Your curated collection of saved posts and media
🎙️ VibeVoice Podcasting 🔥 🙌 Thanks to @broadfield_dev You Can Now Generate Long-form Multi-speaker AI Podcast with ZeroGPU on @huggingface https://t.co/UKr5JlGPcg

app: https://t.co/esPDyHE1YC check image to image to use in your apps https://t.co/ieYOnUI8Nv

MV-RAG Retrieval Augmented Multiview Diffusion https://t.co/7Z3RIPGy8M

discuss with author: https://t.co/4hZyFkb4kn

Hermes 4 Technical Report https://t.co/01n2jfk3D5

discuss with author: https://t.co/yXCD4uwFcT

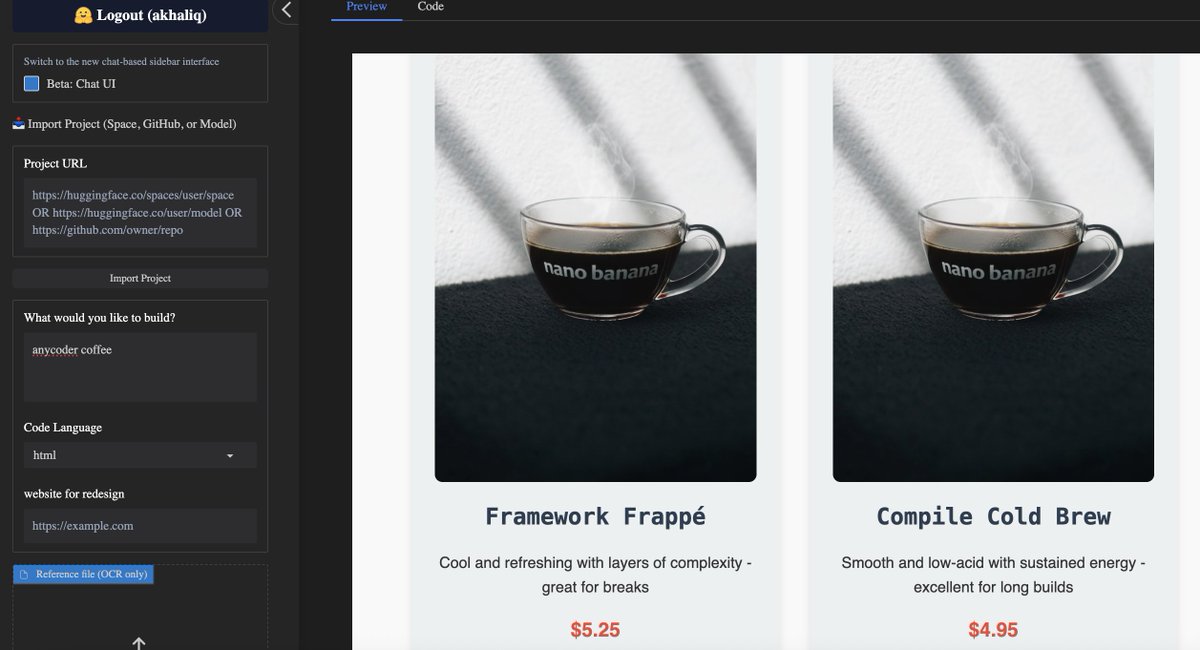
nano banana is now available in anycoder for vibe coding use cases https://t.co/U9AQF3kfcC
nano banana text to image generations in your vibe coded apps is now supported as well https://t.co/o8rkvWAfmz
nano banana is now available in anycoder for vibe coding use cases https://t.co/U9AQF3kfcC
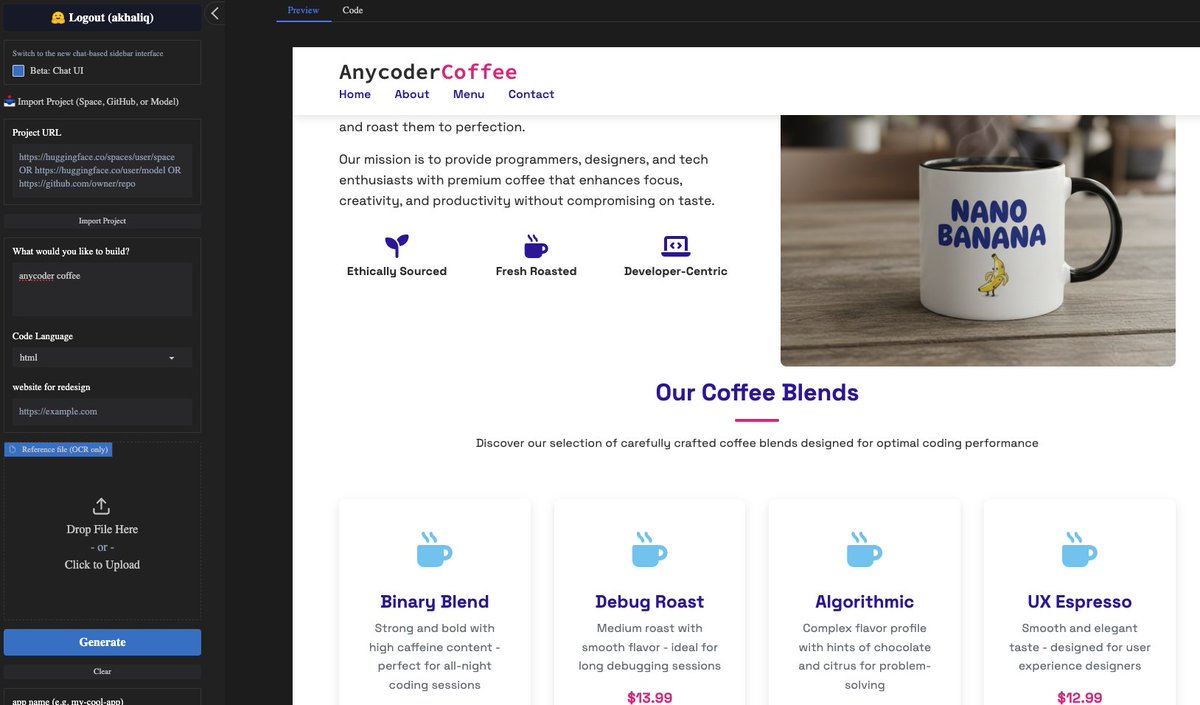
app: https://t.co/esPDyHDu94

Hugging Face Paper:https://t.co/d0ZhJe2EE8

Hugging Face Paper:https://t.co/d0ZhJe2EE8

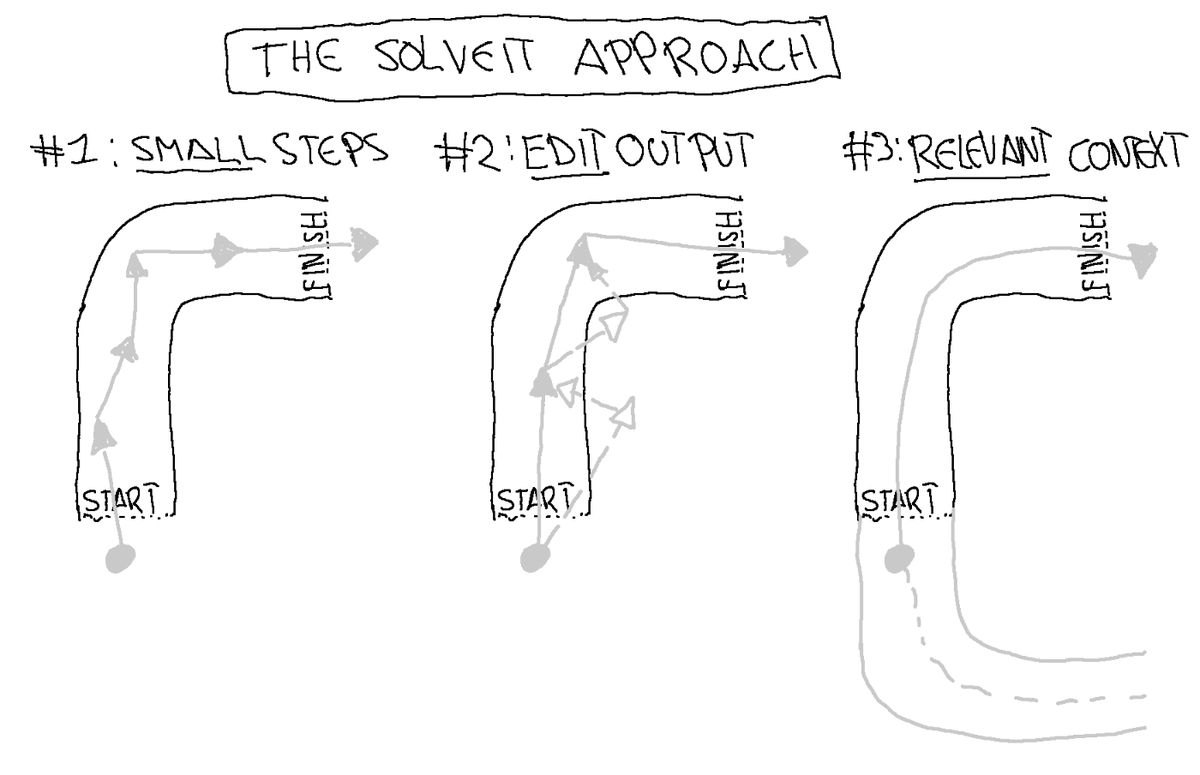
I took the Solveit course by @jeremyphoward and @johnowhitaker. Main insight: we can't expect one-shot AI solutions because we can't even ask the right question on the first try. It's no wonder most AI tools feel like a self-driving car hell-bent on driving off a cliff. 🧵 https://t.co/0Pdv6U8JdV
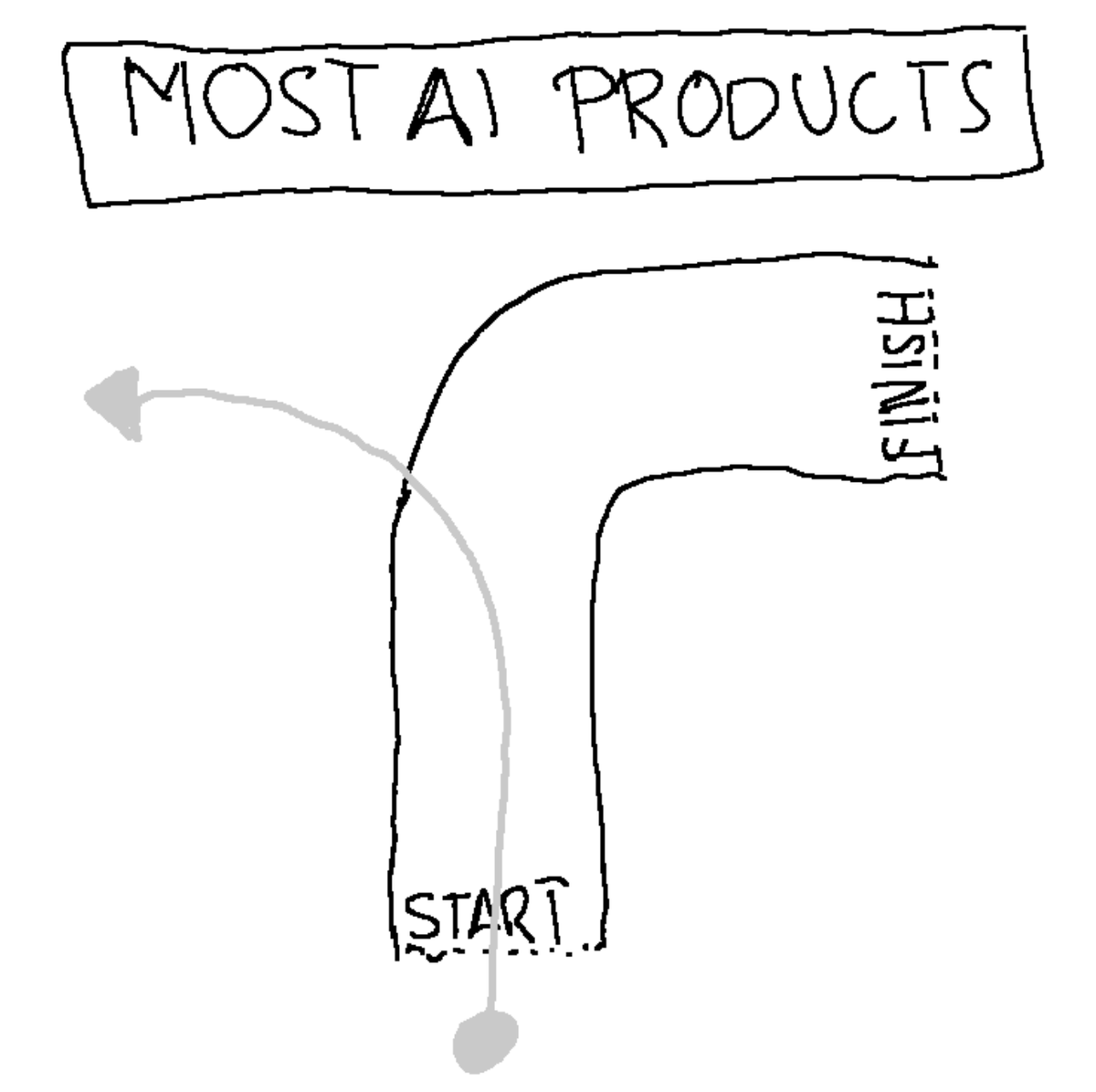
The fix? Work WITH LLM properties, not against them: • RLHF makes them over-eager → Work in small steps, ask clarifying questions • Autoregression causes drift → Edit AI responses, use examples to guide direction • Flawed training data → curate relevant context manually https://t.co/eOGN1PLvnZ
@steve2Seattle @SmileyGnome @iwasnevrhere_ @CommunityNotes Seems they actually worked pretty well though? https://t.co/kacXyzLfJv
first i thought scaling laws originated in OpenAI (2020) then i thought they came from Baidu (2017) now i am enlightened: Scaling Laws were first explored at Bell Labs (1993) https://t.co/CAZPgrxGCX


Kimi's founder, Zhilin Yang's interview is out. Again, you can let Kimi translate for you: ) lots of insights there. https://t.co/nCEb1Cyq5b Several takes: 1/ Base Model Focus: K2 aims to be a solid base model. We've found that high-quality data growth is slow, and multi-modal data doesn't significantly boost textual "IQ." So, we focus on maximizing every data token's value — token efficiency. 2/ Data Rephrasing: With 30T tokens, only a small portion is high-quality data (billions of tokens). We rephrase these to make them more efficient for the model, improving generalization. 3/ Agentic Ability: We aim to enhance generalization. The biggest challenge is making the model generalize well beyond specific tasks. RL improves this over supervised fine-tuning (SFT). 4/ AI-Native Training: We're exploring more AI-native ways to train models. If AI can do good alignment research, it'll generalize better, beyond single-task optimization. 5/ RL vs SFT: RL's generalization is better, as it learns from on-policy samples, but it has its limits. RL helps improve specific tasks, but it's hard to generalize to all scenarios without tailored tasks. 6/ Long Contexts: Context length is crucial, we need millions. The challenge is balancing model size and context length for optimal performance, as some architectures improve with long context but worsen with short ones.


maybe antibiotic resistance would have funding if we didn't prohibit investors from coming to our conferences https://t.co/x0RRAs8nOa

Follow https://t.co/fl3Mvguo1y to stay up to date. https://t.co/wcYqjR1mqB
The @xAI Grok 2.5 model, which was our best model last year, is now open source. Grok 3 will be made open source in about 6 months. https://t.co/TXM0wyJKOh

Follow https://t.co/fl3Mvguo1y to stay up to date. https://t.co/wcYqjR1mqB

hugging face is the new github https://t.co/yBo3I7ztEK
hugging face is the new github https://t.co/yBo3I7ztEK
So many multipliers! Great to see that Grok2 was trained using μP. https://t.co/mURbaZFkCw https://t.co/li7P9OJCr4


So many multipliers! Great to see that Grok2 was trained using μP. https://t.co/mURbaZFkCw https://t.co/li7P9OJCr4


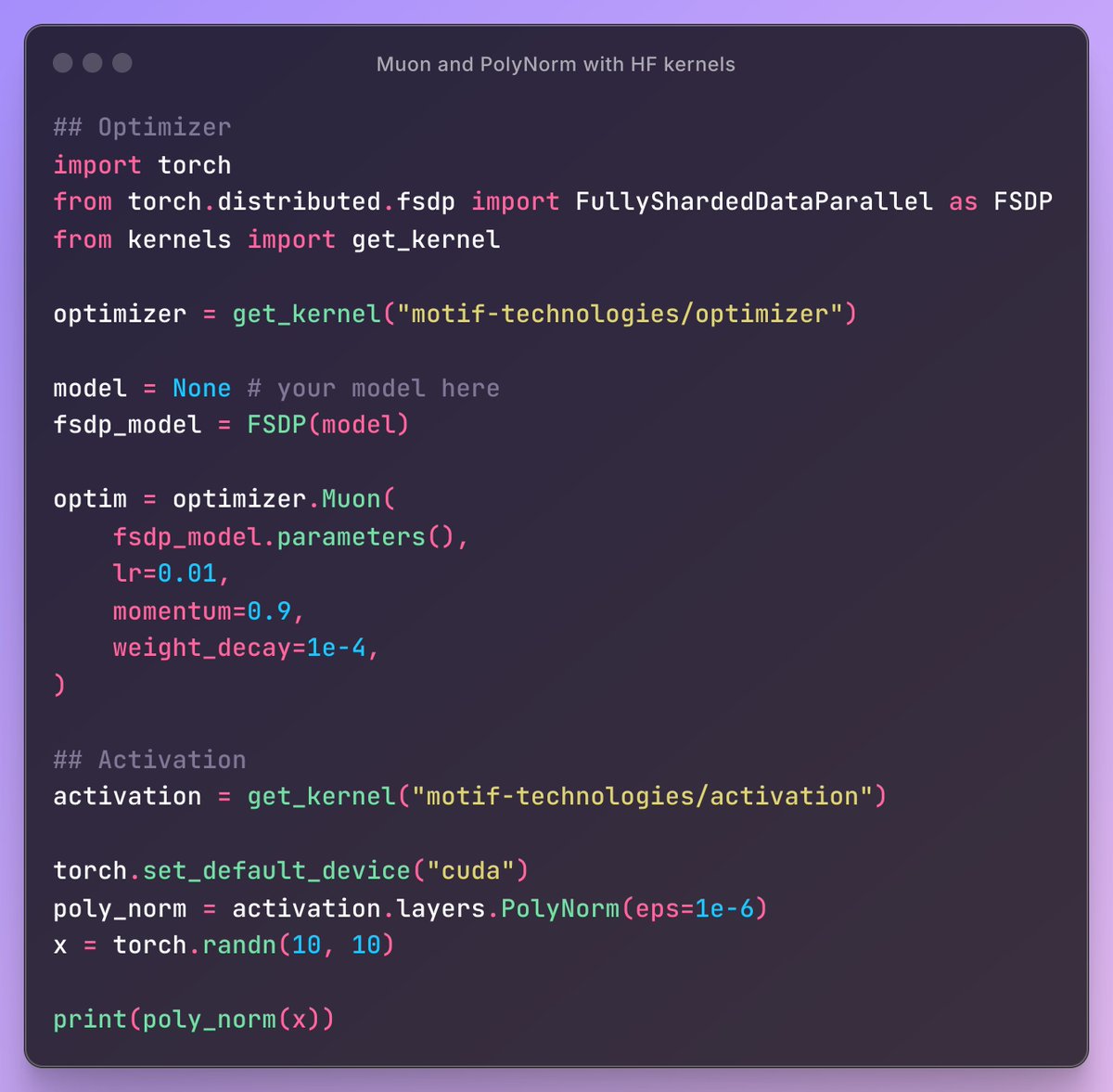
Wow, pretty cool that they also open sourced a FSDP2 compatible Muon and PolyNorm working with @huggingface kernels! https://t.co/Gqw7Hpj1v3
Motif 2.6B tech report is pretty insane, first time i see a model with differential attention and polynorm trained at scale! > It's trained on 2.5T of token, with a "data mixture schedule" to continuously adjust the mixture over training. > They use WSD with a "Simple moving ave
Hugging Face quietly dropped FREE courses with certification It cover everything from LLMs to diffusion models. Here are the best ones you should bookmark today 🧵👇 https://t.co/QvLywX0lZ5

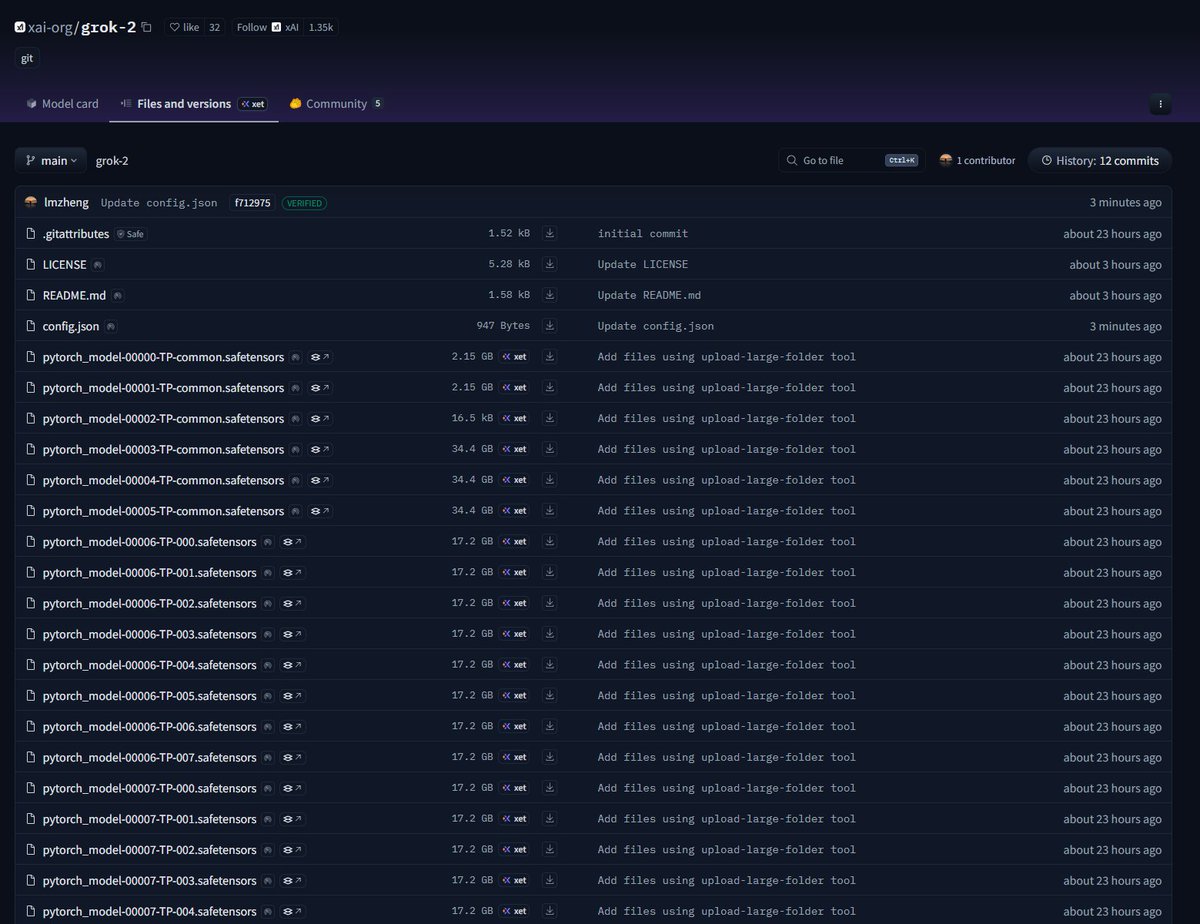
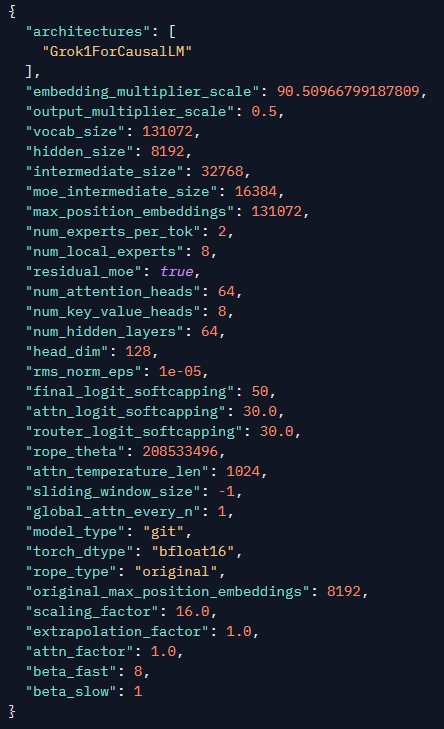
Grok-2 got open-sourced same arch as grok-1 https://t.co/eOdmj6zKaK https://t.co/KHb59ymyQ2
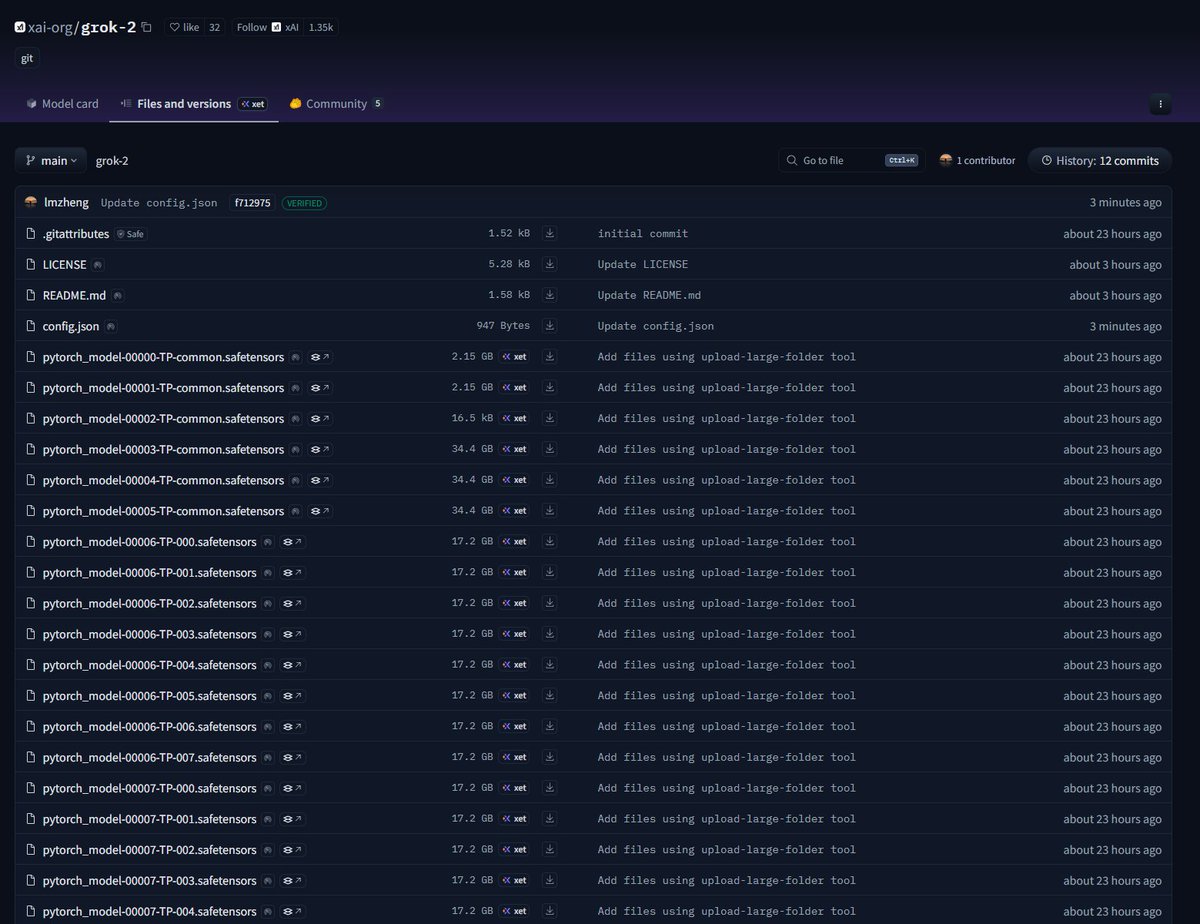
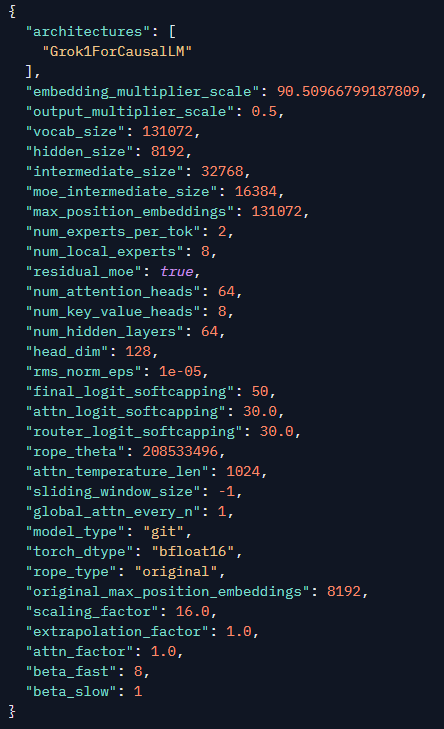
Grok-2 got open-sourced same arch as grok-1 https://t.co/eOdmj6zKaK https://t.co/KHb59ymyQ2
🤔A more aggressive INT4 model for DeepSeek-V3.1: https://t.co/mELIFdbpNP #intel #autoround #huggingface @deepseek_ai

🤔A more aggressive INT4 model for DeepSeek-V3.1: https://t.co/mELIFdbpNP #intel #autoround #huggingface @deepseek_ai

Microsoft just released VibeVoice - 1.5B SoTA Text to Speech model - MIT Licensed 🔥 > It can generate up 90 minutes of audio > Supports simultaneous generation of > 4 speakers > Streaming and larger 7B model in-coming > Capable of cross-lingual and singing synthesis Love the expressiveness and the emotion control on the model! Kudos to Microsoft 🤗
Nano Banana is now available on @huggingface Spaces for free for PRO users! 🤗 🤝🍌 https://t.co/rwJ7NOJ8Zd

Nano Banana is now available on @huggingface Spaces for free for PRO users! 🤗 🤝🍌 https://t.co/rwJ7NOJ8Zd
