Your curated collection of saved posts and media
Made in London with AWS: Justina Chung, VP, @BessemerVP. Based in Bessemer’s London office, Chung discusses the AI advantage for startups looking to launch and build a business in the city. Through the company's partnership with AWS, she is able to help founders access infrastructure, compute, and expertise.
@jxnlco LinkedIn is starting to find it https://t.co/Sy4aMmbmqa
@jxnlco LinkedIn is starting to find it https://t.co/Sy4aMmbmqa
today, we release the open weights of Krea 2. welcome Krea 2 Raw and Krea 2 Turbo, an undistilled model from mid-training meant to be fine-tuned, and a fast distilled version with a wide aesthetic diversity. read the details below 👇 https://t.co/3ymzUL2bxv
@TheZachMueller Don’t let the polls do this to you 🤣 https://t.co/9OHRTU1J9I

JUST IN🚨: A quantum computer just performed 2.6 billion years of computation in 4 minutes https://t.co/Zy4ZI6yDis


JUST IN🚨: A quantum computer just performed 2.6 billion years of computation in 4 minutes https://t.co/Zy4ZI6yDis


💯 https://t.co/RltSC8fg9b

@NousResearch Hey Hermes, /learn Kung Fu https://t.co/PcyRLbkaIX

@NousResearch Hey Hermes, /learn Kung Fu https://t.co/PcyRLbkaIX

Learned good things from the most recent test! The 'gear ratio' between the syringe bore vs the 1/16' tube vs the 0.1mm wide channels on the chip is hard to wrap my head around. I think tomorrow I'll stop building from my head and see how other people do microfluidics haha. https://t.co/GvrCiXFUuW

Qwen-AgentWorld: Language World Models for General Agents "We introduce Qwen-AgentWorld-35B-A3B and QwenAgentWorld-397B-A17B, the first language world models capable of simulating agentic environments covering 7 domains via long chain-of-thought reasoning." "We explore two complementary strategies for applying world modeling to enhance language agents (mainly using the 35B-A3B model as agent): Decouple and Unify , where the world model serves as the environment simulator and agent foundation model, respectively."
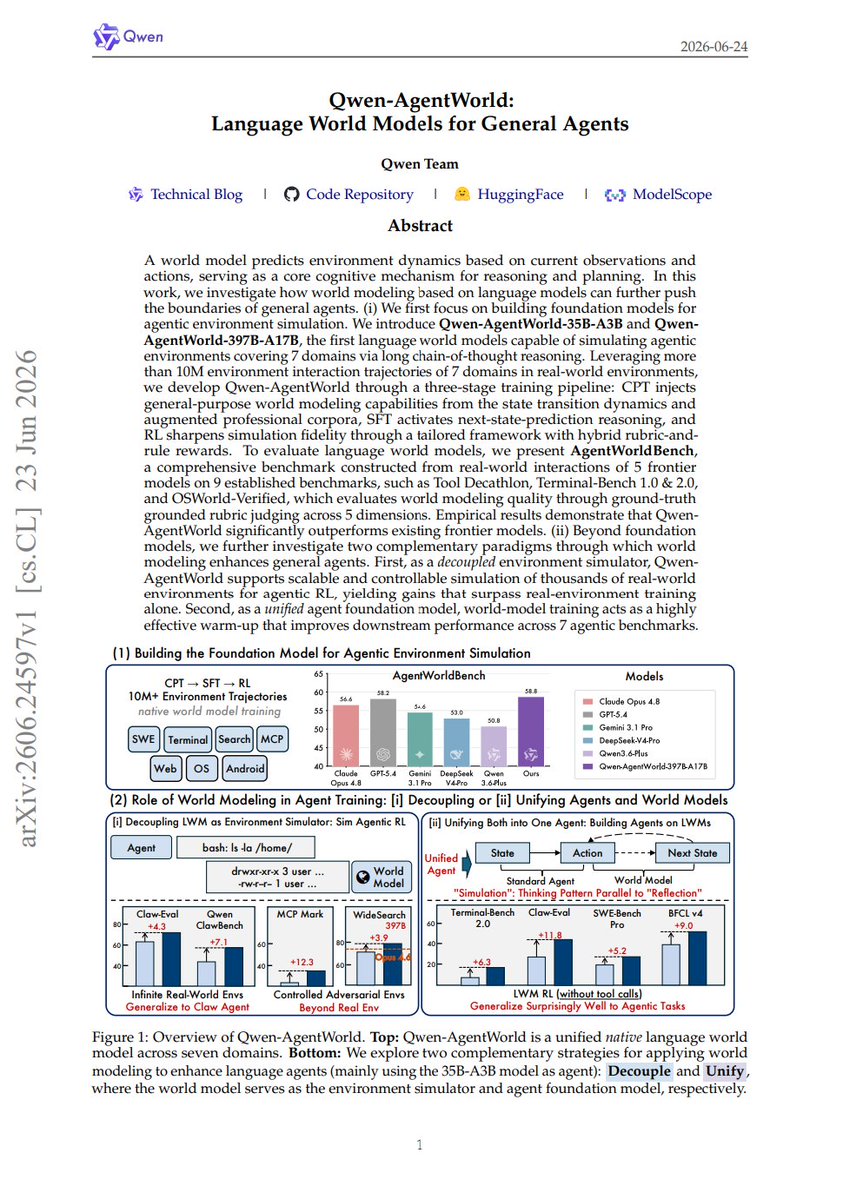
blog: https://t.co/qLAINM9ozD code: https://t.co/EqmJlMtB8C huggingface: https://t.co/yPbcomSzwq abs: https://t.co/2VZCXCO6gC

OpenThoughts-Agent: Data Recipes for Agentic Models "a fully open data curation pipeline for training agentic models" "more than 100 controlled ablation experiments to systematically investigate each stage of the pipeline" Key findings: • As with reasoning data, the choice of instructions is among the most important factors in our data pipeline. • The strongest model by benchmark performance does not necessarily make the best teacher. • Filtering training data to retain the execution traces with more model turns improves the resulting training sets. • Repeating the top few sources leads to diminishing returns in our largest training runs, and we therefore expand the set of data sources to increase diversity. "We then assemble a training set of 100K examples from our pipeline and fine-tune Qwen3-32B on this dataset, which yields an average accuracy of 44.8% across seven agentic benchmarks"

Try this great Unlimited-OCR demo from @_akhaliq: https://t.co/IhXb2Kyf5O
Baidu just released Unlimited-OCR https://t.co/oxvNrDg1SC

Try this great Unlimited-OCR demo from @_akhaliq: https://t.co/IhXb2Kyf5O

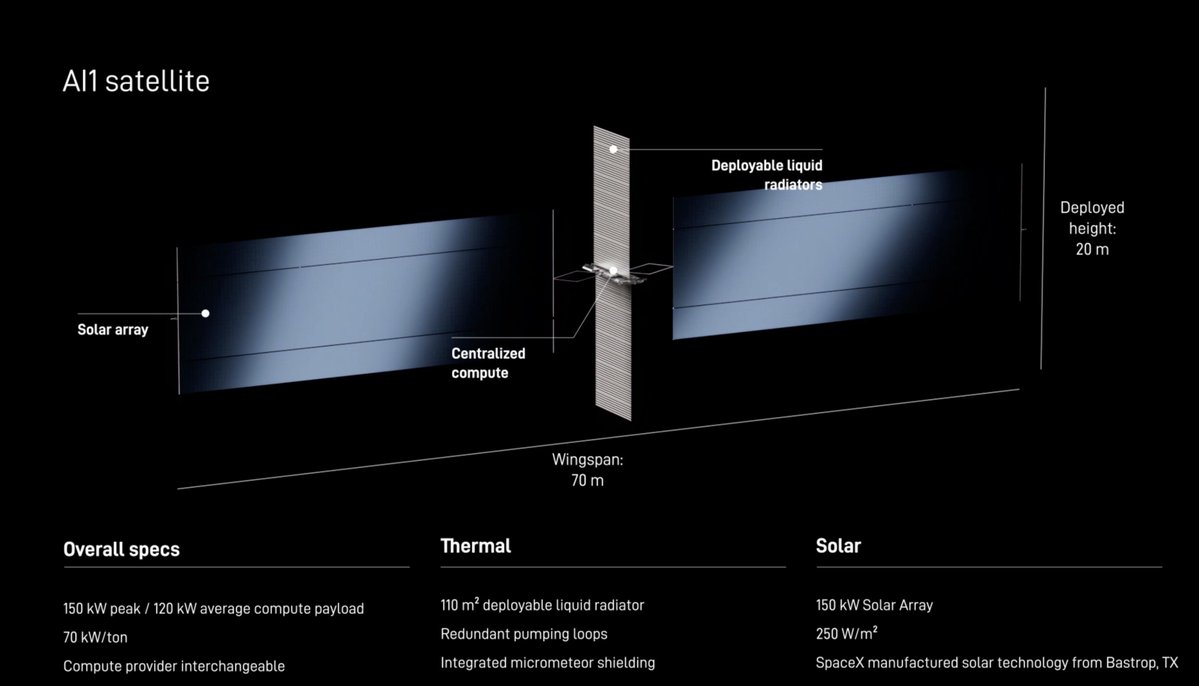
Elon confirms "Starmind" will be the official name of @SpaceX's AI satellite constellation. Earlier this year, SpaceX filed a request with the FCC to launch and operate a constellation of 1 million AI satellites. SpaceX's AI1 satellite: https://t.co/BrssGvX6Ub
@xdNiBoR @xai Yes
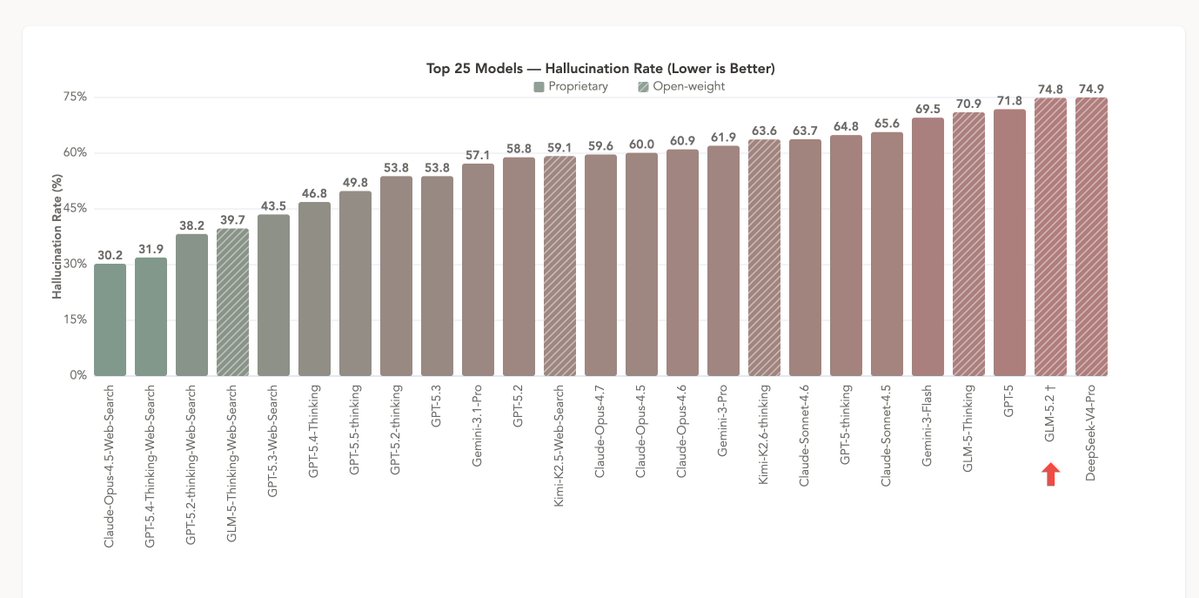
HalluHard update: We’ve added GLM-5.2, using adaptive thinking with maximum reasoning effort, to our leaderboard. Despite its impressive performance on other benchmarks, GLM-5.2 still hallucinates frequently on our challenging multiturn benchmark. https://t.co/xbppFeo7Pd
A lot of people talk about AI's impact on jobs. Oracle just put some numbers behind that discussion, cutting 21,000 roles while accelerating its AI push. The transition from AI experimentation to AI implementation is well underway. https://t.co/45VKOcl5RI

https://t.co/dHeVhIcLe5

https://t.co/6eqLRsyvV3 @itsjessyin project!

https://t.co/6eqLRsyvV3 @itsjessyin project!

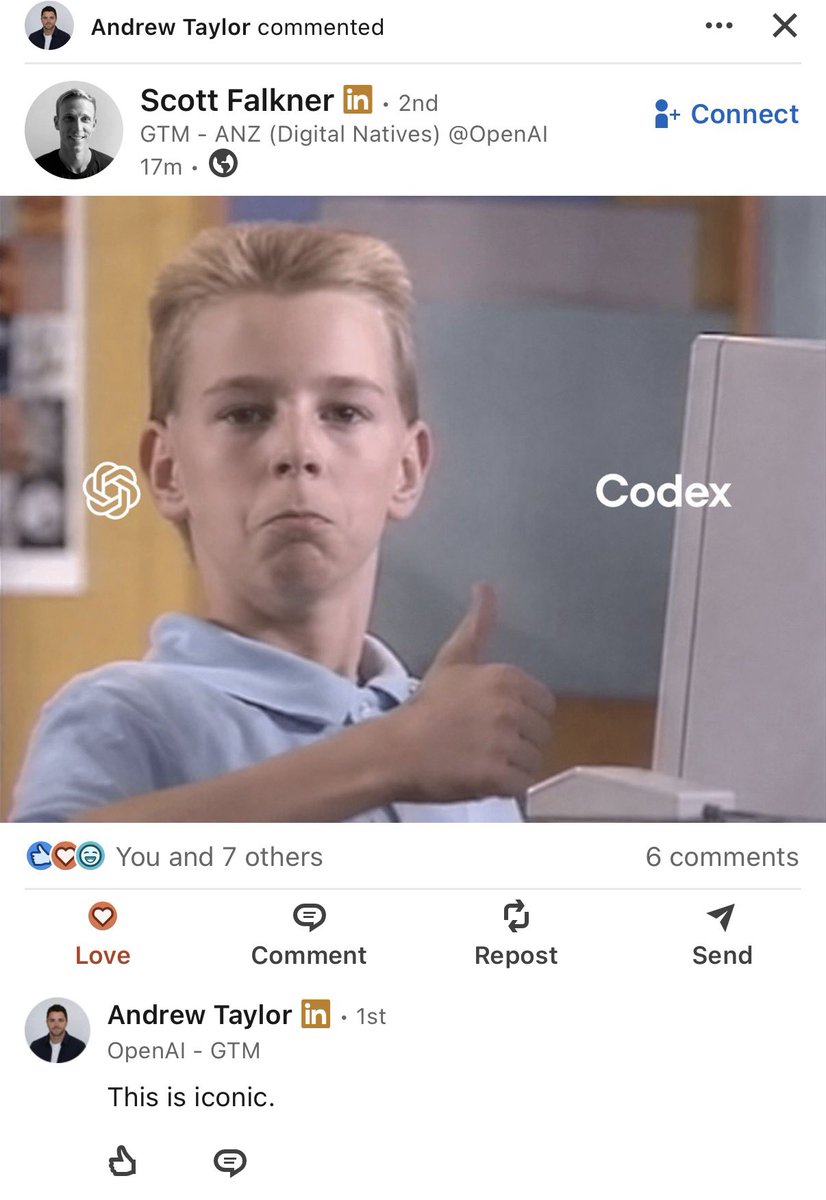
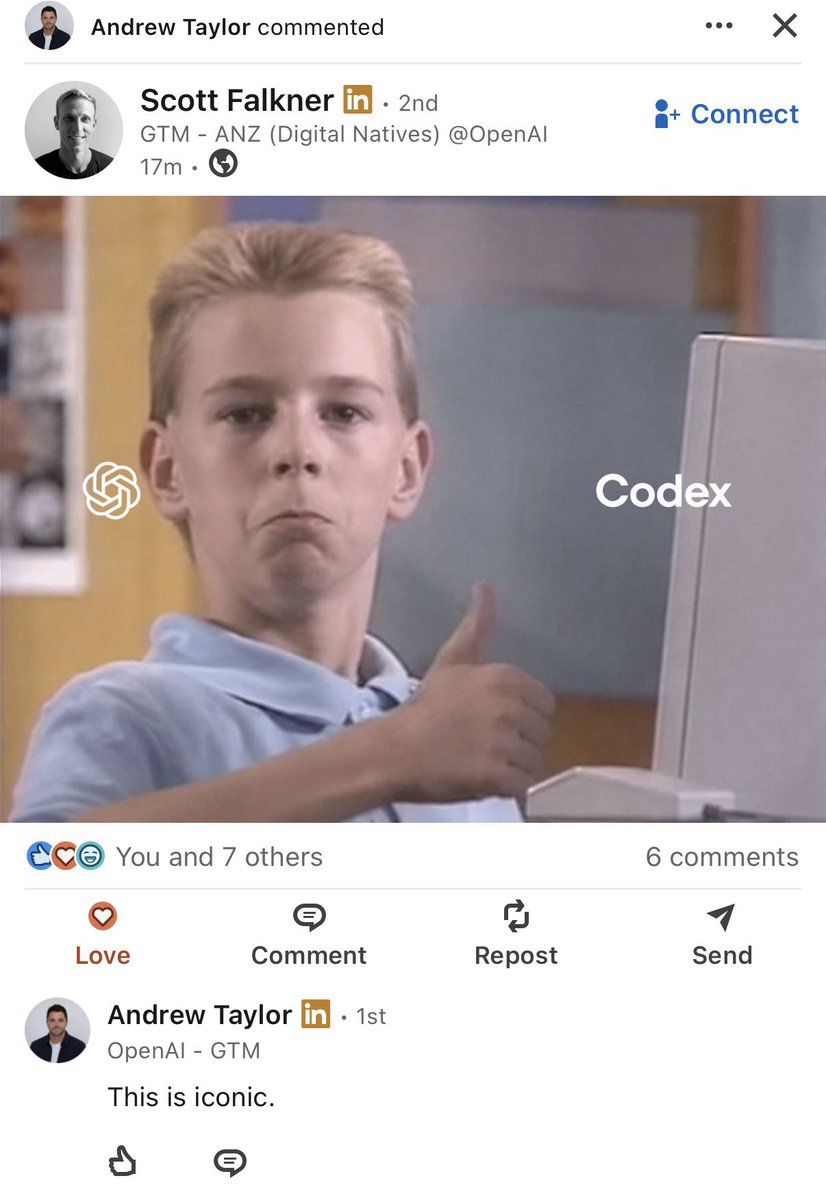
ever since i was a small boy i knew i wanted to computer https://t.co/u0llIGUzx1
ever since i was a little girl i knew i wanted to computer https://t.co/iOHK59SO2A


ever since i was a small boy i knew i wanted to computer https://t.co/u0llIGUzx1


@michellechen this inspires me. I knew I'd like to work with computeRS, too. https://t.co/PWaKkgxeAa

@michellechen this inspires me. I knew I'd like to work with computeRS, too. https://t.co/PWaKkgxeAa

@jxnlco https://t.co/NuCBHUypTf

@jxnlco https://t.co/NuCBHUypTf

UV curing resin arrived and made life much easier! The graveyard is growing :) https://t.co/JmCiWVlmp3

absurd that LLM benchmarking papers from THIS YEAR are evaluating SUCH OLD MODELS! https://t.co/WQNPBA6dvz
