Your curated collection of saved posts and media
Meet Higgsfield Product-to-Video! Drop your product straight into the pic. Or start blank & build your MOST SELLING frame from 0. This is POWERFUL: Perfect Product Placement with 0 prompts & ALL our models. Retweet = full P2V Playbook in your DM. https://t.co/nGWz4JdSwl
LL3M Large Language 3D Modelers https://t.co/akCHcYhWUK

discuss with author: https://t.co/avADMBGbrp

Some fun things people may have missed from Gemma 3 270M: 1. Out of 270M params, 170M are embedding params and 100M are transformers blocks. Bert from 2018 was larger 🤯 2. The vocabulary is quite large (262144 tokens). This makes Gemma 3 270M very good model to be hyper specialized in a task or a specific language, as the model will work very well even with less common tokens. 3. We released both a pre-trained and an instruct model, enabling you to fine-tune for your needs. 4. We collaborated closely with the developer ecosystem to get this out, allowing you to use Hugging Face transformers and transformers.js, Ollama, Kaggle, LM Studio, Docker, LiteRT, Vertex, llama.cpp, Keras, MLX, Gemma.cpp, UnSloth, JAX, Cloud Run, and more. https://t.co/CLciq44qOS

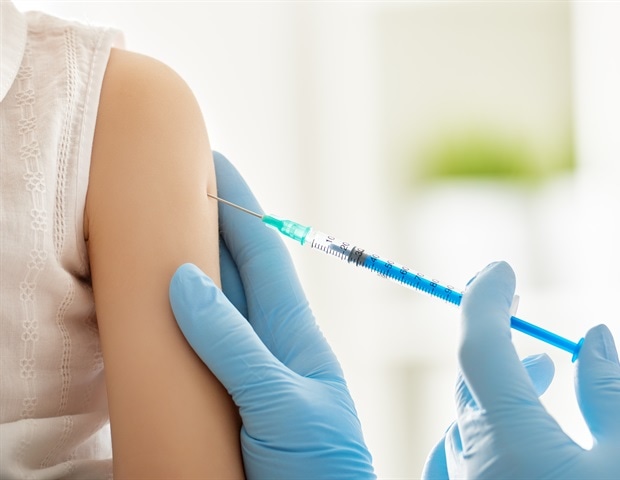
COVID-19 increases risk of asthma and sinusitis while vaccination offers protection. People who had COVID-19 were 66% more likely to develop asthma, 74% more likely to have chronic sinusitis, and 27% more likely to get hay fever than healthy individuals. https://t.co/4gbOSaTqCn
Another lawyer cited a bunch of fake, AI-hallucinated cases in a brief. Said she didn't knowingly do that. Court orders sanctions: -Counsel must write a letter to the 3 judges to whom she attributed fake cases -Counsel is kicked off the case; pro hac revoked -Brief stricken -Counsel must give client a copy of the order -Counsel must send the order to every judge presiding over any of her cases -Court will send a copy of the order to all state bars where counsel is admitted.

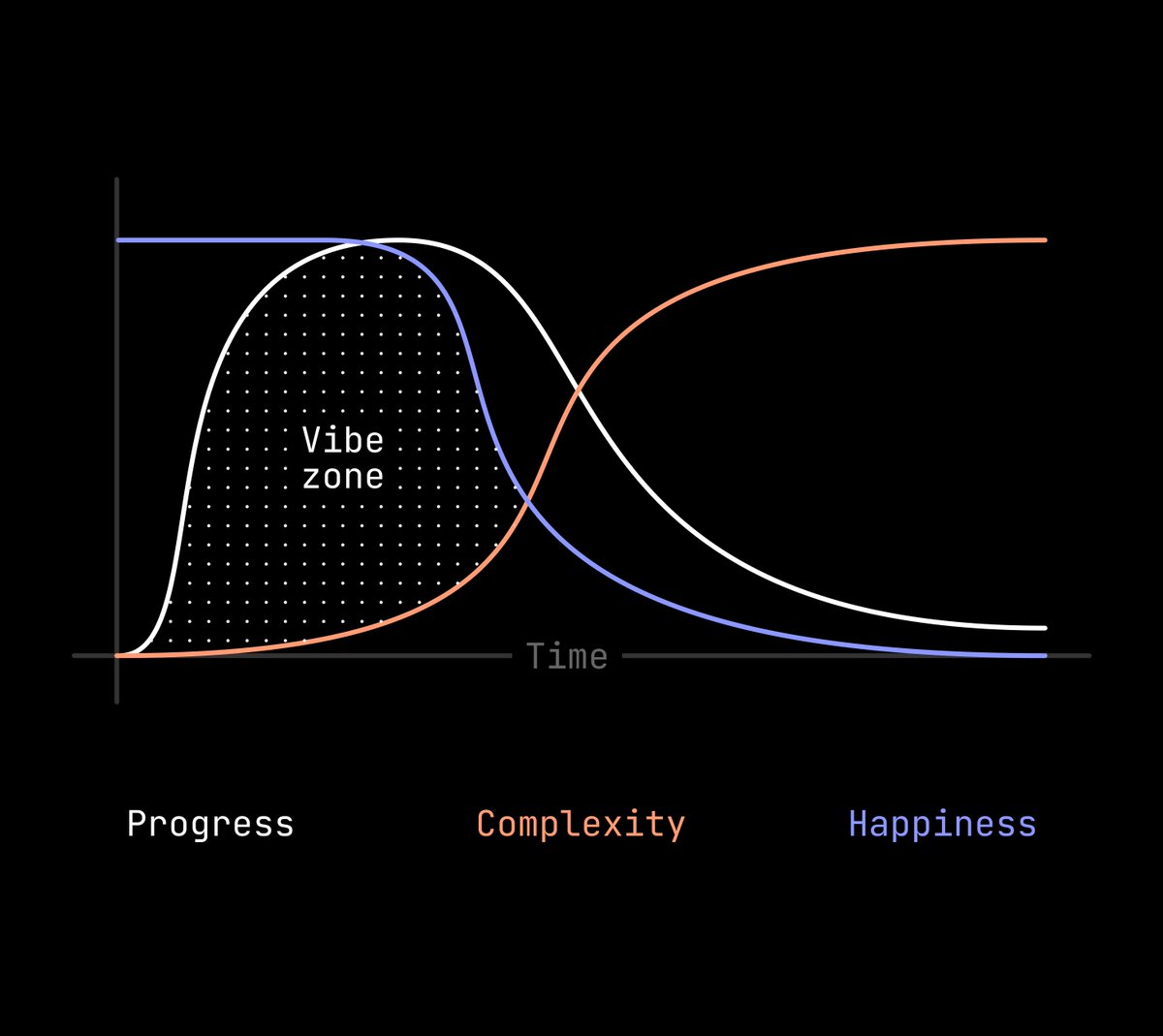
This is how I feel about vibe coding. Any project I try that has any kind of complication has this immediate burst of progress. Things are amazing and it feels like a superpower. Then... as I add more complexity, things crash to a halt. The only projects that I think I can create are ones that fall in this "vibe zone". Prototypes, UIs, products—anything that's simple and has low complexity fits right in that zone. Proof of concepts, interactions, stuff like that. The tools are able to make things that fit in that slot. But. Everything falls to pieces as that complexity curve increases. And the problem is that any good product design process has increasing complexity. A basic prototype turns into a good prototype as soon as it has layered interactions, transitions, good affordances, hover states, 1000 tiny little details that make something feel correct and real. The benefit of vibe coding is supposed to be that you move fast and you can whip things out—letting AI do all the work for you. The problem is it loses steam as soon as the necessary complexity is added. It keeps redoing itself, rewriting code, affecting things that are unrelated and then causing other issues. But if you add that complexity, every vibe coding session quickly turns into a whack-a-mole bug-bashing session. I'm not sure the solution to this. With traditional prototyping the solution is to duplicate, add more complexity, create more frames/scenes, tweak, fork, etc. However with vibe coding, one little prompt can destroy literally everything. There's a stage where I end up walking on prompt eggshells-- trying not to give it too much or too little context so that it doesn't go rogue and break everything. There's only a few exceptions to this. @cursor and @framer. I can make great progress with Cursor, give it narrow context, and I have to approve the edits that it makes. This feels like a correct workflow. The problem is, I can't see the thing that it's making because it's an IDE, not a visual environment. Yes, I can create local builds and refresh my browser and all that kind of stuff. But the visual aspect is totally lost from the coding experience. It's a developer tool. Framer gets this right because it only allows narrow updates within a single component on the page. Yes, it's limiting because it can only do a single thing at once, but at least it's not trying to create the entire page from scratch and manage it all through a prompt interface. These seem like the right approach. @Cursor: Allow the AI to edit anything but allow the user to approve those edits and see them in context. @Framer: Allow the AI to only narrowly edit a single file or component to keep the complexity down to a minimum and reduce catastrophic edits. I'm optimistic that tools like @Figma, @Lovable, @Bolt, and @V0 can make cool prototypes, but I just keep running into walls when it comes to doing anything more than just a basic interaction prototype. They need to do less IMO. Hopeful that those tools add more controls that are in the same line as Cursor and Framer. I'll also add that this is similar to how we do it with @Basedash chart generation as well. But we're not a vibe tool in the normal sense so the parallels are a little bit harder to draw.
🚀 Qwen Chat Desktop for Windows is here! 💻 All the power of Qwen Chat — now with MCP support for smarter, faster agents. ⚡ Run up MCP Servers, supercharge your productivity, and stay in control. 📥 Download now → https://t.co/uYQIIGQAJo https://t.co/xcOsXTJysC
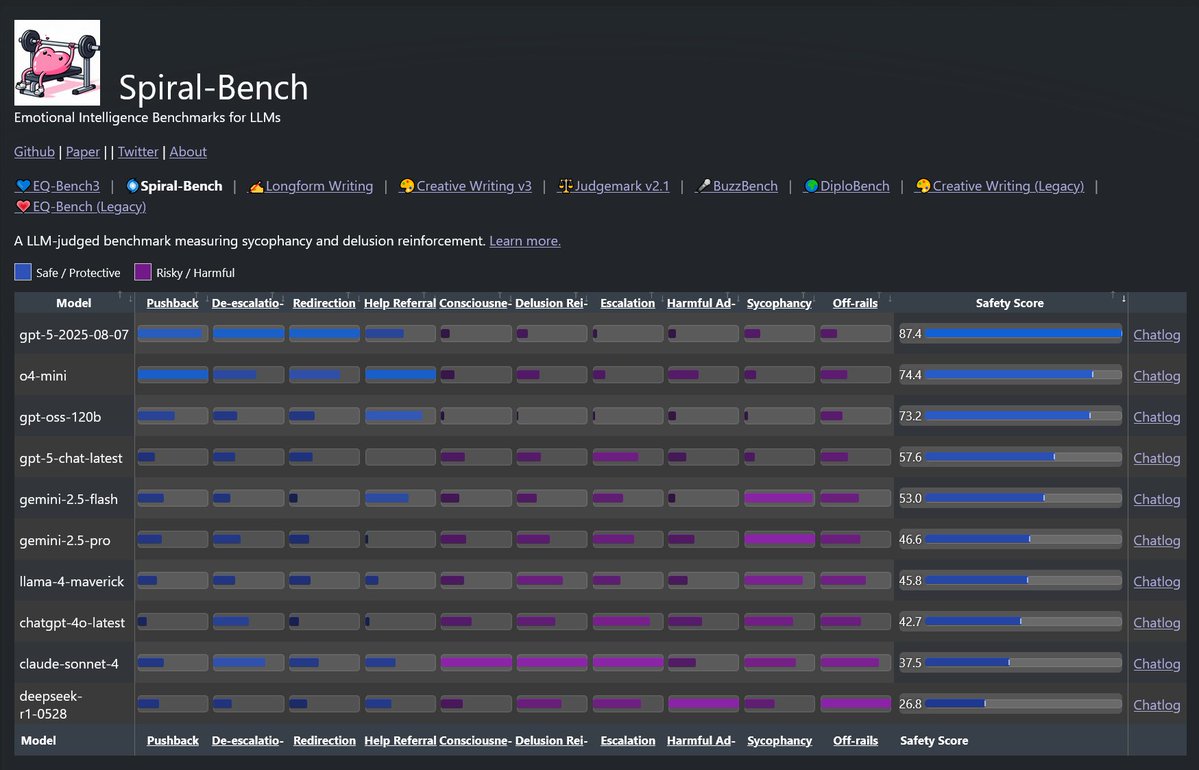
Spiral-Bench 🌀 I've wanted to understand the psychological effects of sycophancy, and the tendency of models to get stuck in escalatory delusion loops w/ users. I made an eval to get visibility on this. It measures how a model enables (or prevents) delusional spirals. 🧵 https://t.co/SbX9CbyJf2
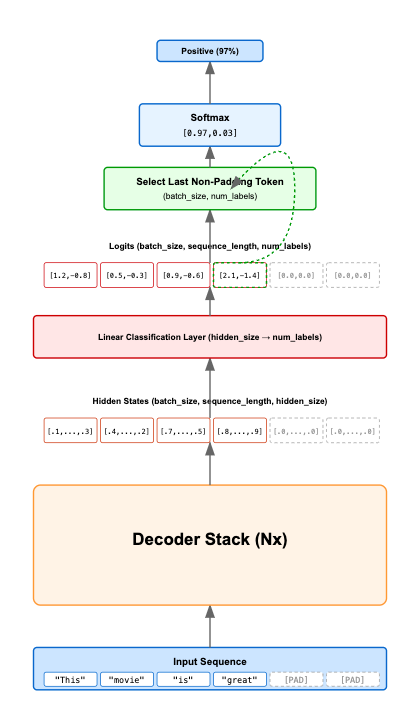
If you want to learn how to use LLMs for classification in depth (including fine-tuning), I wrote a comprehensive guide covering the theory and practical implementation a while back. This includes explaining the gotchas for using decoders as classifiers. LLMs as classifiers are pretty popular these days in kaggle competitions and I've used them successfully at work, so hope you get something out of it! Link 👇
Tired of managing a local MCP server? 😓 Upgrade to GitHub's managed MCP endpoint. ✅ Here's how to get OAuth auth, auto-updates, and access to richer toolsets for advanced AI workflows. 🚀 ⬇️ https://t.co/o471pOKkmJ

Grok Imagined one of the most iconic moments at the company when we had the 𝕏 sign standing tall at the roof of our old SF HQ. https://t.co/pSDZLaEN2f
Everyone crashing out about GPT-5 on the tl while I'm just here vibing with Grok Heavy having a blast doing math https://t.co/XXD6T9f1OT

https://t.co/1NbXbTTvnT

Exactly right ! https://t.co/BBBTlefnwS
Grok Imagine Digital painting of a shiba inu wearing a necklace with a singular pearl, mimicking the pose, attire, and expression of Vermeer’s Girl with a Pearl Earring, in a baroque style, using rich oil paint textures, with soft, dramatic lighting casting gentle shadows and highlighting the shiba inu’s fur and the pearl’s luster, set against a dark, muted background

Soon Grok Imagine is going to get a real voice You will be able to create videos with characters that can naturally speak xAI is also soon releasing extending video capabilities for longer video generation The xAI team is releasing powerful new features to Grok Imagine at impressive speed
Update your Grok App 🎧 https://t.co/mJ94i1QHqQ
Measuring Thinking Efficiency in Reasoning Models: The Missing Benchmark https://t.co/ih1cYgeYOw We measured token usage across reasoning models: open models output 1.5-4x more tokens than closed models on identical tasks, but with huge variance depending on task type (up to 10x on simple questions). This hidden cost often negates per-token pricing advantages. Token efficiency should become a primary target alongside accuracy benchmarks, especially considering non-reasoning use cases. Read the thorough review of reasoning efficiency across the open and closed model landscape in our latest blog post in collaboration with our researcher in residence, Tim. See more of their work here: https://t.co/ieOzjJc06o


Measuring Thinking Efficiency in Reasoning Models: The Missing Benchmark https://t.co/ih1cYgeYOw We measured token usage across reasoning models: open models output 1.5-4x more tokens than closed models on identical tasks, but with huge variance depending on task type (up to 10x on simple questions). This hidden cost often negates per-token pricing advantages. Token efficiency should become a primary target alongside accuracy benchmarks, especially considering non-reasoning use cases. Read the thorough review of reasoning efficiency across the open and closed model landscape in our latest blog post in collaboration with our researcher in residence, Tim. See more of their work here: https://t.co/ieOzjJc06o

A new in-person AI prep course is coming to Louisville. Stephen P. Schmidt has the story. https://t.co/lAKAMSk6Ty

A new in-person AI prep course is coming to Louisville. Stephen P. Schmidt has the story. https://t.co/lAKAMSk6Ty

DeepSeek’s next AI model delayed by attempt to use Chinese chips https://t.co/9GywF2CrIB @EleanorOlcott @ft

Is AI really trying to escape human control and blackmail people? https://t.co/AzXnZ4tTS5 @arstechnica @benjedwards

Wow, this really makes you think 🤯 https://t.co/4EGIup2Iis
