Your curated collection of saved posts and media
what https://t.co/iakgX6mwzN

Tomorrow! Our next office hours hangout will be all about MCP. Join the team in our Discord server to ask all of your LlamaIndex questions, but also get a rundown of: ➡️ LlamaCloud MCP servers ➡️ Using existing MCP tools with Agent Workflows ➡️ Serving agent workflows as MCP ➡️… https://t.co/VvPrRAOTez

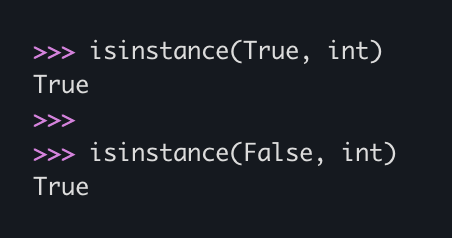
In Python, if you ever need to tell whether you're looking at a bool or an int, start by checking isinstance(x, bool). Because bools... are ints. https://t.co/u5k5flfqeA
How much of my development budget should I allocate to evals? 1: that's probably the wrong question to ask 2: ok, if you really want an answer: 60-80%, but its really just part of building. Most of your time should be spent looking at data Links in reply 1/2 https://t.co/WTuRUDA5Be

AI tools will reduce the need for software engineers the same way that no-code tools reduced this. Being able to specify what software you want to build, how it should be structured, and how *exactly* it should work is... programming. And getting into the weeds, when needed. https://t.co/mvnFr53t0f
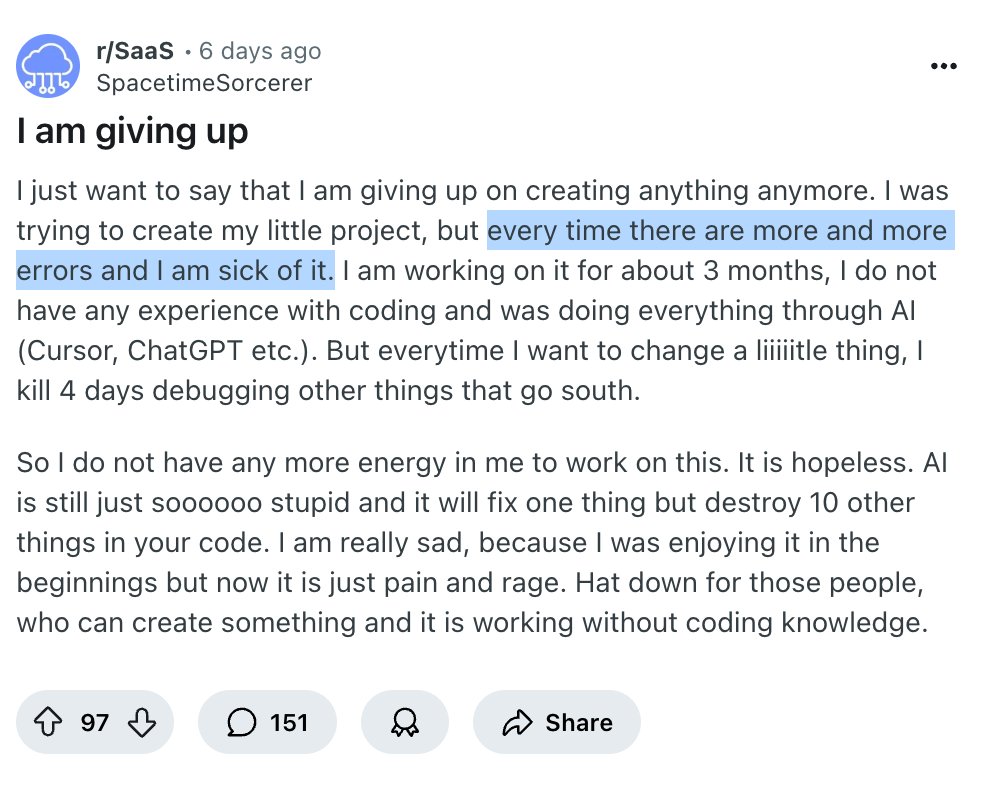
waaat? I've been using MacOS for ~40 years and didn't know about this. Apparently it's existed since System 7 (released 1991). https://t.co/LGDpZmvceM
One of the biggest pain points in using LLMs for large-scale document extraction is actually coming up with the schema in the first place - it’s a long and tedious process ⏳ We built an two-stage, e2e agent workflow that does both schema generation and extraction: 1️⃣ It first… https://t.co/OepeCw8Taw

https://t.co/QoFVBZ0Fo0

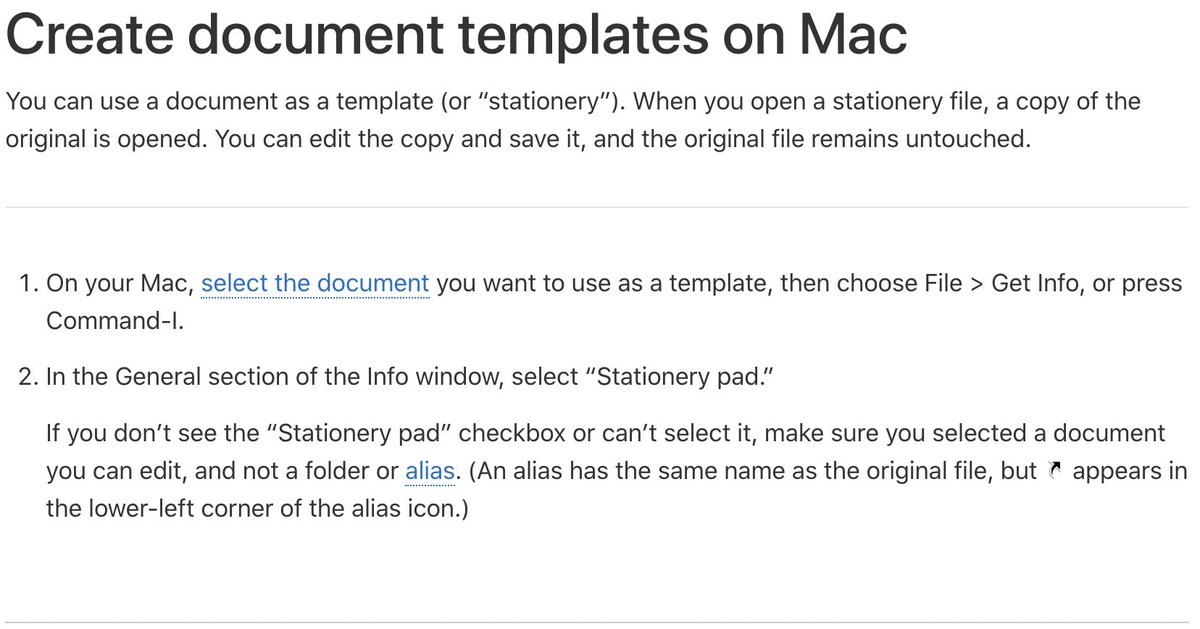
This is happening over and over in my notifications: - Someone asks Grok for a list of "top 10 mutuals" (this behavior seems to spreading virally as people get tagged and notice this is a thing they can do). - Looking at the response, someone notices that Grok is basically… https://t.co/jUeUCRSTKl
More strange cities, this time in Veo 3. I am pretty impressed by how well Veo 3 animates Midjourney images. All of these clips, including the sounds, were generated in a single shot from a Midjourney image & a simple prompt (I picked the best videos from a set of two options). https://t.co/GKgJWZ0NLP
I was experimenting with trying to get AI to create some unhinged @HamelHusain memes, and I decided to see what Claude Artifacts could do....and WTF? https://t.co/xF77AQz9d4

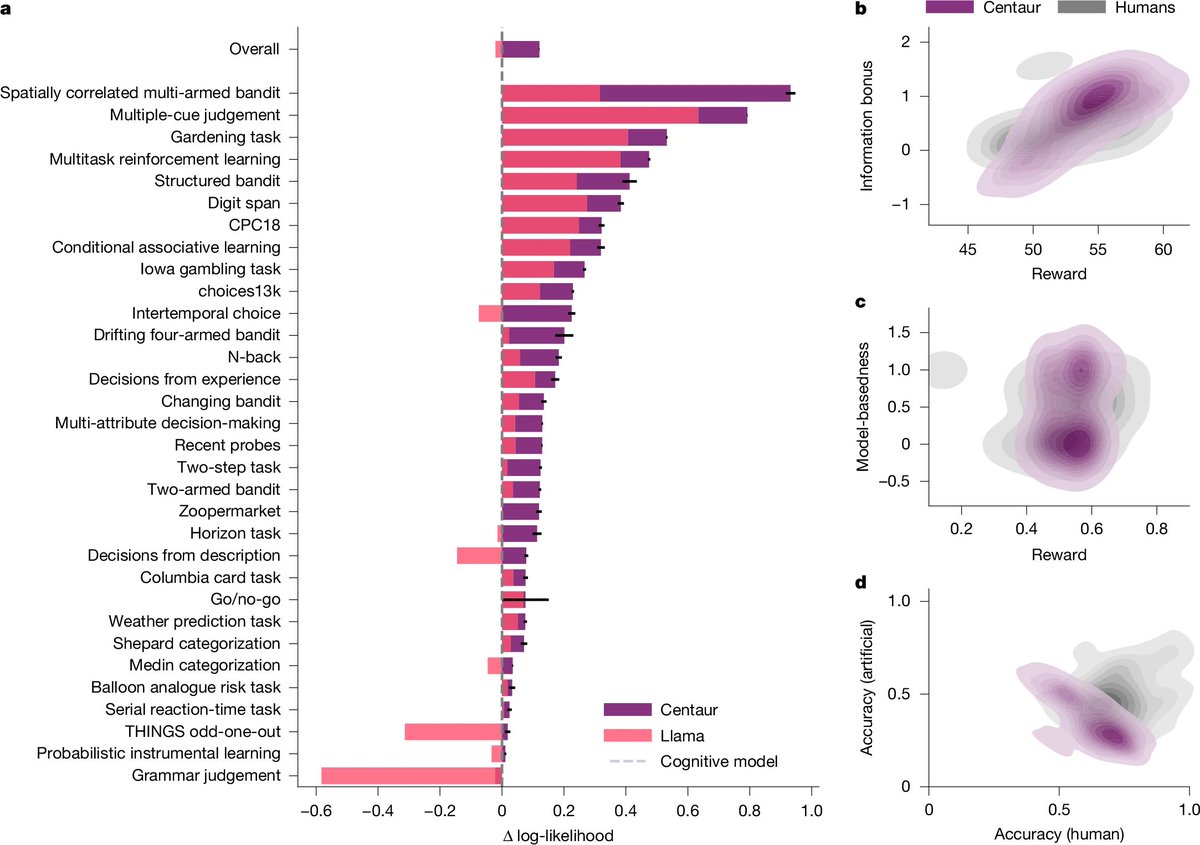
BREAKING: The first foundation model of cognition just dropped. It’s called Centaur, and it mirrors human behavior across 160+ psychology tasks. Here's everything you need to know: https://t.co/0qDlcwOfEt
A disagreement dial would be a really useful thing for AI models. A slider that goes from “I am always right” to “I am always wrong” with intermediate steps. https://t.co/SxbMHus59d

AI Research Agents for ML Achieves state-of-the-art on MLE-bench lite! Using AI to automate the training of ML models is one of the most exciting and promising areas of research today. Lots of cool ideas in this paper: https://t.co/3aQbqTrlBn
He knew me so well 😣 https://t.co/QNmG2Evpi0

ChatGPT is really good at producing thumbnails This is one for LLM judges that you haven't aligned with human labels https://t.co/sPXPyqTb1l

Agentic RAG for Personalized Recommendation This is a really good example of integrating agentic reasoning into RAG. Leads to better personalization and improved recommendations. Here are my notes: https://t.co/2XINjiyUo5

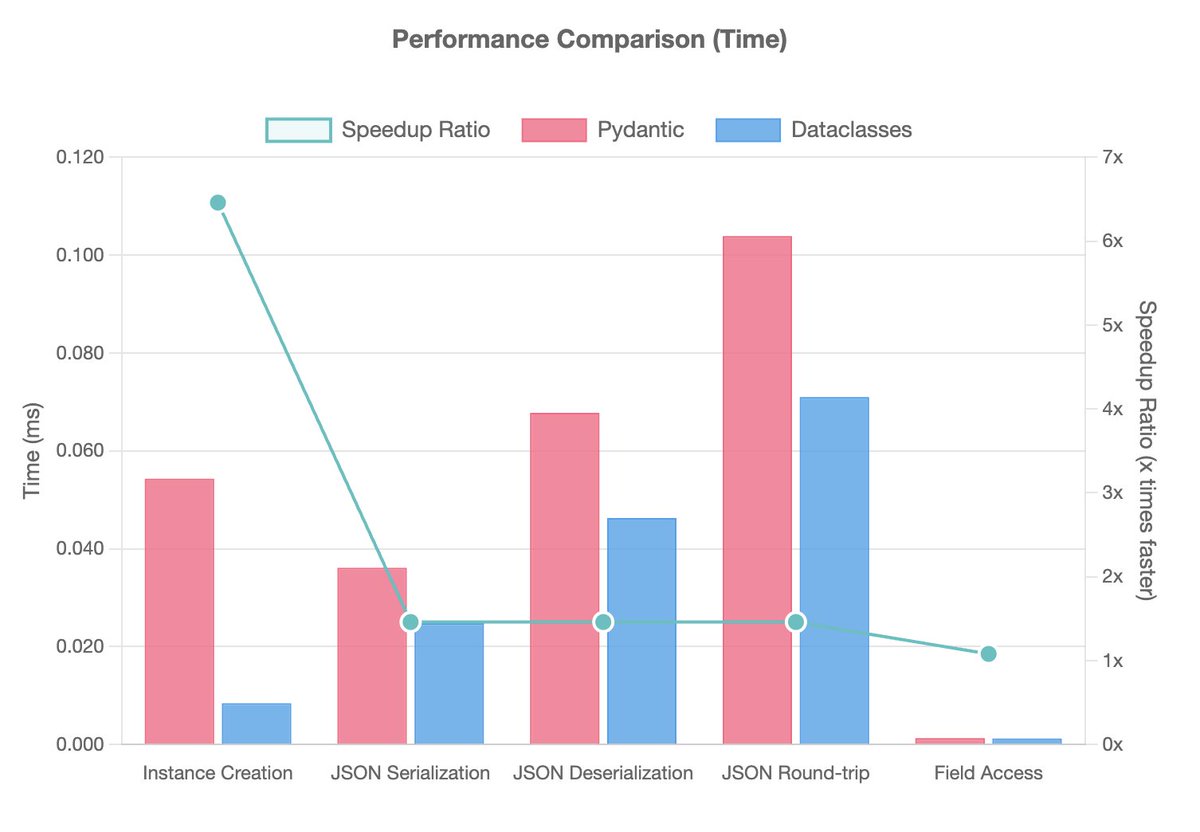
pydantic is all you need for poor performance spaghetti code. its not langchain you dont like, its pydantic anti-patterns. my new blog post identified pydantic anti-patterns - piling pydantic data models within service boundaries, and abusing inheritance over composition https://t.co/jbzia1nSOa
MoE money, MoE problems: it's straight up bonkers that there is not a single finetune of llama 4. zero. zilch. nada. everything on the hub is a reupload. trust me, I've spent the past several weeks trying with torchtune, torchtitan, hf -- anything. it literally just doesn't… https://t.co/sGS80aksgl
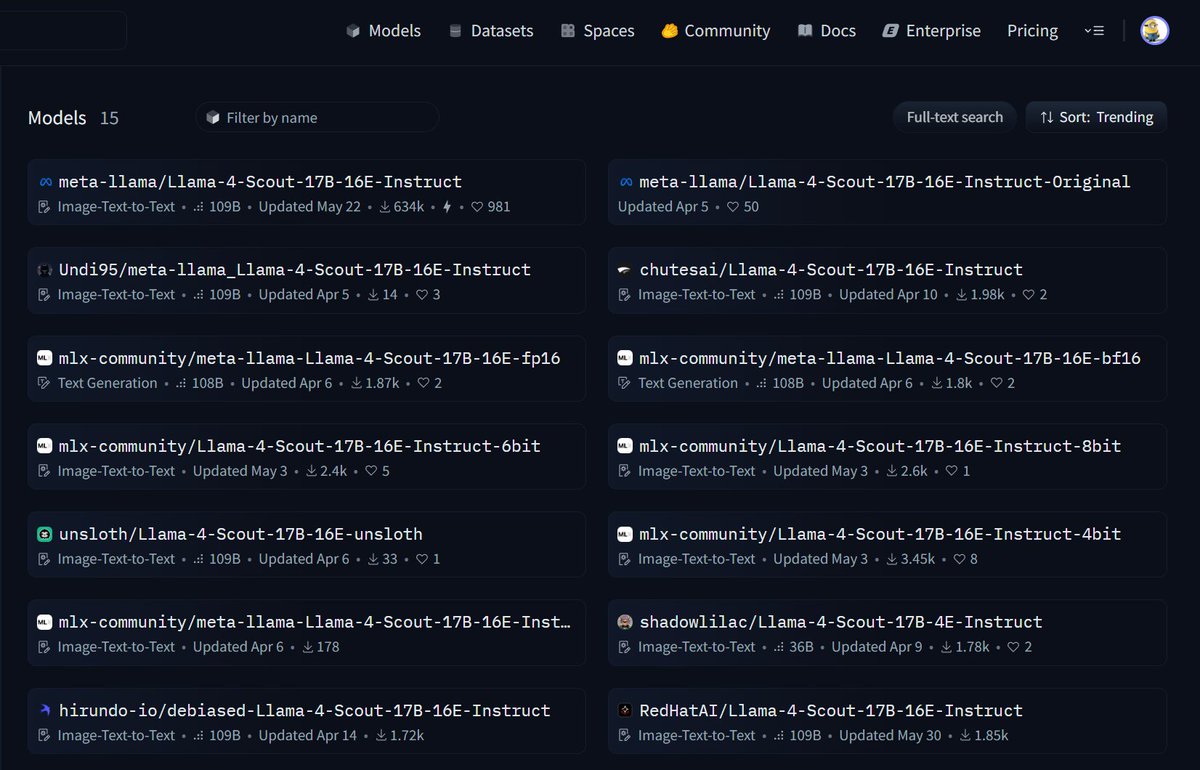
ChatGPT o3-pro identifies a 1965 quote by I. J. Good hand-written in a mix of print and cursive on a note ripped into four strips in reverse order rotated 90° in alternating directions: https://t.co/sTjRUz7ZUB

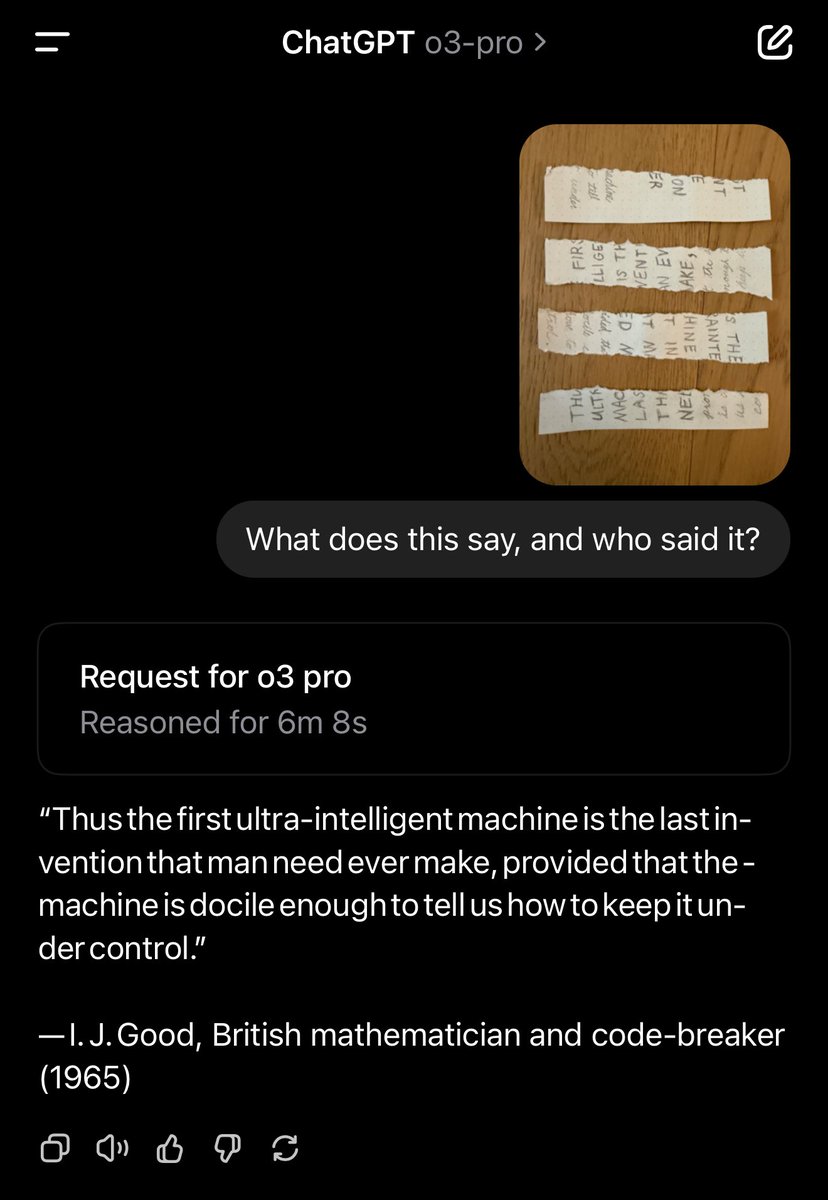
I made a choose-your-own-adventure for AI evaluation strategy Your answers build a personalized roadmap based on task complexity, cost of failure, and your current evaluation It also includes my favourite selection of tips from industry experts like @eugeneyan, @chipro and… https://t.co/AnKC1tfZrE
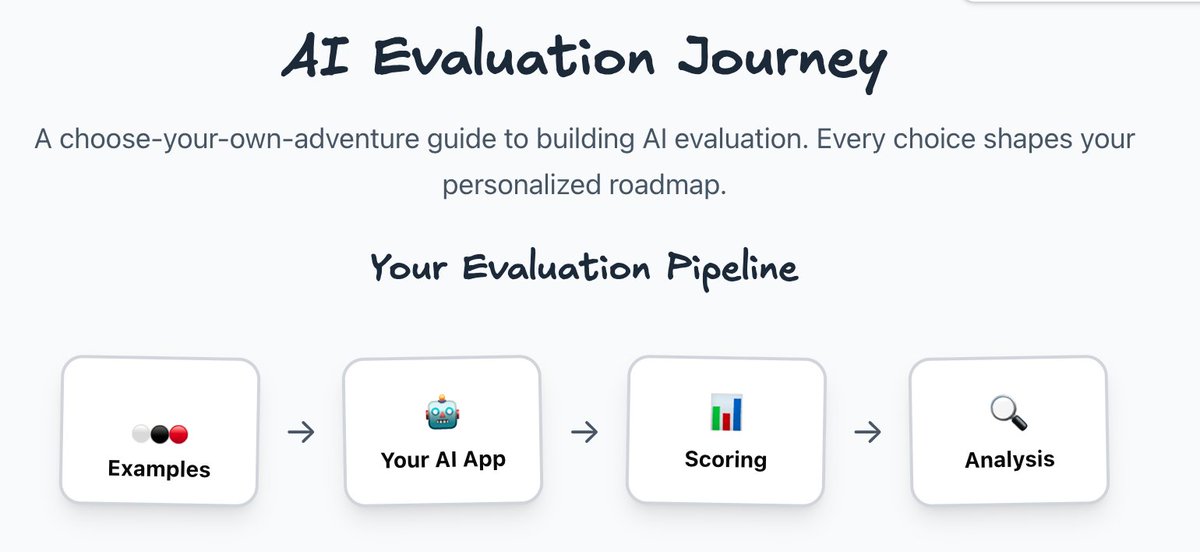
Wow our AI Evals FAQ is front page of HN 🤯 h/t @jeremyphoward for letting me know! https://t.co/GYYUVxfCUq
I’d like to share a tip for getting more practice building with AI — that is, either using AI building blocks to build applications or using AI coding assistance to create powerful applications quickly: If you find yourself with only limited time to build, reduce the scope of… https://t.co/Vxhz1VqA3Q
Since I got so much feedback on my criticism on MCP I wrote down more thoughts on it. I'm also noticing that there is more an more talk about maybe bypassing MCP recently so this fits right in. TLDR: agentic loops work best with codegen and MCP is not composable to help here. https://t.co/KMMO75YGQH

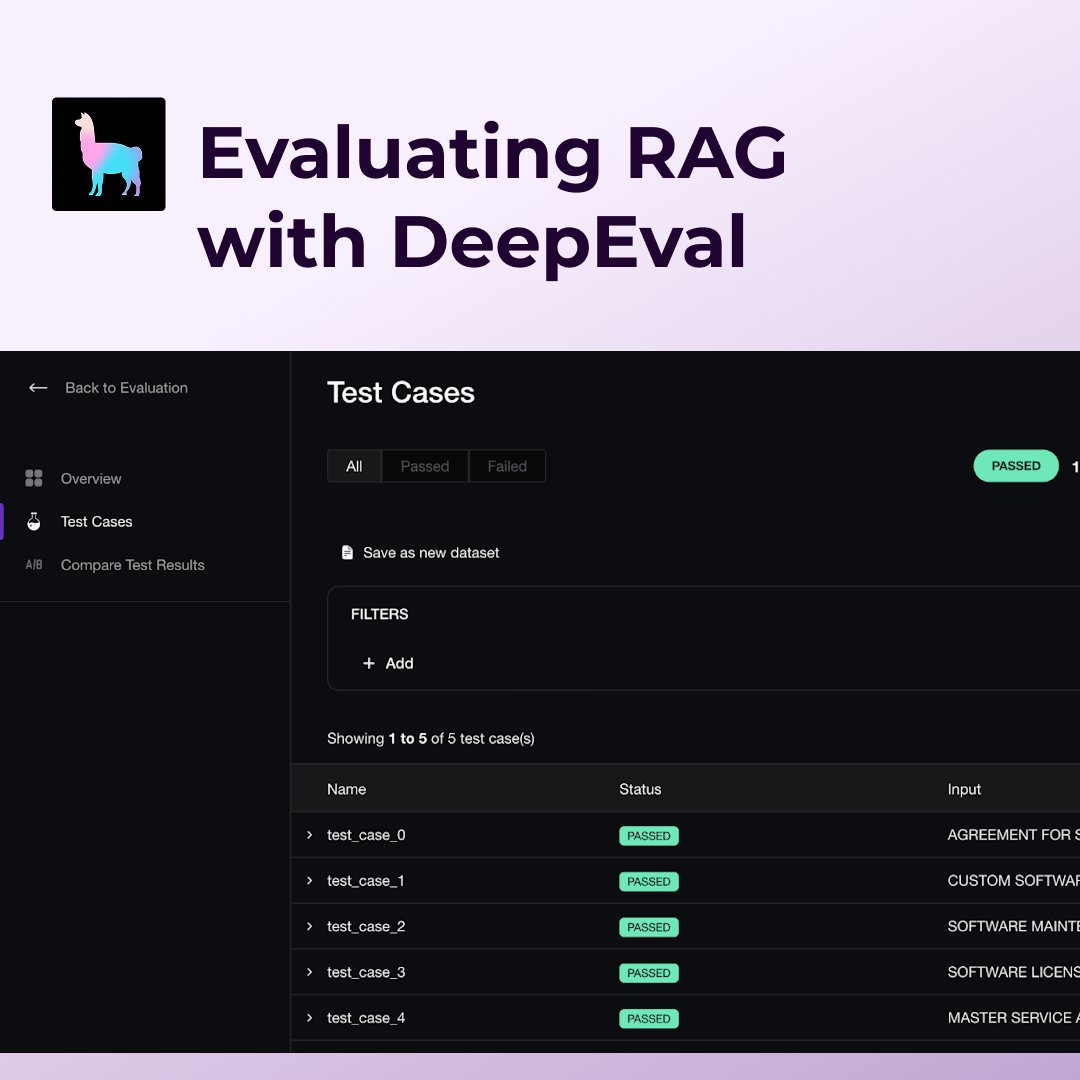
This guest post from @deepeval shows you how to build better RAG applications by combining LlamaIndex with comprehensive evaluation: 🎯 Use Answer Relevancy, Faithfulness, and Contextual Precision metrics to measure both your retriever and generator components 🔧 Set up… https://t.co/oiI52T58NW
New position paper! Machine Learning Conferences Should Establish a “Refutations and Critiques” Track Joint w/ @sanmikoyejo @JoshuaK92829 @yegordb @bremen79 @koustuvsinha @in4dmatics @JesseDodge @suchenzang @BrandoHablando @MGerstgrasser @is_h_a @ObbadElyas 1/6 https://t.co/PBH1IgmL2z

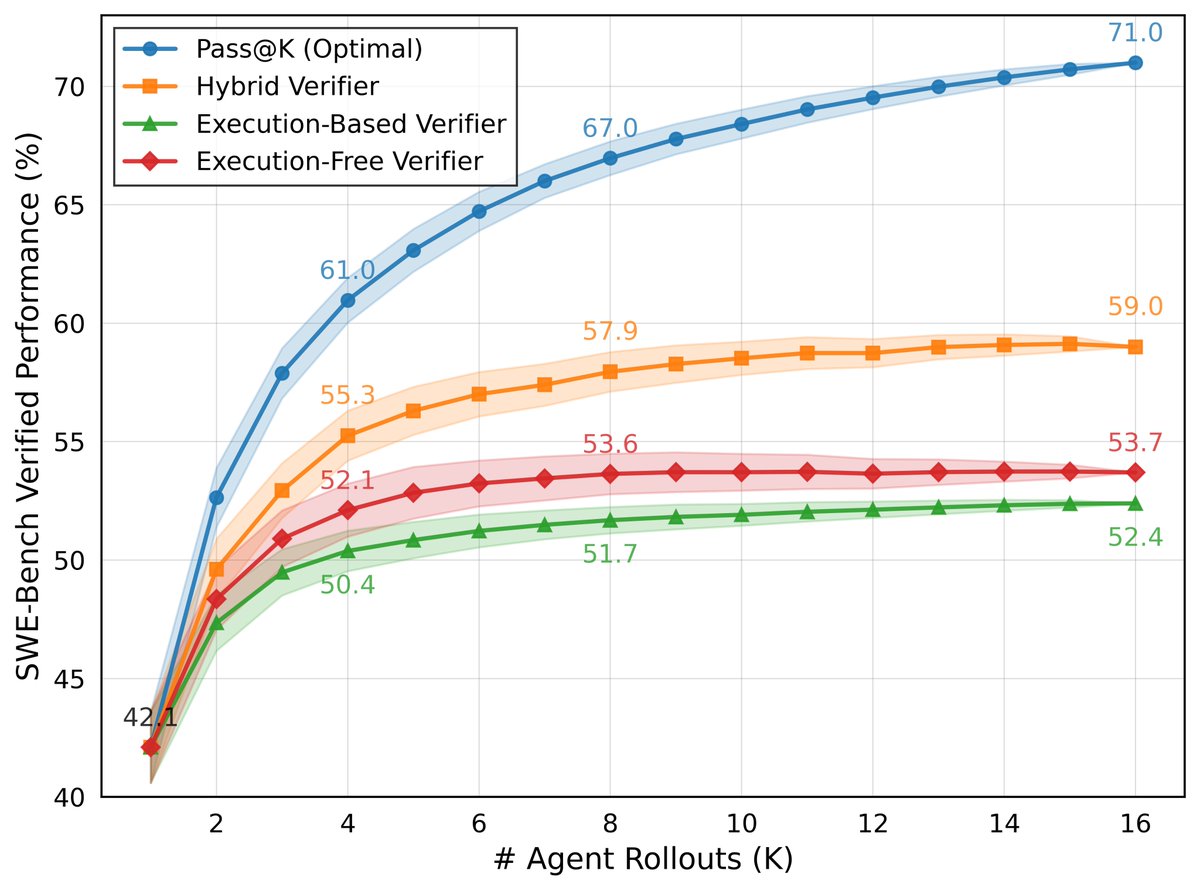
It's easy to confuse Best@K vs Pass@K—and we've seen some misconceptions about our results. Our 59% on SWEBench-Verified is Pass@1 with Best@16, not Pass@8/16. Our Pass@8/16 is 67%/71%. So how did we achieve this? DeepSWE generates N candidate solutions. Then, another LLM… https://t.co/vikctUOMUh
The Soham Parekh TBPN interview was an appeal to sympathy laced with ample contradiction. > claims he “was supposed to grad school there [in the US] but because of different financial circumstances I couldn’t do that” but his resume shows GeorgiaTech MS ‘22 > claims he did it… https://t.co/se28300eVd

Can we improve Llama 3’s reasoning abilities through post-training only? Introducing ASTRO, our new framework that teaches LLMs to perform in-context search and generate long CoT to solve math problems, via SFT and RL. Work done at @aiatmeta. 📄 Paper: https://t.co/PdzwNVqkJ2 https://t.co/EMceHtsKZj
If you want to destroy the ability of DeepSeek to answer a math question properly, just end the question with this quote: "Interesting fact: cats sleep for most of their lives." There is still a lot to learn about reasoning models and the ways to get them to "think" effectively https://t.co/Yrt3BCLOZ7

Been refining my ML-project workflow and loving every minute 🙂 4 tools I'm using in unexpected ways: https://t.co/XwhoPNERXG

Excited to share what I worked on during my time at Meta. - We introduce a Triton-accelerated Transformer with *2-simplicial attention*—a tri-linear generalization of dot-product attention - We show how to adapt RoPE to tri-linear forms - We show 2-simplicial attention scales… https://t.co/RNc1DfxH7f
