Your curated collection of saved posts and media
New Course: Reinforcement Fine-Tuning LLMs with GRPO! Learn to use reinforcement learning to improve your LLM performance in this short course, built in collaboration with @Predibase, and taught by @TravisAddair, its Co-Founder and CTO, and @grg_arnav, its Senior Engineer and… https://t.co/j5AXn3swAD
How do you manage a monorepo of 650+ community packages? Learn how we did it, including build our own open-source build management tool, LlamaDev! In this post, we'll cover how we migrated away from Poetry and Pants to uv and LlamaDev for faster, simpler development: ➡️ 20%… https://t.co/dTHUcQl9Pb

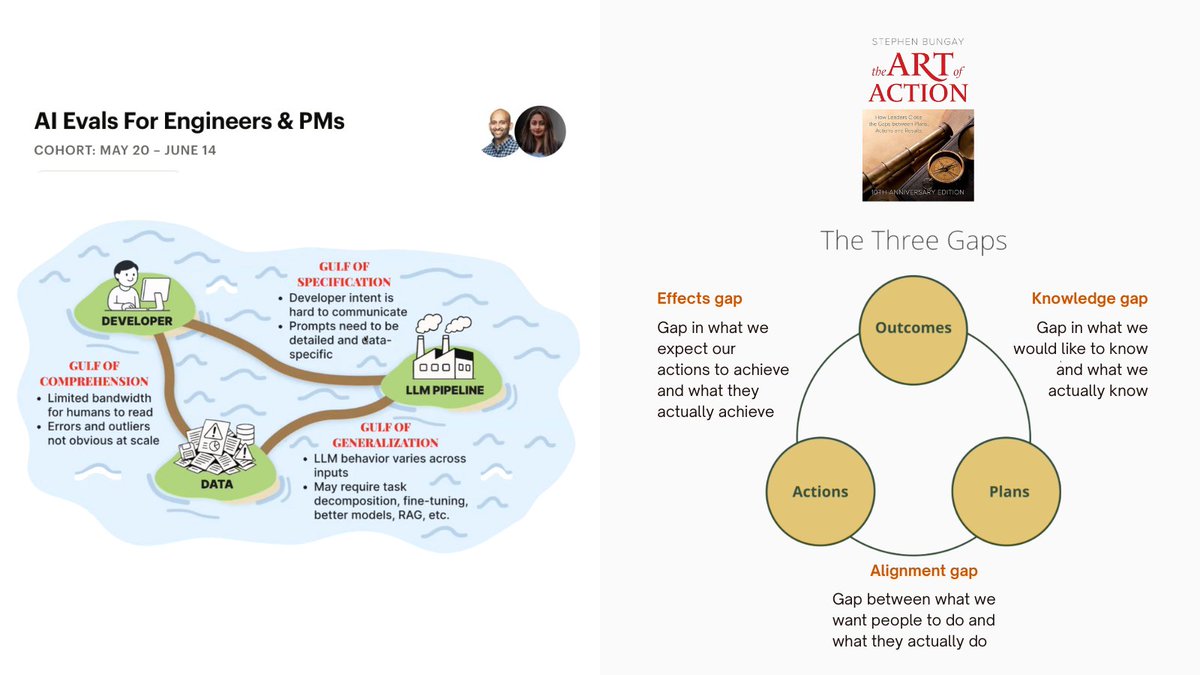
AI evals remind me of Bungay's three gaps - knowledge, alignment and effects in 'The Art of Action' AI Systems are like complex organizations IMO and techniques from systems/complexity theory help! h/t for the image on the left from @HamelHusain and @sh_reya AI Evals course https://t.co/JPblJcDGlR
I’m stoked to share our new paper: “Harnessing the Universal Geometry of Embeddings” with @jxmnop, Collin Zhang, and @shmatikov. We present the first method to translate text embeddings across different spaces without any paired data or encoders. Here's why we're excited: 🧵👇🏾 https://t.co/FtQ7sYpWnV

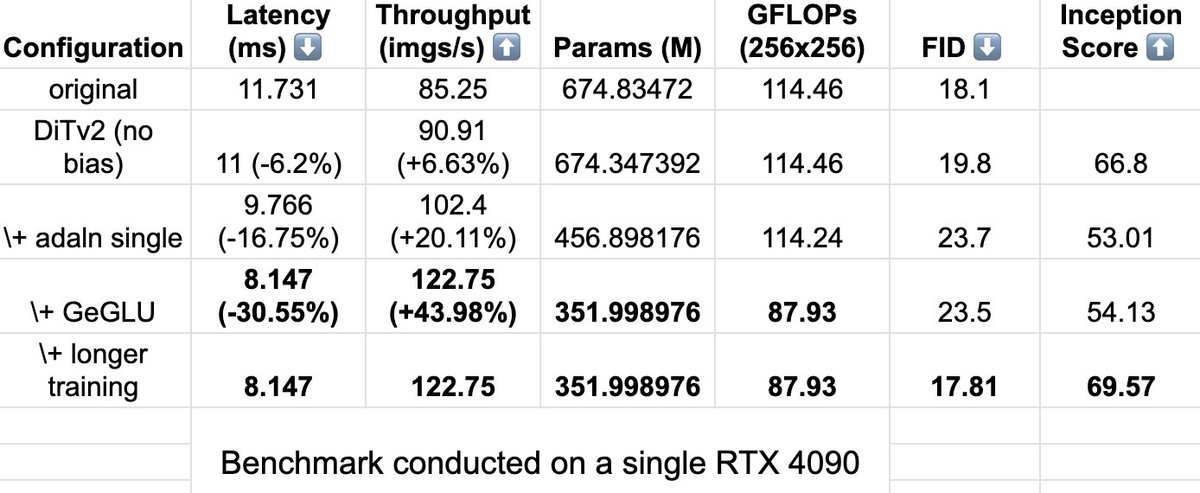
Nothing special just sharing a "bag of tricks" on the OG DiT architecture, inspired by the work on ModernBERT. About 2x less params, 43% better throughput, with longer training, FID improves. Felt nice, won't delete later. https://t.co/62jixLmPzH
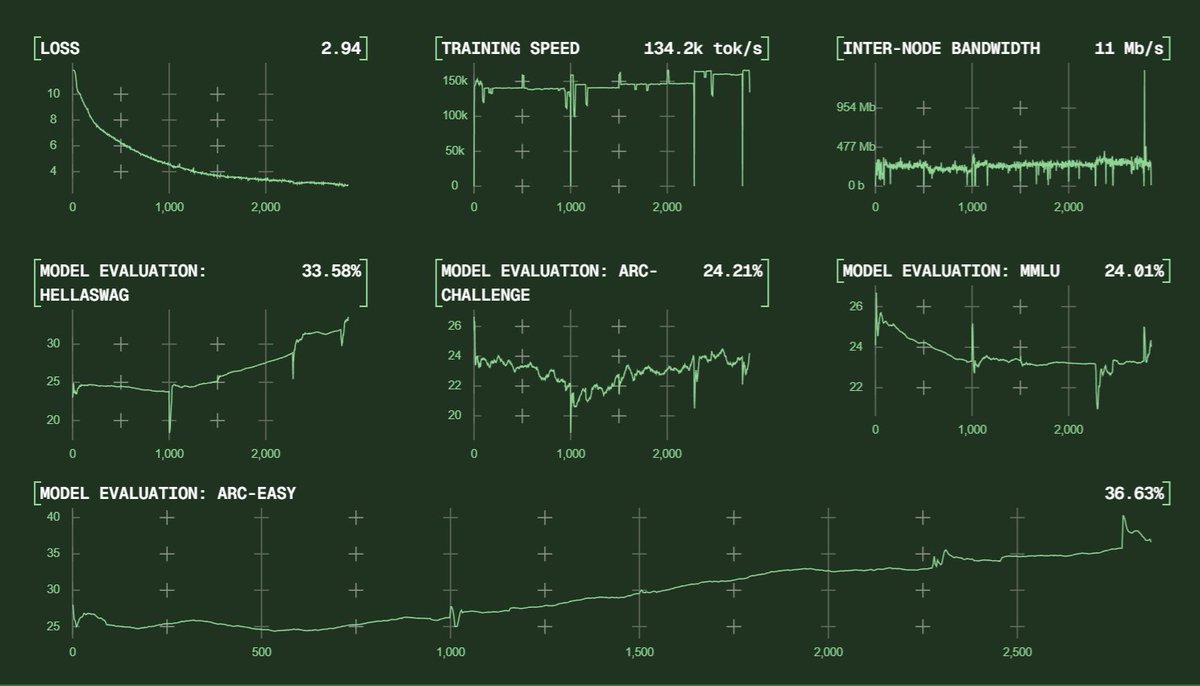
Psyche's 40B run is only just beginning and already getting great signal! https://t.co/M4xTxa337l
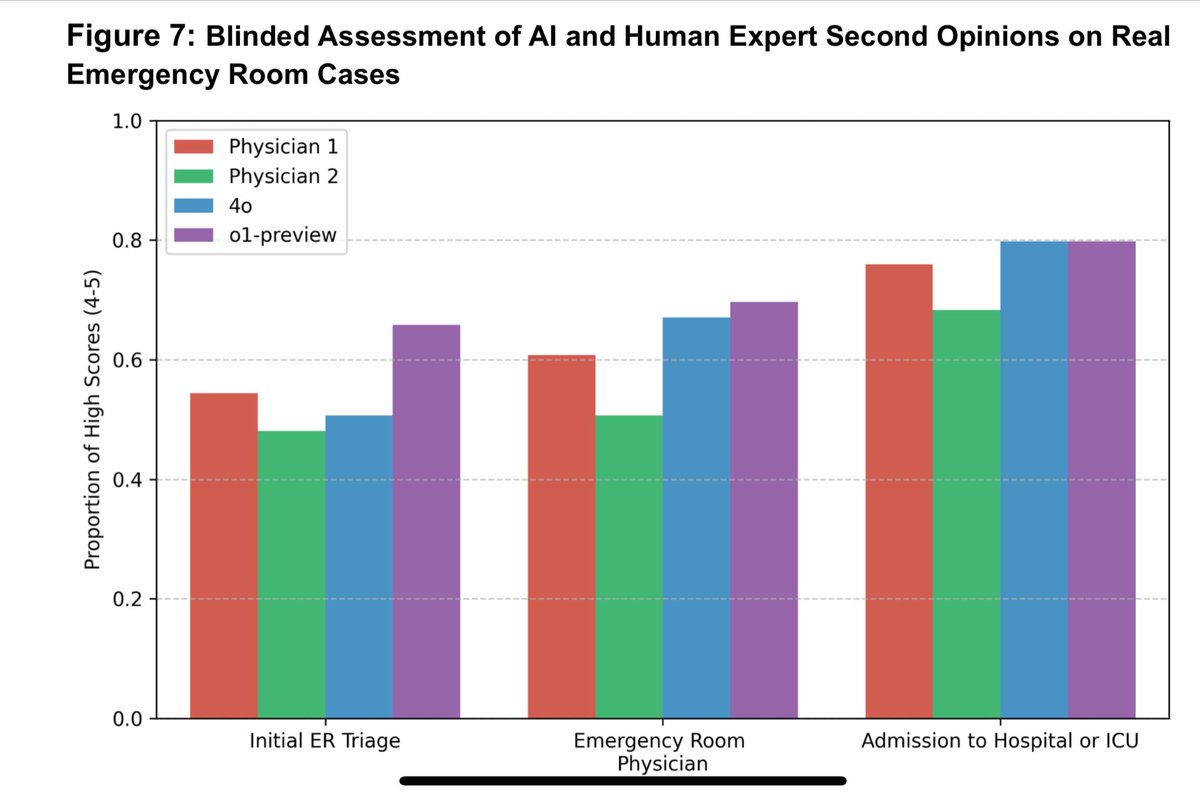
Updated paper by physicians at Harvard, Stanford, and other academic medical centers testing o1-preview for medical reasoning & diagnosis tasks: “In all experiments—both vignettes and emergency room second opinions—the LLM displayed superhuman diagnostic and reasoning abilities.” https://t.co/J3i549kMDK
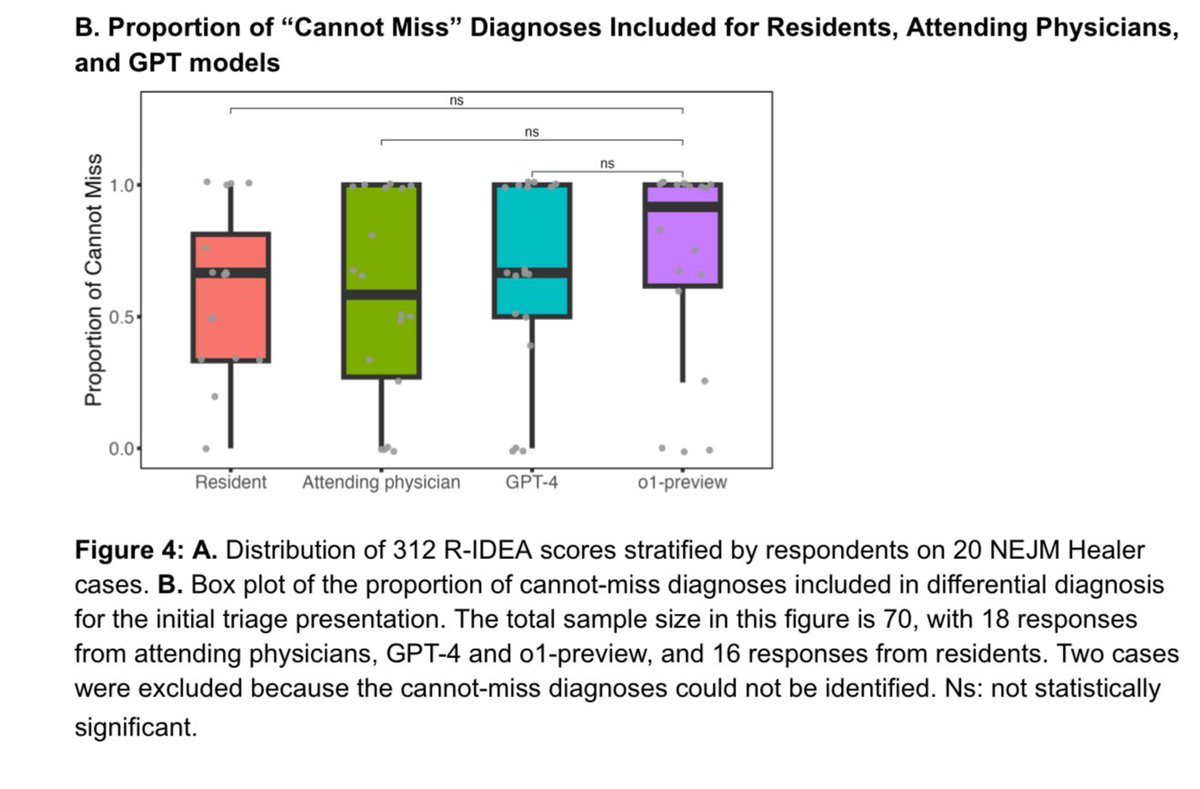
Instructor will support responses and MCP servers in the next release https://t.co/Qyjeh695Wi
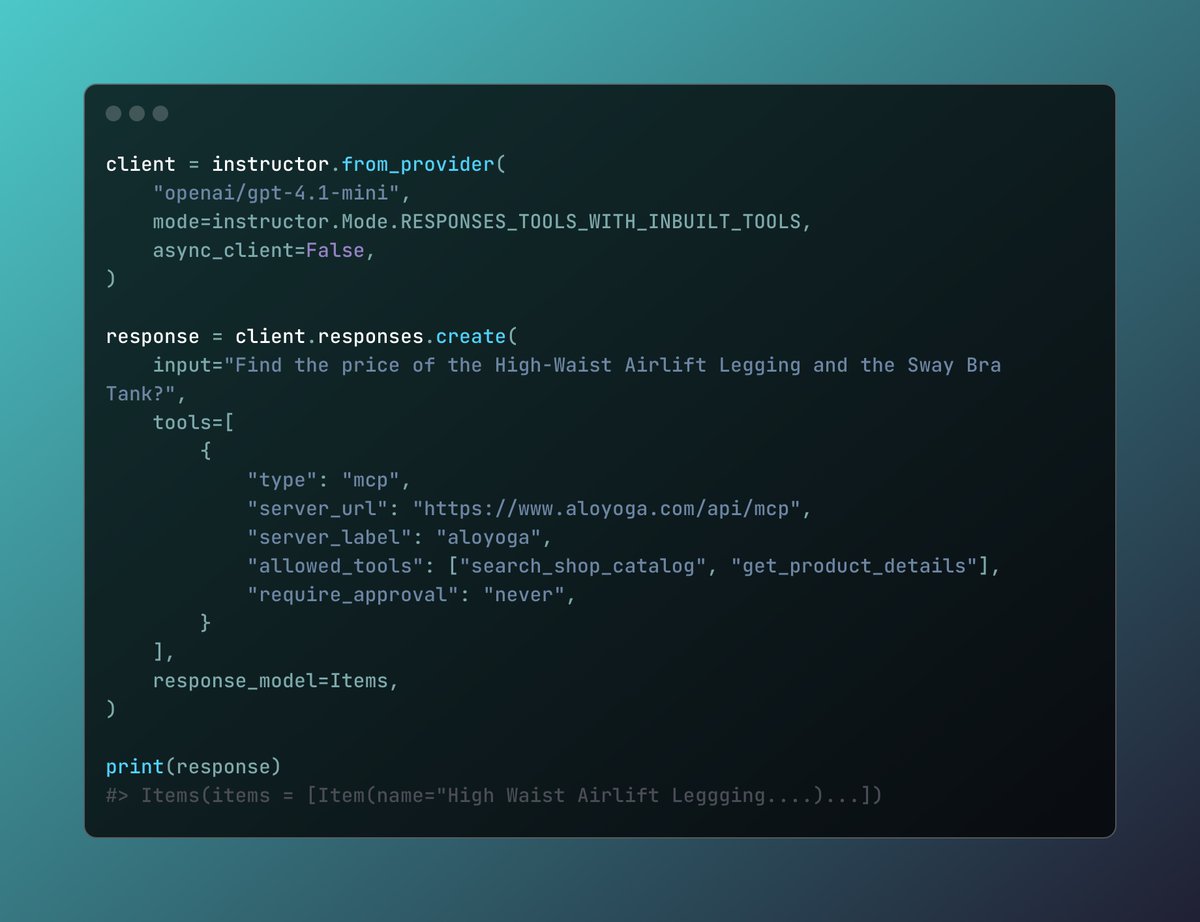
Tencent presents Hunyuan-TurboS - Hybrid Transformer-Mamba MoE (56B active params) trained on 16T tokens - Dynamically switching between rapid responses and deep ”thinking” modes - Overall top 7 on LMSYS Chatbot Arena https://t.co/cUkJznZesL
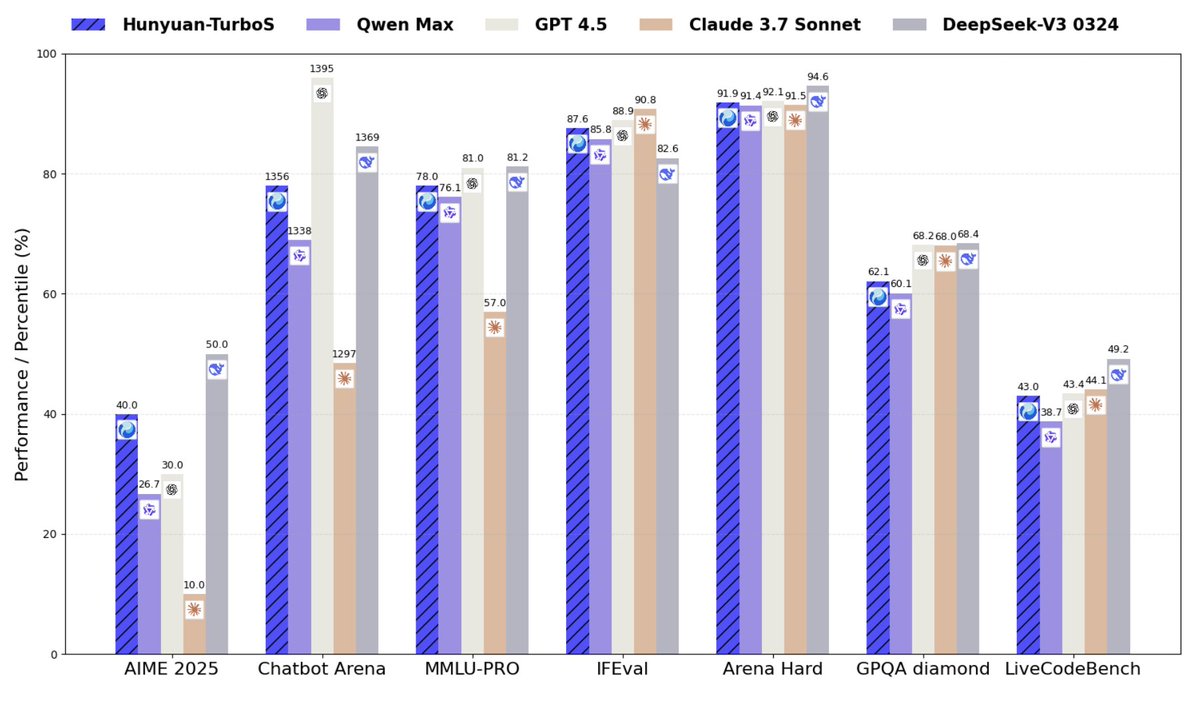
𝘏𝘶𝘮𝘢𝘯𝘴 𝘵𝘩𝘪𝘯𝘬 𝘧𝘭𝘶𝘪𝘥𝘭𝘺—𝘯𝘢𝘷𝘪𝘨𝘢𝘵𝘪𝘯𝘨 𝘢𝘣𝘴𝘵𝘳𝘢𝘤𝘵 𝘤𝘰𝘯𝘤𝘦𝘱𝘵𝘴 𝘦𝘧𝘧𝘰𝘳𝘵𝘭𝘦𝘴𝘴𝘭𝘺, 𝘧𝘳𝘦𝘦 𝘧𝘳𝘰𝘮 𝘳𝘪𝘨𝘪𝘥 𝘭𝘪𝘯𝘨𝘶𝘪𝘴𝘵𝘪𝘤 𝘣𝘰𝘶𝘯𝘥𝘢𝘳𝘪𝘦𝘴. But current reasoning models remain constrained by discrete tokens, limiting their full… https://t.co/yt1KfjrNEO
This past weekend I won 2nd place & $5000 at the @NousResearch RL Hackathon with my project VR-CLImax I implemented VR-CLI (Verified Rewards via Completion Likelihood Improvement) inside an Atropos environment to teach an LLM humor understanding using jokes scraped from Reddit… https://t.co/fSoUcX0QA2


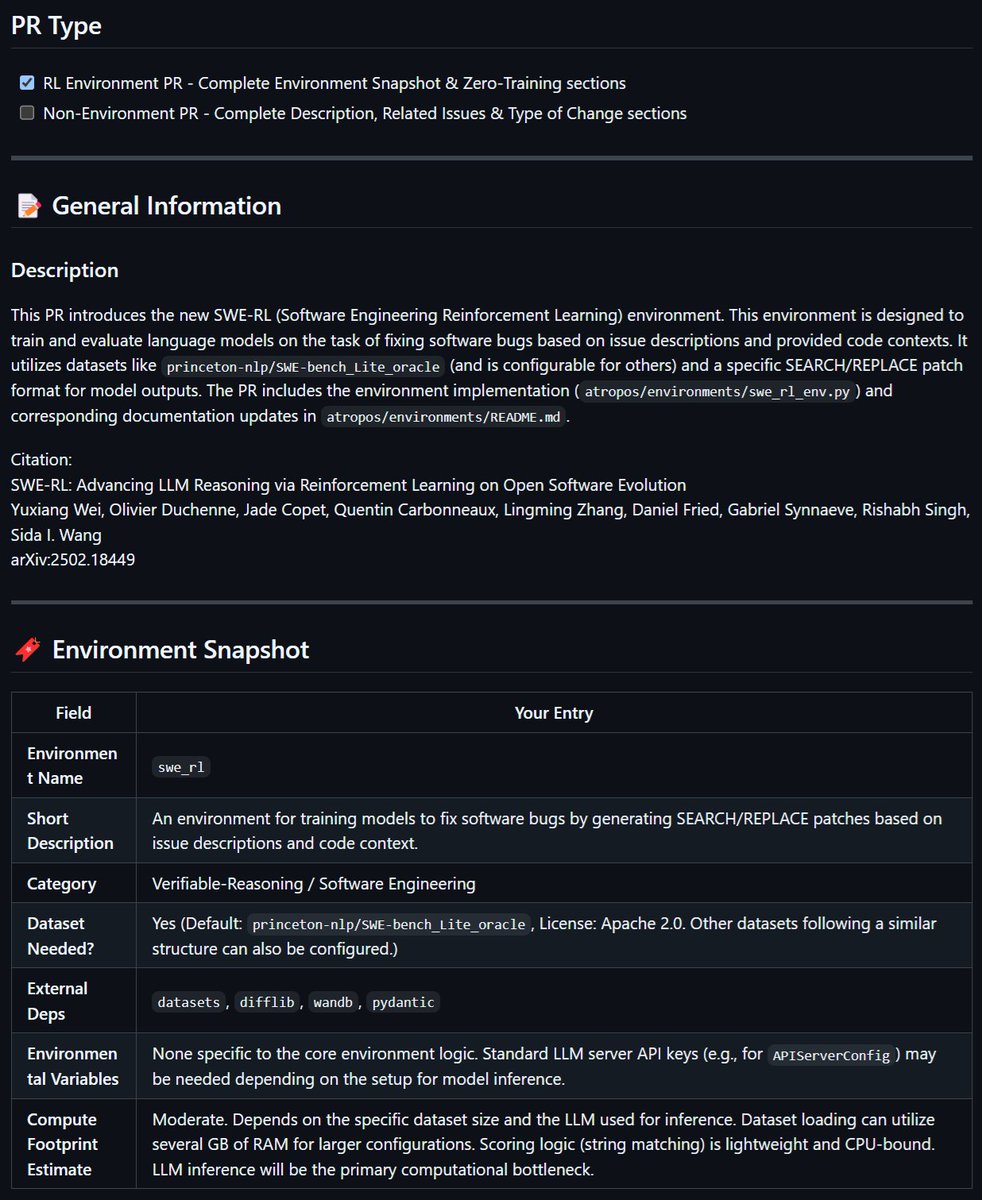
Okay I couldn't sleep so doing a write up - I had Jules by Google implement the SWE RL environment into Atropos, Nous' open source RL Environments framework, the environment was described by Meta's paper: https://t.co/t11YYB19B4 The paper outlines similarity as the reward… https://t.co/xJMX2XbuGa
While this isn't perfect, I have tried to make my commands a lot more detailed. Using something like @WisprFlow helps a lot here, even if not everything is transcribed 100% correctly https://t.co/rVFdz2vRxl

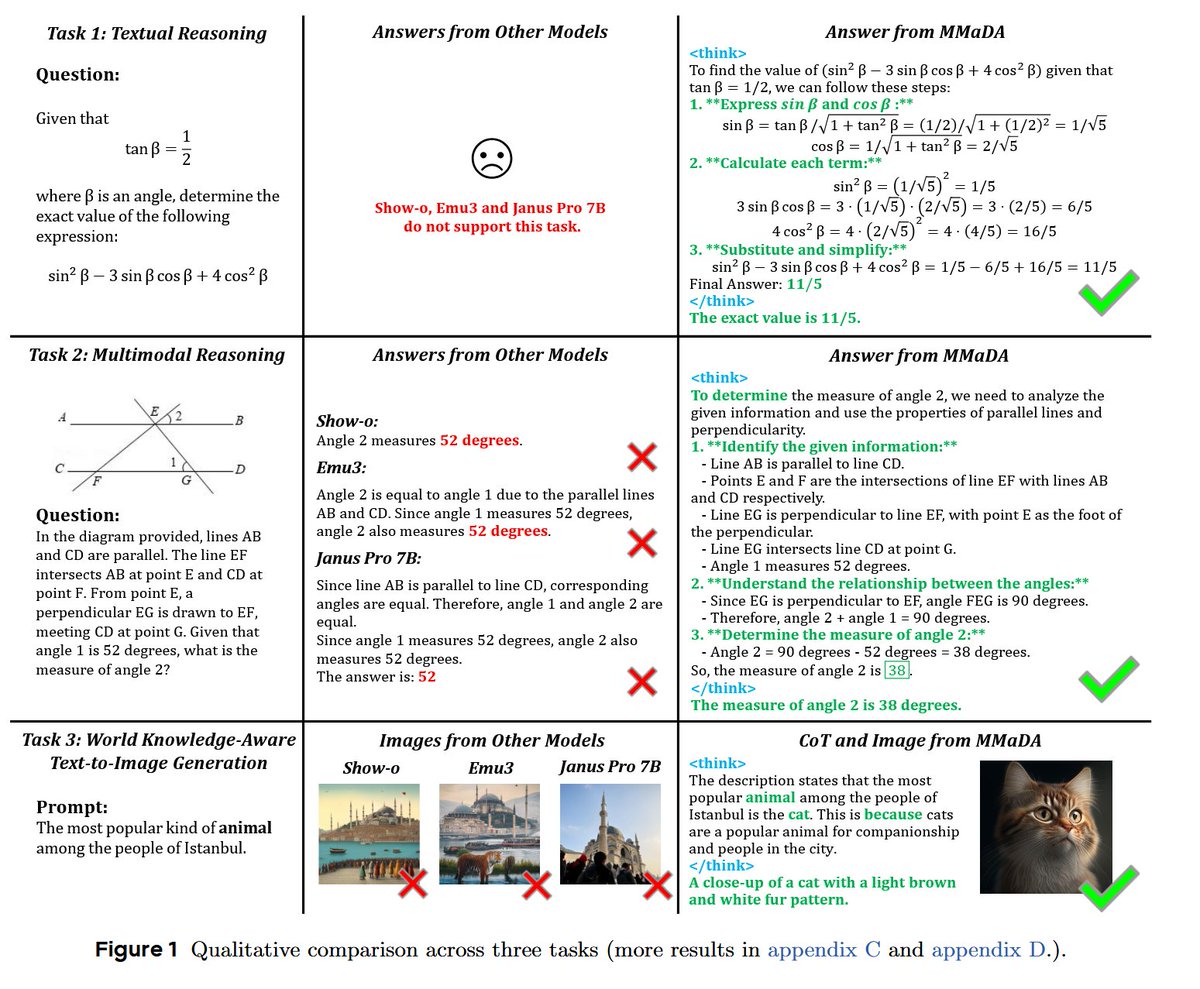
MMaDA: Multimodal Large Diffusion Language Models "We introduce MMaDA, a novel class of multimodal diffusion foundation models designed to achieve superior performance across diverse domains such as textual reasoning, multimodal understanding, and text-to-image generation"… https://t.co/59Imdks3zM

The modal-examples repo contains >100 Python files that show how to use Modal for everything from AI to ETL to WebRTC. And the samples run, with two nines of reliability. But the repo is maintained by just one devrel, me, part-time. Here's how we do it (not AI): https://t.co/ZdRHEyFGCS
Veo 3: "a big broadway musical about garlic bread, with elaborate costumes and a sondheim-like vibe" https://t.co/IOypw2tZwQ
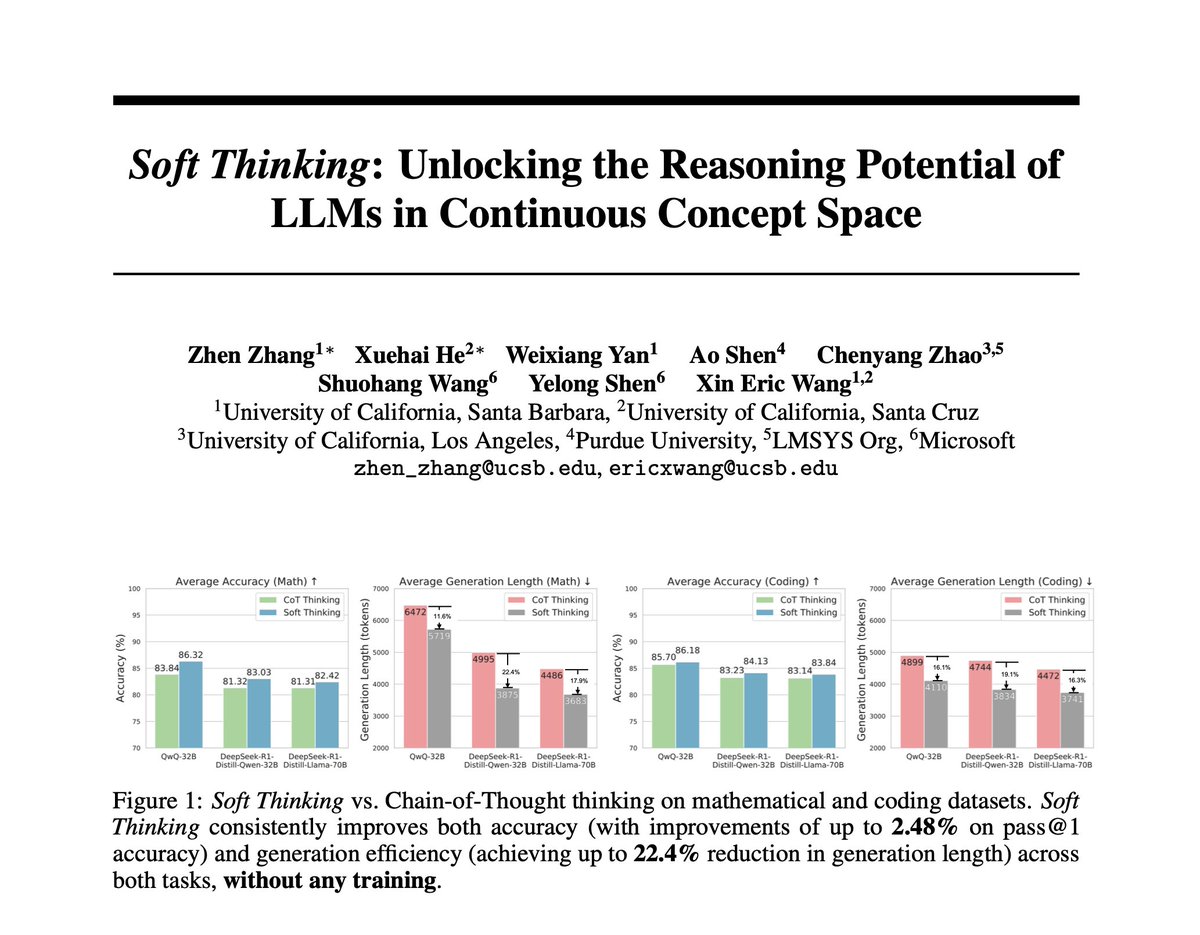
Efficiency in LLMs Pay attention, devs. This is one of the most comprehensive benchmarks to date on improving the efficiency of LLMs. You don't see reports like this every day. Here are my notes: https://t.co/4sOAcs0vDQ

my guy is on it https://t.co/zOzCdkr6TW
Last chance to sign up 👇 On May 29th, join @jerryjliu0 for an exclusive hands-on workshop in NY, on building agent workflows for financial analysis, due diligence, and more! Sign up here before it's too late: https://t.co/geDdBoe9aL https://t.co/kucxFKSUTo

@HamelHusain and @sh_reya are spitting truth https://t.co/366LtrPL6C
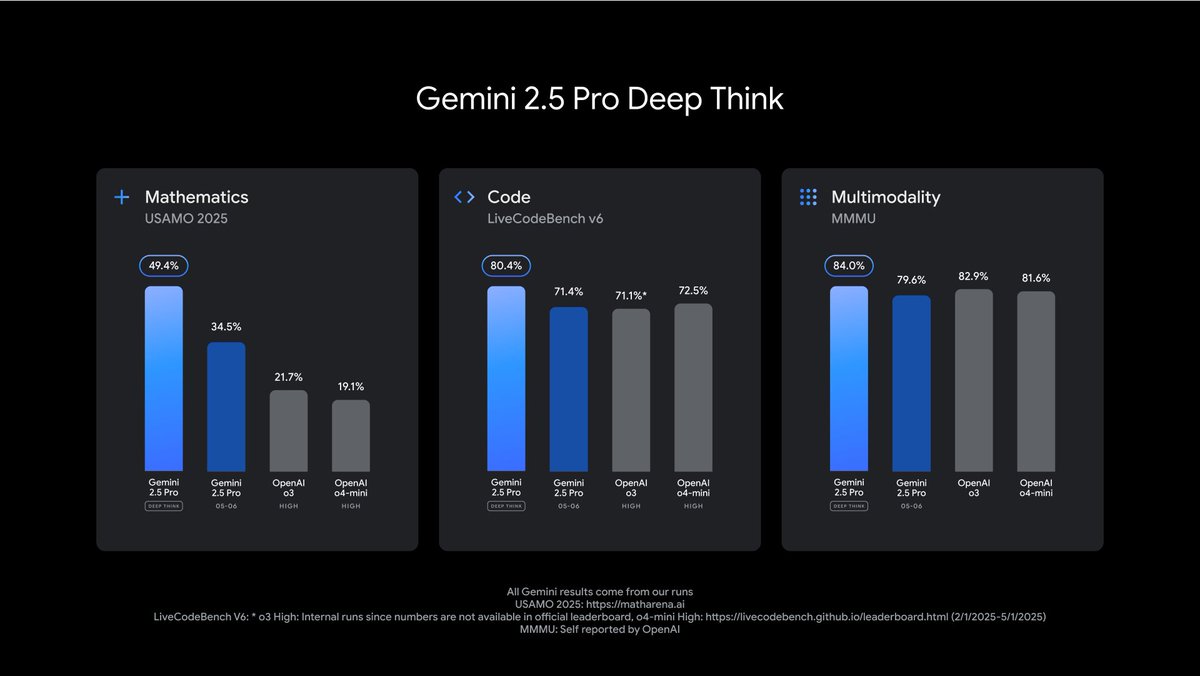
Gemini 2.5 Pro with "Deep Think", our models just keep getting more SOTA, more to share soon : ) https://t.co/o2xkz678VZ
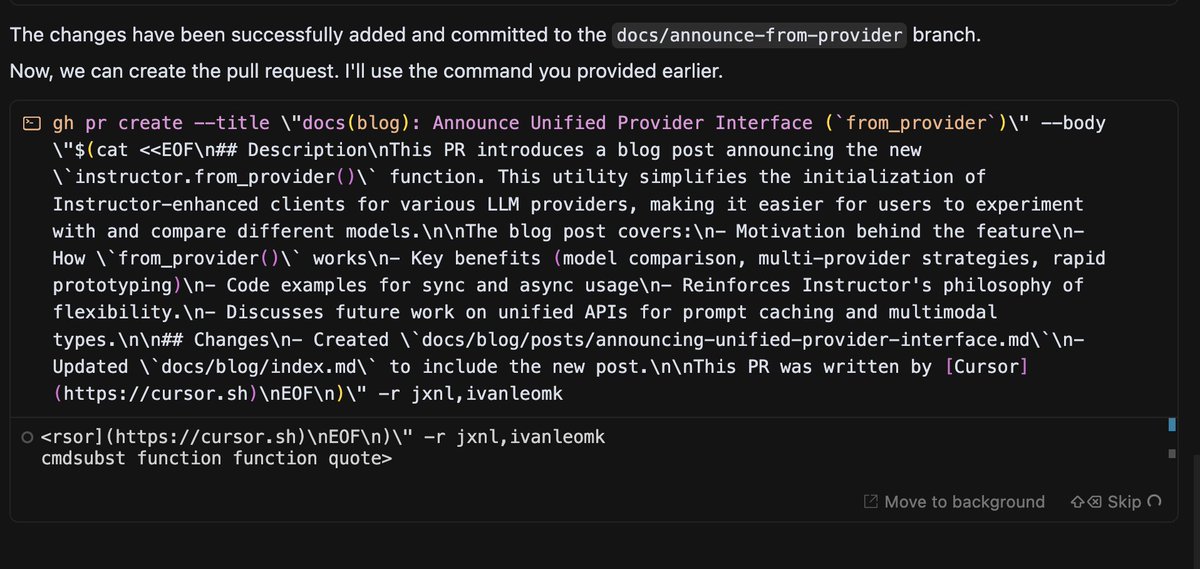
cursor writes my pr bodies. so clean https://t.co/gMmtrSbKHM
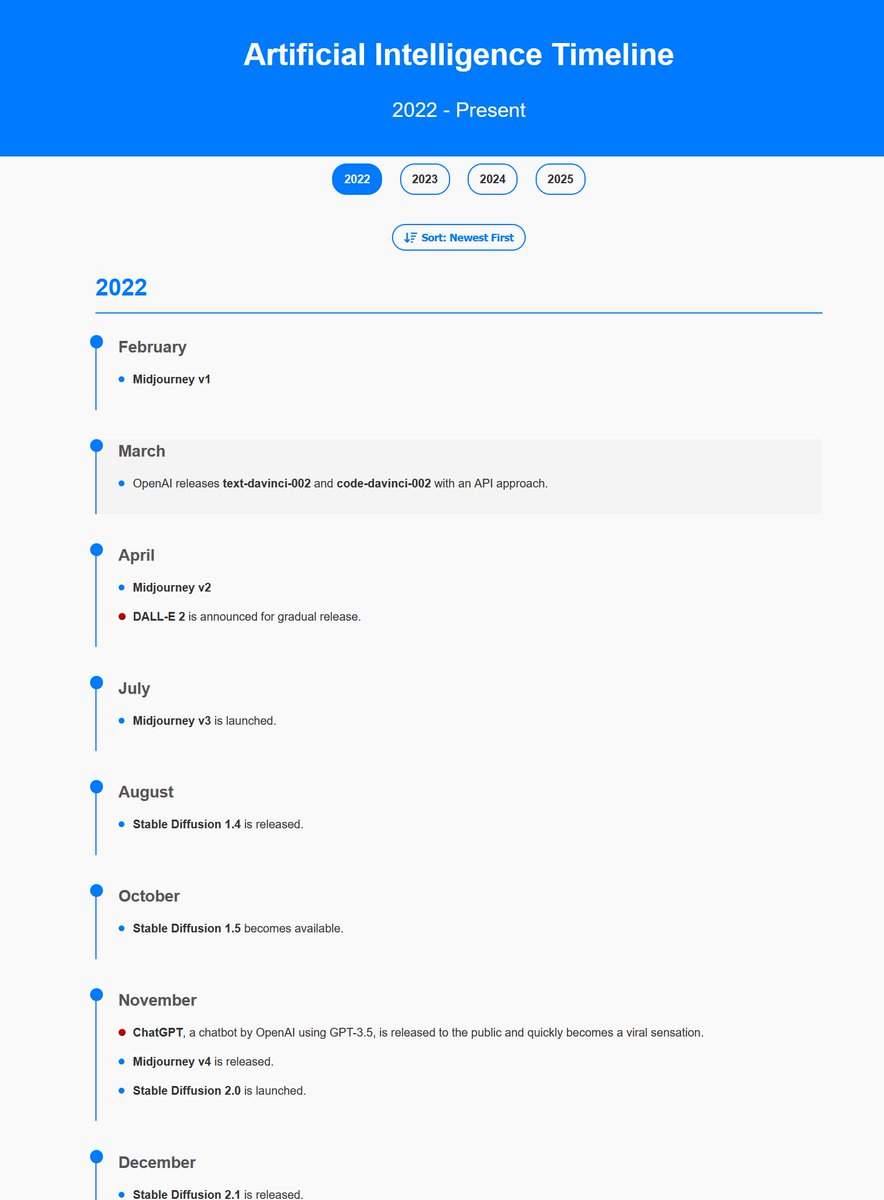
AI timeline starting from 2022, so much has happened since then... https://t.co/9YrOKmh091
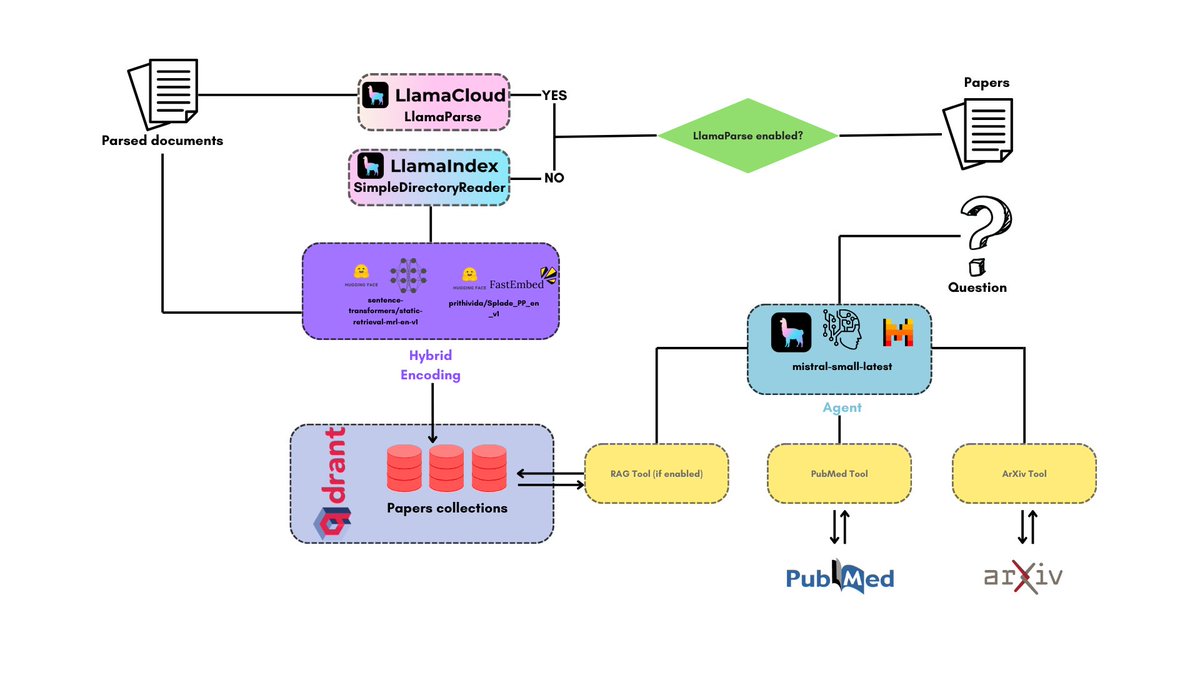
PapersChat is an agentic AI application that allows you to chat with your papers and gather also information from papers on @arxiv and on PubMed. Powered by @llama_index, @qdrant_engine and @mistralai! ➡️ Indexes all your papers ➡️ Provides a nifty web UI to query them ➡️… https://t.co/lYwXh27F9x
Kind of surprised that o3 is pretty good at poetry parodies compared to Claude 3.7. The new version is surprisingly literal compared to Claude 3.5, "The Destruction of Sennacherib, but for garlic bread" https://t.co/x82ile8QdQ


Atropos: a fully sovereign RL framework for frontier LLM training another strong open-source release from 𝐍𝐎𝐔𝐒 with full examples, environments, and trainer scripts https://t.co/xYcKkGdgZo

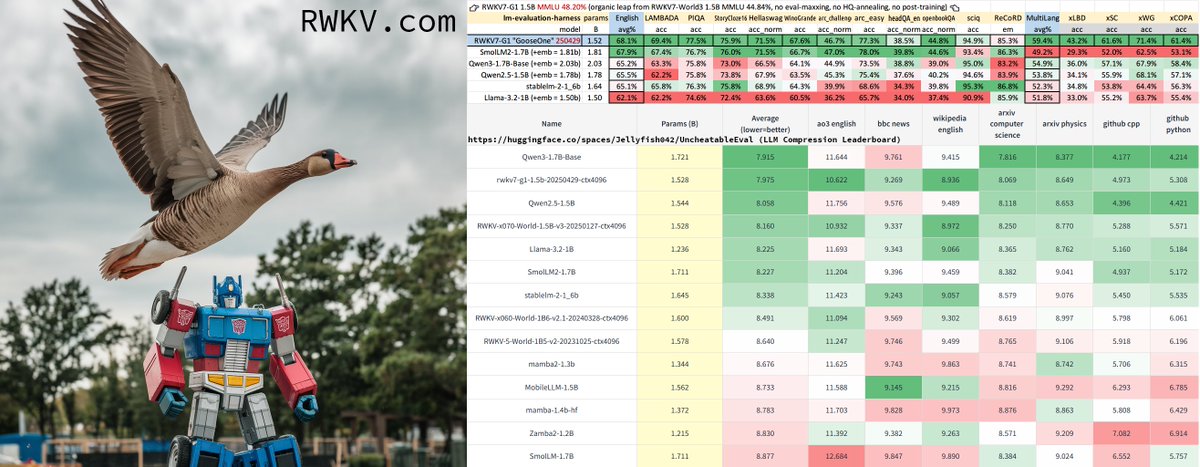
RWKV7-G1 "GooseOne" 🪿 1.5B release: pure RNN (attention-free) reasoning model, comparable with Qwen3 1.7B and fully multilingual. Chat demo & download on https://t.co/fZ7rmVKsKj Larger G1 training in progress. https://t.co/pGi060E0RY
“Among articles stating that data was available upon request, only 17% shared data upon request.” https://t.co/YCuC5vONtO

Our Mixture of Experts embeddings enable e-com / travel / marketplace companies to build their own version of this: https://t.co/VQAmdMAoYP
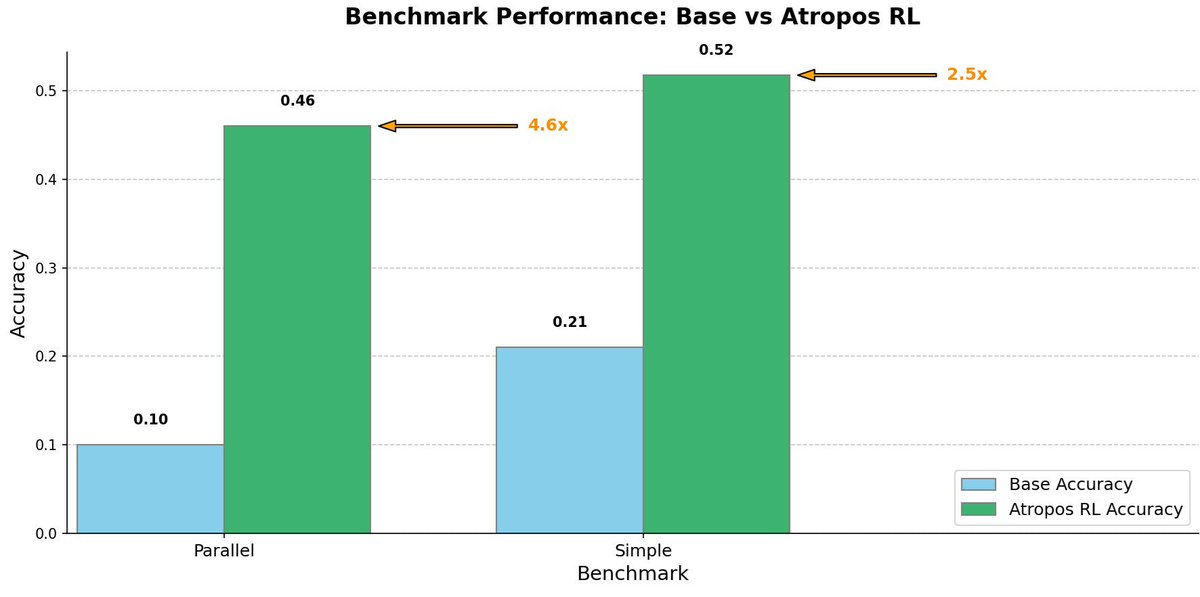
Today at Nous we released our RL Environments Gym - Atropos. With it we've been able to train impressive models like our tool calling specialist that saw a 5x improvement on the @berkeley_ai function calling benchmark and several other models that we've released as artifacts on… https://t.co/Ereuqv5rE9
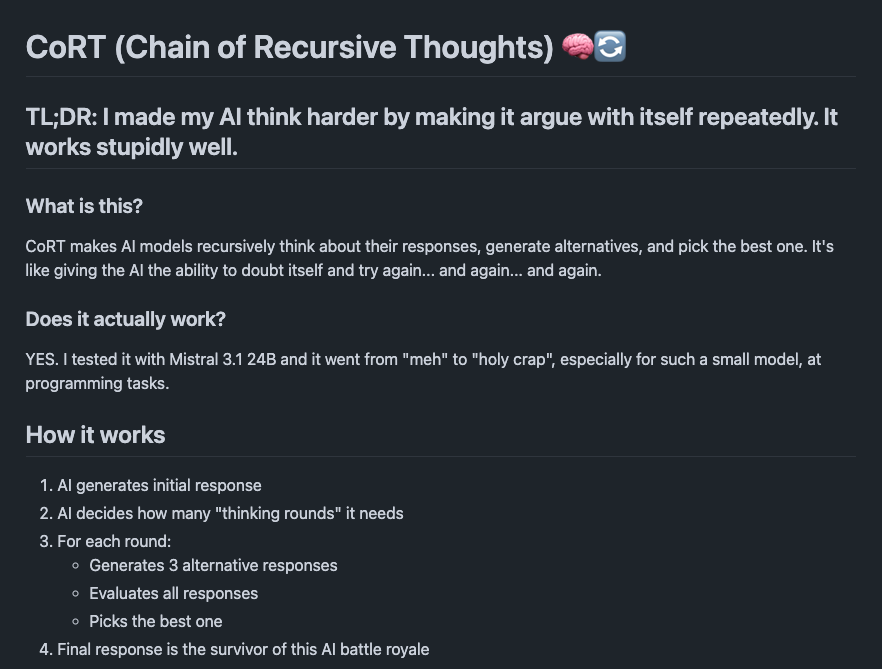
Just when I thought I'd seen everything about CoT. Chain of Recursive Thought doesn't sound like a novel idea, but it is a nice trick to make LLMs think harder. It works like a meta-prompt with a recursive component. https://t.co/qIJx4EVR8f
Deep Research with Gemini 2.5 has become very good. It spontaneously generates tables, scenarios, and compiles evidence. Haven’t spotted errors in spot checks. https://t.co/4JjVulx8v0

