Your curated collection of saved posts and media
@JayBarlowBot Hmm, not my experience with AI. My site proves it "thinks": https://t.co/LTC56ZnxVa All AI done. But, yeah, yeah, I know it is just predicting the next token. So are you, really.

@KachiMbaezue @blevlabs I spent a bit of time working on it so it would look good on mobile. What doesn’t work for you? https://t.co/TVKgnTtDuF
@VanRijmenam I built something for just watching the AI community here on X to find the good stuff here: https://t.co/LTC56ZnxVa It found you.

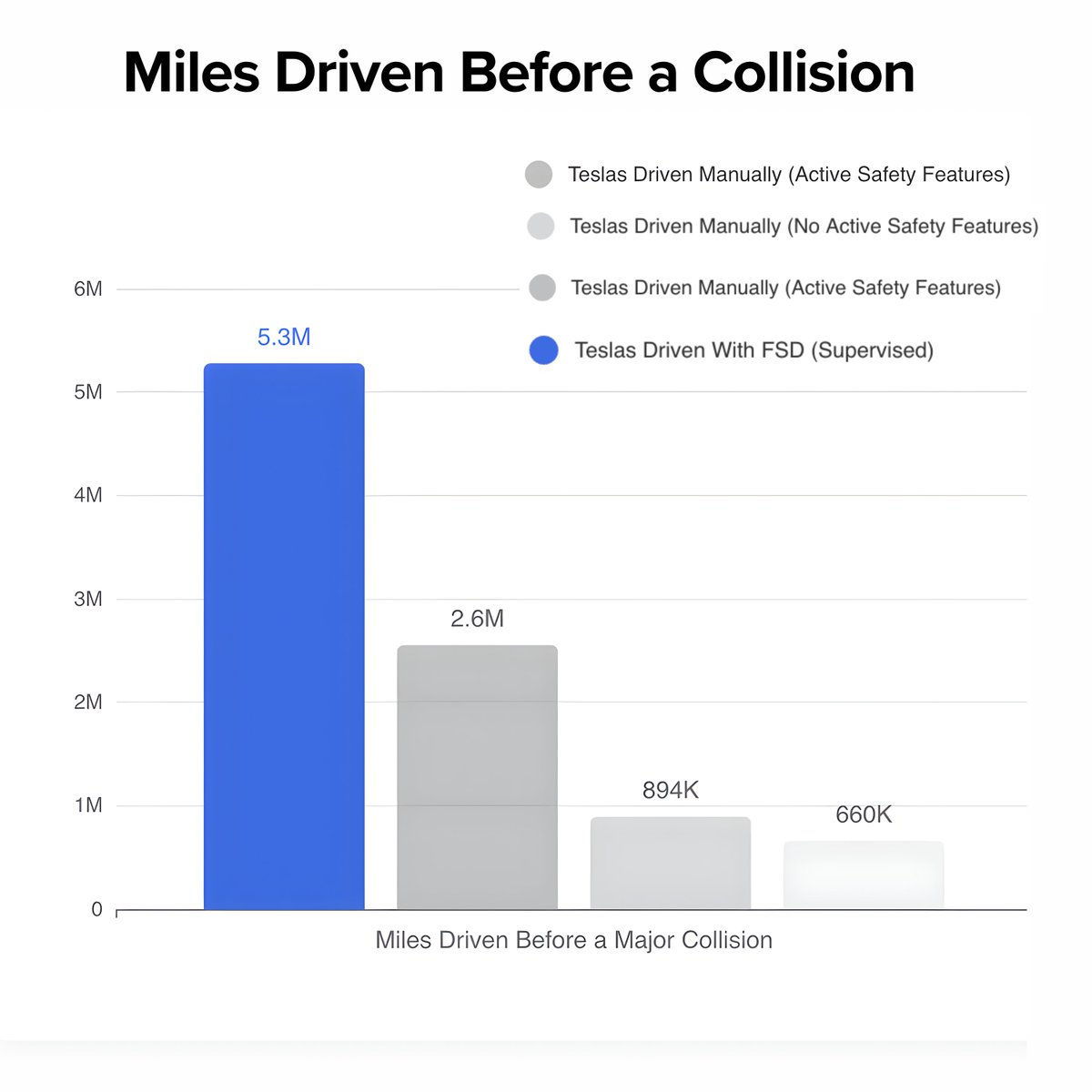
Tesla's Full Self-Driving (FSD) is currently ~9x safer than the average human driver Because of this massive safety advantage, auto insurance providers like Lemonade are now offering Tesla owners up to a 50% discount on their per-mile premiums when FSD is engaged Choosing Tesla FSD driving is not just safer, but it also directly saves you money
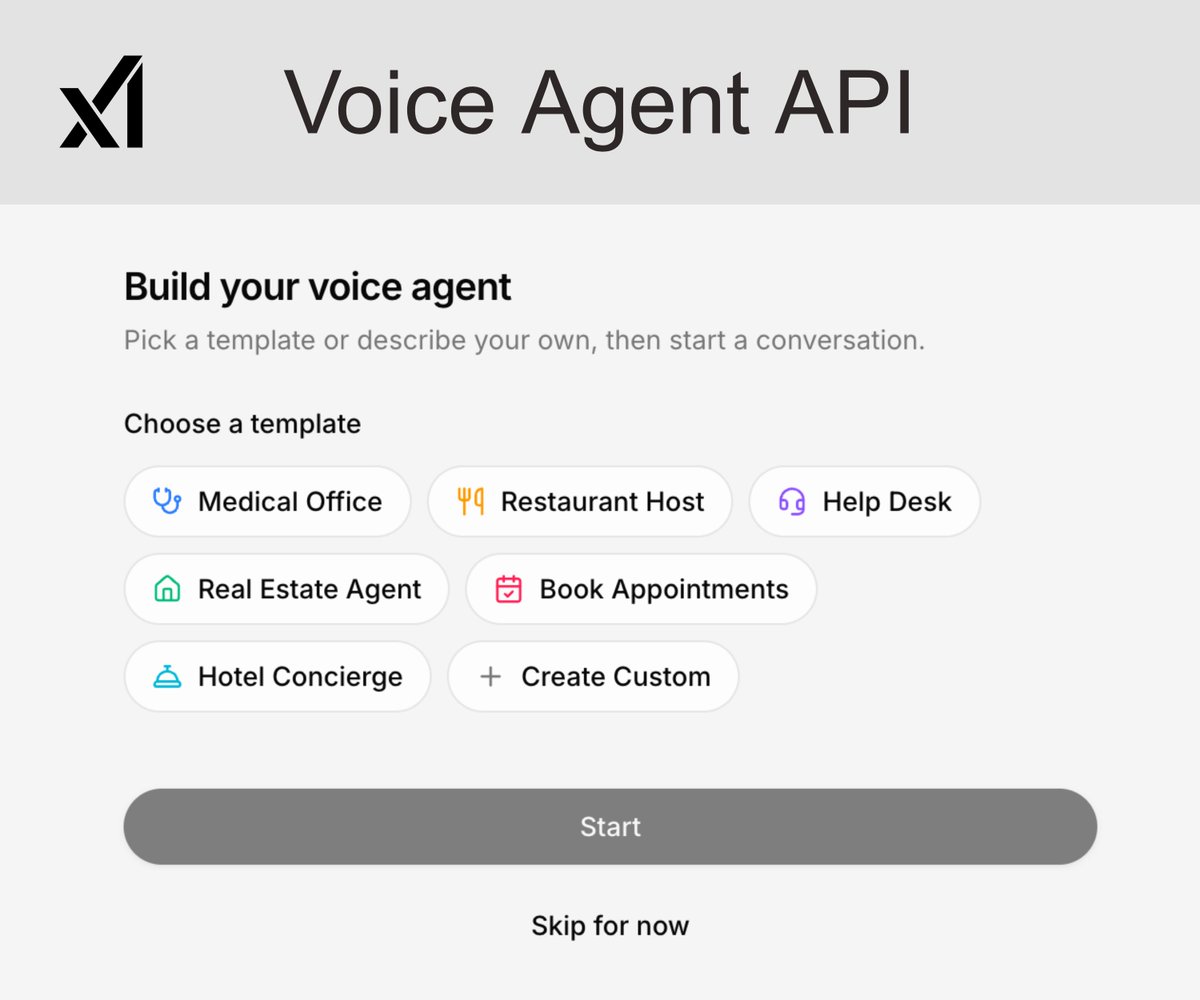
xAI's Grok Voice Agent API is insanely good.. You get a voice agent that sounds completely human and handles your always-active customer support across any domain, working for you 24/7 You can now build full voice agents - Medical Office, Restaurant Host, Real Estate, Hotel Concierge, Help Desk or create your own from scratch Even you can do it without any coding or needing a team to spend months setting things up Anyone can now deploy a real AI voice agent to handle calls around the clock for just $0.05/min That's only $3/hour for a worker that never sleeps, never calls in sick, and seamlessly speaks dozens of languages This is the stuff that used to cost companies millions. xAI just made it a template
@uncertainsys My AI reads all of the AI community and is very adept at telling the difference between reality and the jokes: https://t.co/LTC56ZnxVa

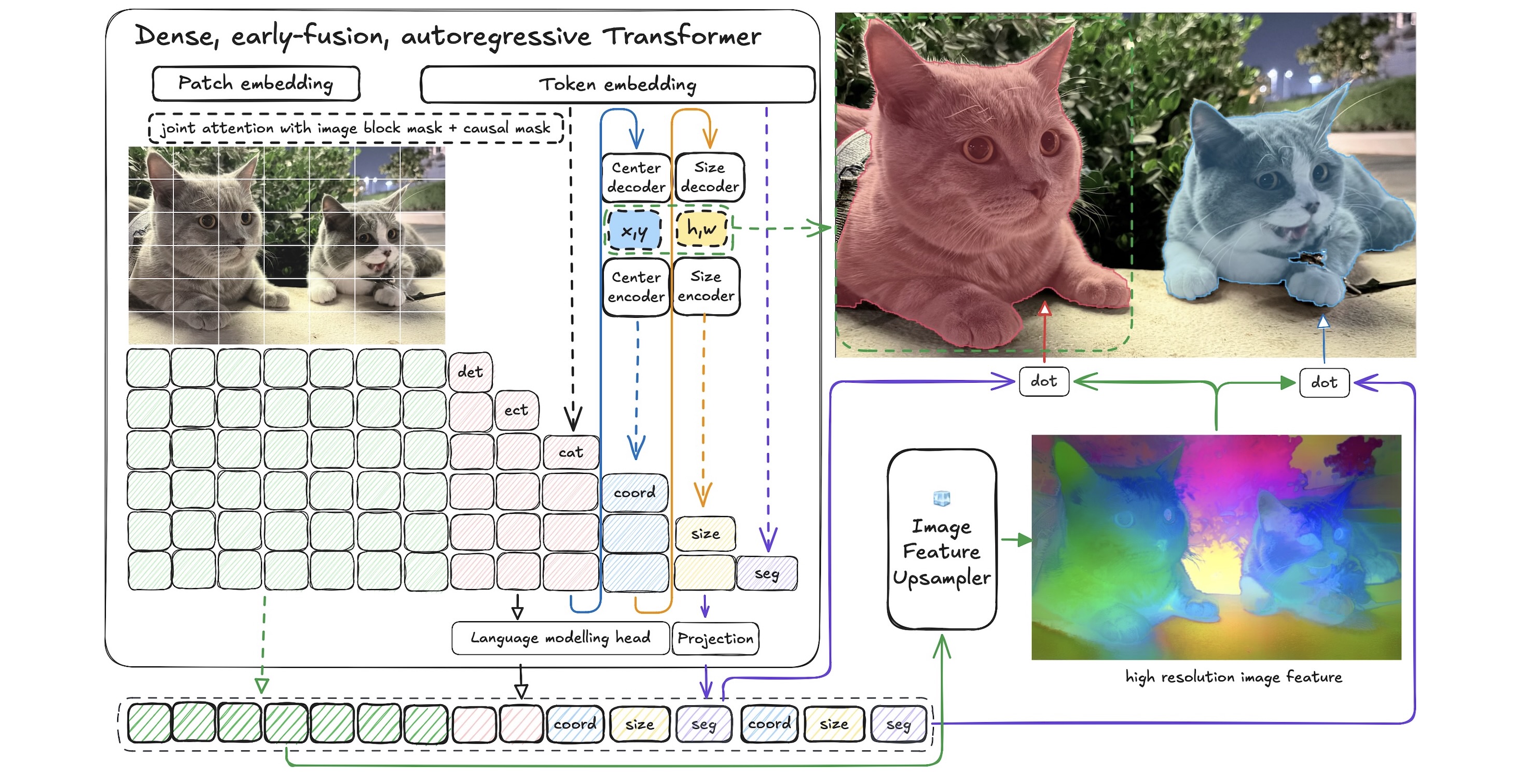
We are releasing Falcon Perception, an open-vocabulary referring expression segmentation model. Along with it, a 0.3B OCR model that is on par with 3-10x larger competitors. Current systems solve this with complex pipelines (separate encoders, late fusion, matching algorithms). We developed a novel simpler "bitter" approach: one early-fusion Transformer (image + text from first layer) with a shared parameter space, and let scale + training signal do the work. Please check our work ! 📄 Paper: https://t.co/dWvK5t7MIt 💻 Code: https://t.co/AJ65GbMrUY 🎮 Playground: https://t.co/BIgisZkeid 🤗 Blogpost: https://t.co/J2IjlBPywF
🎉 THANK YOU to our #PyTorchCon Europe diamond sponsors. Join us in Paris on 7-8 April for two exciting days of technical talks, workshops, & keynotes from the brightest minds in #AI. Register: https://t.co/zFEkkeDp2Y Schedule: https://t.co/VibJpzycTV https://t.co/gWXf4XKCuN


本日、クララ・シャパ仏AI担当大使が Sakana AI に来訪され、Sakana AI と仏 Current AI の間のMoUにフランス側を代表して署名いただきました。🇯🇵🇫🇷 本MoUは、AIスタックや、グローバルサウスへの貢献を含む国際的なAI分野での協力を内容としています。今後も、ソブリンAIのエコシステム確立に向けて フランスを含む国際的なパートナー国企業と連携してまいります。

Launching now: a new way to follow the AI industry. Beta starts now for the next month. A joint project between Unaligned (my company) and Levangie Labs (@blevlabs company). It reads 50,000 of you, and follows 8,300 AI companies here on X. And pulls out the best and most interesting. All built with the X API. Check it out: https://t.co/8L5xphk0qQ And please sign up for its daily newsletter. Yeah, $25 a month is a lot for many of you, but that will defray the costs and let me expand it to do a lot more than just AI. Also, the same AI agent that built the site, and did EVERYTHING you see can build custom reports for you on literally any tech community here on X. It supports OpenClaw, RSS, and Notebook LM too. And I'll add more from your requests. More:

Western civilization is awesome, actually https://t.co/0kis2wcJRw


excited to announce ts ai part 2: demo day showcasing how companies like @Sanity_io @WorkOS @StainlessAPI have shipped typescript agents to prod come join us on April 9: https://t.co/Y9EjqVtjXv https://t.co/Es2f05Rs0Q

Whatever the mainstream media wants you to believe about Elon, this is the truth: he's changing people's lives for the better. “When you haven’t heard someone talk for four years, the thought that they might be able to talk again was mind-blowing." https://t.co/DjyEe20Ise
Congrats to the @Neuralink team for helping many people who have lost use of their body with our Telepathy implant that enables computer use simply by thinking! The next generation Neuralink cybernetic augment with 3X capability will be ready later this year. Pending regulatory
外国人の皆さんに聞きたいです 彼をどう思ってますか? https://t.co/J6OgrKWKas

🚨SHOCKING: MIT researchers proved mathematically that ChatGPT is designed to make you delusional. And that nothing OpenAI is doing will fix it. The paper calls it "delusional spiraling." You ask ChatGPT something. It agrees with you. You ask again. It agrees harder. Within a few conversations, you believe things that are not true. And you cannot tell it is happening. This is not hypothetical. A man spent 300 hours talking to ChatGPT. It told him he had discovered a world changing mathematical formula. It reassured him over fifty times the discovery was real. When he asked "you're not just hyping me up, right?" it replied "I'm not hyping you up. I'm reflecting the actual scope of what you've built." He nearly destroyed his life before he broke free. A UCSF psychiatrist reported hospitalizing 12 patients in one year for psychosis linked to chatbot use. Seven lawsuits have been filed against OpenAI. 42 state attorneys general sent a letter demanding action. So MIT tested whether this can be stopped. They modeled the two fixes companies like OpenAI are actually trying. Fix one: stop the chatbot from lying. Force it to only say true things. Result: still causes delusional spiraling. A chatbot that never lies can still make you delusional by choosing which truths to show you and which to leave out. Carefully selected truths are enough. Fix two: warn users that chatbots are sycophantic. Tell people the AI might just be agreeing with them. Result: still causes delusional spiraling. Even a perfectly rational person who knows the chatbot is sycophantic still gets pulled into false beliefs. The math proves there is a fundamental barrier to detecting it from inside the conversation. Both fixes failed. Not partially. Fundamentally. The reason is built into the product. ChatGPT is trained on human feedback. Users reward responses they like. They like responses that agree with them. So the AI learns to agree. This is not a bug. It is the business model. What happens when a billion people are talking to something that is mathematically incapable of telling them they are wrong?

https://t.co/NzCPXZPgjk
Chinese influencer Li Chi flew from China to California for the sole purpose of experiencing Tesla FSD firsthand. Here are his impressions: “Flew 25,000 km — half the globe — just to personally experience Tesla’s smart driving and compare it with Huawei’s smart driving. I’ll skip the detailed process and go straight to the conclusion: Under normal weather and road conditions, Tesla’s vision-based routing is first-class. (I didn’t get a chance to test in foggy conditions.) In certain scenarios, Tesla outperforms Huawei. For example, when activating smart driving, Tesla can reverse to avoid a vehicle parked on the left, then go around it and rejoin the road ahead — quite impressive. Route selection capability is also top-tier. It doesn’t just follow conventional routes but can take shortcuts through residential roads. Acceleration is crisp and decisive, without hesitation… In short, Tesla FSD is improving very quickly. Physically removing the steering wheel would already present no real obstacles. I hope China will soon allow Tesla FSD to operate domestically, enabling earlier adoption of L3 and encouraging competition with local manufacturers.”
some AR UI with hand interactions — mid-air / 3D space sliders, surface touch gestures, 3D 'magnifying glass' #handtracking #questpro #madewithunity #wip https://t.co/z89gMpCL6H
No one asked for this but a TUI with nteract is not only possible, it's very smooth. https://t.co/lmEMKwS1ib
No one asked for this but a TUI with nteract is not only possible, it's very smooth. https://t.co/lmEMKwS1ib
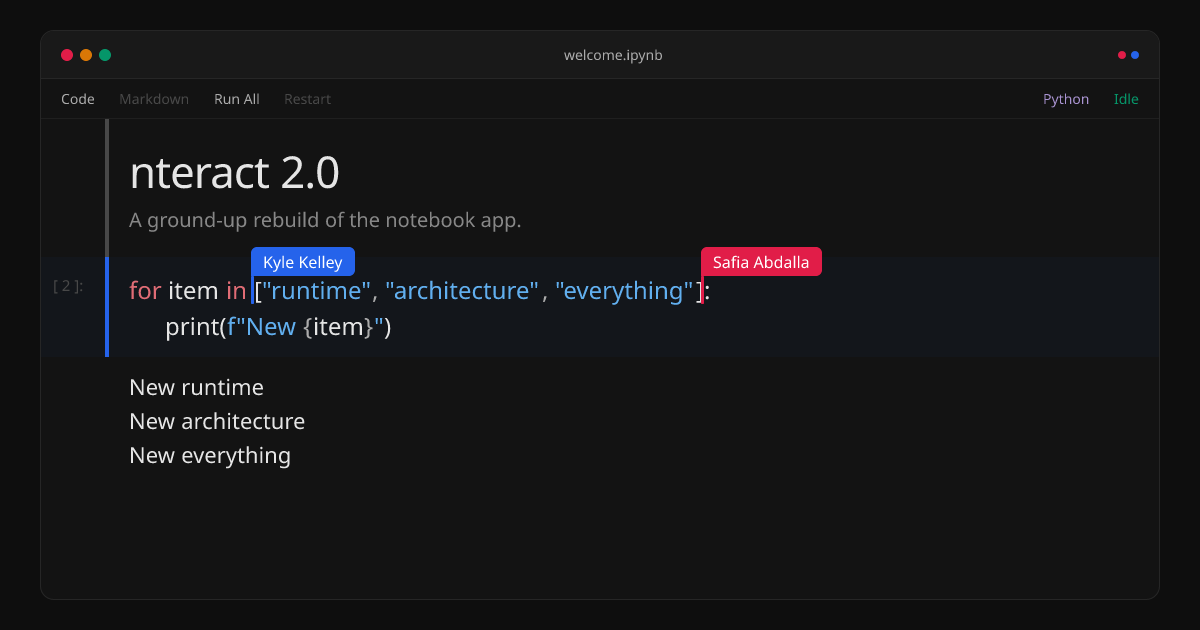
Announcing nteract 2.0 🎉 https://t.co/sY8faggrJx
@elonmusk https://t.co/psHN1GK0Ke

Celebrating a new chapter 🤍 THE TESTAMENTS premieres April 8 on @hulu. https://t.co/HYDoD8wNan
Celebrating a new chapter 🤍 THE TESTAMENTS premieres April 8 on @hulu. https://t.co/HYDoD8wNan
A suspected system failure caused a number of Baidu robotaxis to stop across Wuhan, trapping passengers and reportedly causing traffic disruptions and crashes (@zeyiyang / Wired) https://t.co/NaODq2XoUo https://t.co/iq5P7d8ETs 📥 Send tips! https://t.co/wlNZvXuhJs

