Your curated collection of saved posts and media
discuss with author: https://t.co/zDPcs9QJxC

4DNeX Feed-Forward 4D Generative Modeling Made Easy https://t.co/swhUDyRYRX
discuss with author: https://t.co/T9PqMsK72Y

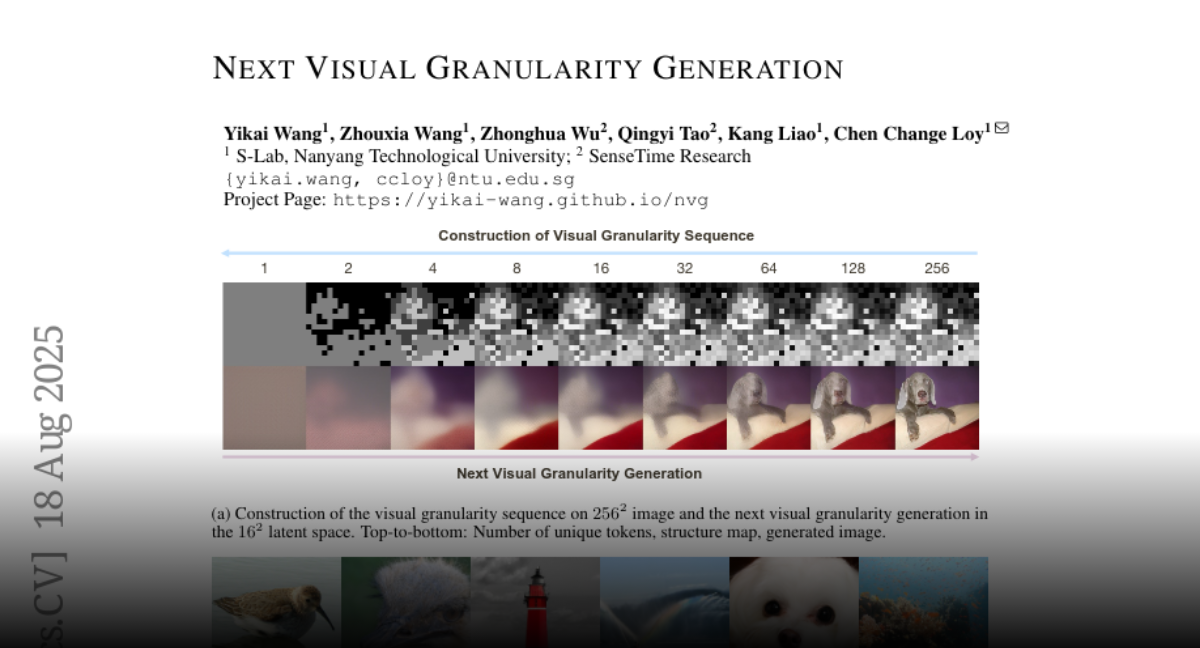
Next Visual Granularity Generation https://t.co/9oSg9smExP
discuss with author: https://t.co/U8ZOSh3R1u
Speed Always Wins A Survey on Efficient Architectures for Large Language Models https://t.co/xYZkNqycbS

discuss with author: https://t.co/kxVLY2eIw1

Has GPT-5 Achieved Spatial Intelligence? An Empirical Study https://t.co/6khkhnOmtr

discuss with author: https://t.co/cMXT7Hr971

https://t.co/IQMnfBc1Ll GLM 4.5 + @Alibaba_Qwen Qwen image edit is available in Anycoder for vibe coding use cases Stay tuned for this open source tool, with more features and faster updates 👀 https://t.co/eNNfsMcZRf
Reinforcement Learning with Rubric Anchors https://t.co/IjftvLY6Pl

discuss with author: https://t.co/F6RHCqyuMp

Again, no model card, no social announcement...it's so deepseek https://t.co/5gOhdyrWBG
Again, no model card, no social announcement...it's so deepseek https://t.co/5gOhdyrWBG
New from S-Lab, Nanyang Technological University & SenseTime Research: Next Visual Granularity Generation (NVG)! This novel framework progressively refines images from global layout to fine details, offering fine-grained control over generation. It outperforms the VAR series in FID scores!
At this point, it's just ANYTHING-to-Video. Higgsfield Draw-to-Video gives you a blank page to start off. You have TOTAL freedom over your result. Just drop ANY image, ANY text, or ANY product. The frame is YOURS. Retweet to get a full guide in DM. Check this out: https://t.co/FpUZlUjS0M
we are so back https://t.co/s2H1NSvss8
we are so back https://t.co/s2H1NSvss8
The ultimate guide for using gpt-oss with llama.cpp - Runs on any device - Supports NVIDIA, Apple, AMD and others - Support for efficient CPU offloading - The most lightweight inference stack today https://t.co/a6E3DssXmw

WE ARE SO BACK!!! https://t.co/tXWZJLajxi

WE ARE SO BACK!!! https://t.co/tXWZJLajxi

SAM 2 by @AIatMeta has finally been integrated into @huggingface Transformers! 🔥 It's a generalization of SAM 1 to video, allowing you to segment and track something you care about across a sequence of frames. SOTA performance, Apache 2.0 license https://t.co/uZjqmn3wsk
We’re releasing early pre-training checkpoints for OLMo-2-1B to help study how LLM capabilities emerge. They’re fine-grained snapshots intended for analysis, reproduction, and comparison. 🧵 https://t.co/MJNYnp3ZN5

DeepSeek-V3.1 https://t.co/TYZImBzLh0
DeepSeek-V3.1 https://t.co/TYZImBzLh0
Deepseek just released a new model! https://t.co/H7jH2wxEuK https://t.co/qI1dw2fKCe

Deepseek just released a new model! https://t.co/H7jH2wxEuK https://t.co/qI1dw2fKCe

It's out friends! Really great to see the state of things in image edits, video fidelity being pushed further and further, thanks to the community! This release also features new fine-tuning scripts for Qwen-Image and Flux Kontext (with support for image inputs). So, get busy making these models your own 🤗 We also improved the loading speed of Diffusers pipelines & models. This will become particularly evident when operating with large models like Wan, Qwen, etc. Release notes: https://t.co/jN6Z9lwoLZ


OmniPart: Part-Aware 3D Generation 🪛 Semantic decoupling 🏙️ Structural cohesion 🤗 Free and open source demo available on Hugging Face https://t.co/I8WAAJg2UB
Just crossed 20M monthly requests with @huggingface inference providers, our router for open models. @CerebrasSystems @novita_labs & @FireworksAI_HQ are growing the fastest! It's now powering the official open playground from @OpenAI & integrate with apps like @cline & @roo_code. Let's go!
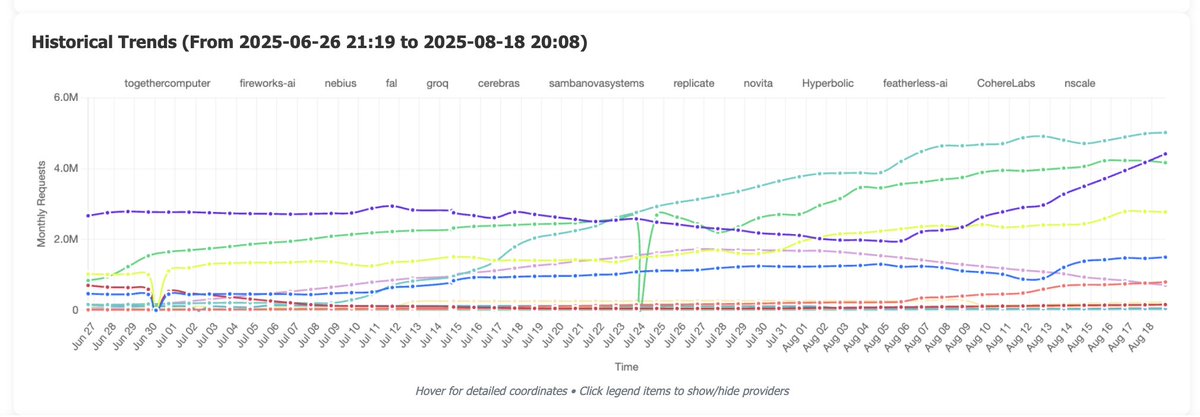
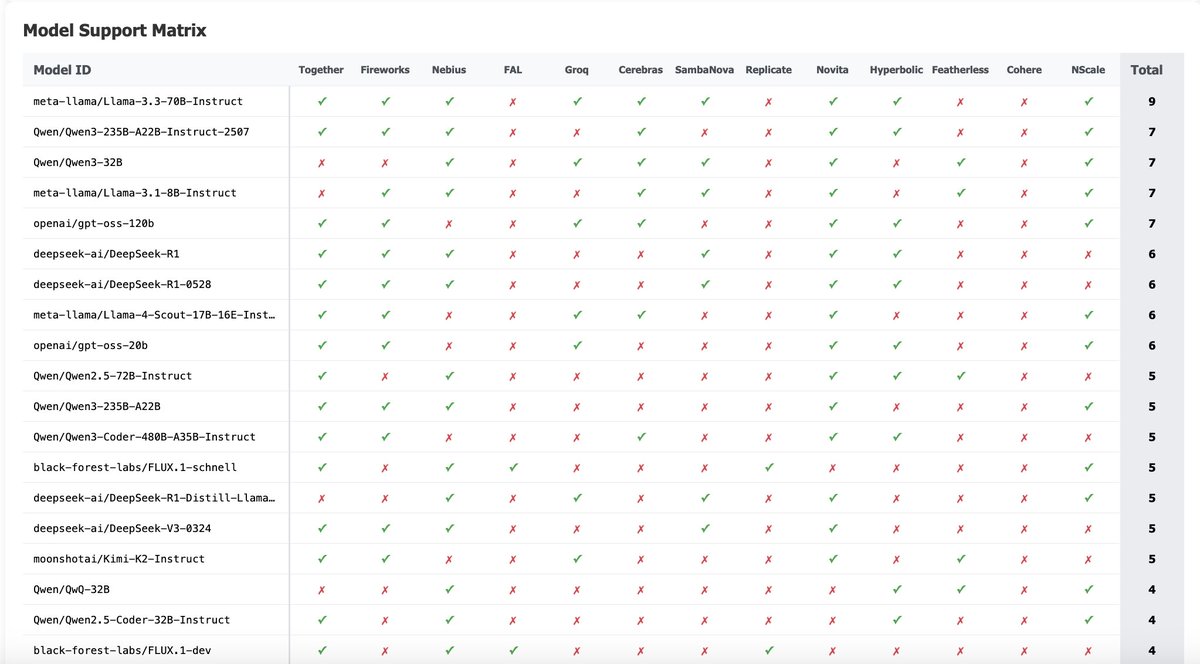
check out https://t.co/ZxAaGRdCyC for more https://t.co/4jtzp2akWl

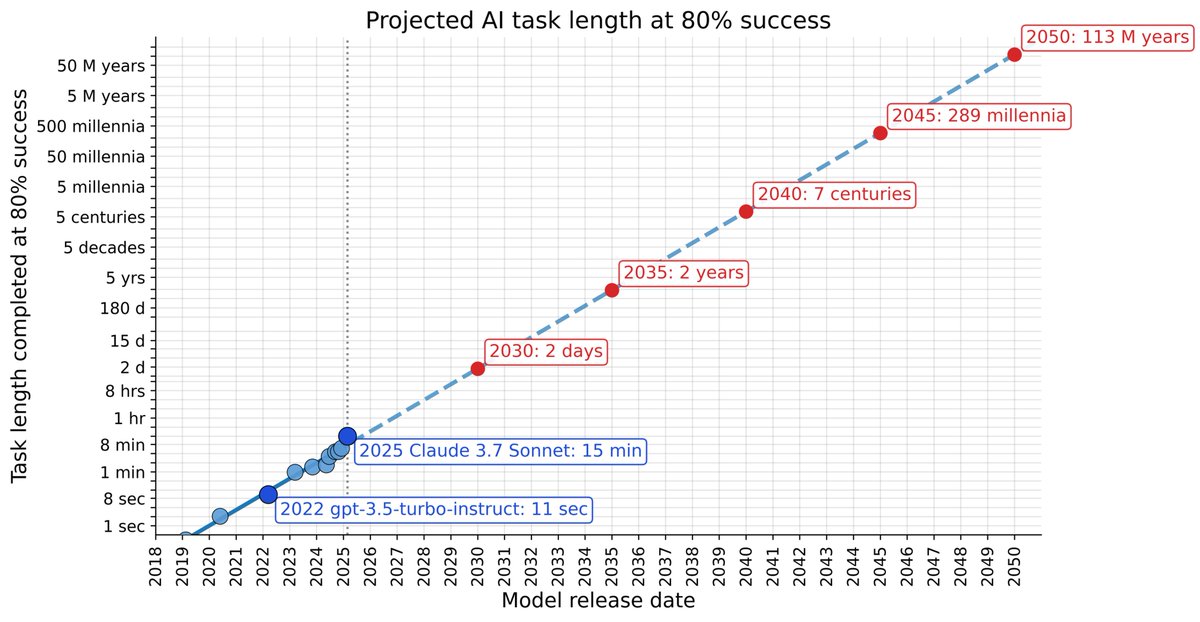
the task length an ai can reliably finish (conservatively) doubles every 7 months when i'm the age my mom was when she watched me graduate, ai will be able to do tasks that would take someone ~1000 millennia https://t.co/YTppMYNrX9