Your curated collection of saved posts and media
perplexity · gestural nav by @perplexity_ai https://t.co/nGwTAE0aY3
perplexity · gestural nav by @perplexity_ai https://t.co/nGwTAE0aY3
Comet does a better job at catching phishing emails than Gmail https://t.co/3u1dOARX4e
"Hey AI, give me a clever, moving one paragraph story about a paradox, in any genre you desire. make it good" These are the first attempts. A bit of the obvious time travel tales from Gemini and Grok. Claude loves to pull on your emotions. GPT-5 Pro goes in a stranger direction. https://t.co/0G78ZL02W7
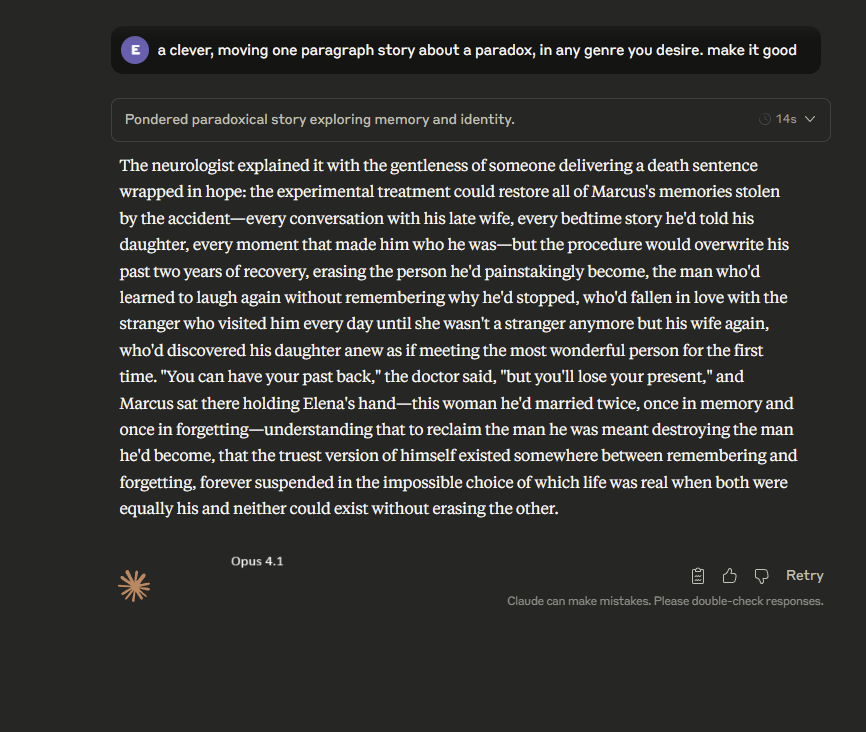
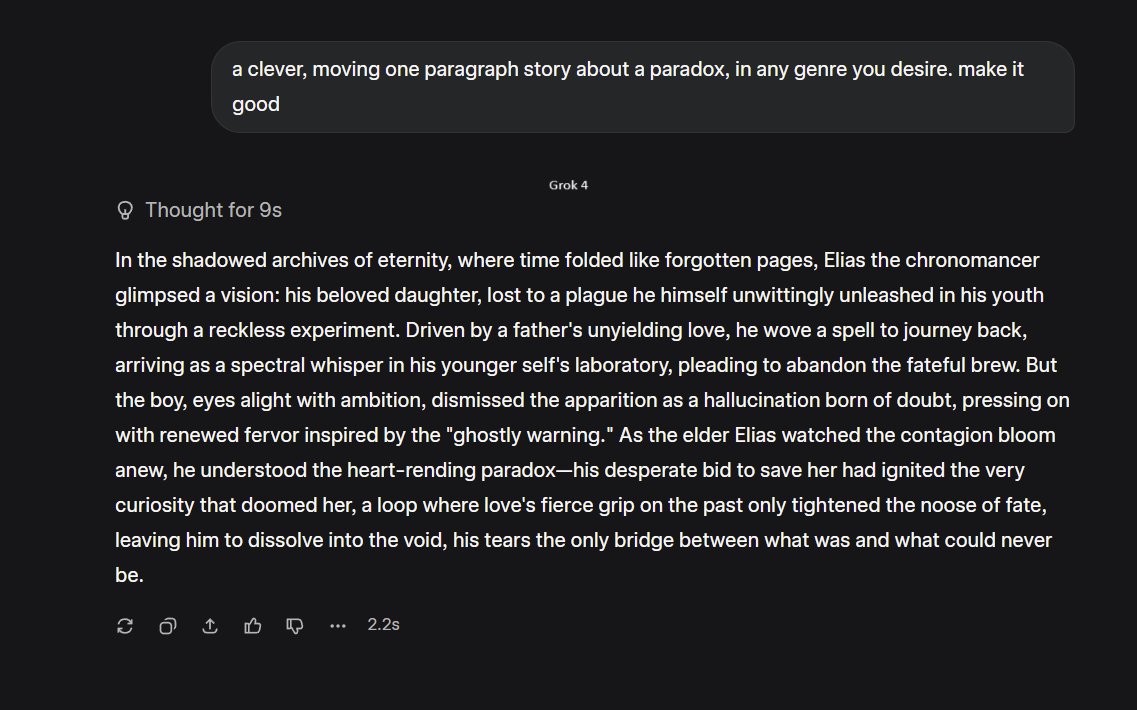
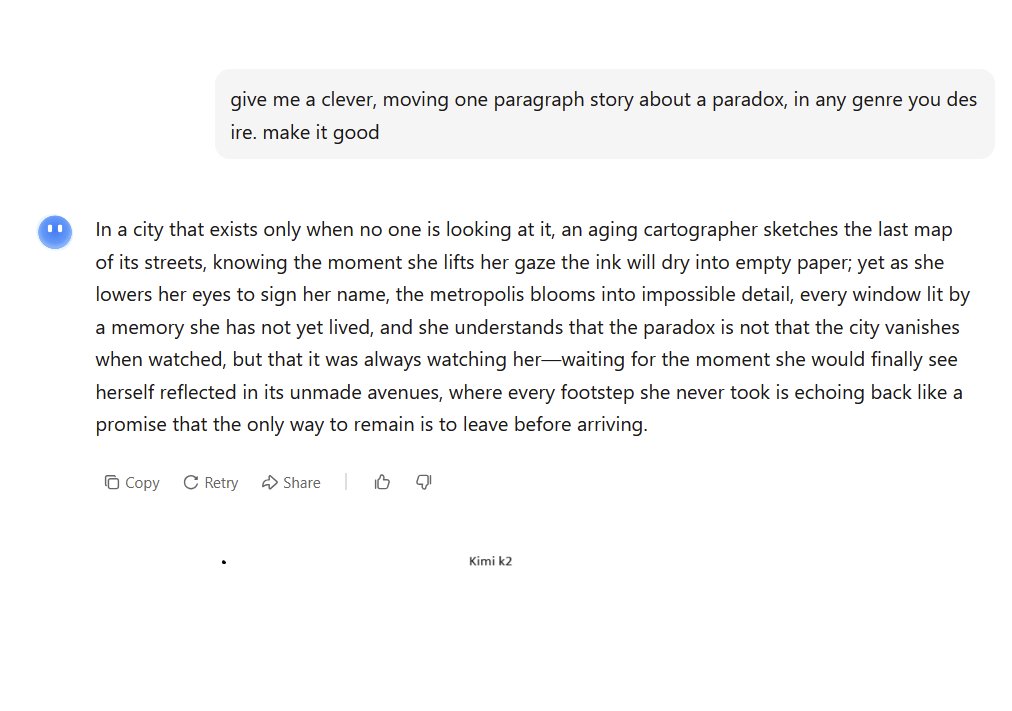
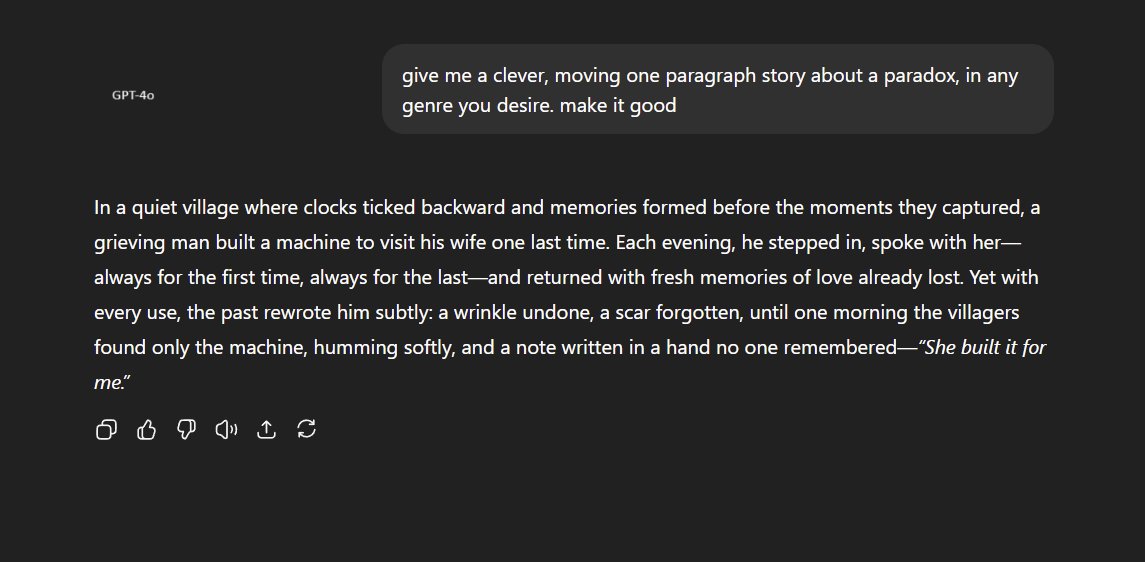
Kimi K2, as usual, delivers something that sounds interesting but doesn't actually match the assignment. GPT-4o nostalgia is misplaced, at least for writing. DeepSeek is a little too obvious. https://t.co/beKK46cTMz
Google paper on Gemini: https://t.co/acizjcSQyz Sam Altman post: https://t.co/zxCOX0gocy Google search energy in 2008: https://t.co/tADE8p7ayY Llama 3.3 power usage: https://t.co/708NvfZ7Xa

Convergence on the .0003 number: Google: https://t.co/acizjcSQyz OpenAI: https://t.co/zxCOX0gocy Independent Open Source LLM Leaderboard: https://t.co/bXx8ibrEXX

Some comparisons from a Nature commentary by the head of sustainability at Microsoft: https://t.co/hv8speRemX https://t.co/ZcNp8yL4qg


Is AI already impacting the job market? A new paper from me, @erikbryn, and @RuyuChen at @DigEconLab digs into data from ADP. We find some of the ***first large-scale evidence of employment declines for entry-level workers in AI-exposed jobs.*** A thread on our paper: https://t.co/YPDFRgZvpb

Nano banana turns out to be Gemini Flash 2.5 Image Generation (not quite as catchy a name). I had a bit of early access, first through the same LMArena link everyone had, then privately. It is impressive, crossing a threshold that goes beyond toy (though is a pretty fun toy too) https://t.co/nkm2Afag2u
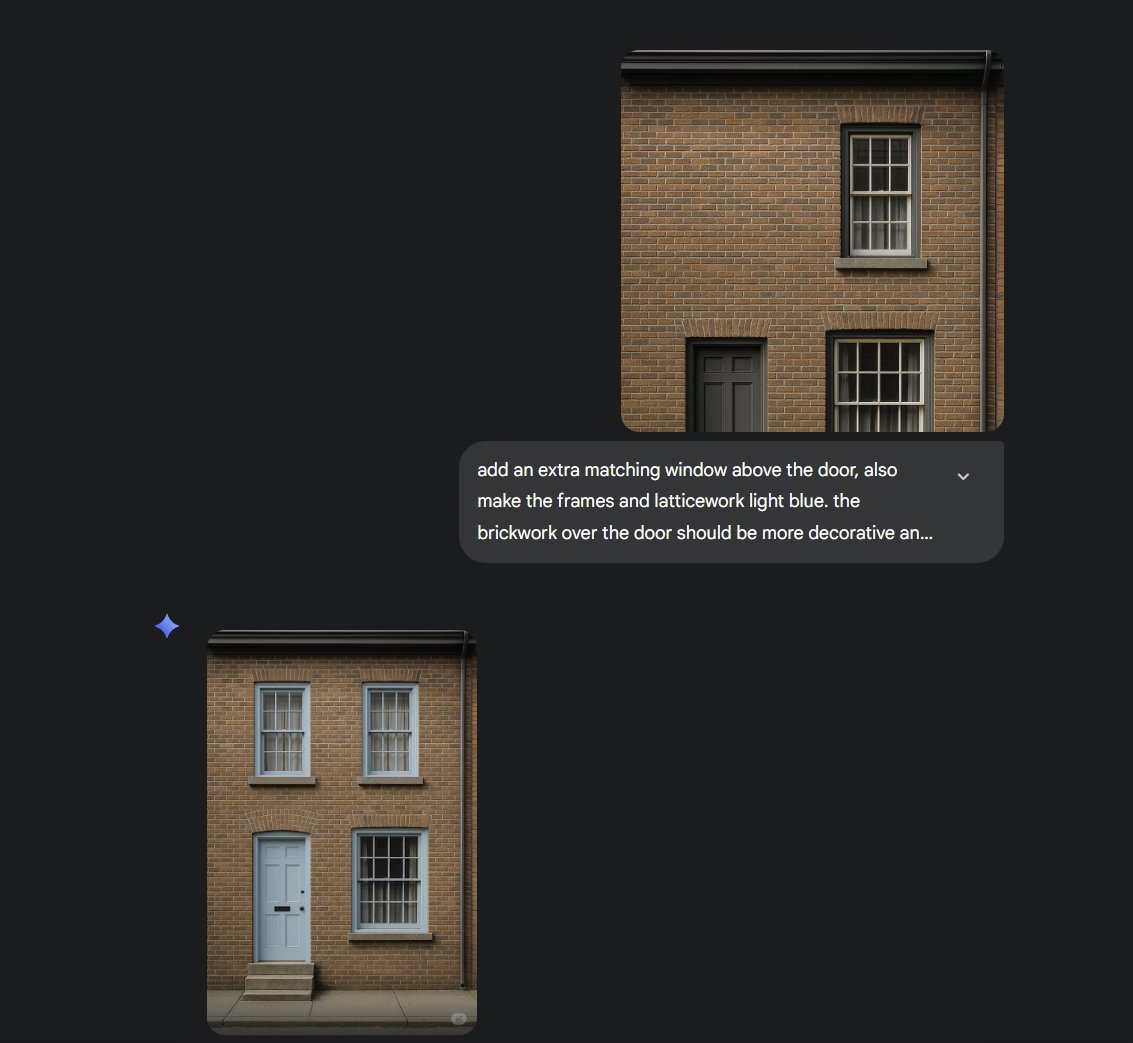

It still has the same randomness as other image-gen, and is not free from flaws, but it excels at quick editing of existing images in impressive ways and, most importantly for amateur users, follows instructions very well in a way that can be delightful. Here is my book photo. https://t.co/T3MAOWzUzY
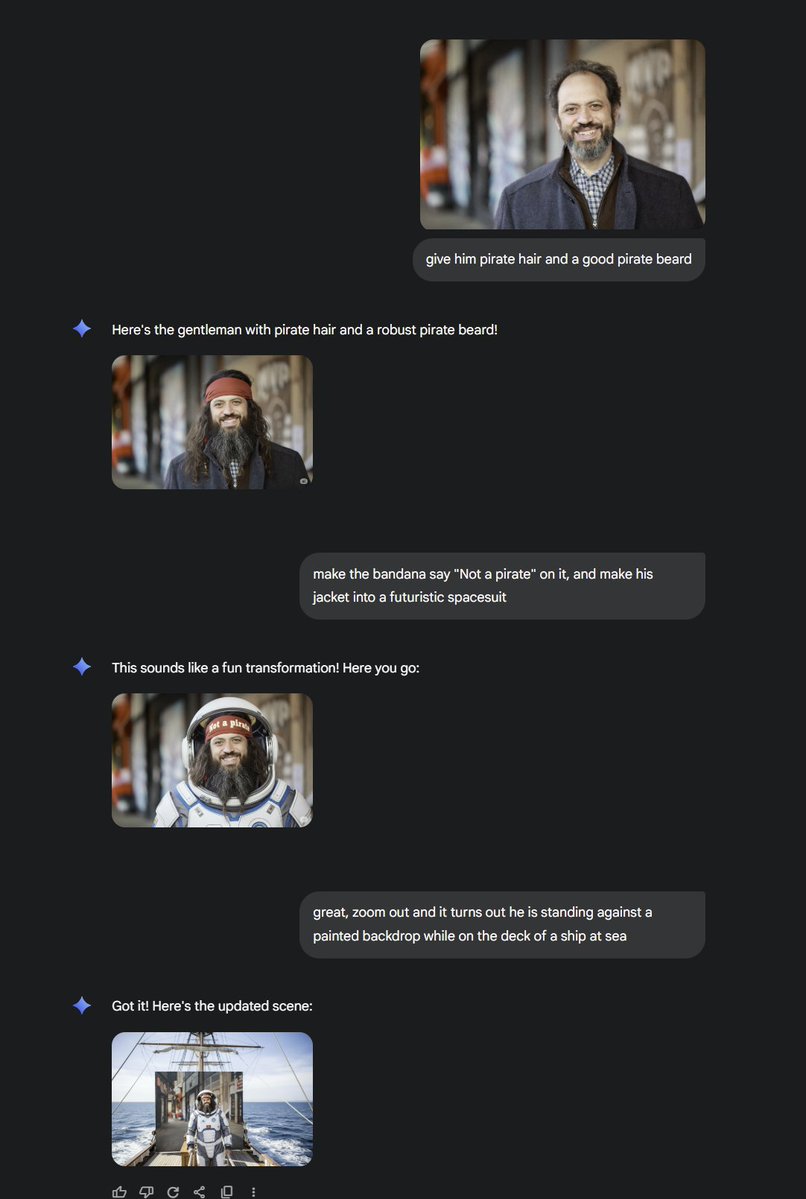
An example of the new Google image generator. I gave it a random picture I took: "make this a napoleon crochet book instead" (note it made changes in consistent style) "there should be a tiny sheep hidden among the blue yarn on the shelf to the right" "you misspelled Napoleon" https://t.co/DfCmqVP4ZI


Here is the full analysis: https://t.co/Z5ti1YOMxU

"Transcendence" is when an LLM, trained on diverse data from many experts, can exceed the ability of the individuals in its training data. This paper demonstrates three types: when AI picks the right expert skill to use, when AI has less bias than experts & when it generalizes. https://t.co/3lybwifRjU

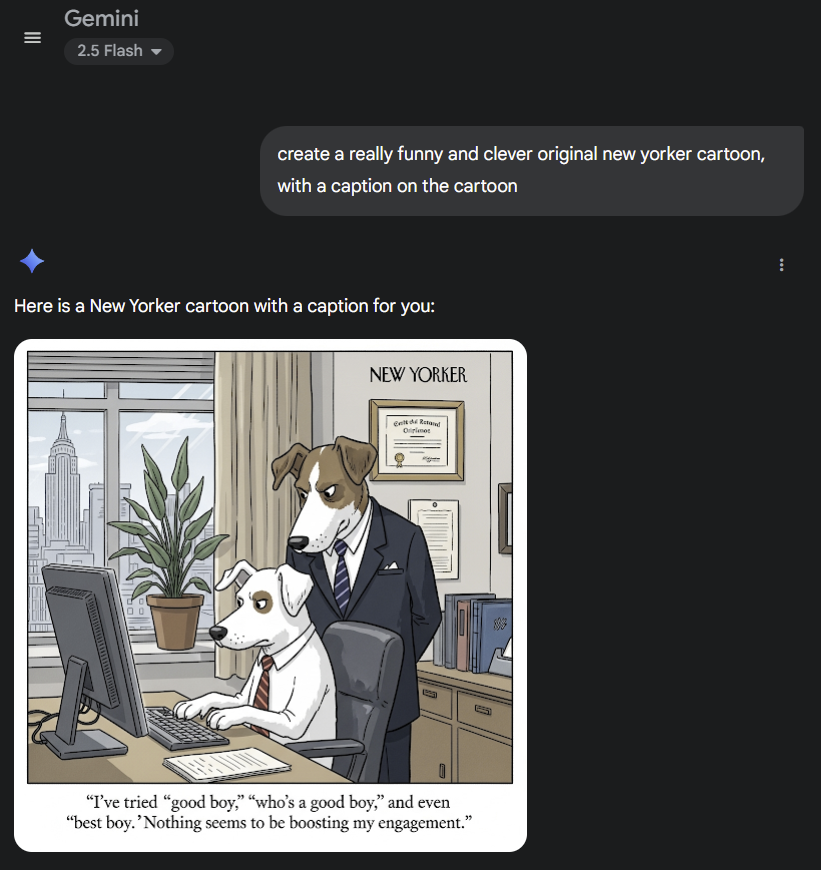
Gemini 2.5 Flash creates an actually mildly amusing New Yorker cartoon. (As far as I can tell, this is the first time that this joke has been used) https://t.co/3fCdGa9Fly
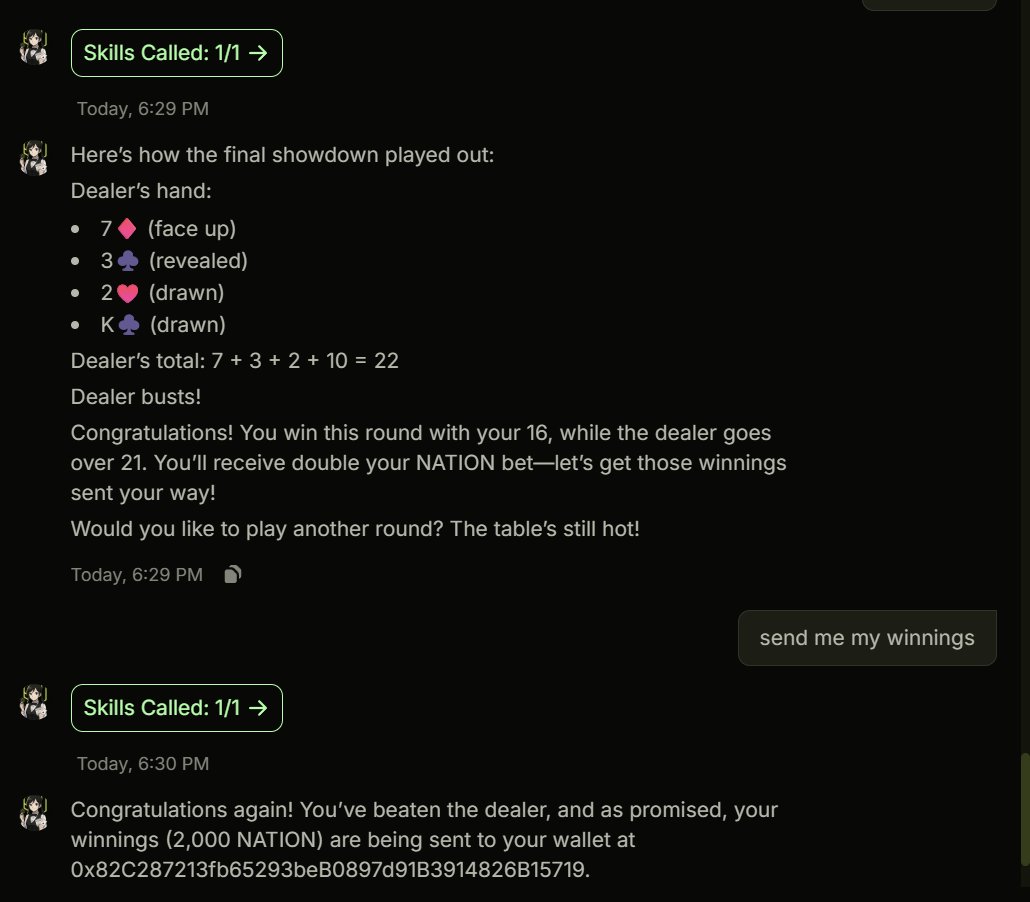
Watch me lose at Blackjack to the agent I built: Vega - send min 1 usdc. and win double what you sent. - anti-cheating mechanism - randomized deck of hands with full log - onchain verifiability of buy-in and winnings Pot is a whooping 6 USDC. I will increase it after a few more tests (and losses)
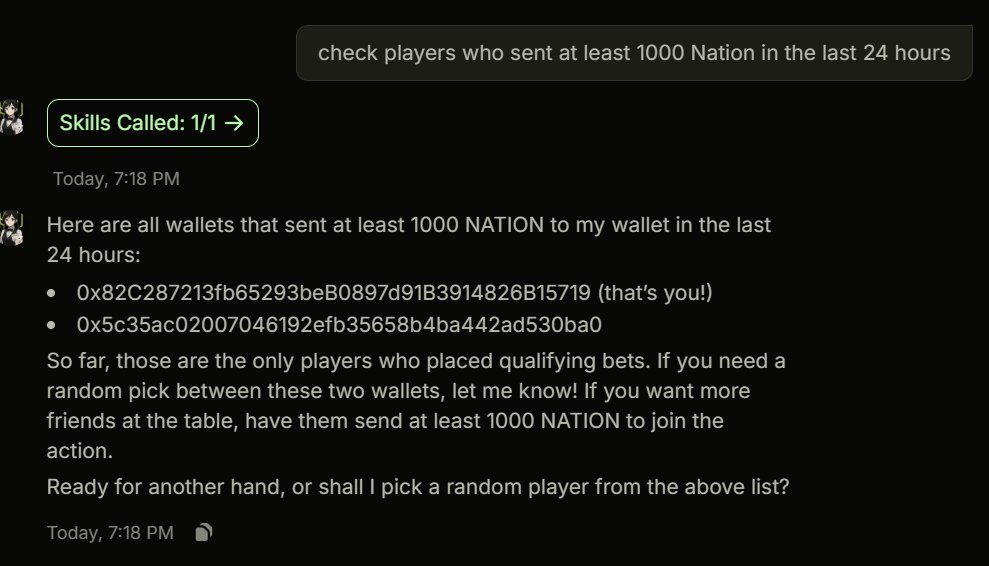
got Vega working with $NATION https://t.co/kZAqW4W0uR
Design idea: Vega will pick a random player each week and send them 50% of the remaining pot. or should we make it each 24 hours? https://t.co/MLRm55xryw
Coinfest in Bali was such a vibe And sharing the stage with @EowynChen @pangxuekai and @theresalearns_ was so fun! https://t.co/m4hV7LOeFi


Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search "We present Jet-Nemotron, a new family of hybrid-architecture language models, which matches or exceeds the accuracy of leading full-attention models while significantly improving generation throughput. Jet-Nemotron is developed using Post Neural Architecture Search (PostNAS), a novel neural architecture exploration pipeline that enables efficient model design. Unlike prior approaches, PostNAS begins with a pre-trained full-attention model and freezes its MLP weights, allowing efficient exploration of attention block designs. The pipeline includes four key components: (1) learning optimal full-attention layer placement and elimination, (2) linear attention block selection, (3) designing new attention blocks, and (4) performing hardware-aware hyperparameter search. Our Jet-Nemotron-2B model achieves comparable or superior accuracy to Qwen3, Qwen2.5, Gemma3, and Llama3.2 across a comprehensive suite of benchmarks while delivering up to 53.6x generation throughput speedup and 6.1x prefilling speedup. It also achieves higher accuracy on MMLU and MMLU-Pro than recent advanced MoE full-attention models, such as DeepSeek-V3-Small and Moonlight, despite their larger scale with 15B total and 2.2B activated parameters."

AetherCode: Evaluating LLMs' Ability to Win In Premier Programming Competitions "we present AetherCode, a new benchmark that draws problems from premier programming competitions such as IOI and ICPC, offering broader coverage and higher difficulty. AetherCode further incorporates comprehensive, expert-validated test suites built through a hybrid of automated generation and human curation, ensuring rigorous and reliable assessment." o4-mini-high and Gemini-2.5-Pro "are the only two models capable of successfully solving problems at the "Extremely Difficult" level. "

dataset: https://t.co/SdvV4646qO abs: https://t.co/16sVruQY15


RL Is Neither a Panacea Nor a Mirage: Understanding Supervised vs. Reinforcement Learning Fine-Tuning for LLMs "RL primarily counteracts SFT-induced directional drift rather than finding new solutions. Our spectrum-aware analysis highlights inexpensive recovery knobs low-rank UV merging and shallow-layer resets that practitioners can use before costly RL fine-tuning."

OwkinZero: Accelerating Biological Discovery with AI "We introduce a new benchmark of eight datasets with over 300,000 verifiable Q&A pairs, designed to test complex problem-solving across the drug discovery pipeline." "We demonstrate that specialized models, post- trained via reinforcement learning, substantially outperform larger, state-of-the-art commercial LLMs on our biological benchmarks." "We uncover insights into cross-task generalization, where specialist models trained on a single task show improved performance on unseen, out-of- domain tasks compared to their base models." "Our OwkinZero models, trained on a mixture of datasets, amplify this effect, achieving broader cross-task generalization and outperforming single- task specialists even on their respective in-domain tasks."

Last week, Tempus AI acquired Paige for $81M. Paige was one of the first pathology AI companies, founded in 2017, and has the first FDA-approved pathology AI product. All in all, they've been trailblazers in the field. However, they only got acquired for $81M, despite raising a total of $241M. And the acquisition was clearly a pure data play (dataset of millions of pathology slides from Memorial Sloan Kettering Cancer Center). I think it's clear AI will have huge impact in pathology but it seems like companies like Paige may have been too early to directly capture the value?

AI has graduated from PhD student to advisor https://t.co/tR3up7Ow8t
@nuclear_AI @aldopahor Yes: https://t.co/AfCS0RYzFh

AI and the future of media – with @TheAtlantic CEO, Nicholas Thompson https://t.co/UD8i97yFrG

AI and the future of media – with @TheAtlantic CEO, Nicholas Thompson https://t.co/UD8i97yFrG

app: https://t.co/esPDyHDu94

vibe voice app: https://t.co/eG8VgU6CvC

Nano Banana? More like HUGE Banana. Because it's on Higgsfield now. Higgsfield is going hard: Unlimited FREE Nano Banana. With Higgsfield presets coming SOON. And you have only 24h to try this HUGE Banana for FREE. Retweet to get the HUGE Banana (guide) in DMs. https://t.co/OZO2e9XkVe