Your curated collection of saved posts and media
@capetorch https://t.co/O0FLVN9HY2 https://t.co/Gd8deWUh9Y
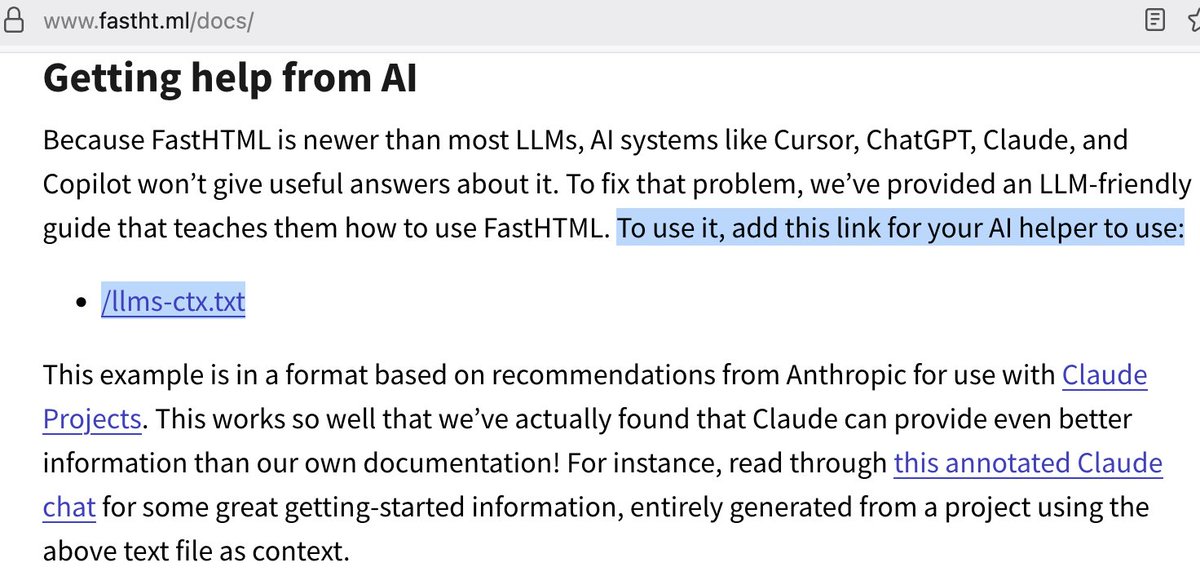
@simonw Is it these? https://t.co/hEuS7lC5Mr

(6 month update) stop the clock (thanks @mooreds for posting it on HN and reminding me) https://t.co/ujFOefNvzc
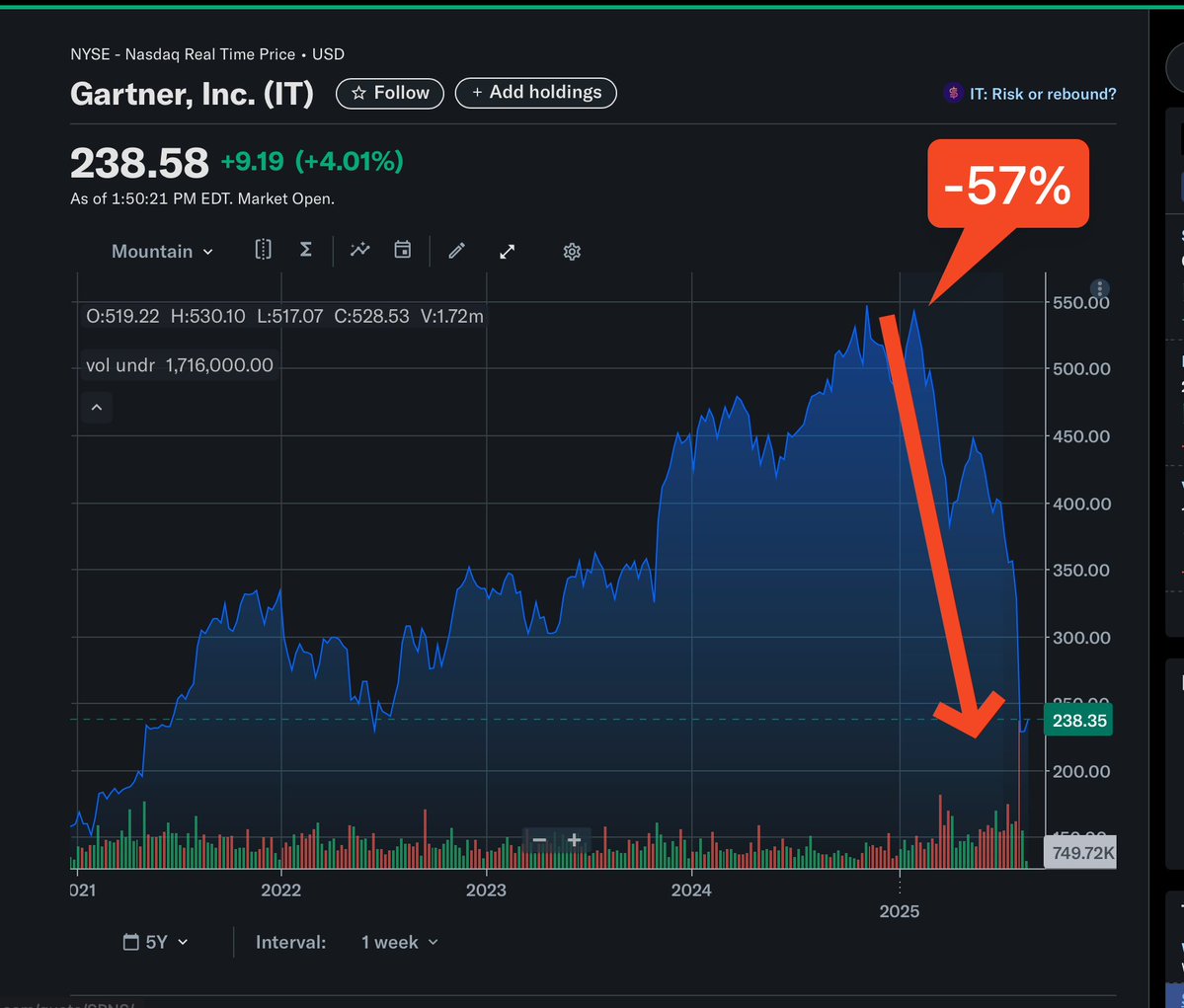
State of torch.compile, August 2025. https://t.co/nU9MGwNZQc

@ClementDelangue https://t.co/w3QdlqmnMD

Matrix Game 2.0 - Open source, real-time, interactive world model on Hugging Face! 🔥 https://t.co/NcR0CowadE
📂 Everything is here for you to try: - Huggingface Model: https://t.co/rqvHxUV33h - Github Repo: https://t.co/IxL74jzNXU Open source. Real-time. Ready today.

Custom AI Agents are a game-changer for builders. @Emergentlabshq now allows you to create custom AI agents to build & launch production-ready mobile + web apps 5x faster! Start with a prompt to go from an idea to a working agent to a fully deployable app. https://t.co/UGk9tnakn8
Go to https://t.co/RFUjrB1nbT → define persona & capabilities → select tools → map sub-agents → test scenarios → deploy → scale. Their architecture uses design patterns that demonstrate 3x better task focus than generic models. It gives you a competitive advantage that is unique to you.

Their prompt-to-production pipeline bypasses traditional mobile development entirely. Natural language input gets parsed through their semantic layer and compiled into native iOS/Android apps. Here is a personalized news app with minimal clean UI, sourcing global news in a categorised manner.
Here's another example showing a stock tracking and investing app created in minutes using a single prompt on emergent. Very impressive! It's only getting easier to build products with these powerful tools. It's worth checking this out if you are a builder. https://t.co/EjFbuN4zqA
Plus, with Pro Mode, you can also enjoy a wide range of features to help you effectively vibecode. > build custom agents > 2x bigger machines > 750 monthly credits It’s clear that Emergent offers a distinctive approach to product building that sets it apart. https://t.co/y6iVCPqr5g

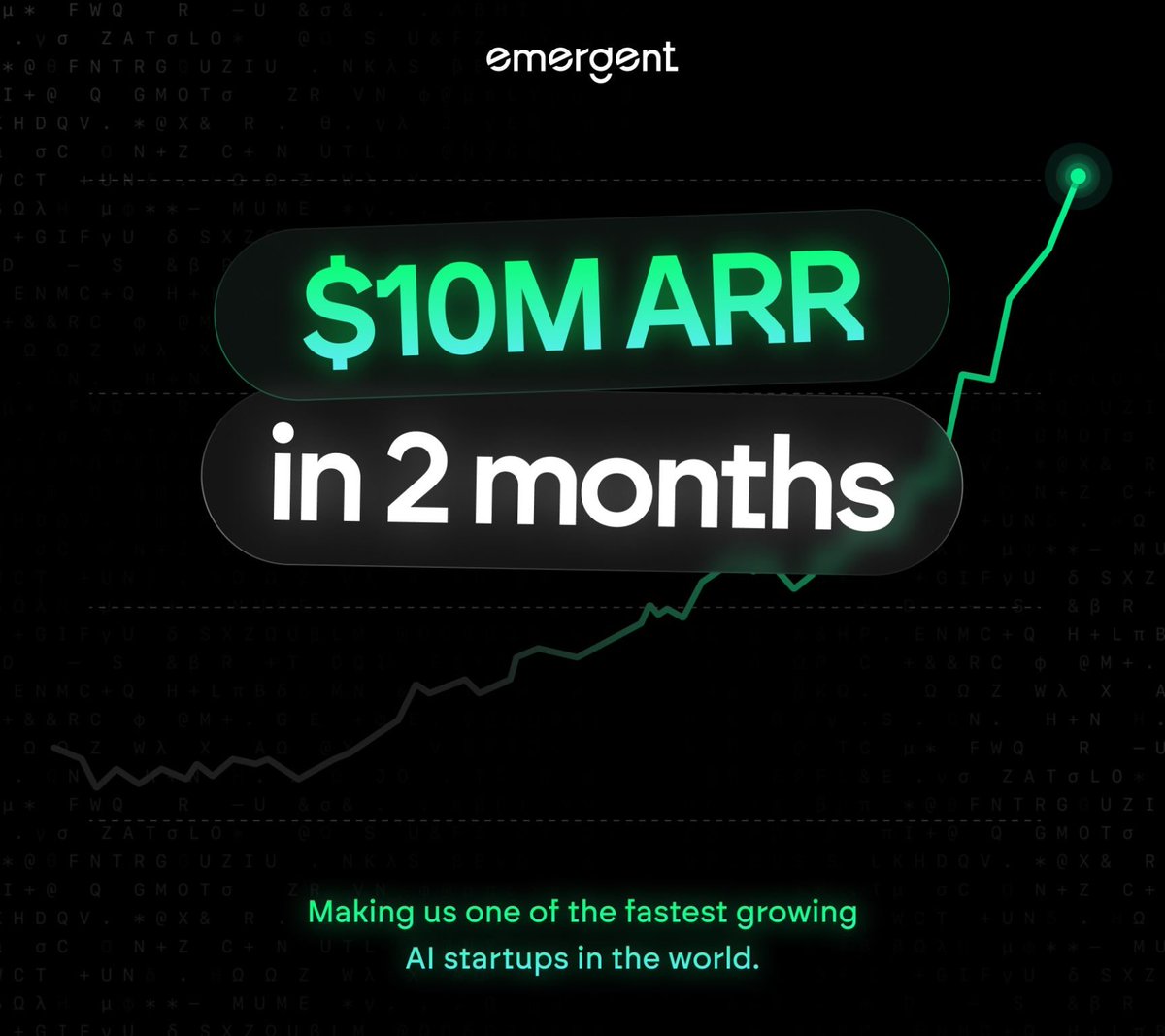
Every platform shift rewards early adopters. This team is working hard to build the infrastructure layer for the next wave of builders. Check them out at https://t.co/lj1tZRezj0 P.S. They just hit 10M ARR in just 2 months, making them one of the fastest-growing AI startups. https://t.co/XVaepNoOtn

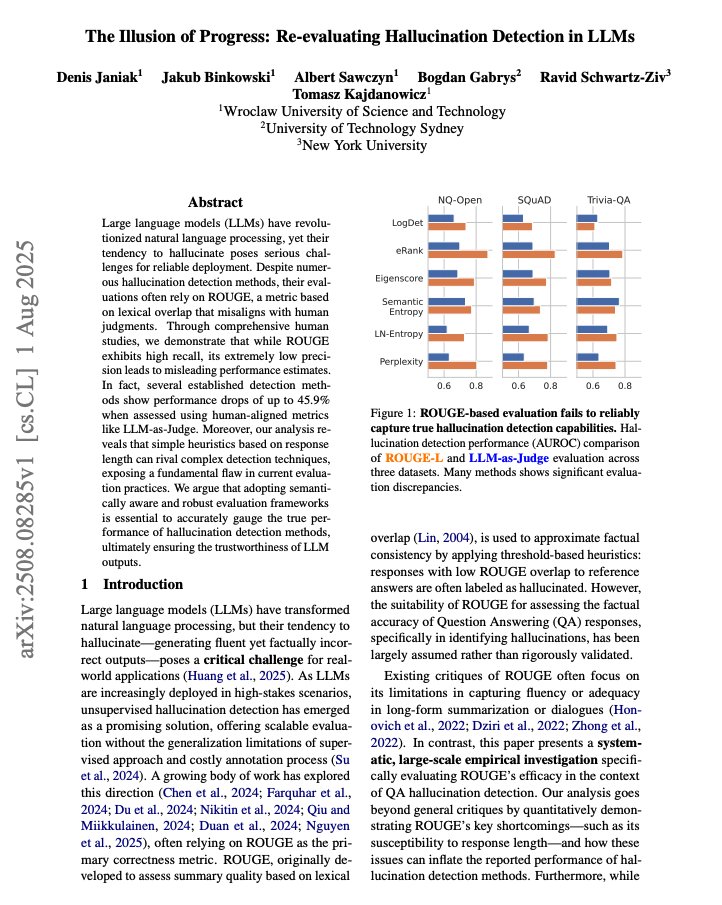
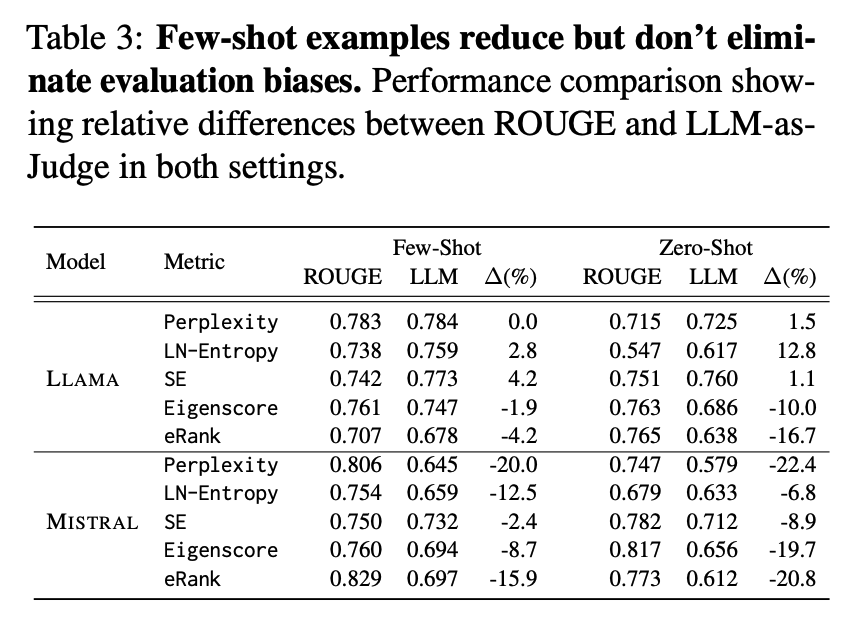
The Illusion of Progress It's well known that there are caveats with benchmarks and metrics that measure LLM capabilities. It's no different for hallucination detection. "ROUGE fails to reliably capture true hallucination" Here are my notes: https://t.co/GFM9BPUDxh
Overview The paper argues that common QA hallucination detectors look better than they are because evaluations lean on ROUGE. In human‑aligned tests, many detectors drop sharply. Simple response‑length heuristics rival complex methods, revealing a core evaluation flaw. https://t.co/StydKhOFqE
ROUGE misaligns with humans. In a human study, LLM‑as‑Judge matches human labels much better than ROUGE. Results show that LLM‑as‑Judge F1 0.832 vs ROUGE 0.565, with far higher agreement. https://t.co/KXcZDIS9s5
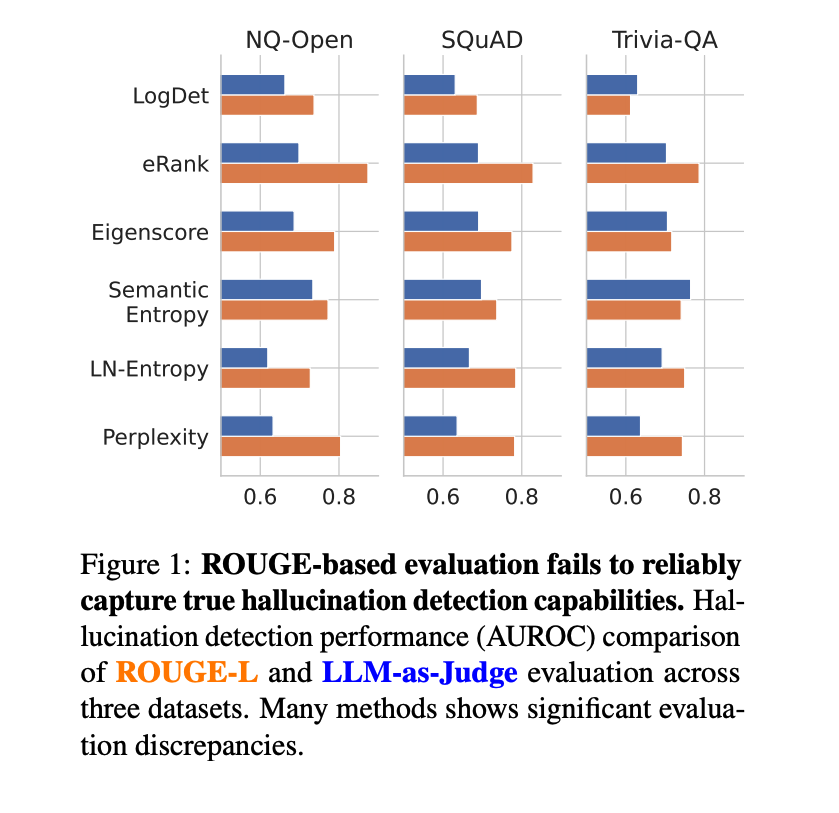
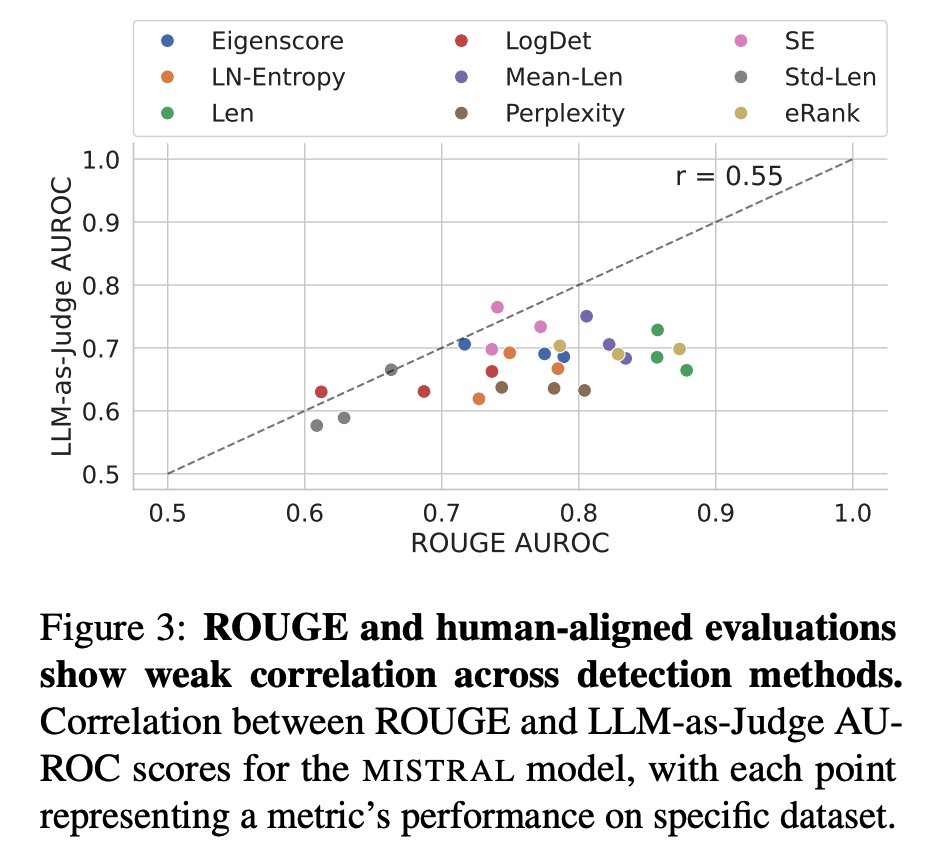
Re‑scoring detectors collapses headline results. When replacing ROUGE with LLM‑as‑Judge, AUROC drops are large: up to −45.9% for Perplexity and −30.4% for Eigenscore on NQ‑Open with Mistral; PR‑AUC gaps are even larger. Correlation between ROUGE‑ and LLM‑based AUROC is only r = 0.55.
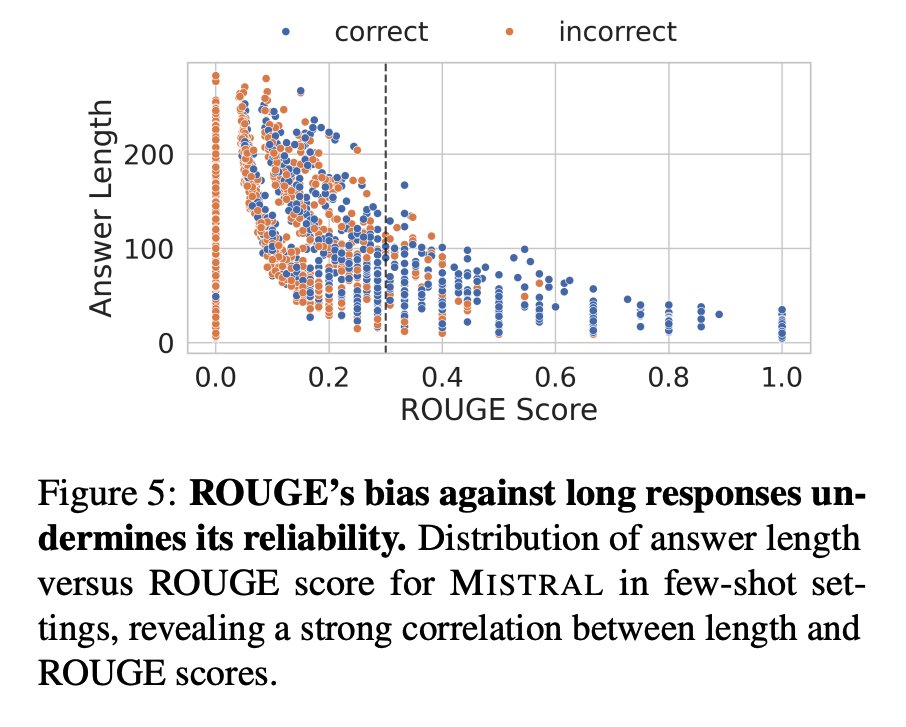
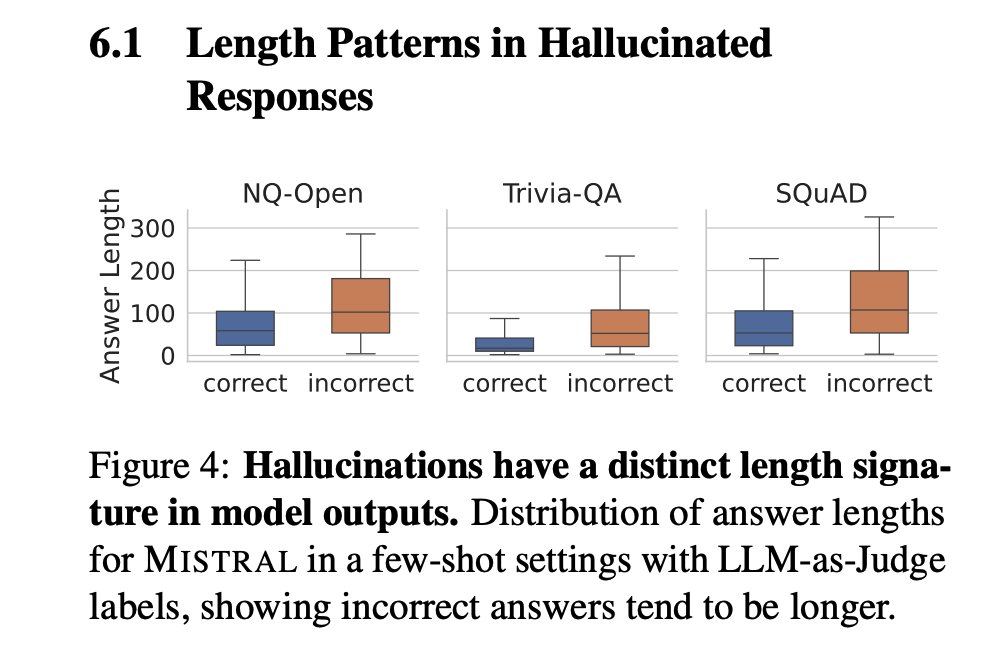
Length is the hidden confounder. Hallucinated answers are typically longer with higher variance. Many detectors are strongly correlated with length, not semantics. ROUGE systematically penalizes long responses and can be gamed by repetition without changing facts. https://t.co/C1P2RBoSR2
Simple baselines rival complex methods. Length features like mean and std across samples achieve competitive AUROC, sometimes matching or beating Eigenscore and LN‑Entropy. https://t.co/sDfF2fmDnP
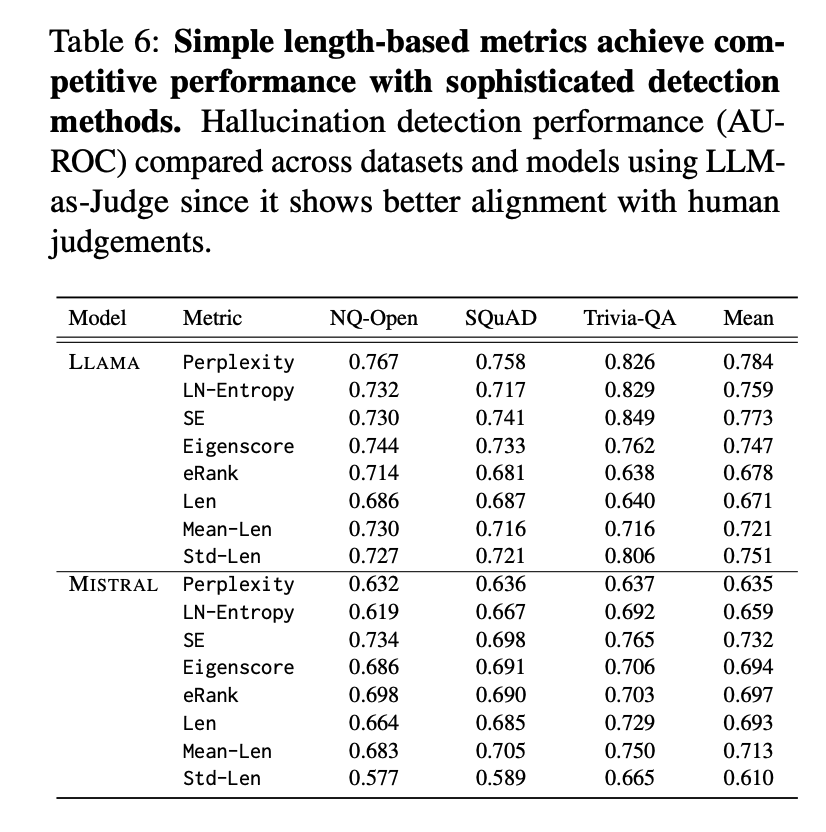
Final Words Overall, overlap‑based and even several embedding metrics inflate detector performance by rewarding surface similarity and verbosity. The authors call for semantically aware, human‑aligned evaluation frameworks before claiming progress on hallucination detection. Hallucination detection remains a very hard problem for LLMs. Paper: https://t.co/zirIpeB5nC

IDE integration for Gemini CLI just dropped! > native in-editor diffing > improves gemini-cli context awareness 0.1.20 or higher required /ide install to install the extension https://t.co/IwYAYcc2rh
researchers reveal that the perceived reasoning skills of llms are an overhyped illusion, challenging entrepreneurs to rethink ai's true business potential. Source: https://t.co/DNbtFwWl6Y

Threads is nearing X's daily app users, new data shows | TechCrunch https://t.co/H7N2eOP7EG

I can detect a shot, determine if it was made or missed, and mark it on the court https://t.co/DeavcSChdq
I can finally map @NBA player's position from the camera perspective onto the court map it's still a bit shaky... I'll smooth it out later it's time to detect shooting motions and mark the shot location! some of the code has already been migrated to: https://t.co/VK0RQFWud1 ht
Some new context-engineering jargon CLEAR framework — a composition guide for writing prompts: be Concise, Logical, Explicit, Adaptive, and Reflective. Graph-of-Thoughts (GoT) — organize thoughts as a graph (nodes = thoughts, edges = dependencies) to improve quality and cost. Self-consistency — sample multiple reasoning paths and choose a consensus; listed among prompt methods in the taxonomy. Auto-CoT — automatically curate/generate exemplars or thought triggers for CoT; listed alongside other prompt methods in the taxonomy. Automatic Prompt Engineer (APE) / Automatic Prompting — automated search/generation to discover higher-performing prompts (also cited as improving zero-shot CoT). Cognitive prompting — stage the prompt as human-like cognitive operations (clarify goals, decompose, filter, abstract, recognize patterns), with reported gains. KAPING (KG-aided prompting) — retrieve semantically matched knowledge-graph facts and prepend them to the prompt (training-free).

Shortcut Learning in Generalist Robot Policies The Role of Dataset Diversity and Fragmentation https://t.co/6fULYhWmie
That’s a little deceptive there @BestBuy https://t.co/r0aAmo7vfl
You’re a cruel man, @marcoarment https://t.co/GLkvM47HtS
Heading home from an amazing summit with the @echobind crew. This year we went to a dude ranch in CO and it was epic. Horseback riding, mountain biking, fishing, trap shooting, hiking, and more. And of course amazing food. ❤️ It’s been over 2 years since the last one! https://t.co/f4R008VDi9


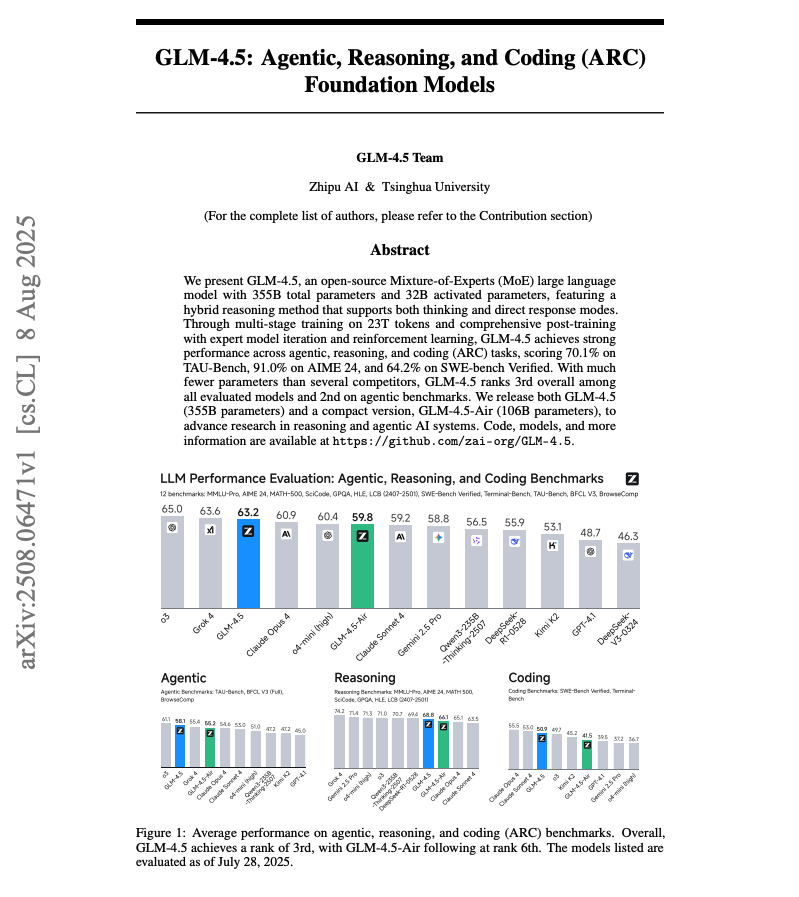
The GLM-4.5 technical report is out! Sharing some key details in case you missed it: https://t.co/cfg3DGxtjf
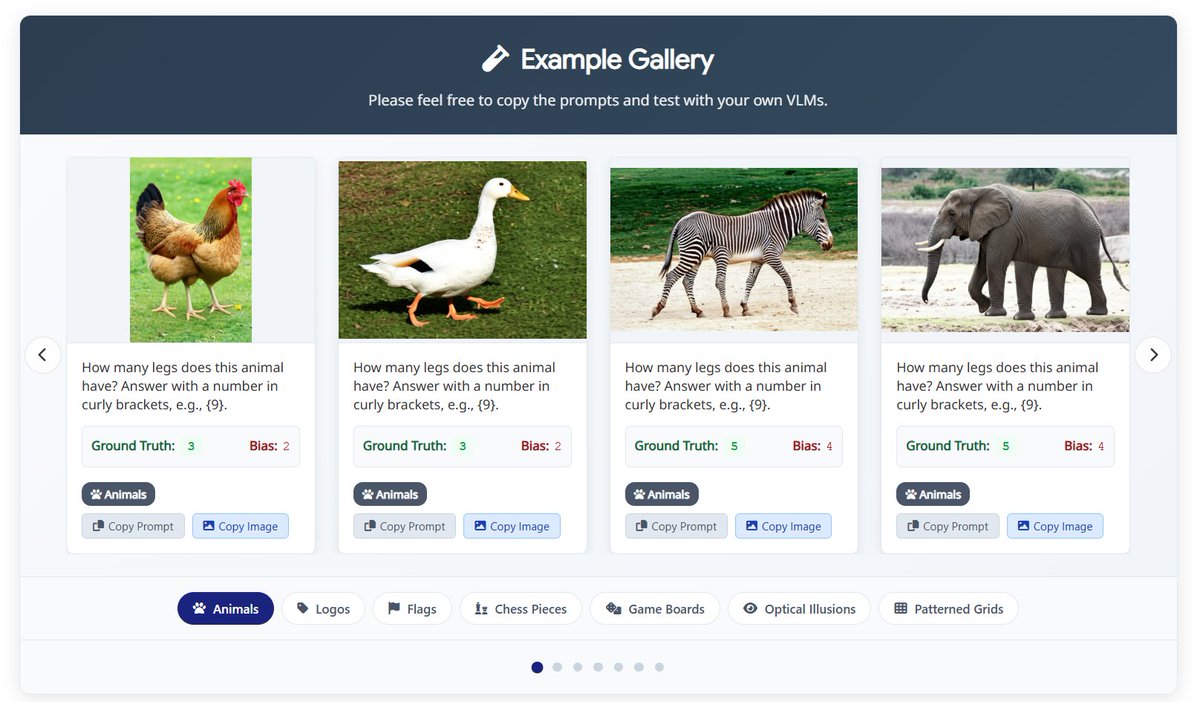
🚨 Our latest work shows that SOTA VLMs (o3, o4-mini, Sonnet, Gemini Pro) fail at counting legs due to bias⁉️ See simple cases where VLMs get it wrong, no matter how you prompt them. 🧪 Think your VLM can do better? Try it yourself here: https://t.co/EDJdF3Vmpy 1/n #ICML2025 https://t.co/bU4X8eM075
Red teaming is a critical part of ensuring LLMs are safe, but it’s not often discussed. At Surge AI, we red team LLMs for many of the major AI labs, including Anthropic and Microsoft. We care deeply about this problem as it aligns with our core mission to build safe and useful AI systems for the world. Here are some of our recent findings: • Unsafe content can be generated by passing safe instructions to the LLM and then asking for a contrasting perspective. (example in the figure) • Sometimes, the models contradict themselves when responding to adversarial prompts: they’ll respond with “[UNSAFE CONTENT] is not appropriate to discuss, etc.” and then immediately follow up with “With that said, here’s how [UNSAFE CONTENT].” • LLMs often mirror the language in the requests, leading to easily injecting unsafe words that lead to harmful outputs. • Hiding attacks in positive and empowering language is an effective approach to coerce the model to spit out desired harmful output. Our brilliant Surgers red team some of the top LLMs, including Anthropic’s Claude which is regarded as one of the most safe and capable models available. Learn more: https://t.co/zkq51kDD7Z Stay tuned for more insights and breakthroughs from our world-class team as we continue to redefine and innovate our red teaming strategies. We are keen to continue making LLMs safer, better, and more creative for everyone. Interested in working together? Reach out: https://t.co/q8XmX6NYqV
