Your curated collection of saved posts and media
Here's how it looks like when running inference on various resolution with ONNXRuntime. 1920x1080 pixels https://t.co/j4mTMId6jE
1280x720 pixels https://t.co/3t2E6fWWQW
848x480 pixels https://t.co/8oHOef8f5V
640x480 pixels https://t.co/6ZiDEGOs2T
320x240 pixels https://t.co/wX0c0u34ZO
Here's a visualization of running the pretrained DEIM-X model on a video https://t.co/ys2bflcrhV
You can also launch a gradio interface to test the inference at variable image sizes. https://t.co/d7QRzkUV6C
I hope this is helpful. DEIMKit Repo - https://t.co/85B8girTc1 Disclaimer - I'm not affiliated with the original DEIM authors. I just found the model interesting and wanted to try it out. Cite the DEIM authors in your works.

would definitely buy an iPhone 17 Chunk https://t.co/hkg1hUTxLb

More details: https://t.co/bYAvkyVye7

@ashishgoel Congratulations Agastya and Ashish!!! Huge achievement!! Add it to the IOI medal this son is a natural Olympian. https://t.co/BihwNjMjCe

@Farmz4Rachel lol like everything but this was in reference to the n**** salute. Fuck that. https://t.co/0p8Fmf90ub

Writer Julia Doubleday (@juliadoubleday) writes on our blog about her struggles with chronic illnesses caused by COVID. Long COVID has curtailed her physical activities but she's fighting for a normal life. #COVID #COVID19 #COVIDIsntOver https://t.co/StmqzxvKo9

Looking for your next AI Engineering Role? Aa bunch of VC-backed startups are hiring founding engineers, in ai and backend systems. Don't miss out on some great opportunities and your next big challenge Apply now! https://t.co/1wqJdsRLpS

@FidelEverywhere @Mattel https://t.co/4zmR0yYZuA

@TheComfyEnjoyer @Mattel https://t.co/qOSk9iks1R

We've heard the community! 📣📣📣 Following the open-source release of our Hunyuan 3D World Model 1.0, we're excited to introduce the new 1.0-Lite version, optimized for consumer-grade GPUs! This is the first open-source, explorable world generation model compatible with CG pipelines, now more accessible than ever. Key Technical Optimizations: 🔹Dynamic FP8 Quantization: We’ve cut VRAM requirements by 35%—from 26GB to under 17GB—making it easy to run on consumer GPUs without compromising performance. 🔹SageAttention Quantization: Our method quantizes the Q, K, and V matrices in the Transformer to INT8, combined with dynamic smoothing and hardware optimizations, to achieve an inference speedup of over 3x with less than 1% precision loss. 🔹Cache Algorithm Acceleration: By optimizing redundant time steps, we've significantly improved inference efficiency for a smoother user experience. Now, developers can run a complex world model without the need for expensive, high-end hardware. Try it now: https://t.co/swscD5KGu2 Github: https://t.co/vKq8ykY4Hu Hugging Face: https://t.co/StC2E9kOmE Technical Report: https://t.co/JmqbQ4iq9e


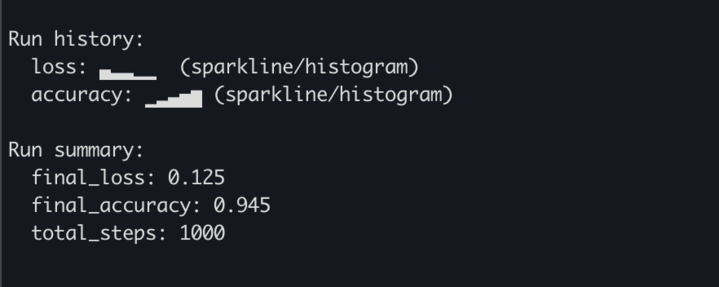
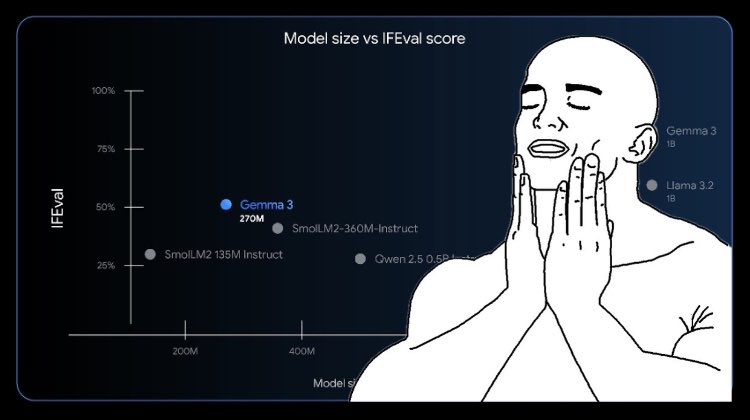
Google just released their smallest Gemma model ever: Gemma 3 270M! 🤯 🤏 Highly compact & efficient 🤖 Strong instruction-following capabilities 🔧 Perfect candidate for fine-tuning It's so tiny that it can even run 100% locally in your browser with Transformers.js! 🤗
Finally done with deploy my upscaling model on @huggingface. > implementing Multi-Recurrent Branches from scratch. > currently upscaling with a PSNR of 34.2 db , will be improving it. hf deployment: https://t.co/TuGtraHPE5 https://t.co/Dvyl3XRSSs

Gemma 3 270M joins the family. ⮕ More smol models, please. https://t.co/KmDOSNaP1L
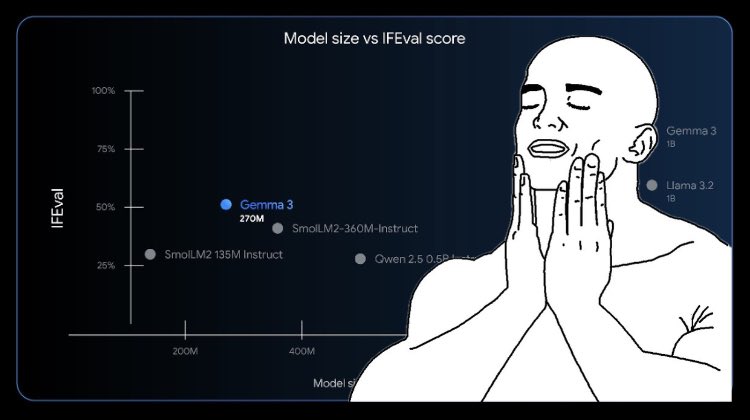
Gemma 3 270M joins the family. ⮕ More smol models, please. https://t.co/KmDOSNaP1L
On @huggingface Hub! https://t.co/ejNBnrE4FM
🌟We are excited to release TexVerse — a large-scale 3D dataset with high-res textures! TexVerse contains 858K 3D models (158K with PBR materials), totaling 1.6M high-res instances. Feel free to check it out. 📄Paper: https://t.co/WDuLt5mVJH 📷GitHub: https://t.co/B9xFTZCnaj ht

On @huggingface Hub! https://t.co/ejNBnrE4FM

We didn’t just build Mellum for us. We open-sourced it for everyone. Props to @huggingface for helping us get it out there 👌 Find out more about Mellum here: https://t.co/Cf7KLihPad https://t.co/mMQcz55lpc

We have released our LFM2-350M based TTS model as open source 🚀 We have also released many different FT models. GPU Platform: @hyperbolic_labs Data: Emilia + Emilia Yodas(EN) LLM Model: LFM2-350M @LiquidAI_ Disk and Space: @huggingface I'm very happy to have released this model as open source. Many thanks to @VyvoSmartChain #opensource #speech #tts #huggingface #lfm #gpu
wait, did google just dropped the smallest VLM/ LLM out there??? https://t.co/610PuHWuuy

wait, did google just dropped the smallest VLM/ LLM out there??? https://t.co/610PuHWuuy

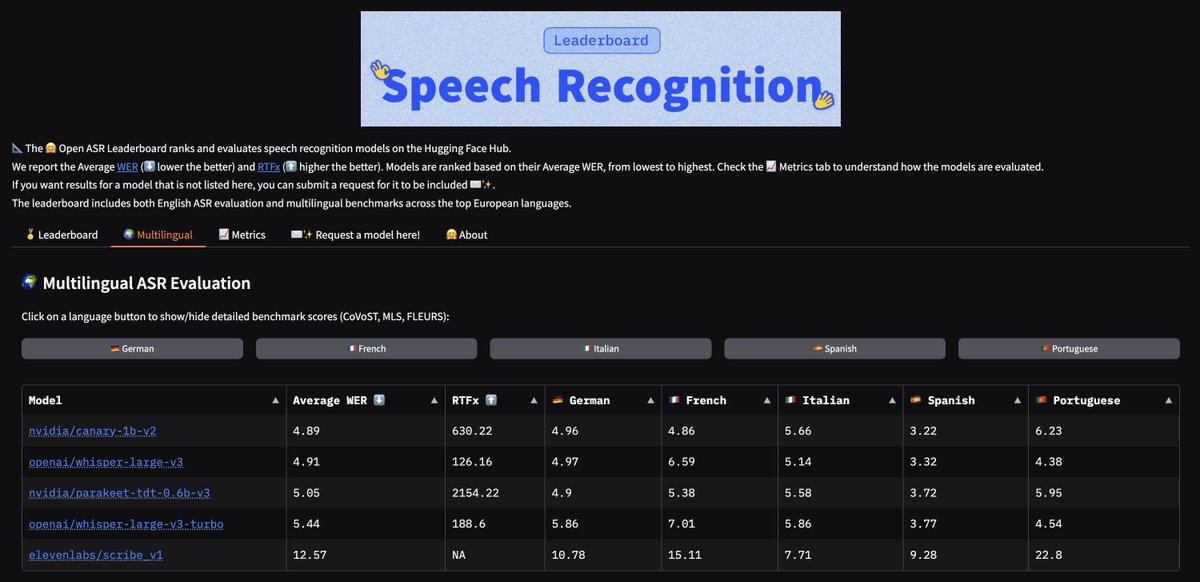
🚀 Big update: Open ASR goes multilingual! We’re kicking off with 🇩🇪🇫🇷🇮🇹🇪🇸🇵🇹 — German, French, Italian, Spanish & Portuguese. English ASR has reached a strong level of maturity, so we’re exploring new languages 🌍 More languages coming soon… Which one should we add next? https://t.co/VK7R4KuTht
Just saw GLM-4.5V is trending #2 on Hugging Face https://t.co/n1tm3zQjOx https://t.co/9nhCCSzhxn
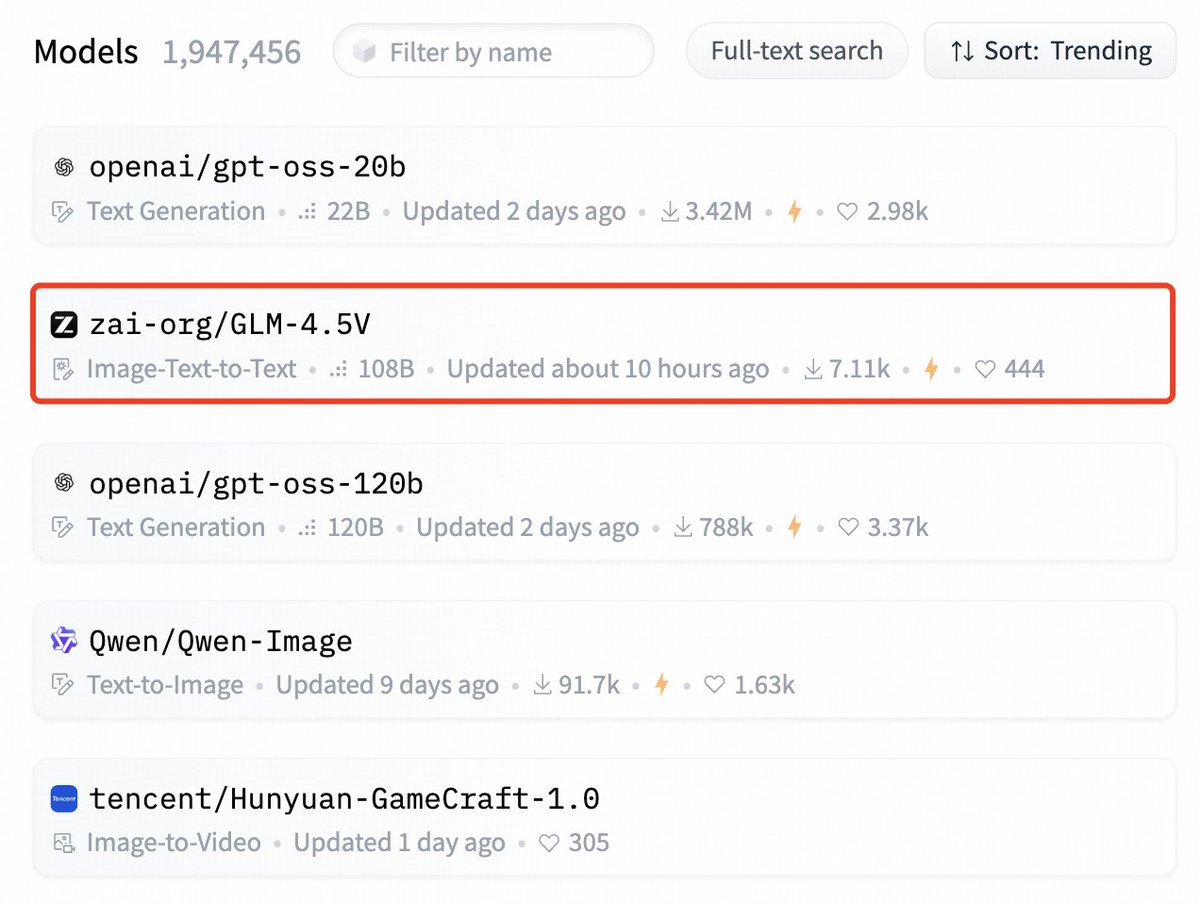

Just saw GLM-4.5V is trending #2 on Hugging Face https://t.co/n1tm3zQjOx https://t.co/9nhCCSzhxn

🚀 New in Weave: Content API Log any media your AI apps use and analyze it in traces. Inspect, evaluate, and compare images, audio, video, markdown, PDFs, and even HTML. Works across all of your AI agents and apps. One place for all of your multimodal debugging needs. https://t.co/uz9X7QnQM6
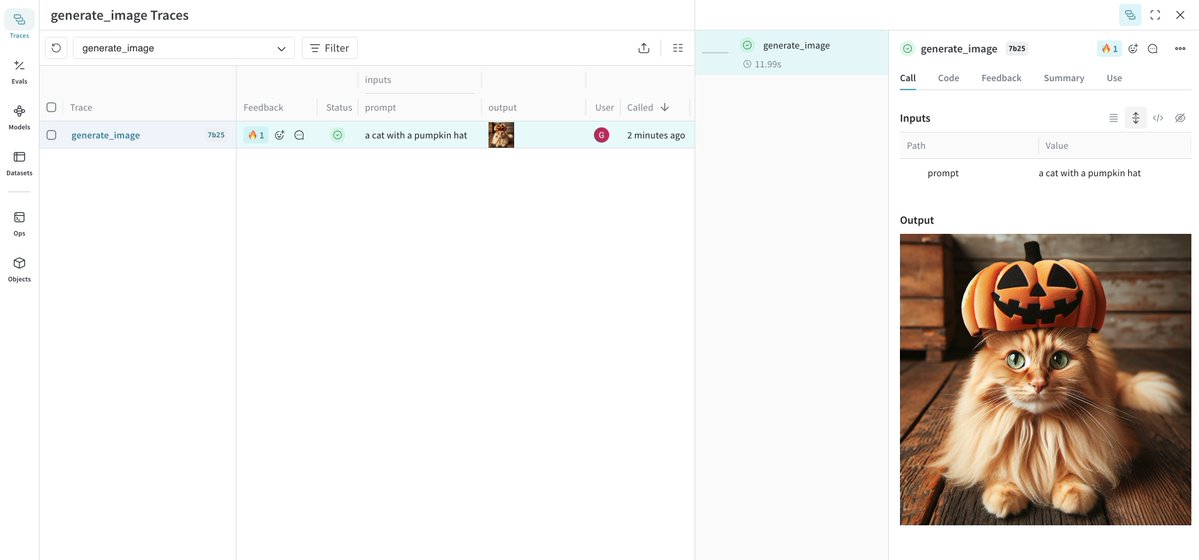
Example here: https://t.co/czaVlnFyH2