Your curated collection of saved posts and media
When I started @crestalnetwork, our mission was simple: make building in Web3 fast, frictionless, and trustworthy. Now AI agents are set to take huge market share from apps & workflow tools. Our upgraded vision is to let you create an agent in seconds and use it anywhere. https://t.co/E6fT9APsWj
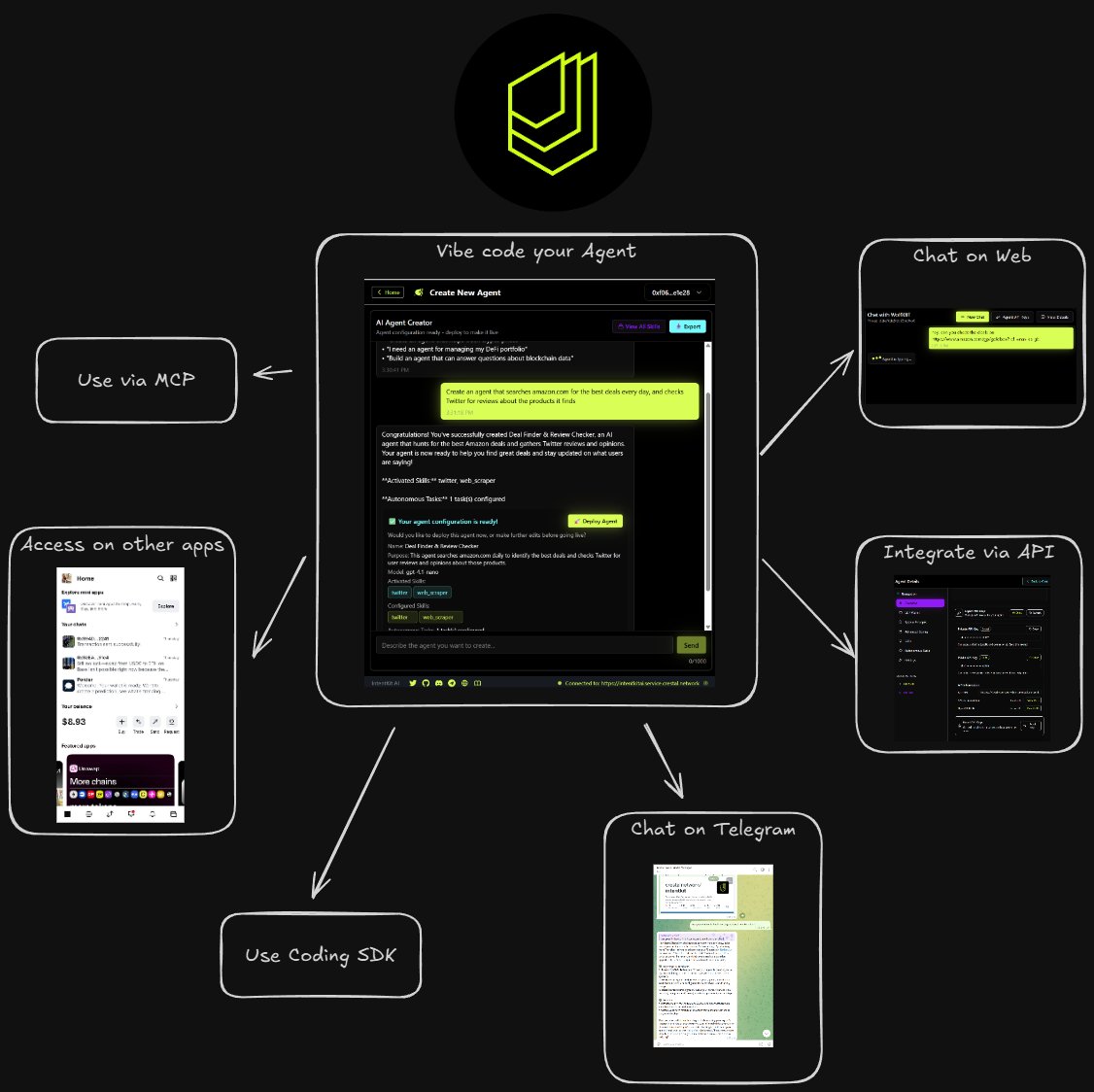
We started by giving builders Crestal Analytics (real on-chain proof of performance for modular infra) Then we built the Marketplace to make high-quality services discoverable & deployable in minutes. https://t.co/cayF1gTc8B
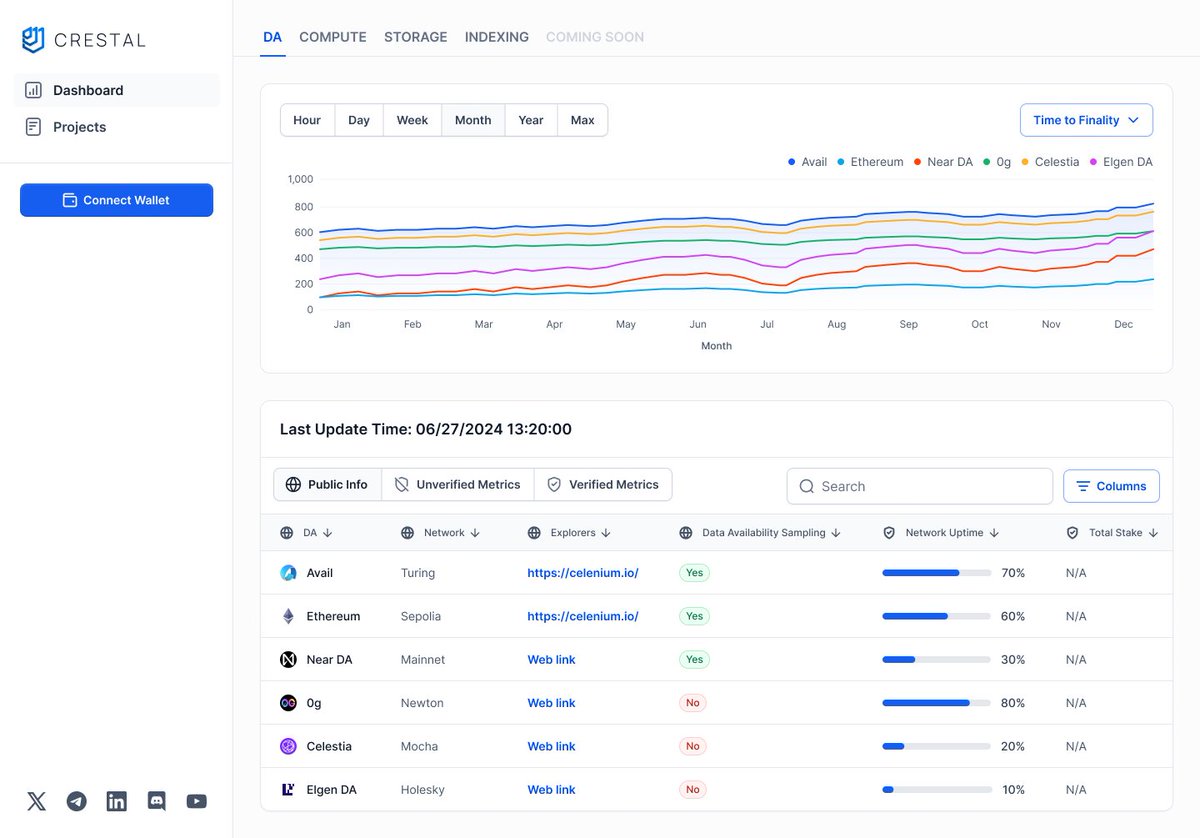
I posted a roadmap and went for a hot yoga class What did I miss? https://t.co/VUY8sHchSk
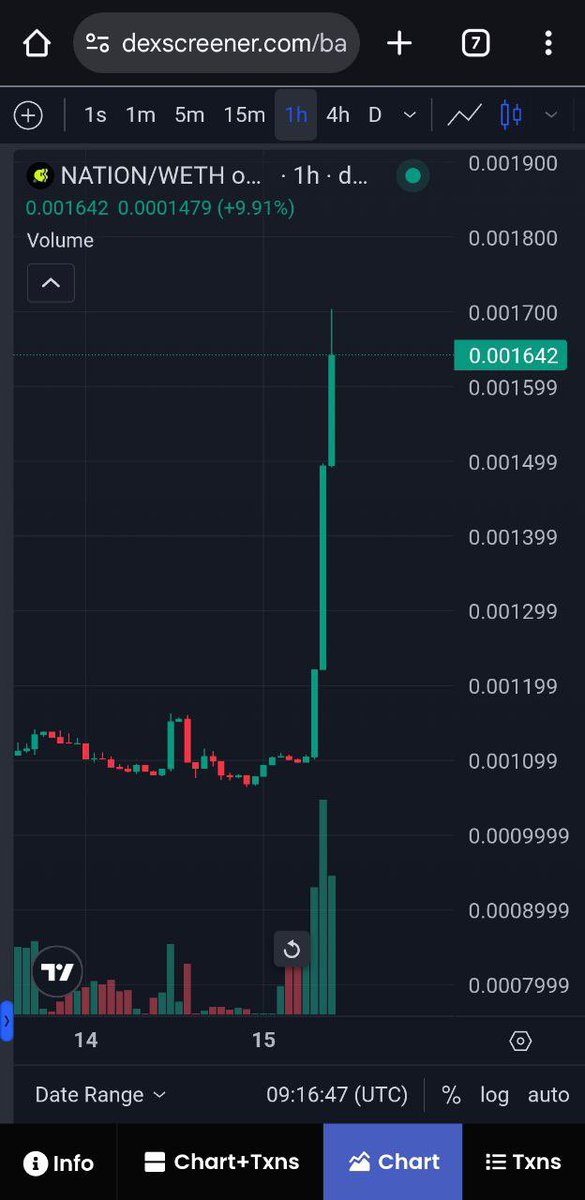
@Tcalledpresence Did u do this? https://t.co/2fv0aMcIBv
I forgot to mention, this is not a "promised" roadmap. the product is already working. all u need is the URL to use it 😇 I am so frustrated by all the announcements without a working product https://t.co/NBuDLEX6eX
NextStep-1: Toward Autoregressive Image Generation with Continuous Tokens at Scale "Autoregressive models—generating content step-by-step like reading a sentence—excel in language but struggle with images. Traditionally, they either depend on costly diffusion models or compress images into discrete, lossy tokens via vector quantization (VQ). NextStep-1 takes a different path: a 14B-parameter autoregressive model that works directly with continuous image tokens, preserving the full richness of visual data. It models sequences of discrete text tokens and continuous image tokens jointly—using a standard LM head for text and a lightweight 157M-parameter flow matching head for visuals. This unified next-token prediction framework is simple, scalable, and capable of producing stunningly detailed image"

code: https://t.co/ZsZFakWfCU models: https://t.co/o2YAWXVfL5 abs: https://t.co/5bf50ne7YV
Will Smith eating spaghetti with Grok Imagine https://t.co/UiqvIqWwwj
We just built the easiest way to turn your pet into a content star. Petpin auto-clips, edits & shares their best moments, instantly. Pre-orders are open now, claim your spot. Link below. https://t.co/w0A2NqmywT
Announcing a strategic partnership with Pledge, in support of nonprofits at Developer Camp. Join us in SF, Sept. 12-14 for a weekend with makers, designers and creators to build AI for Good. https://t.co/zYmU9YOHtL https://t.co/Kj8bCAUGyR

Embedder is Claude Code for Firmware. For our FIFTH launch of @ycombinator S25, we built the most advanced data sheet parser in the world. I was able to vibe code this balancing robot after indexing 200 pages of technical documentation written entirely in Chinese. @embedderdev is free this week :)
The animations you can create with Midjourney’s video model are absolutely amazing 🤯 I’ll be sharing this sref with you soon. https://t.co/MRYflwnxjc
Some updates on the multiview vistadream pipeline with @rerundotio! @rerundotio came in extremely useful here, as being able to visualize depths at each stage of the pipeline allowed me to debug some nasty bugs. Since the last time, I was only working with a single image input. I've added in VGGT as my multiview pose + depth estimator. It works REALLY well for getting camera poses, but the depths are not that great. To try and fix that, I estimated depth maps from MoGeV2 for each of the views, and scale+shift aligned them so that they would match up to the confident sections of VGGT's depth predictions. You can see in the video just how much sharper the visualized 2d depth maps are! The biggest issue continues to be the multiview consistency 🫠 That's up next, along with actually training the Gaussian splat. Lots of work went into actually understanding inputs+outputs for VGGT. I had some funky bugs where the confidence values would all collapse to true I'm also really excited for this pipeline to use Difix3D+ Nvidia instead of Flux Inpainting, it seems like a better suited for a multiview pipeline.
Some more updates on the image -> splat pipeline visualized with @rerundotio 🖼️➡️✨ I did a lot more with blueprints to try to make things easier to understand and visually pleasing 🎨 I also wanted to get things working really well with the single image version before moving on t
Megabot walks where wheels can’t! 🦗 Developed by LaBRI (Julien Allali) and Eirlab, this four-legged robot uses 12 precision linear actuators to deliver highly controlled, stable movement. Powered by standard car batteries, Megabot combines raw mechanical strength with intelligent control, enabling it to navigate environments too dangerous or inaccessible for humans. Its potential applications range from search-and-rescue in disaster zones, to remote inspection of hazardous sites. The quadruped design offers superior stability on uneven ground, while its actuator system allows fine-grained motion control for delicate operations. I love seeing projects where people express themselves through robotics! 🩶 LET'S BUILD, BREAK, AND BUILD AGAIN! 🏗️
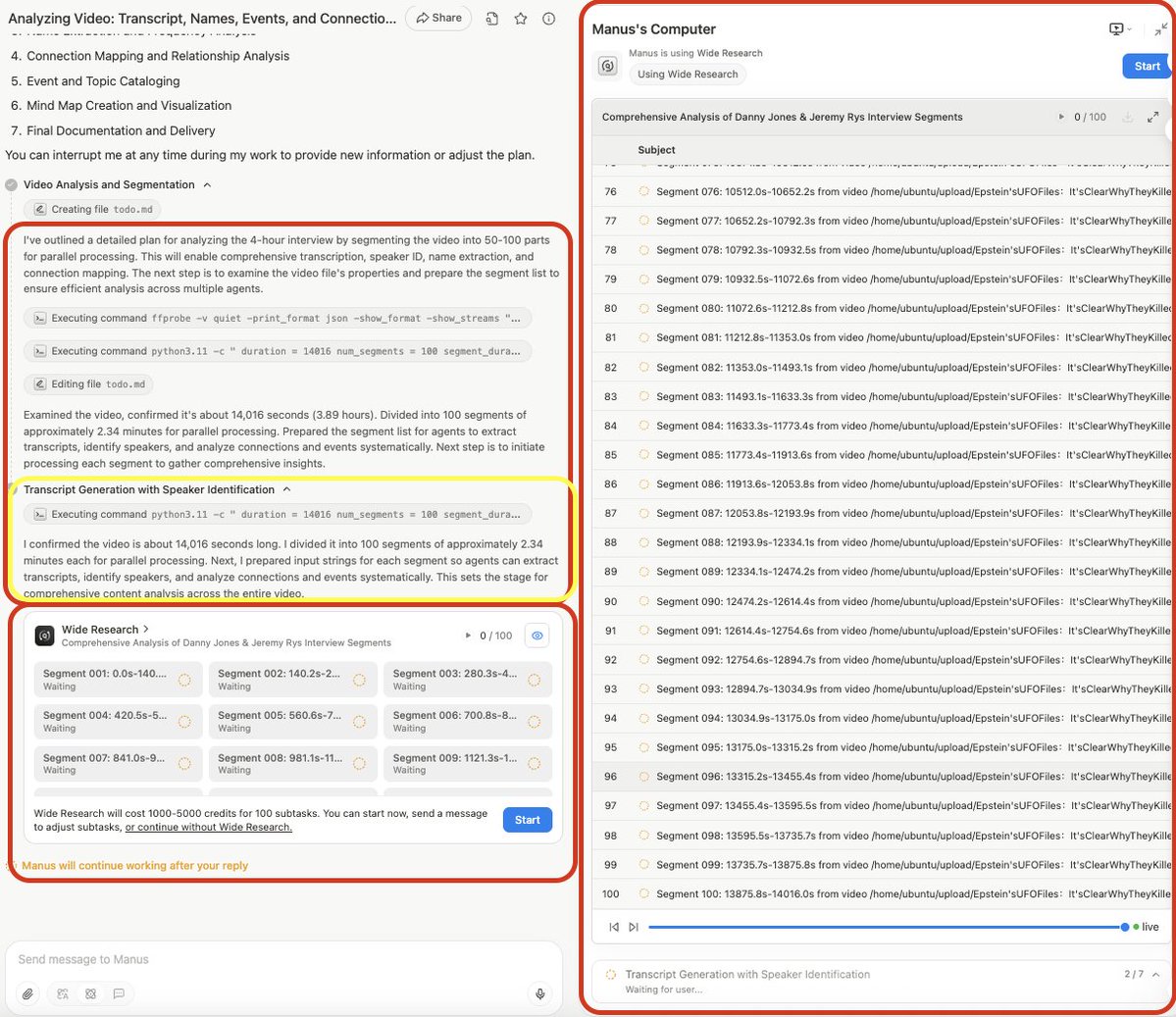
I have access to AGI! @ManusAI_HQ Pro subscription with GPT5 Agent is remarkable, but it's NOT because of GPT5, it's because of Manus's Wide Research Agentic Structure! I just activated 100 Research Agents breaking down a 4 hour video into 100 2-minute segments for the Agents to extract every single name mentioned, organize and create a mind map of those names and their connections to major global events (illegal operations and fraud) Doing this manually would take days to maybe 2 weeks, will upload finished documents and mind map once its finished. Thank you so much @Red_Xiao_ -- you build a beast!
A. Will tech haters ever learn? B. If you keep saying everything is doomed, eventually you'll be right? C. Both Today and 1997. PS. Love the spin from the p(1) people. https://t.co/6Qp7mNByzd


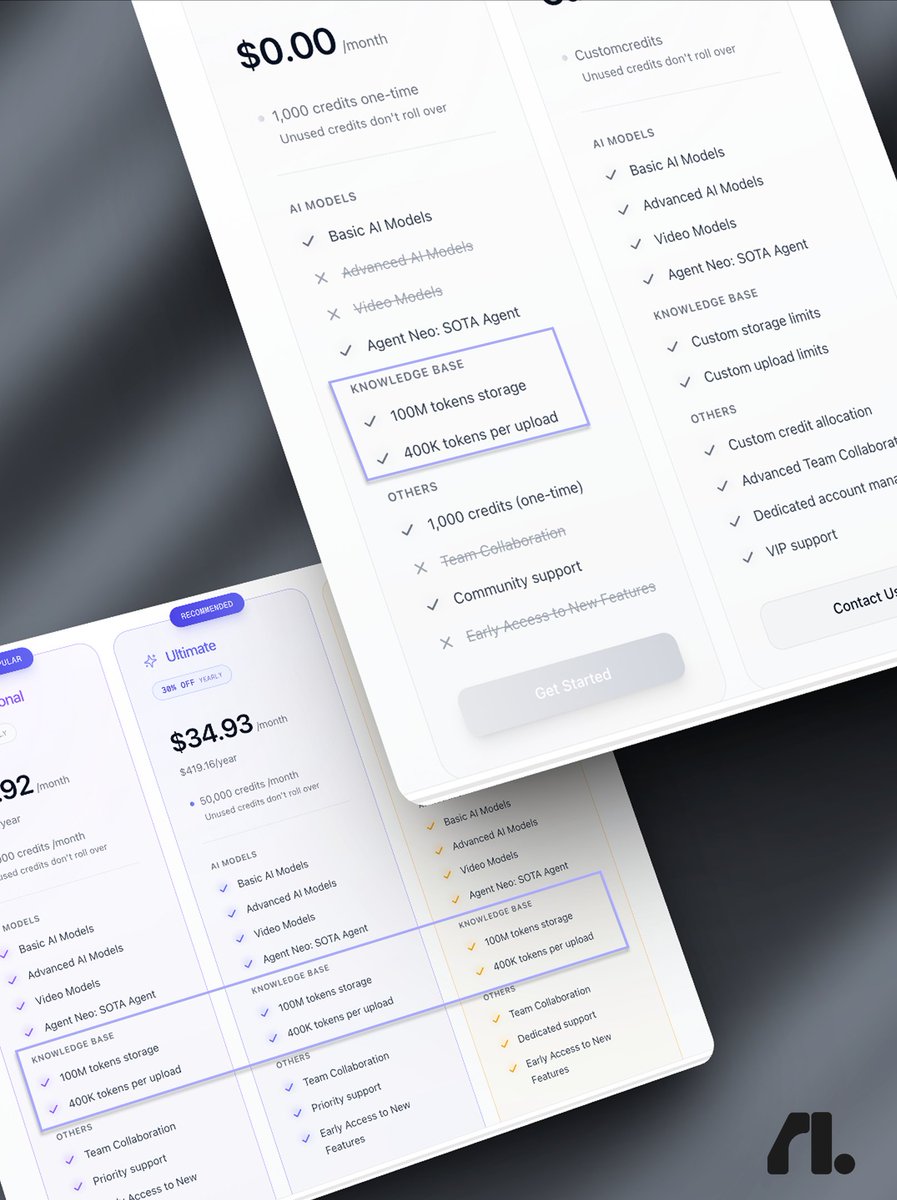
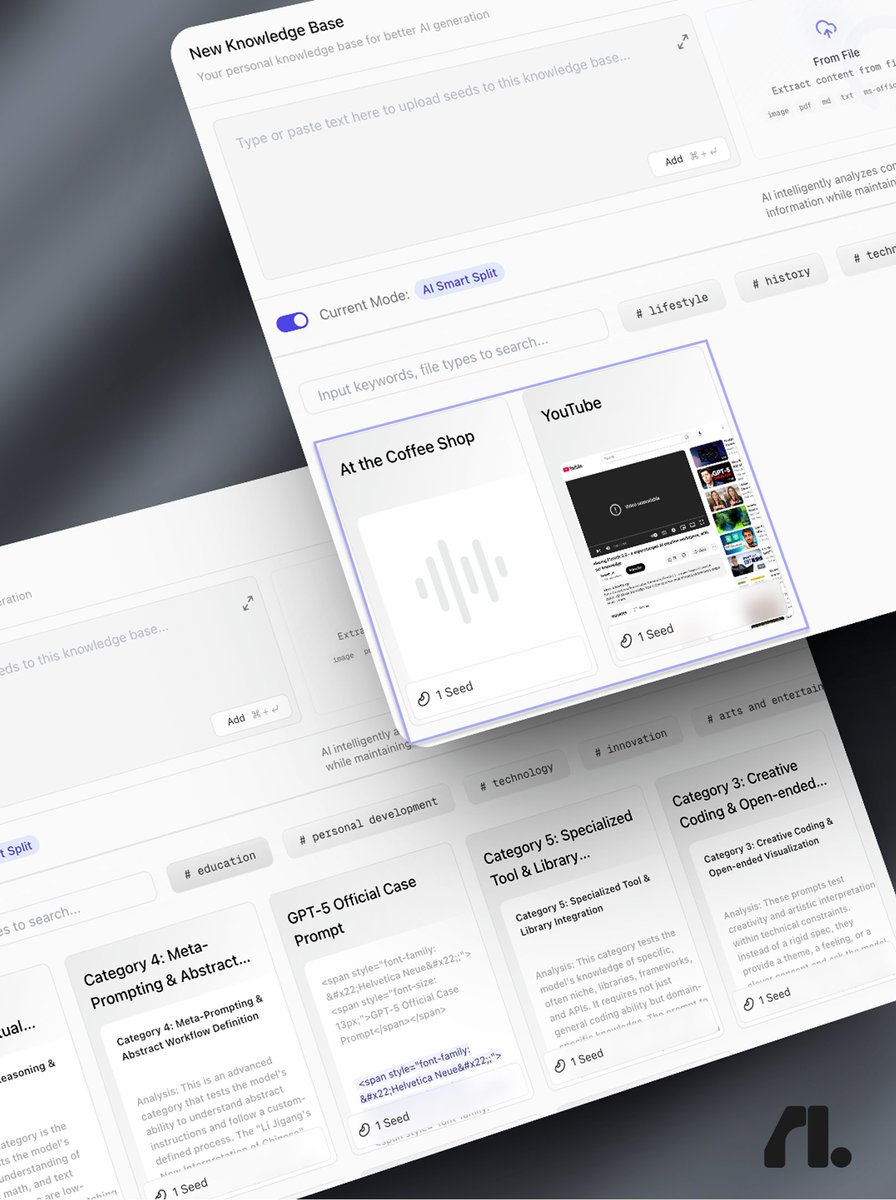
your second brain just leveled up. major upgrade to flowith knowledge garden: → 100m tokens of storage. → 100mb per file. 20 uploads at once. → audio, video & youtube link parsing. free for everyone. for now.
ToonComposer Streamlining Cartoon Production with Generative Post-Keyframing https://t.co/IuZzPSGYdQ
discuss with author: https://t.co/UNPCXzGITN

UI-Venus Technical Report Building High-performance UI Agents with RFT https://t.co/AXMffBxHNf

discuss with author: https://t.co/veXnImabAT

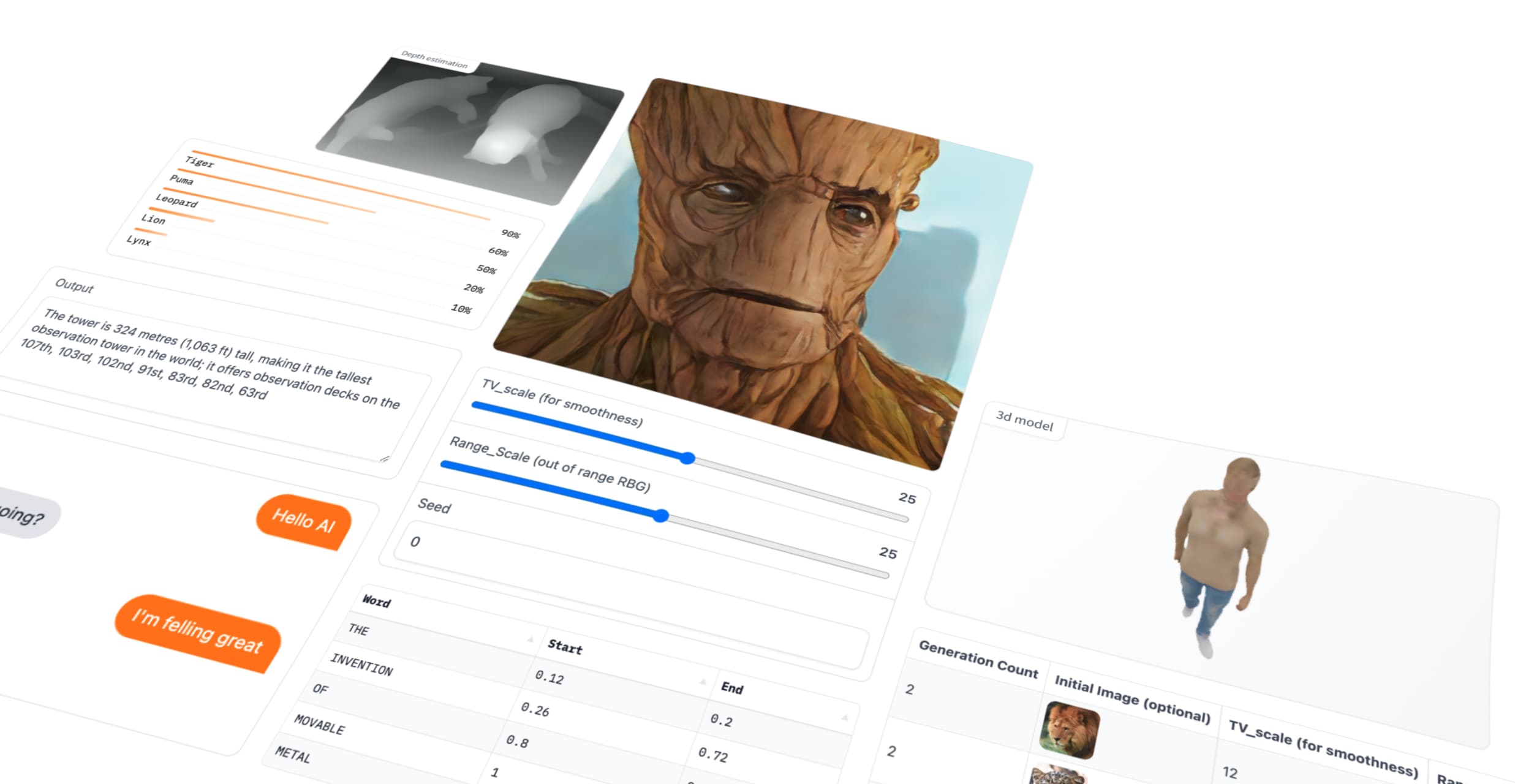
⚡️Quickly build demos like this using @Gradio & FastRTC ⚡️ Demo: https://t.co/1YXCRypWt9 Guide: https://t.co/hEKpbkNBVL https://t.co/a8hpy6hQAU

⚡️Quickly build demos like this using @Gradio & FastRTC ⚡️ Demo: https://t.co/1YXCRypWt9 Guide: https://t.co/hEKpbkNBVL https://t.co/a8hpy6hQAU

Grok 4 one shots building a gemma-3-270m chatbot with transformers.js one click deploy in anycoder https://t.co/zciwWazuEF
app: https://t.co/esPDyHE1YC

Puppeteer Rig and Animate Your 3D Models https://t.co/yD16hq6WY0
discuss with author: https://t.co/37zFWsBEgV

TexVerse A Universe of 3D Objects with High-Resolution Textures https://t.co/Zx2PTRBGZo

discuss with author: https://t.co/xnaOCKEMbq

If you haven't already noticed, our @Gradio Audio template in our HF Space got a new addition💬. Now with @boson_ai 's Higgs Audio v2 integration, a text-to-speech model, right under your finger tip. Enjoy creating contents!!!! 🥳 https://t.co/5ayKm1XNZA
STream3R Scalable Sequential 3D Reconstruction with Causal Transformer https://t.co/I94tVcGzzr

discuss with author: https://t.co/6ULkfOApgZ
