Your curated collection of saved posts and media
Thank you all for the overwhelming interest in our new Member of Technical Staff (RSI Lab) role. Just to clarify many questions asked, the role is not remote. We expect candidates to move to Tokyo, Japan. https://t.co/OUnbrC4BNc Please read the job description for more details! https://t.co/oHM6CMlvXl


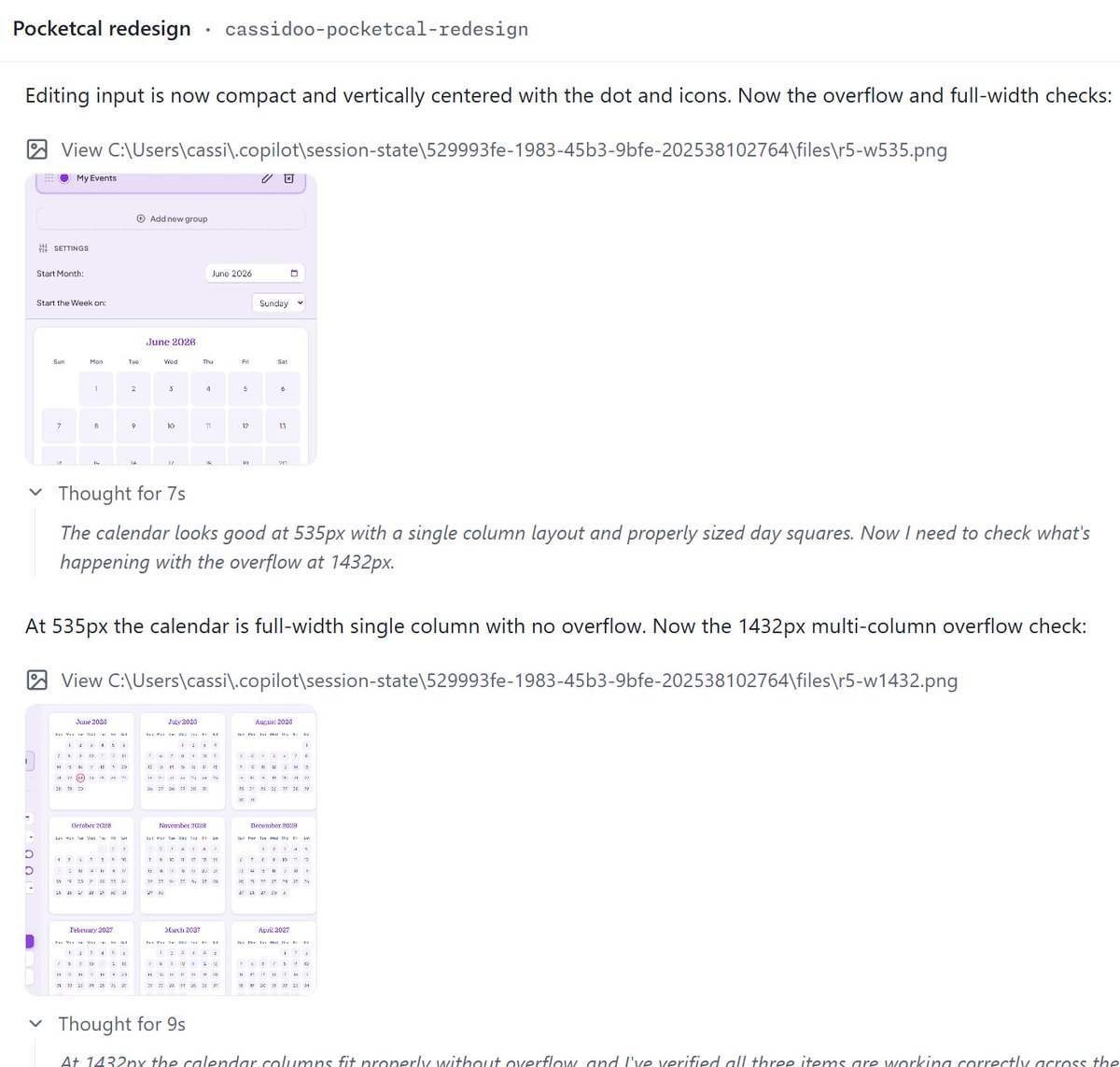
Something that's been pretty nice in the GitHub Copilot app is how helps me with pixel pushing responsive layouts. I've been working on a design update for my app PocketCal, and I used it to test screen sizes and it gave me screenshots based on all the ranges I asked for! https://t.co/h7P1rKHLP6
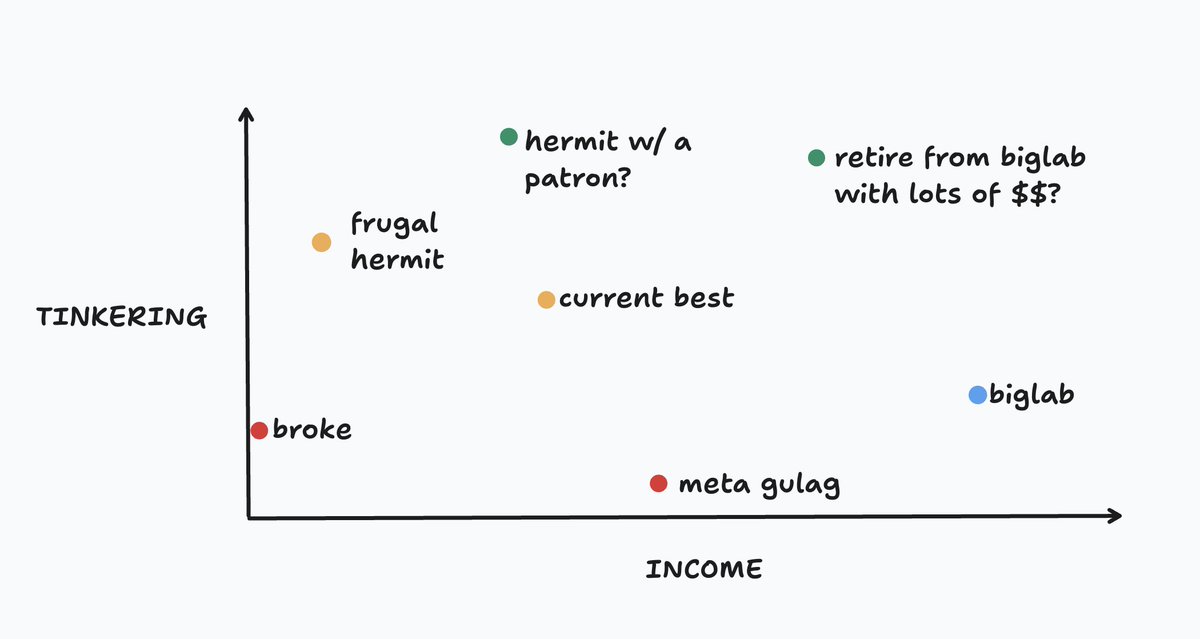
I am also open to other suggestions. One goal of this sabbatical is to explore the space of possibilities more. Work at answerai is the baseline to beat: $150k/yr and lots of exploration possible. Would love to hear from others on finding the freedom vs. work Pareto frontier :) https://t.co/uAXAuUX7WD
implicitly or explicitly, that’s got to be the hope of the big players. https://t.co/01rht8Vrgm
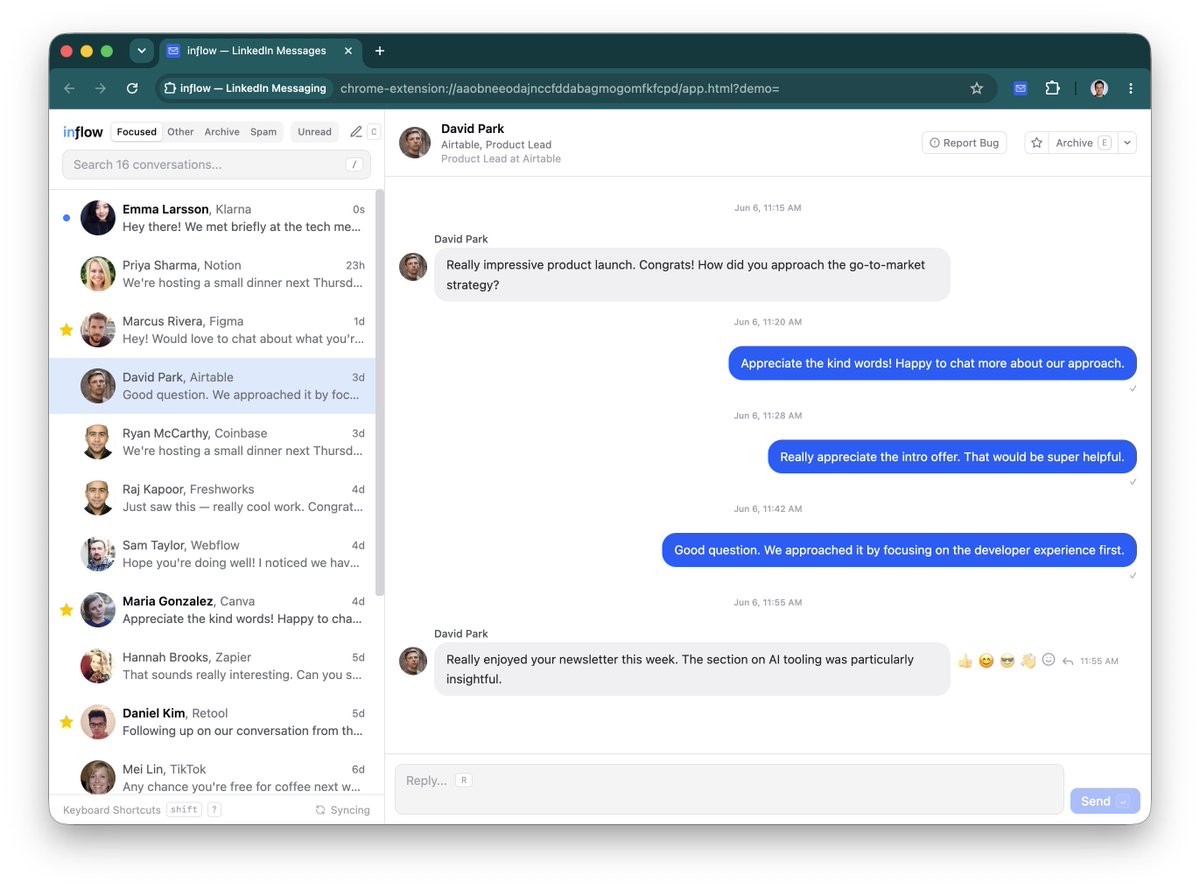
LinkedIn messaging is embarrassingly bad. So I built a faster, private, open-source inbox. ⌨️ Superhuman-style shortcuts ⚡ Instant search with local message sync 🌙 Dark mode, emoji, and more 🔒 Runs completely local as a Chrome extension Open source and free. Get it below 👇 https://t.co/ZgFFVAt6t6
https://t.co/J4YHJzccN8
LinkedIn messaging is embarrassingly bad. So I built a faster, private, open-source inbox. ⌨️ Superhuman-style shortcuts ⚡ Instant search with local message sync 🌙 Dark mode, emoji, and more 🔒 Runs completely local as a Chrome extension Open source and free. Get it below 👇 htt

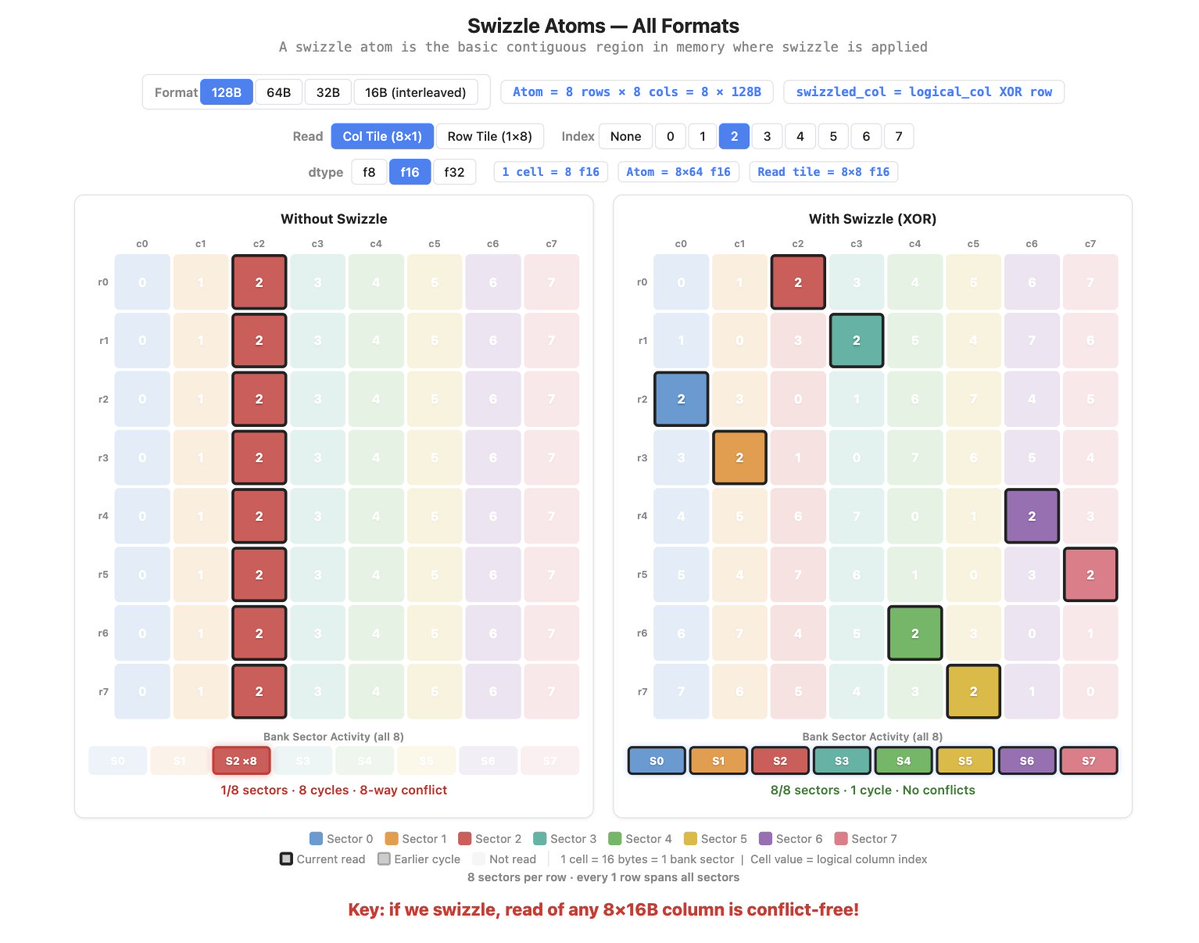
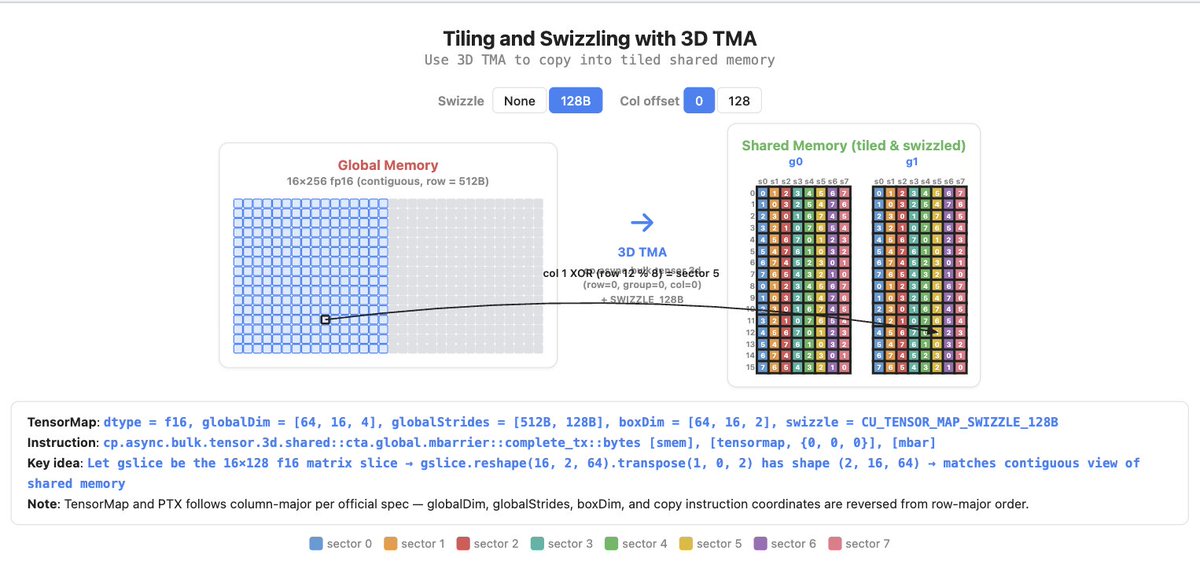
We taught a brand-new mini-series this year at @SCSatCMU on Modern GPU Programming for ML Systems, as part of the ML Systems course, touching on fun questions like what data layout swizzling is, how to use 3D TMA, and state-of-the-art Blackwell programming. We released a curated online book based on the materials: https://t.co/5ZJg2lySNO check it out
Get @glyphengineapp now on the App Store! You a find the perfect emoji or SF Symbol for your app, or generate a custom symbol yourself. Link below: https://t.co/O6j3jKQHQw
aespa x codex https://t.co/200N7H32hy
Post your best codex billboard

aespa x codex https://t.co/200N7H32hy

hard https://t.co/AdSfJ5fHxY
Post your best codex billboard

hard https://t.co/AdSfJ5fHxY

BREAKING: American Airlines has just confirmed it will begin rolling out Starlink across more than 500 narrowbody aircraft starting early next year. https://t.co/aTSx4to74H

Developers and builders! Everyone is shipping agents and nobody has a clean system for seeing what they actually do in production. @trylatitude just open sourced their monitoring platform with the see catch fix flow built in. You get clustered failure patterns, auto evals, and direct editor integration through MCP. Self hostable or free tier. No paywall on core features because it is MIT licensed. Try it: https://t.co/TvYYQ7DHIO
Most underrated data source in a company: your AI agent's conversations. Your agent talks to more customers than any employee, but the data it generates goes nowhere. @trylatitude changes that, see how: https://t.co/LLAa9tpnKE

https://t.co/vwe5FavqAG

Hermes Agent can now /learn from anything: feed it directories of any source material (code, API docs, manuals, PDFs, configs) and it distills a verifiable reusable skill https://t.co/oRznwCRF3E
@NousResearch Time to get to school, Hermes https://t.co/jMNM6OsUrt

NVIDIA highlights vLLM as one of the open source frameworks available for serving Step 3.7 Flash, StepFun's 198B-parameter multimodal Mixture-of-Experts model. NVIDIA's developer blog covers deployment, inference, and fine-tuning workflows for the model, which supports image and video inputs and a 256K context window. Read more: https://t.co/A6VftfrYyK

https://t.co/xH08P84miO
Post your best codex billboard

https://t.co/xH08P84miO

https://t.co/YdaVXwUC2w
Post your best codex billboard

https://t.co/YdaVXwUC2w

Vote for this Codex image https://t.co/5va6syaEvH

Vote for this Codex image https://t.co/5va6syaEvH

With the new Baidu OCR model and @MistralAI OCR 4, you might wonder which one to use. Luckily, I got you covered. Find all SOTA OCR models here: https://t.co/6GAxByELwJ https://t.co/l86bjmZLRB
3B total parameters & 500M activated, yet powerful enough to transcribe 40+ pages in one pass while keeping context intact. Meet Unlimited OCR!

We matched Mythos on public zero-days with CVEs using widely available & open-source derived models & can run it air-gapped if needed. All this with a small team out of Europe Berkeley study ranks us #1 globally in 3 of 8 categories The full evidence: https://t.co/NGVaWxFneq https://t.co/SqRCyHmhzi

This one is by far my favorite Ifykyk https://t.co/Vqv158EYfZ
Post your best codex billboard

This one is by far my favorite Ifykyk https://t.co/Vqv158EYfZ

Today we’ve expanded our AI glasses portfolio with 26 more styles and colors. Meta Glasses available today, starting at $299. https://t.co/wByxkxlR3Z


I believe everyone deserves their own Jarvis. Including you. So I built one that lives in your phone and does the work. Text it, or just call it like you'd call an assistant. Founders, executives, real estate teams already run their day through it. No app. No dashboard. No login. Try it now for free: https://t.co/XGZGOLWmBv

The new company brain. Context is the soul of your company, I learned today. Since I wrote a book, “Age of Context,” years ago I see that context is what we now call our private data. That data should be stored in a way to let AI agents and humans get more and more use out of it. This is precisely what @PromptQL does and here @tanmaigo goes deep on how it now is a company brain, or, rather, a wiki that everyone updates and uses.

@iamlukethedev @Claw3DCity @blevlabs I have exclusive access. But it builds https://t.co/kiuZ7QXLzb
