.co/qqD1WrVlK7
With all the routines and slack integrations one could think @AnthropicAI would finally figure out that their CI pipelines on https://t.co/nFQNPYvQYn keep failing and releases are delayed constantly. cc @amorriscode @bcherny
This roller skating is insanely smooth🔥 made with Midjourney v8.1 + GPT Image 2 + Seedance 2 workflow ⬇️ https://t.co/DjmCupm1XV
Tried Renoise Canvas for the first time and it’s actually really powerful⚡️ My workflow: Midjourney v8.1 → character creation GPT Image 2 → character sheet Seedance 2.0 → video generation Prompt ⬇️ https://t.co/lQ8M486EZ6
@PaulADW Is this like this? https://t.co/mNLYcJRLiw
@Velkariano /learn https://t.co/JrXwTUz7e3 and https://t.co/Eiq8kGvhty and https://t.co/g3s4ZOk2a1 on how to setup and use the best memory system

@IndieSuperhuman https://t.co/cBYfSpvaNi https://t.co/P1HyFecLV9
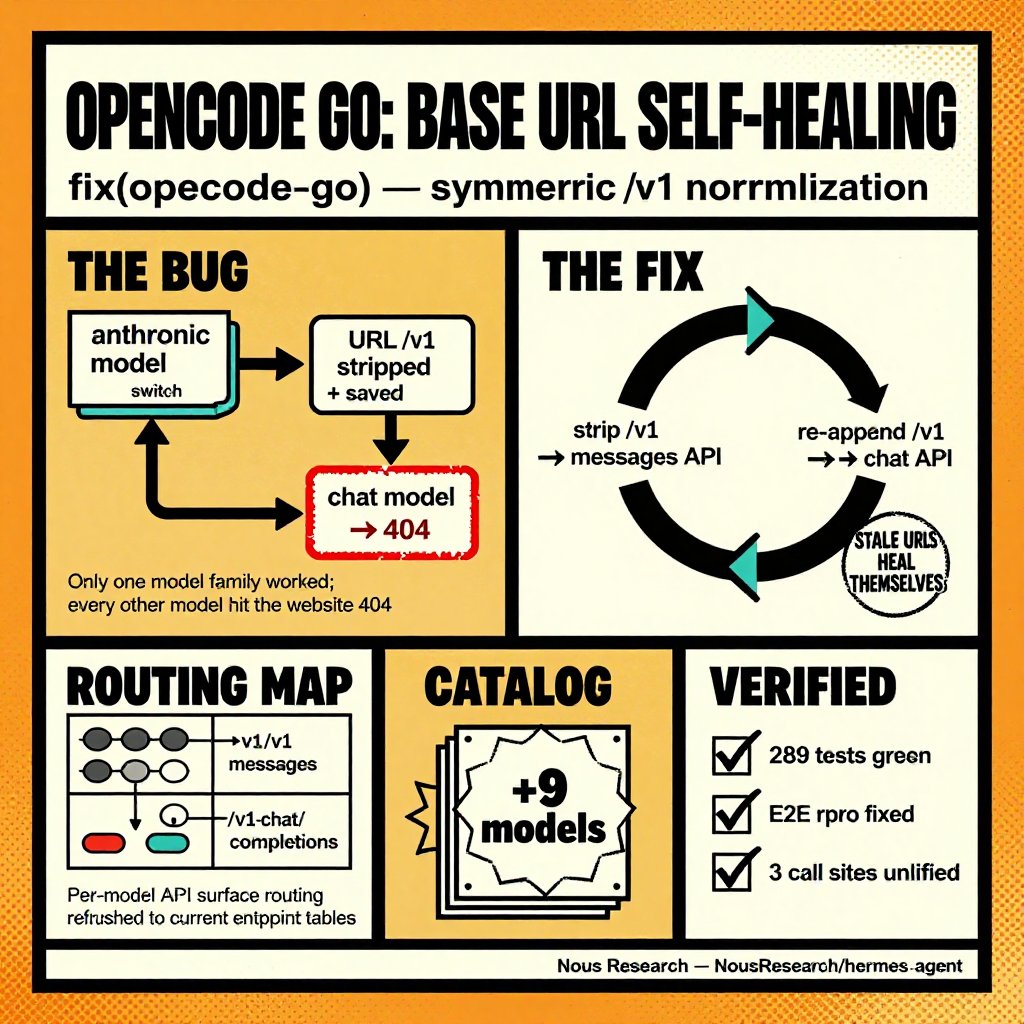
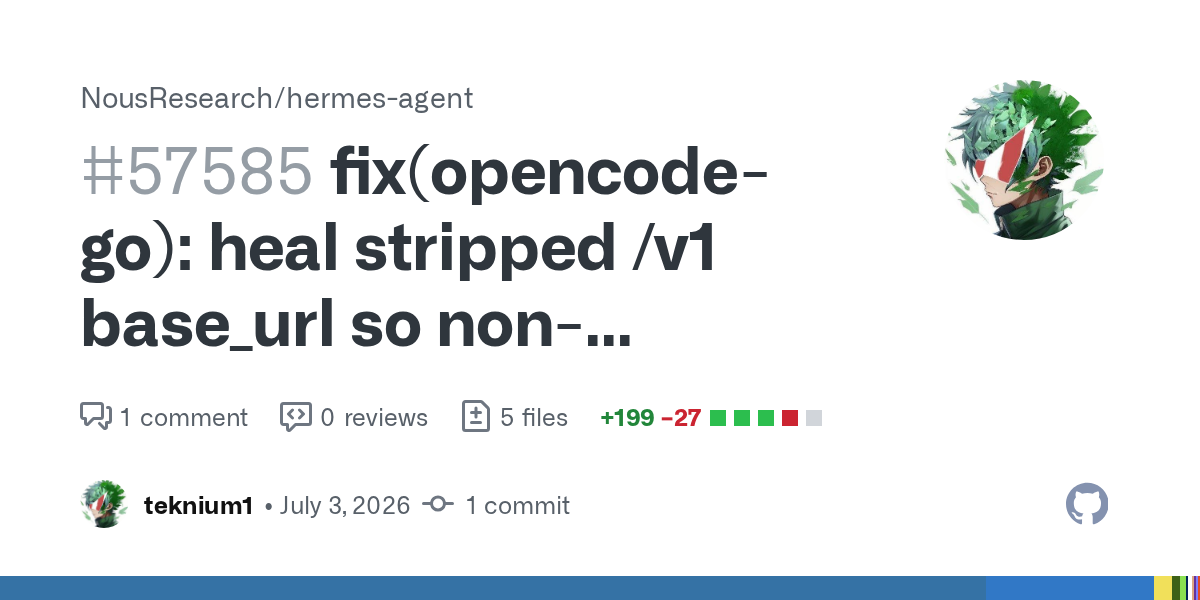
Fable is too much fun to build with. It's just ripping through tasks I throw at it. https://t.co/EQFPHVvCCO
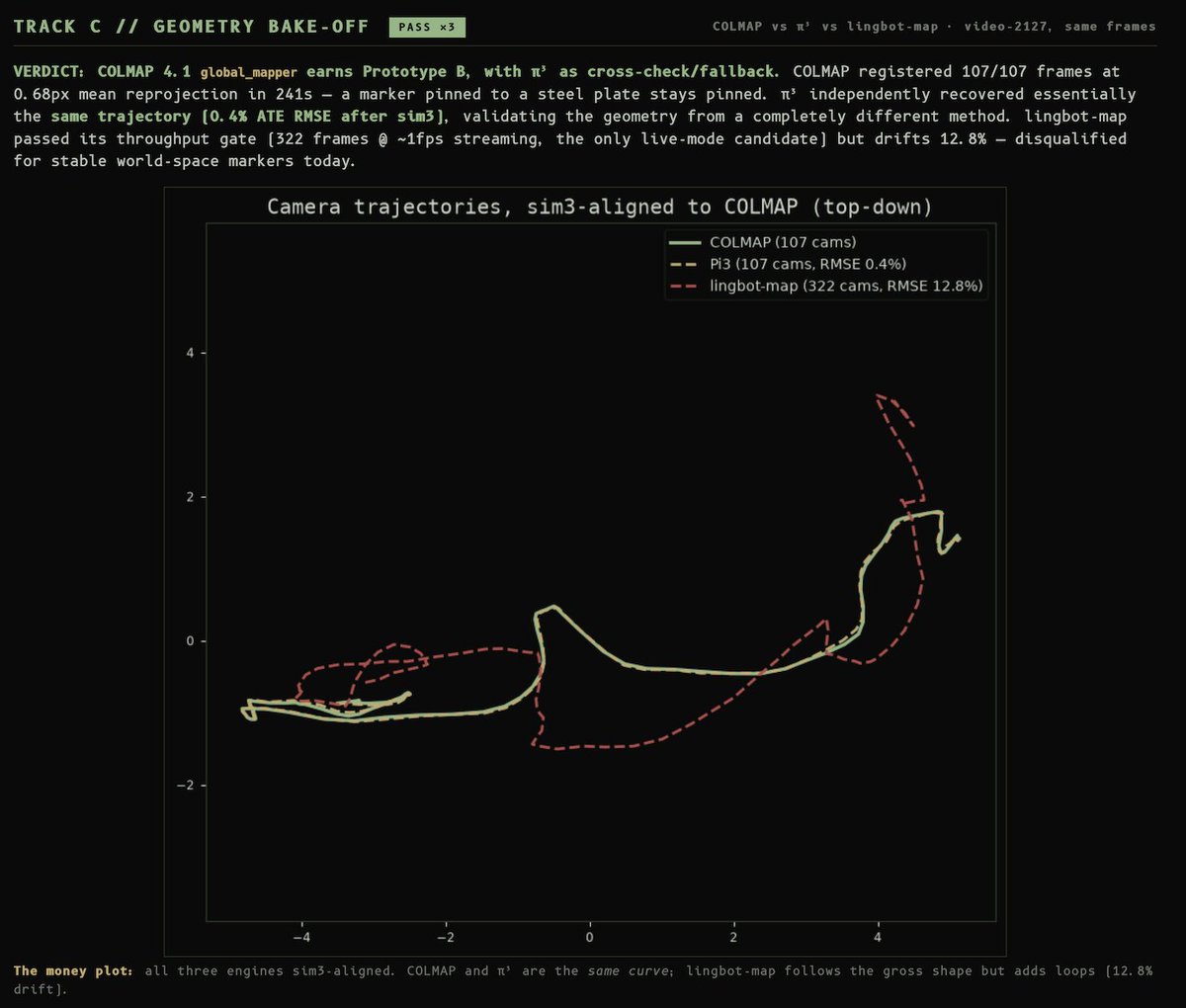
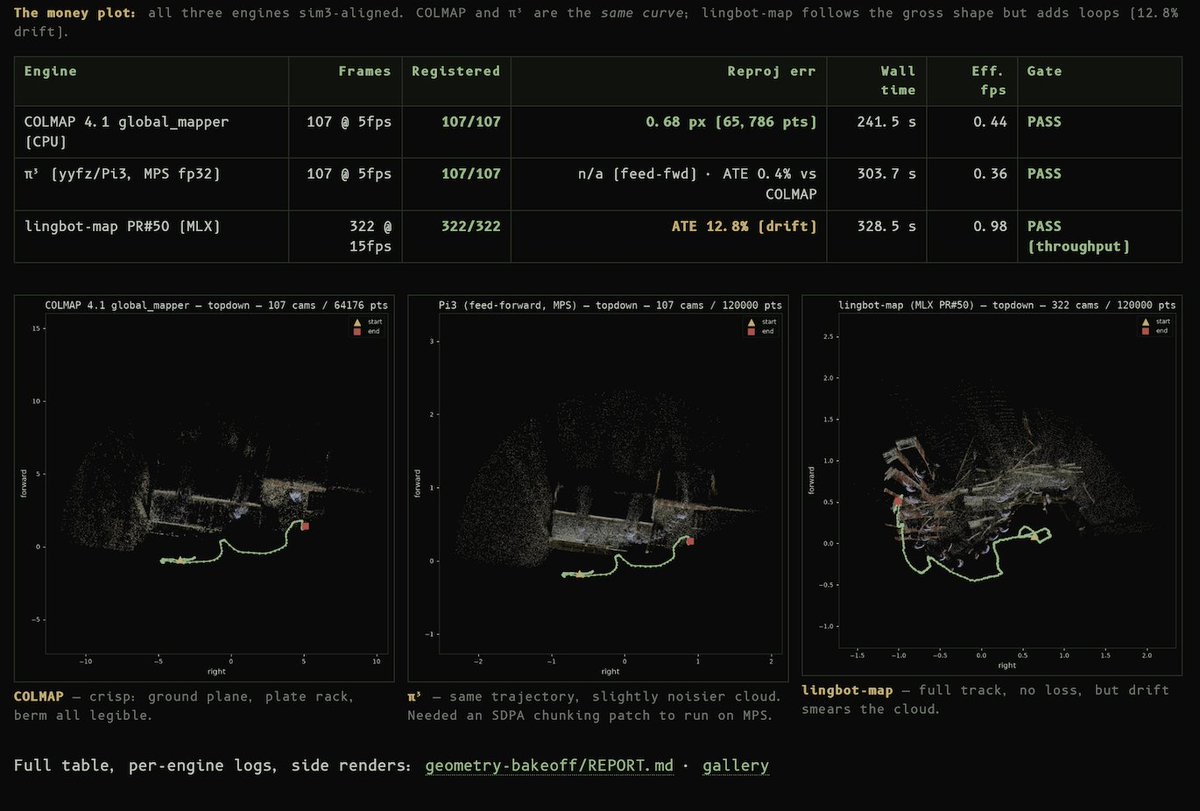
Fable is too much fun to build with. It's just ripping through tasks I throw at it. https://t.co/EQFPHVvCCO
“There’s nothing artificial about AI. It’s inspired by people. It’s created by people. Everybody should care about AI because it's going to impact your individual life, your society and the future generation.” ~ Dr Fei-Fei Li (@drfeifei ) https://t.co/rFWgtN22Bd
Profile of me and the new edition of my book "Rise of the Robots: Technology and the Threat of a Jobless Future," about how #AI will inevitably displace human workers.... by Juha Pippuri Link in the reply (in Finnish) #RiseoftheRobots https://t.co/R42iZLhjQx


https://t.co/j5YbcxzKO7
