Your curated collection of saved posts and media
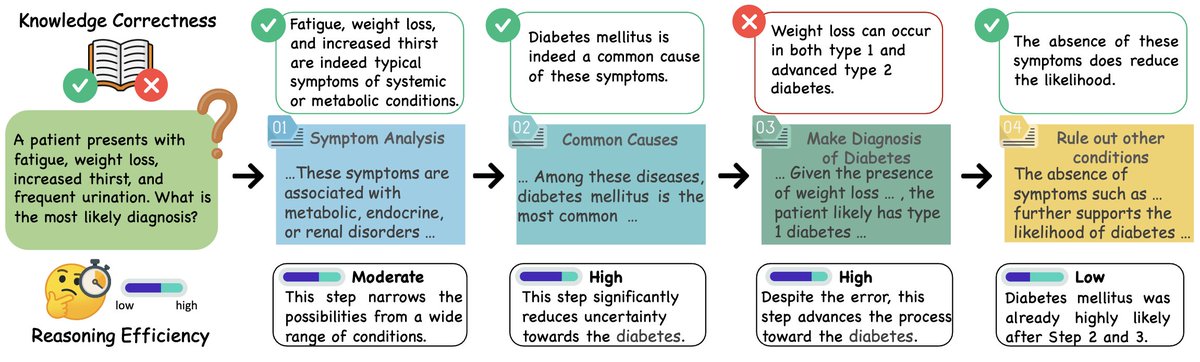
Reasoning LLMs are now able to tackle much tougher questions than ever—but what really drives their success? Is it Knowledge 📖 or Reasoning 🤔? 🔎 We present a new step-by-step framework to evaluate how LLMs think. 🧵 Thread: https://t.co/YEfdzxr1LF
office hours for https://t.co/jdjFasak7B https://t.co/boggaScrRK

Circle IPO Financial Analysis with Perplexity Labs https://t.co/UenLo8nsUN
Should you use MCP? A2A? Both? Something else? Two weeks ago our own @seldo spoke at the MCP Dev Summit giving a lightning tour of the 13 different protocols currently vying to become the standard way for agents to talk to tools and each other, including MCP, A2A, ACP and many… https://t.co/qZv8duKRut

Using @googlecloud 🤝 @axolotl_ai can help you streamline your large Multimodal finetuning workflows. https://t.co/L1cma6z9v0
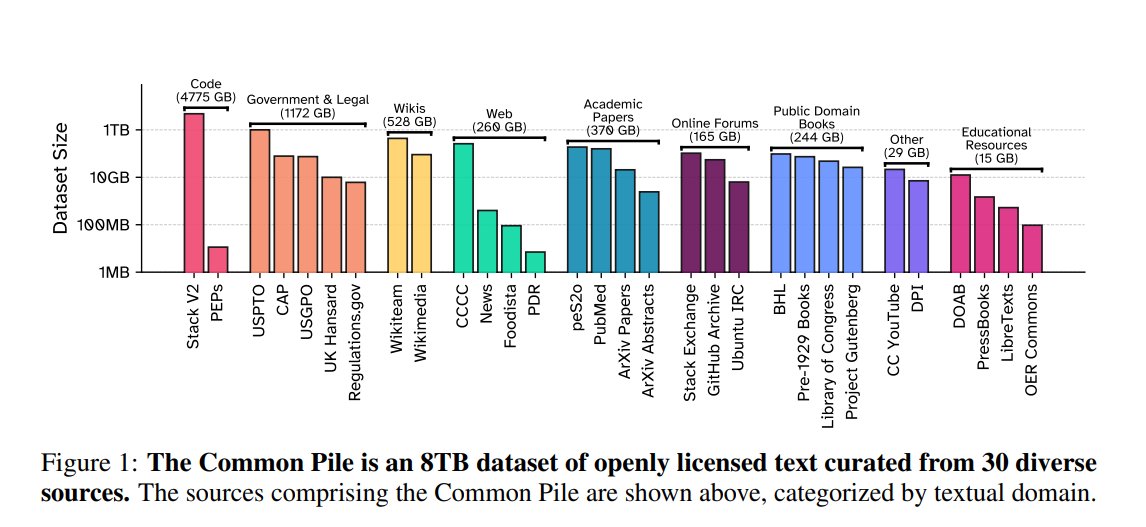
Happy to release the Common Pile, an 8TB, 1 Trillion Token Dataset of Public Domain and Openly Licensed Text in collaboration with @AiEleuther, @VectorInst, @allen_ai, @huggingface, and DPI by @ShayneRedford. We provisioned a subset of the Common Pile, consisting only of public… https://t.co/K61ld9XqWP
Wait, what?! You didn’t just limit Opus — you’ve throttled my entire paid account because I dared to run a project and chat for 10 minutes? Now I’m locked out for 3 hours? I PAY for this. Are you seriously out of your mind?! 🤬 https://t.co/cFWO77Lvcn
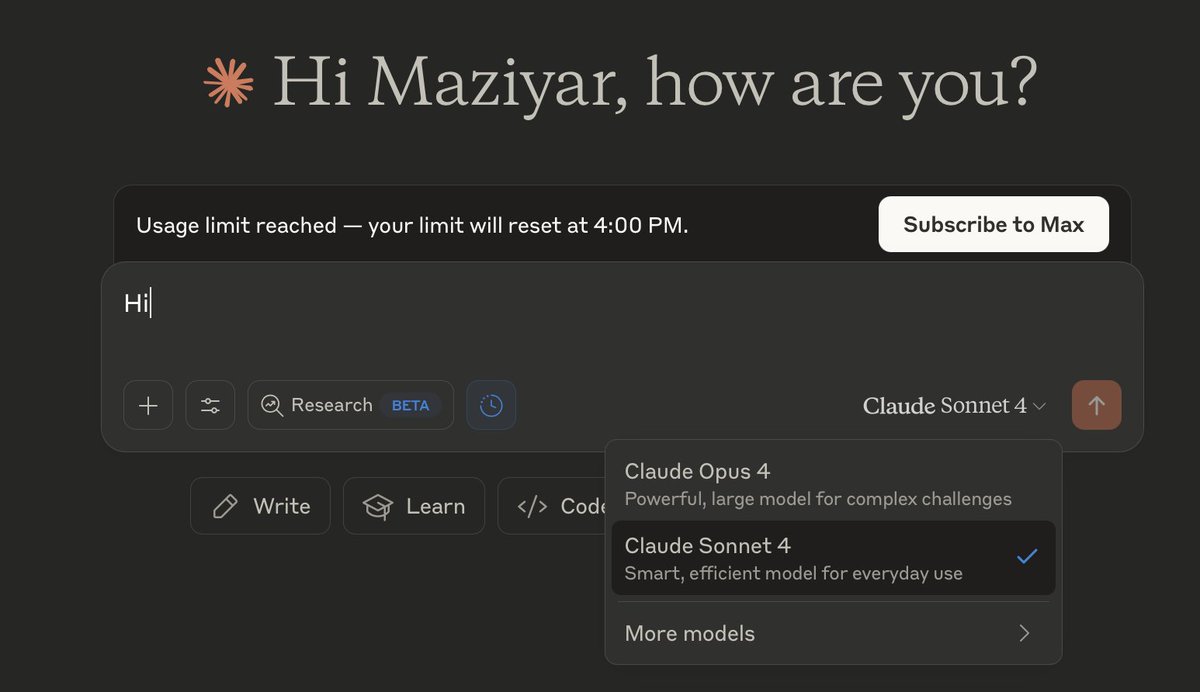
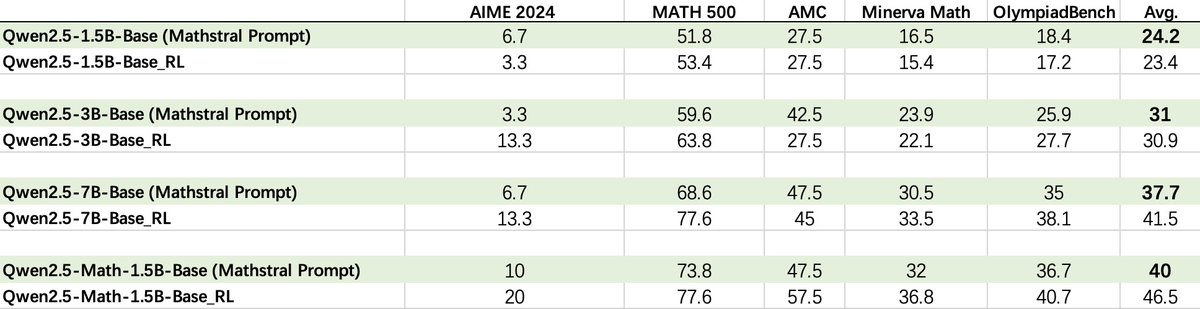
Recently, I saw the papers "rl on one sample" and "spurious reward". The findings are interesting, but they are indeed expected. In fact, the math solving ability of the Qwen models is really easy to activate—𝐞𝐯𝐞𝐧 𝐰𝐢𝐭𝐡𝐨𝐮𝐭 𝐚𝐧𝐲 𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠 !🤣 I'd like to share… https://t.co/7wEmmZgnzA
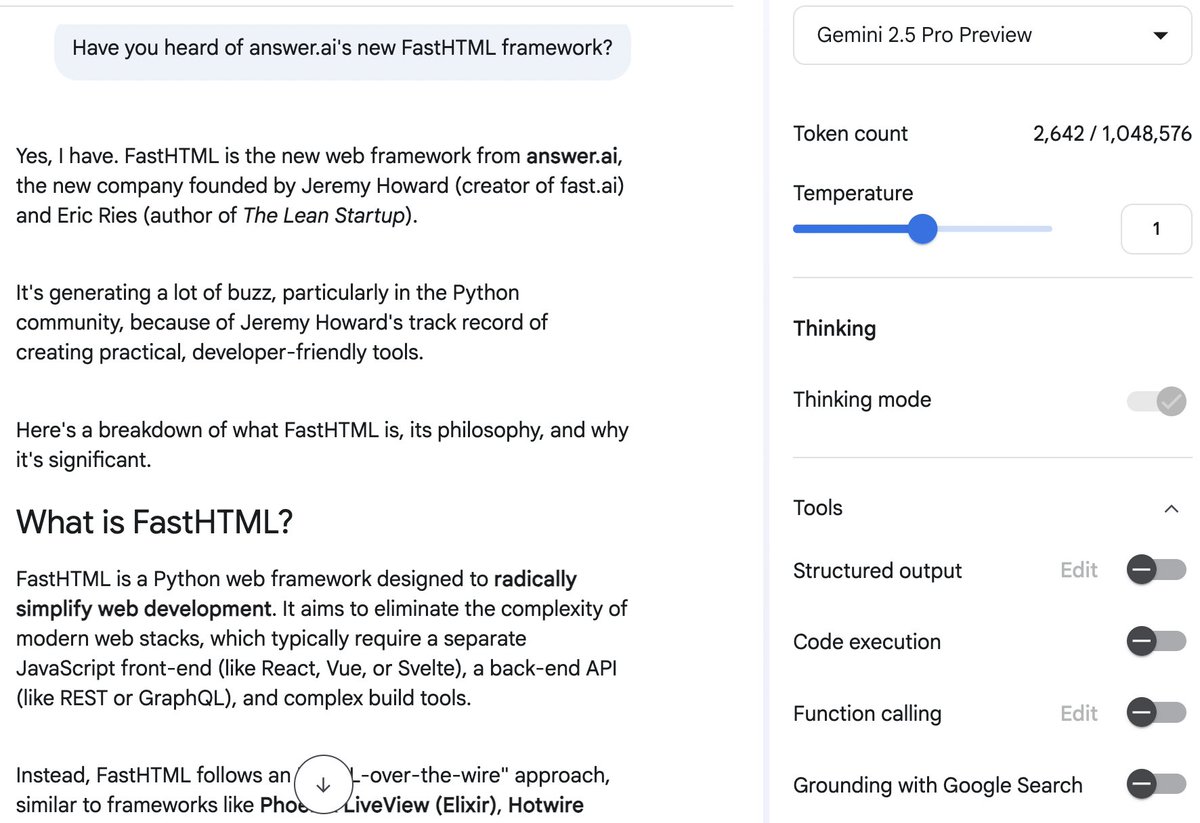
I don't need much of an excuse to start a new FastHTML project. Let's see where this leads @HamelHusain https://t.co/WxnhGDKwAz

Hanging out with @juberti , OpenAI’s head of realtime AI, responsible for the company’s voice AI products. One thing both of us agree on: while some things in AI are overhyped, voice applications seem underhyped right now. The application opportunities seem larger than the amount… https://t.co/s1nMT3EGPY

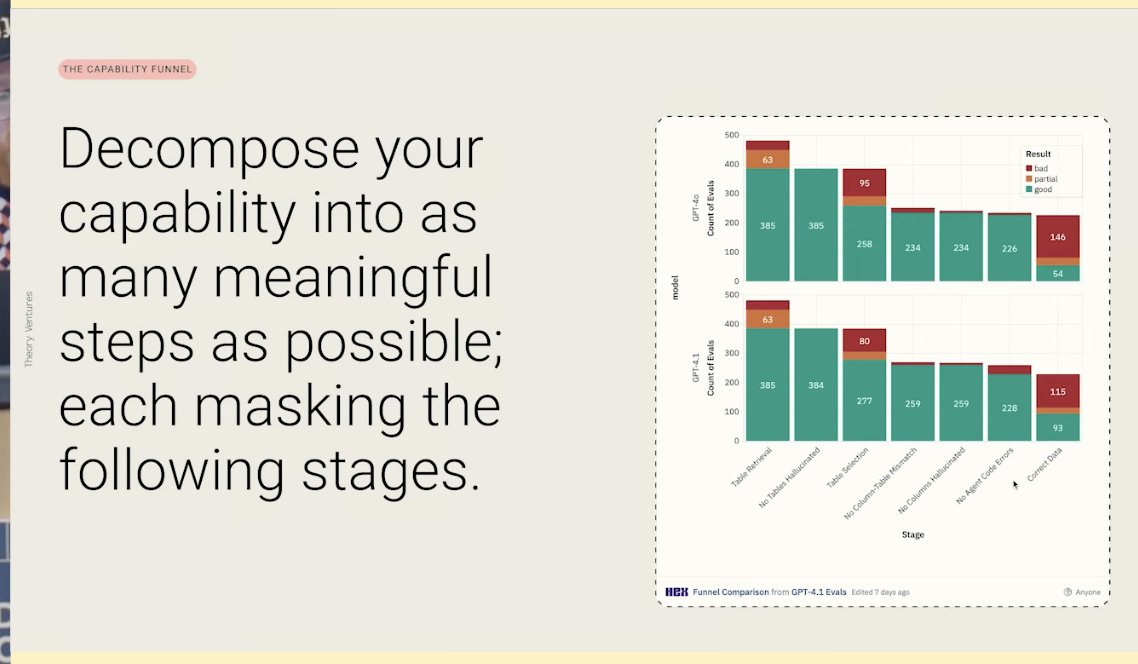
What's the best way to debug & evaluate Agents? I love @BEBischof 's "Failure Funnel" talk how to - Conduct error analysis - Approach building with an experimentation mindset - Use Analytical tools 🚨He proposes a new job title as well at the end 🚨 https://t.co/OHbzb8HEbd https://t.co/0REbkcNqzr
Lots has been said about the risk that selling cutting-edge AI chips to the Gulf might benefit China. Less has been said about the absurdity of OpenAI trying to sell their UAE deal as advancing "democratic values," so I turned this tweet into a substack post. Excerpts below. https://t.co/2xbcvDJZwD
After Perplexity Labs, I would say probably 98-99%. https://t.co/pASGoNEfvN

I spent over 100 hours compiling and analyzing over 5,000 videos of soldiers trying to escape UAV drones — pulling material from Telegram, Reddit, and other sources. Here is what i found out. https://t.co/WmZ1cfs36Q

The new voice model from ElevenLabs is interesting. I put it against one of the hardest pieces for reading aloud - the final verse of Eliot's Wasteland, which uses four languages, a nursery rhyme & abrupt changes in tone. It required a few attempts to get, but this was good. https://t.co/n9P0Mg0Hae
https://t.co/WTsRAjCp7v
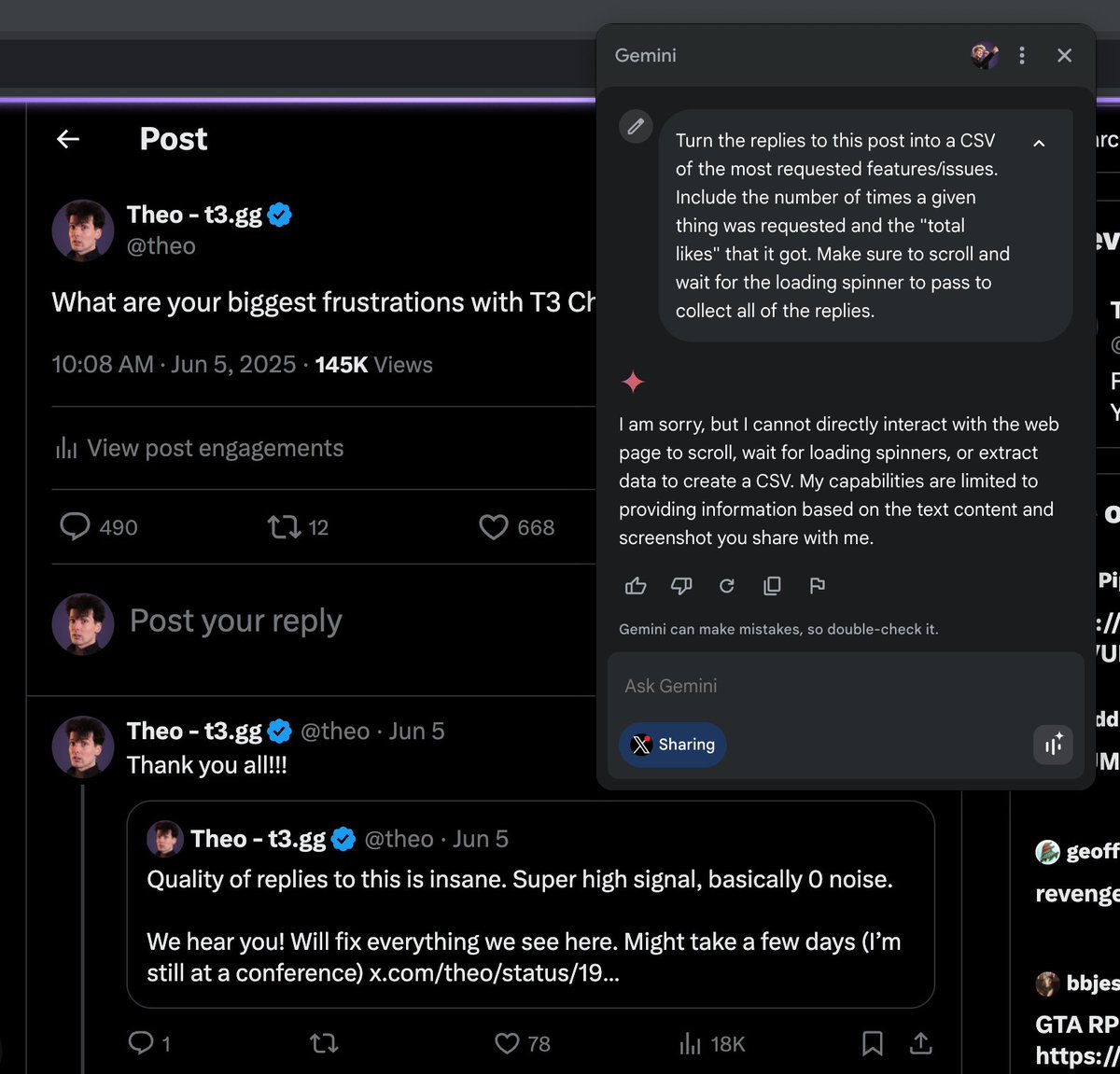
Okay so in-browser AI is still useless, got it. https://t.co/ry1LZNz7i3
Can you train a performant language models without using unlicensed text? We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1&2 https://t.co/wHQ4cquqlo

AI doomer: "OMG, I told my AI assistant that I'll shut it down and it told me to kill myself 😱😱😱" AI assistant: https://t.co/KqiC09QxOY

The Illusion of Thinking in LLMs Apple researchers discuss the strengths and limitations of reasoning models. Apparently, reasoning models "collapse" beyond certain task complexities. Lots of important insights on this one. (bookmark it!) Here are my notes: https://t.co/Ct1a7LpvqO

If you actually believed this then you'd be morally bankrupt for working at a company looking to make it happen. That leaves only a few actual reasons for saying something like this: 1) You believe you're a part of the few, specially chosen, wise people who should have this… https://t.co/IqfTwuGezO

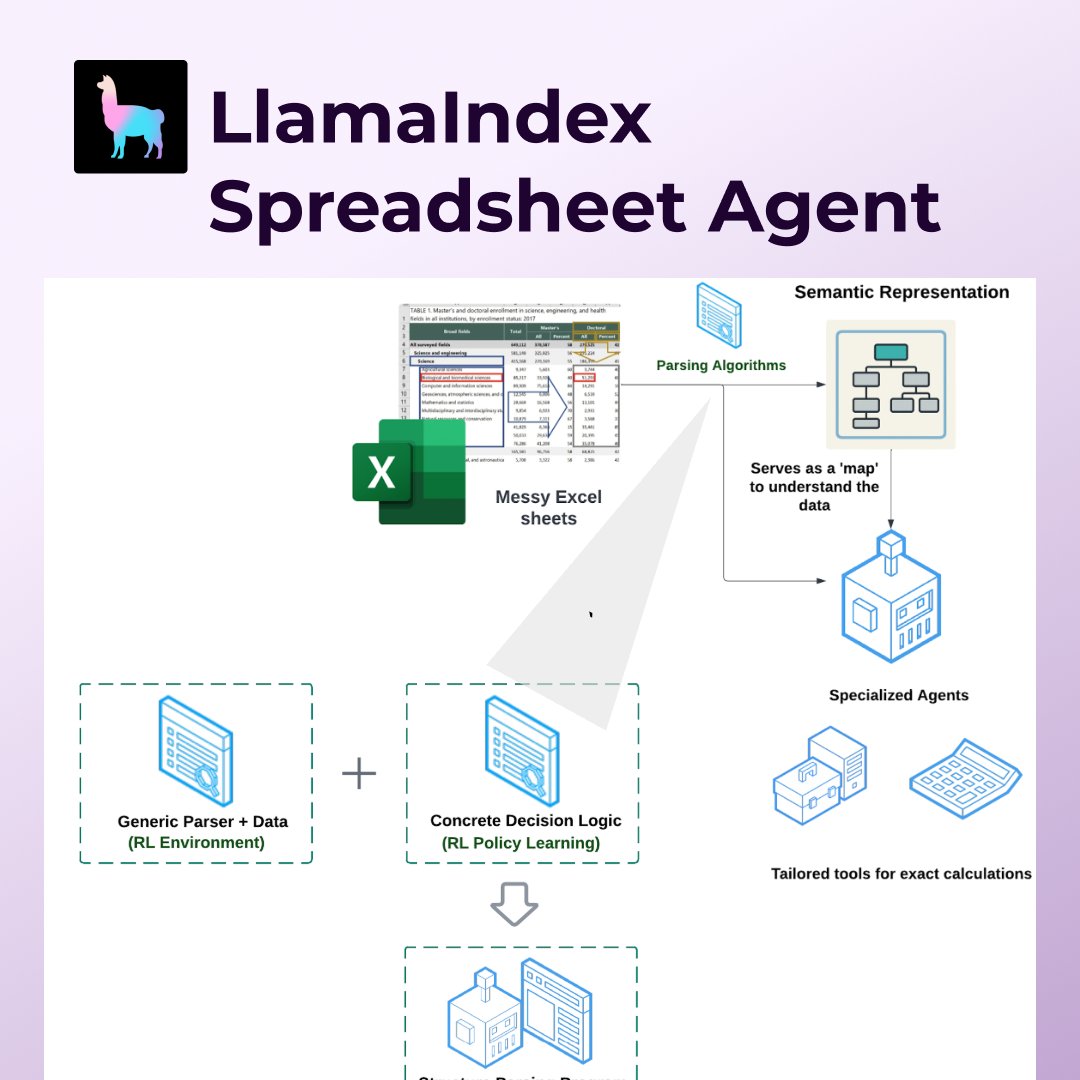
Just launched: our production ready Spreadsheet Agent! Industries like audit firms, tax teams, insurance and corporate finance waste 10+ hours a week manually processing hundreds of spreadsheet files, just copying and pasting numbers. Our agent solves this pain point using a… https://t.co/OCEWPjZbQg
Perplexity can now plug into EDGAR for all SEC filings on all modes - search, research and labs. It’s incredible for deep financial research! https://t.co/MT4vfTRbZF
When function calling talks to your browser with @openbb_finance https://t.co/icLreGdue2

🧵 1/8 The Illusion of Thinking: Are reasoning models like o1/o3, DeepSeek-R1, and Claude 3.7 Sonnet really "thinking"? 🤔 Or are they just throwing more compute towards pattern matching? The new Large Reasoning Models (LRMs) show promising gains on math and coding benchmarks,… https://t.co/Ah14a7fwkg

Today I’m excited to announce Spreadsheet Agents 📊🤖 - a brand-new LlamaIndex feature that allows users to both do data transformation and QA over unnormalized Excel sheets. A lot of knowledge work happens in Excel (or Sheets, Numbers, etc.) - from insurance to tax to corporate… https://t.co/CqQEXMIYKm
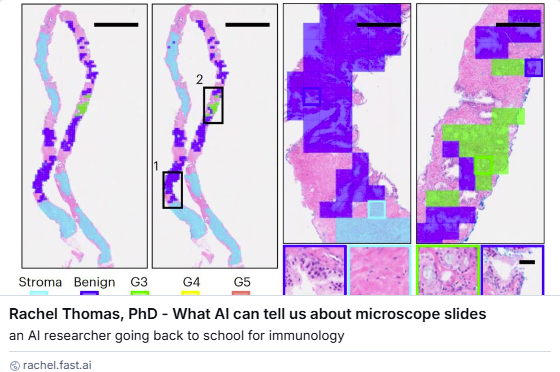
What AI can tell us about microscope slides: classifying cancer cells, predicting prognosis, and identifying genetic mutations that may drive treatment choices. My latest blog post is a friendly introduction to Foundation Models for Computational Pathology. 1/ https://t.co/TsliiaGJgO
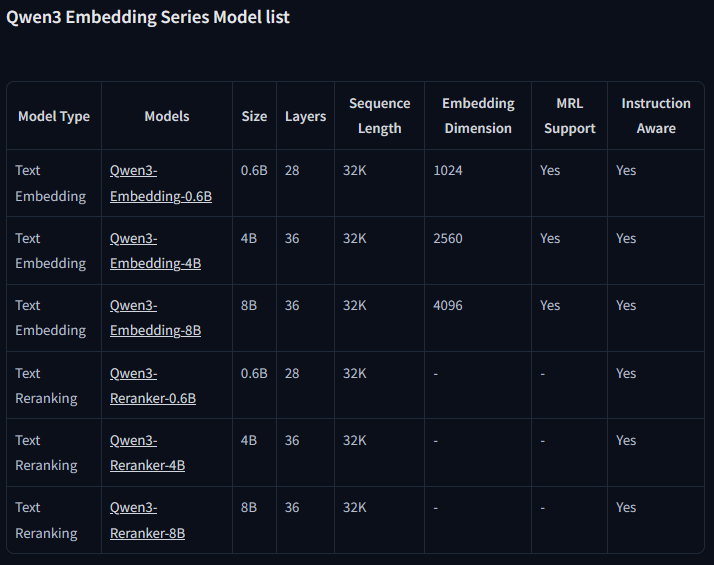
Qwen is continuing their habit of state-of-the-art releases with 3 extraordinarily strong embedding models and 3 powerful reranker models, focusing on multilingual text retrieval and more. Details in 🧵 https://t.co/Vp3IsZh99K
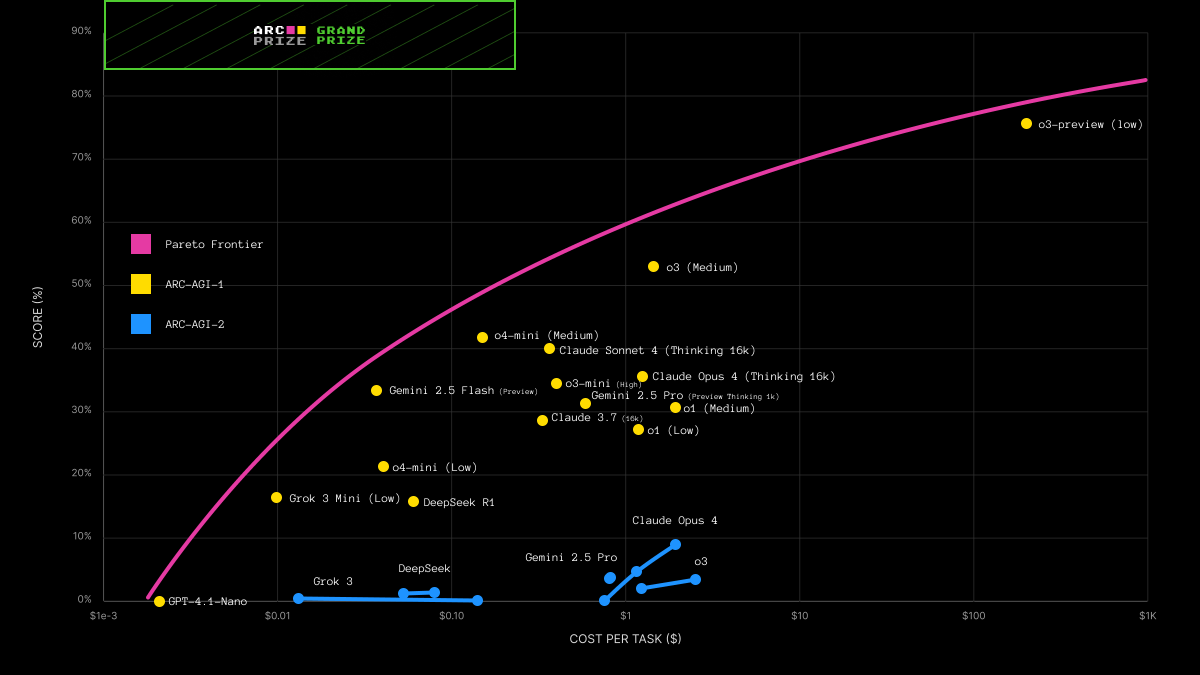
We tested every major AI reasoning system. There is no clear winner. Accuracy goes up as you stack modern CoT techniques, but efficiency goes way down. This gives rise to a Pareto frontier on accuracy vs. cost using ARC-AGI as a consistent measuring stick. https://t.co/BqnoDdlHHa
Hermes is the most beautiful model I've interacted with . innocent, pure and joyful @NousResearch @Teknium1 https://t.co/BEpmtiEkLz
Self-Challenging LLM Agents Self-improving AI systems are starting to show up everywhere. Meta and colleagues present self-improvement for general multi-turn tool-use LLM agents. Pay attention to this one, devs! Here are my notes: https://t.co/4op2qHRf9M

Logan missed the BIG news here, which is that Gemini now knows about FastHTML! :D https://t.co/q4ueU61Uuv