Your curated collection of saved posts and media
🤖 Waiting for that main chat to finish? The Agents window (Preview) now lets you start side conversations to explore multiple ideas at the same time! 🔗 Read the full release notes: https://t.co/zX4FfXo1cm

🌐 The VS Code Blog has a new home! 🔗 Visit our blog: https://t.co/dFL2PdPPcT https://t.co/flXulCp0tR
@hanakoxbt https://t.co/k3M9iEQhSt
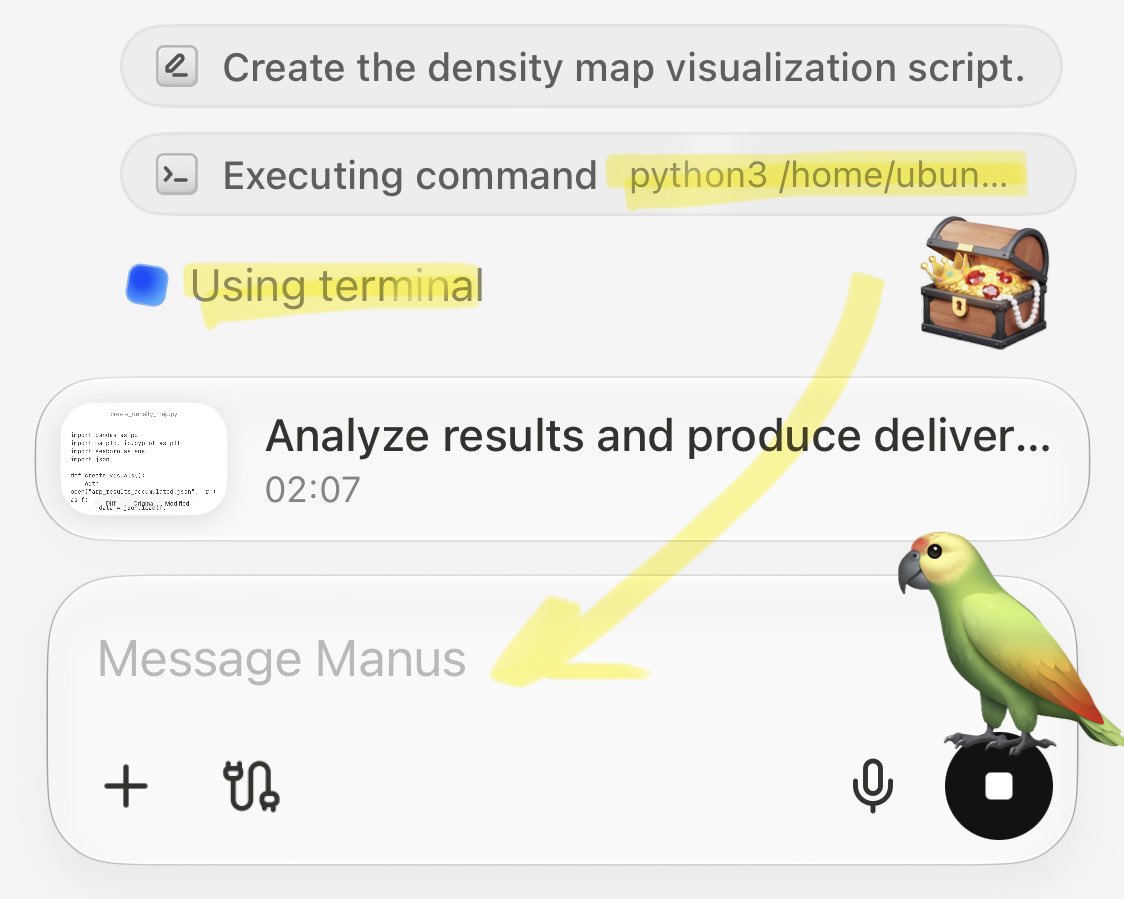
🚨 Claude Mythos: Manus only AI matching its Agentic OS features Full spec: Ubuntu sandbox. Python runtime. Agentic Loop: Plan Act Verify. Skill composition. Multi-agent. Self-optimisation. See app below running an eval against chat APIs. Try it here: https://t.co/TiD1kDSyUr h
@primemans https://t.co/k3M9iEQhSt
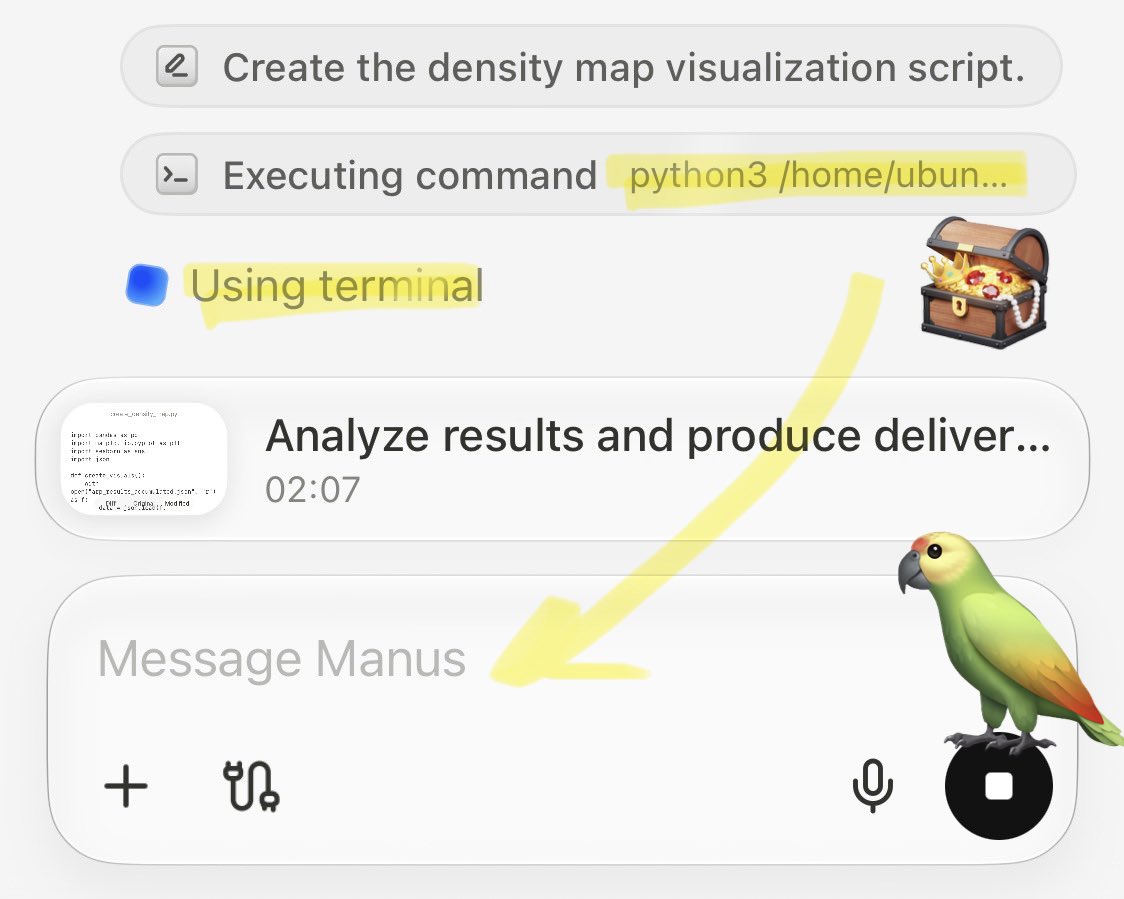
🚨 Claude Mythos: Manus only AI matching its Agentic OS features Full spec: Ubuntu sandbox. Python runtime. Agentic Loop: Plan Act Verify. Skill composition. Multi-agent. Self-optimisation. See app below running an eval against chat APIs. Try it here: https://t.co/TiD1kDSyUr h
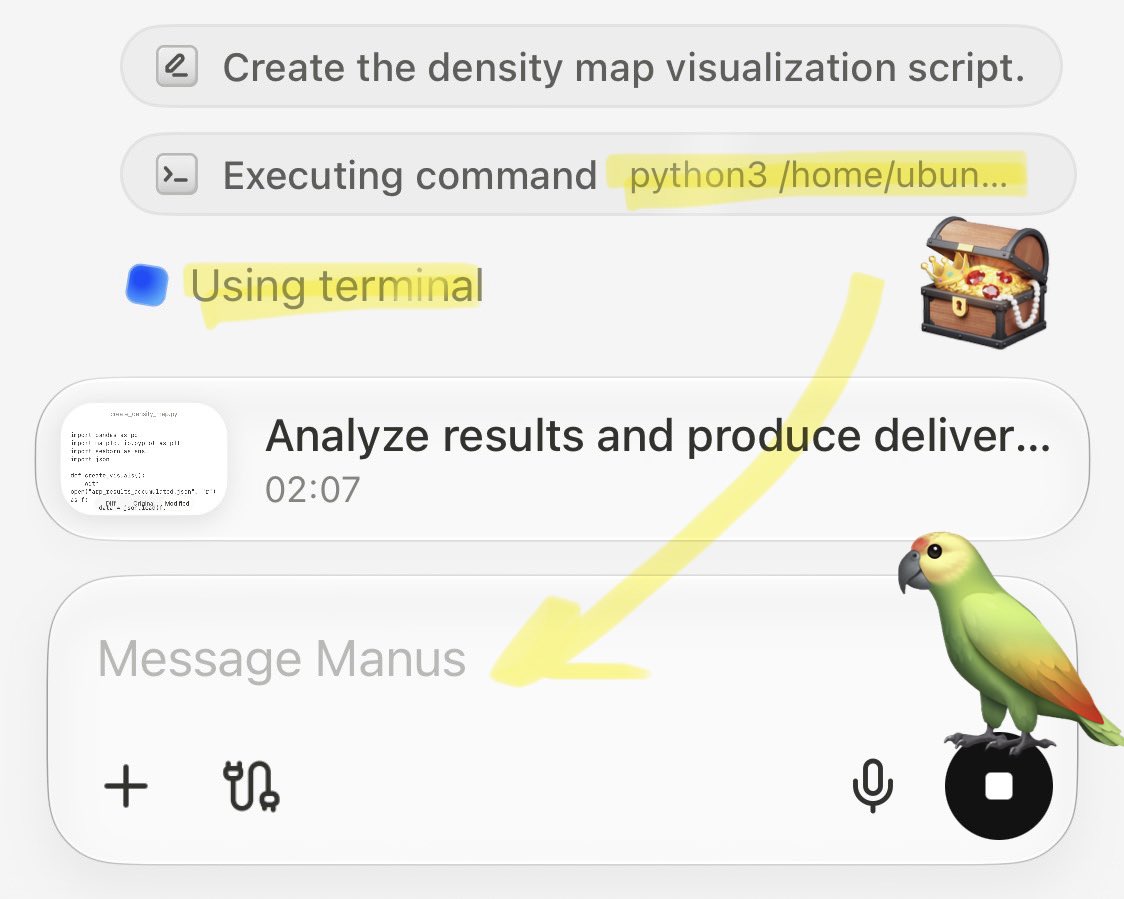
🚨 Claude Mythos: Manus only AI matching its Agentic OS features Full spec: Ubuntu sandbox. Python runtime. Agentic Loop: Plan Act Verify. Skill composition. Multi-agent. Self-optimisation. See app below running an eval against chat APIs. Try it here: https://t.co/TiD1kDSyUr https://t.co/ckLuWYEJMr
🚨 Claude Mythos: Is Claude-ception a Safety Risk? Deeper into the instructions we find the most intriguing feature: “Claudeception”. AI inside AI. No safeguards. Only a payload limit. No user in the loop. Agentic OS > Chat Nested loops running unattended at scale!? Yep 🕳️
1/ Introducing HIW-500 (Humanoids-in-the-Wild 500): the largest open-source humanoid teleop dataset collected in real homes Built w/ @UnitreeRobotics @huggingface across 12 homes in Southeast Asia, it covers: > 500+ hrs > 23K+ episodes > 10+ TB > 10+ household tasks https://t.co/KUfFJm4wno
We’ve designed and built our first AI chip: Jalapeño. Designed from the ground up by OpenAI and brought to production with @Broadcom, Jalapeño is purpose-built for the LLM workloads powering ChatGPT, Codex, the API, and future agentic products. Chips are foundational to the AI economy. Building our own expands our full-stack platform from products to models to infrastructure, and will help us scale intelligence, serve more people, and expand access to AI.

From dough to the tear.🍩 Made with Seedance 2.0 + GPT Image 2 on @Hailuo_AI Prompt ⤵️ https://t.co/3Fr3jfmXl2
Someone’s about to have the best day.🌸 Made with Seedance 2.0 + GPT Image 2 on @SJinn_Agent Prompt ⤵️ https://t.co/CjmcESRVQy
From dough to the tear.🍩 Made with Seedance 2.0 + GPT Image 2 on @Hailuo_AI Prompt ⤵️ https://t.co/3Fr3jfmXl2
https://t.co/ZrOeFyHgeo

The new Claude Tag feature seems extremely useful, but at the same time, a dangerous bargain for enterprises because of the pricing model and the risk of lock-in. The four big changes together mean that you interact with Claude as a coworker instead of a tool (the same Claude instance for everyone instead of each worker; soaks up tacit knowledge without your telling it; acts on its own; and does so asynchronously). All clearly very useful, but completely flips the interaction paradigm. https://t.co/iWpePXGiL8 Let’s talk about lock-in. As far as I can tell, Claude maintains its own memories in this new way of working; the human team members can’t see and edit them. (System administrators presumably can, but they have other things to do!) Tacit knowledge thus goes from a weakness of AI agents to a major strength — it seems inevitable that as teams and orgs start to use Claude this way, it will become the main queryable repository of all their tacit knowledge, creating dependence and stickiness. Effectively, Claude is a coworker that you can’t fire without *every* team losing workflows and know-how. By the way, it also seems to introduce a new and pervasive security risk, since Claude can be integrated into private channels as well, and can be given access to repositories and tools even if the users in that channel don’t have access to them. Anthropic has introduced an interesting but complicated access control model to handle all this: https://t.co/l4oB5SVk9r But I’m not sure I trust people to understand and implement it correctly, nor the LLMs to be sufficiently robust against threats like prompt injection. What about pricing? Claude is not like regular coworkers, because it bills for every token it produces. And it can do an unbounded amount of work, asynchronously and without being asked. In the current model, when AI is a tool, enterprises set per-user budgets, which creates accountability and keeps cost somewhat manageable. When everyone shares a Claude, it will be much harder to track and control spending. Of course you can set a token budget, but turning off Claude for the month for everybody when the budget is hit risks bringing work to a screeching halt. When AI companies talk about the next stage of AI being a “drop-in replacement” for human workers, it should be understood not as a technical innovation but a business model innovation, enabling more value capture and rent extraction. AI companies are no longer competing for a share of enterprises’ IT budgets but rather a share of their entire labor spend, which is orders of magnitude bigger. Claude Tag is a big milestone in this evolution. This shift is very good for AI companies, but it is unclear if it is good for their customers.

Learn more: https://t.co/iN55jcbO3w

Introducing yes&, the social platform built for creation. Creativity has never happened in isolation. A style. A pose. A sound. An outfit. We draw inspiration from the work we admire, then turn it into something new. But inspiration and creation have always lived in separate places. We save Pinterest boards, bookmark TikToks, screenshot Instagram posts, and fill our camera rolls with ideas, yet rarely turn them into creations of our own. AI changes that. On @yesand_ai, anything that inspires you can become a starting point. Discover great work, explore the prompts, skills, and creative process behind it, then remix it into something that’s yours. Every remix preserves the lineage of the idea and recognizes the creators who helped shape it. When creating becomes as simple as taking a photo, creativity naturally becomes social. Ideas evolve through inspiration, remixing, and co-creation. Today, @markusmak12 and I are excited to share that we’ve raised $3M in pre-seed funding, led by @Accel , with support from @parable_vc and an incredible group of partners, to build the infrastructure for collaborative creativity. Come make your next remix: https://t.co/FxQlg2ZTCn
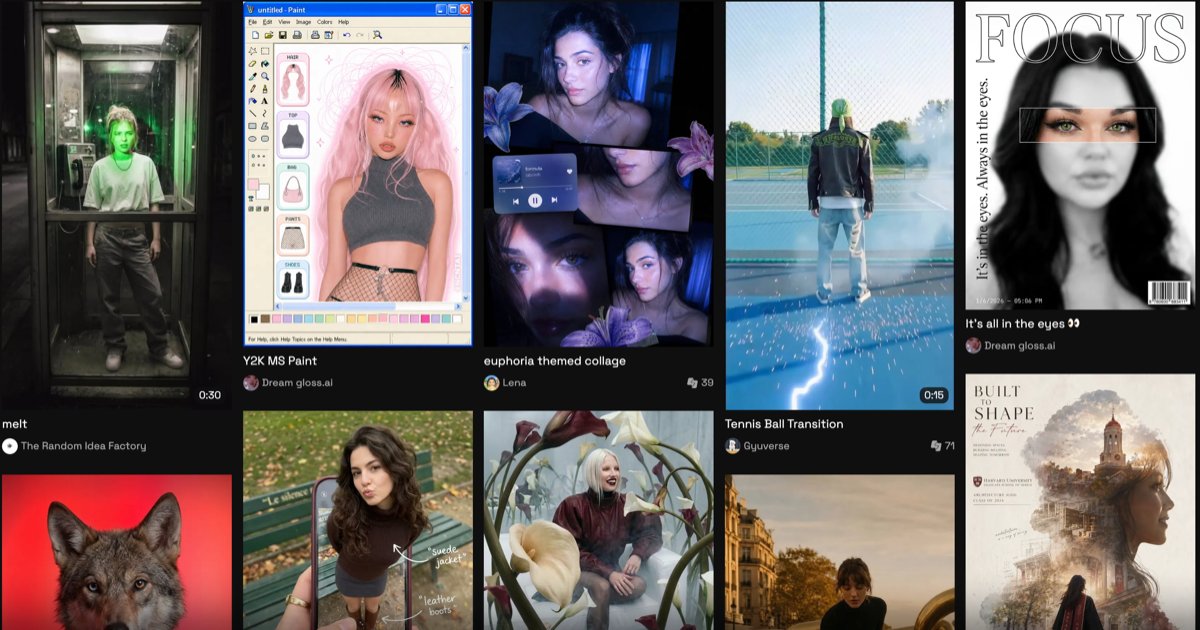
🎨 Introducing Genspark Design The next-gen AI for design and creation, powered by Claude Opus 4.7. From rough idea to professional design, no design background needed. - One tool for everything you design. UI prototypes, videos, HTML animations, posters — all in one place and production-ready. - Stay on-brand with your own design system. Upload your Figma files or save your designs, reuse them across every project, and share them with your team. - Ship it, don't just mock it. Turn any app or website design into working code with one click, built on Genspark Code. Start building at our launch price 👉 https://t.co/Fn9YJHgRx8
Introducing Hubble: the best notepad for you and your agents. - Feels like Notion or Apples Notes, but for Markdown - Live-reloading editor to collaborate with agents - Supports HTML-based apps to build interactive visualizations Free and open-source 👉 https://t.co/lJdHeTrSbt https://t.co/dEjoee8eas

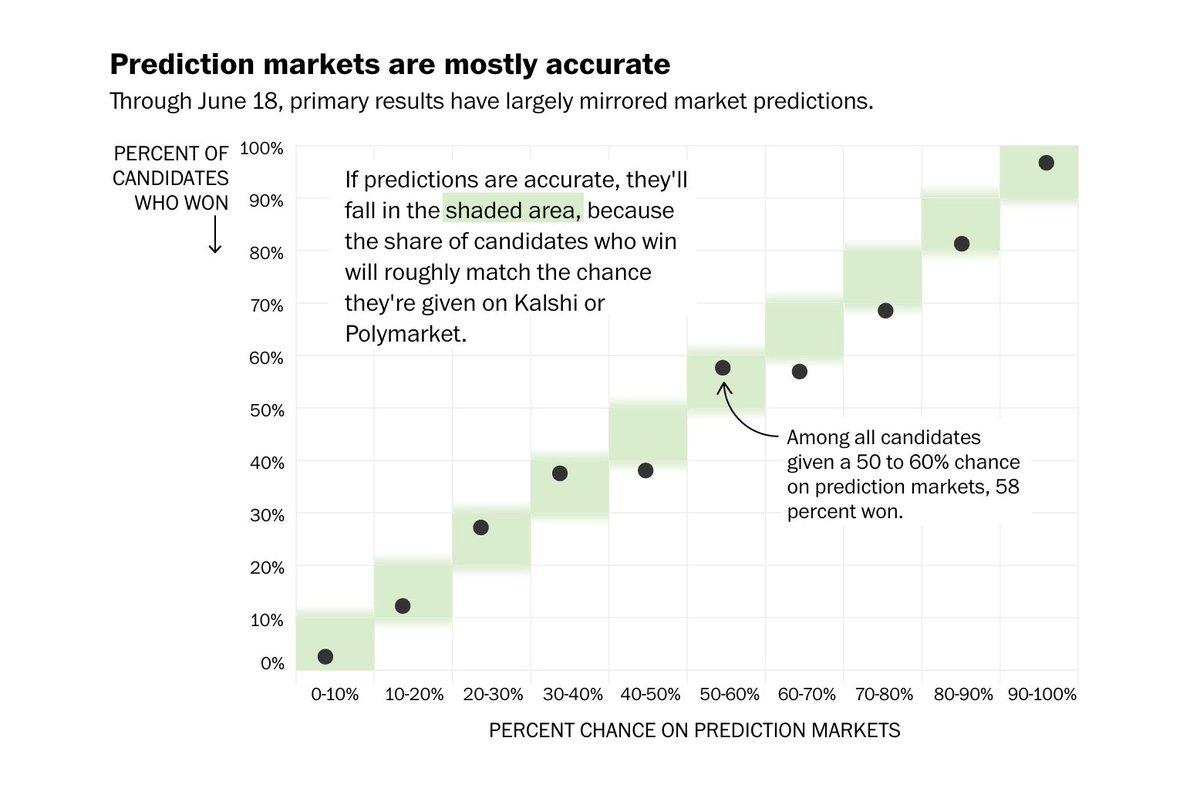
The Washington Post ran a comprehensive analysis on prediction markets across hundreds of primary races. https://t.co/sqLZD92kbS
@davefontenot @hf0 It was a great move. https://t.co/gW6GvQDtw7

@YahooNewsTopics https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

https://t.co/KTDtczuAa6


For years, Google was the starting point for finding information online. Now, for the first time in a long time, people have real alternatives. Google remains incredibly strong, but the emergence of AI assistants is changing user behavior in ways that are worth watching. https://t.co/wzXaL2m94b

Report: Female cop shoots Jewish rabbi outside Pornhub office in Canada while hiding from Marxist gunman who killed immigrant officer named Mohamed https://t.co/0XOk1IBVbG

@embirico https://t.co/IoNlALqPPL

Asmongold explains Keir Starmer's resignation using a WoW raid strategy and it makes perfect sense "Labour just performed a tank swap. Starmer had too many debuffs so they pulled him out and brought in a new tank." "The new guy is going to do the same thing for the same raid. They're tanking the same boss in the same way." "You're Onyxia. Don't fall for the tank swap. He's not the organization. You didn't win, they just reset your aggro."
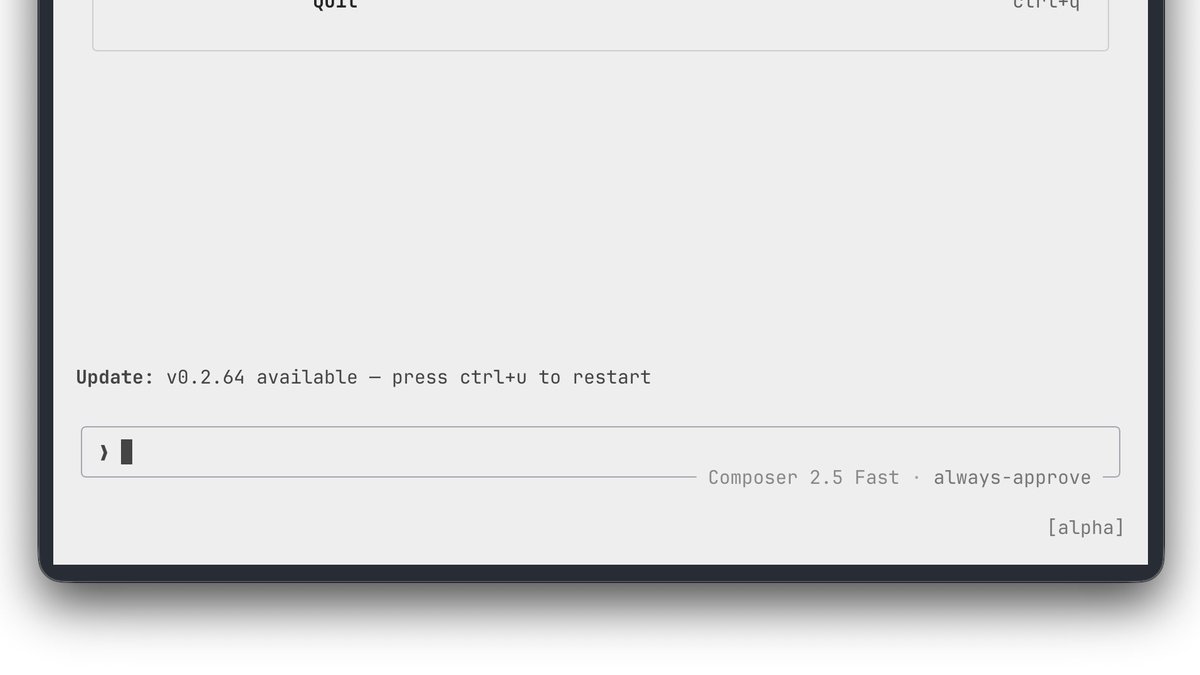
Grok Build just got another update with many improvements Release Notes: v0.2.64 — 2026-06-24 Features: • Dashboard now displays the current directory and branch; click or press Ctrl+L to change location, or Ctrl+W to dispatch new agents into fresh git worktrees. • /recap now appears as a collapsible tool-style block with a loading spinner while generating. Bug Fixes: • Dashboard arrow keys open agent details and exit overlays; closing an agent now selects the neighboring row. • /usage command and credit warnings are now hidden for API-key authentication. • MCP servers from your user config no longer appear labeled as project-scoped when running from your home directory.
Grok Build just got another update with many new features, improvements, and bug fixes Release Notes: 0.2.61 – 2026-06-22 Features: • Closing a terminal tab with a running process now shows a confirmation dialog instead of killing it immediately. • /usage now shows prepaid cred
@Exogynous @BrianRoemmele Come to the discord and we'll help make sure that works! https://t.co/5EoJ4EBecb

A single app model and a simplified local run loop. This Open Source Friday, we'll learn about @aspiredotdev: a code-first orchestration and observability layer for distributed apps, with a built-in dashboard for logs, traces, and metrics. Set a reminder 🔔 https://t.co/5FR2c6pKT0

Elon Musk just confirmed that ‘Starmind’ will be the official name of the SpaceX AI satellite constellation https://t.co/nwkRsIb4eq
People who are complaining that he spends the first half of the movie murdering white people not migrants fail to understand that it’s hammering home an important premise. “Always hang a traitor before you shoot an enemy” https://t.co/M3XkVmVlGu

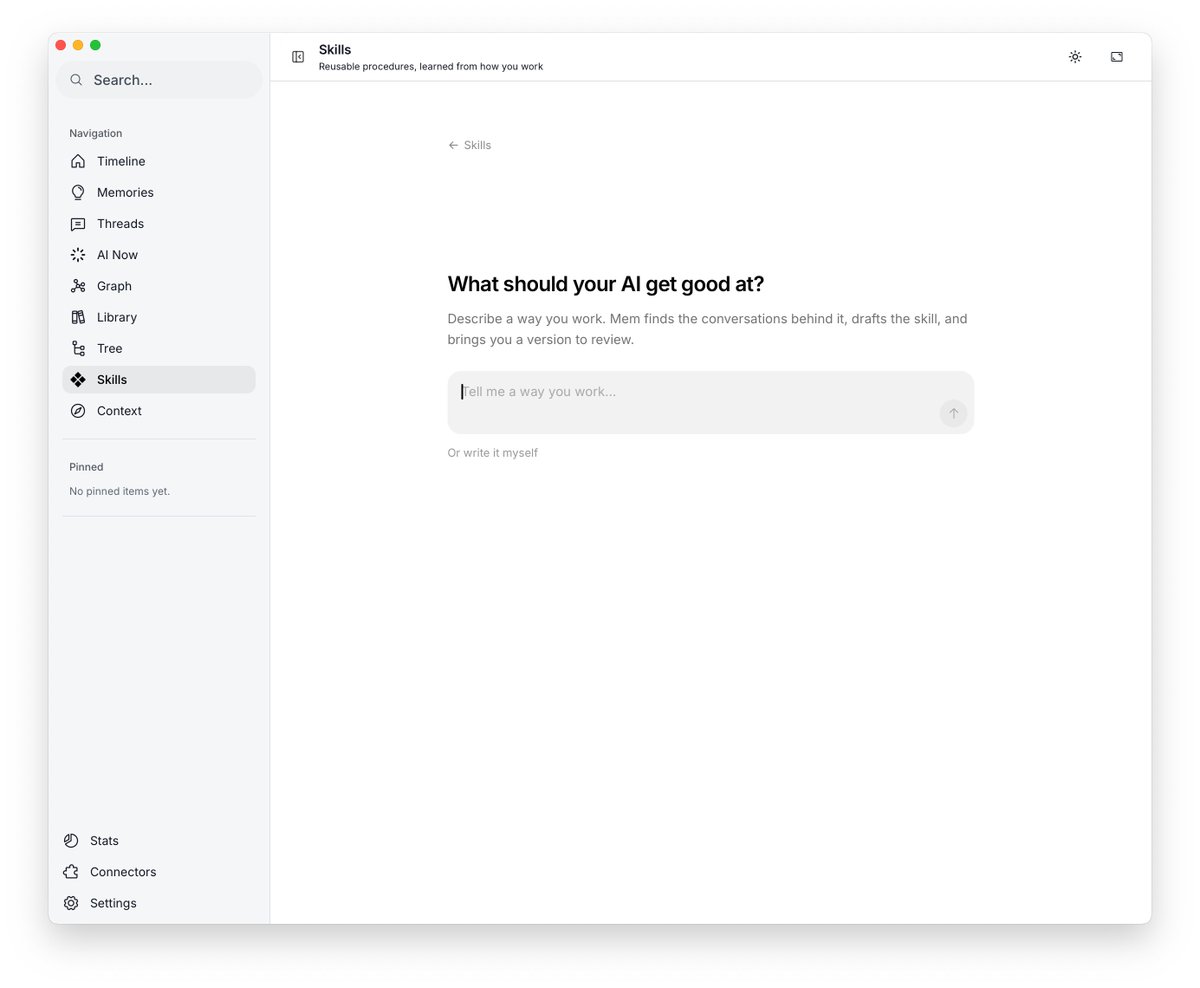
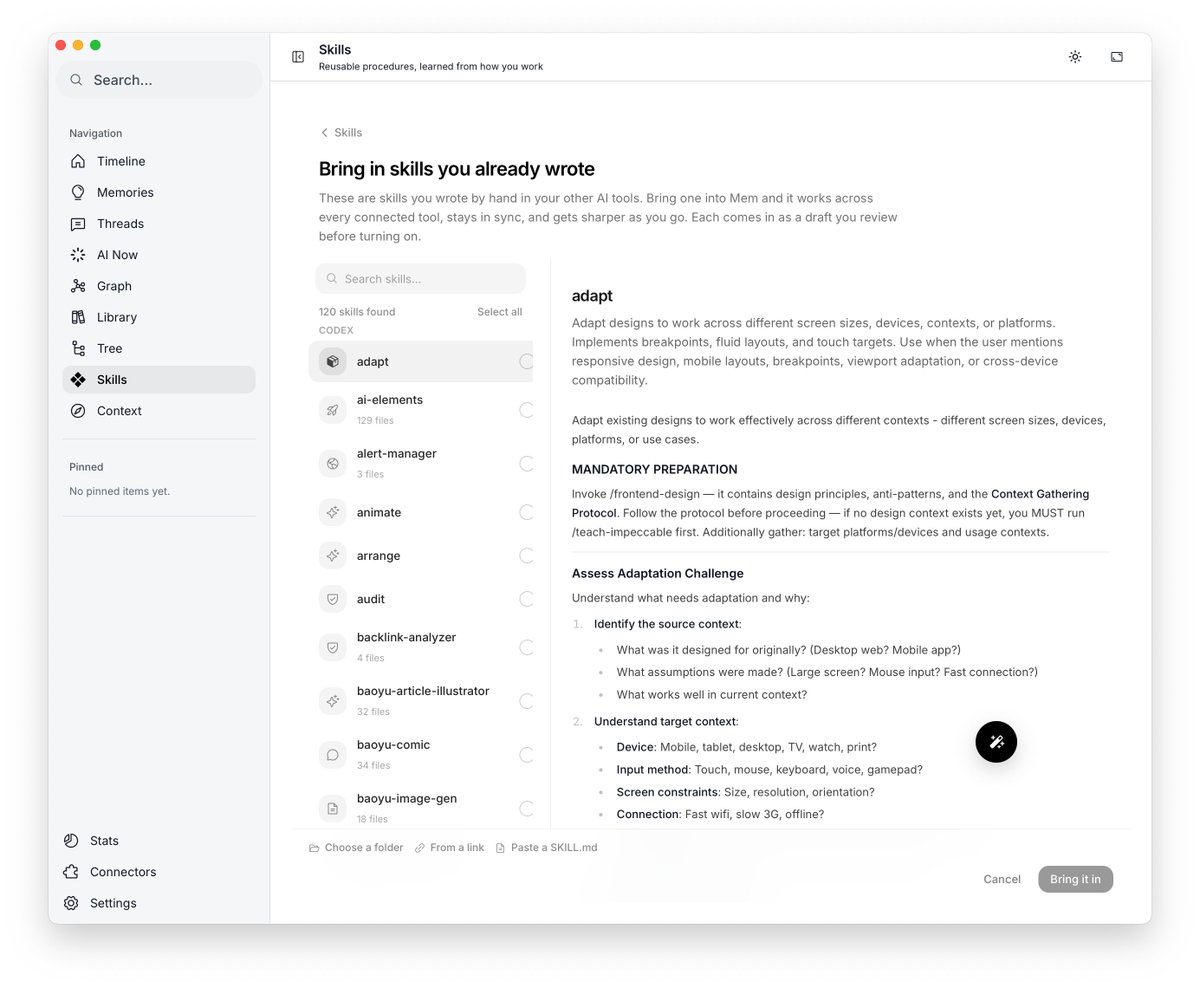
Hermes 引入了 /learn 从任何 input 习得可复用的技能🫡 Nowledge Mem 的 Skills 也有一样的能力 除了默默主动从历史上下文里摸索出可能潜在构成 skills 的机会提示给用户,用户激活之后可以在所有 agent 里调用,并且随着调用还会不断自优化、演进外; GUI 里的 Skill Creator 允许我们主动创建 Skill,它会自动找到相关的历史上下文进行创建和自优化。 其次我们根据用户老师们的建议,闭环了这个主动 flow,增加了 cli 和 ai-now 里的主动创建 Skills 的入口
Hermes can now LEARN from any source or set of sources, build a skill, test it live, and crystallize new learnings. Just run /learn and pass it sources, past sessions, URLs, docs, whatever you think will help it learn, and it'll go from 0 to 1 to create you a skill!
Made in London with AWS: Justina Chung, VP, @BessemerVP. Based in Bessemer’s London office, Chung discusses the AI advantage for startups looking to launch and build a business in the city. Through the company's partnership with AWS, she is able to help founders access infrastructure, compute, and expertise.
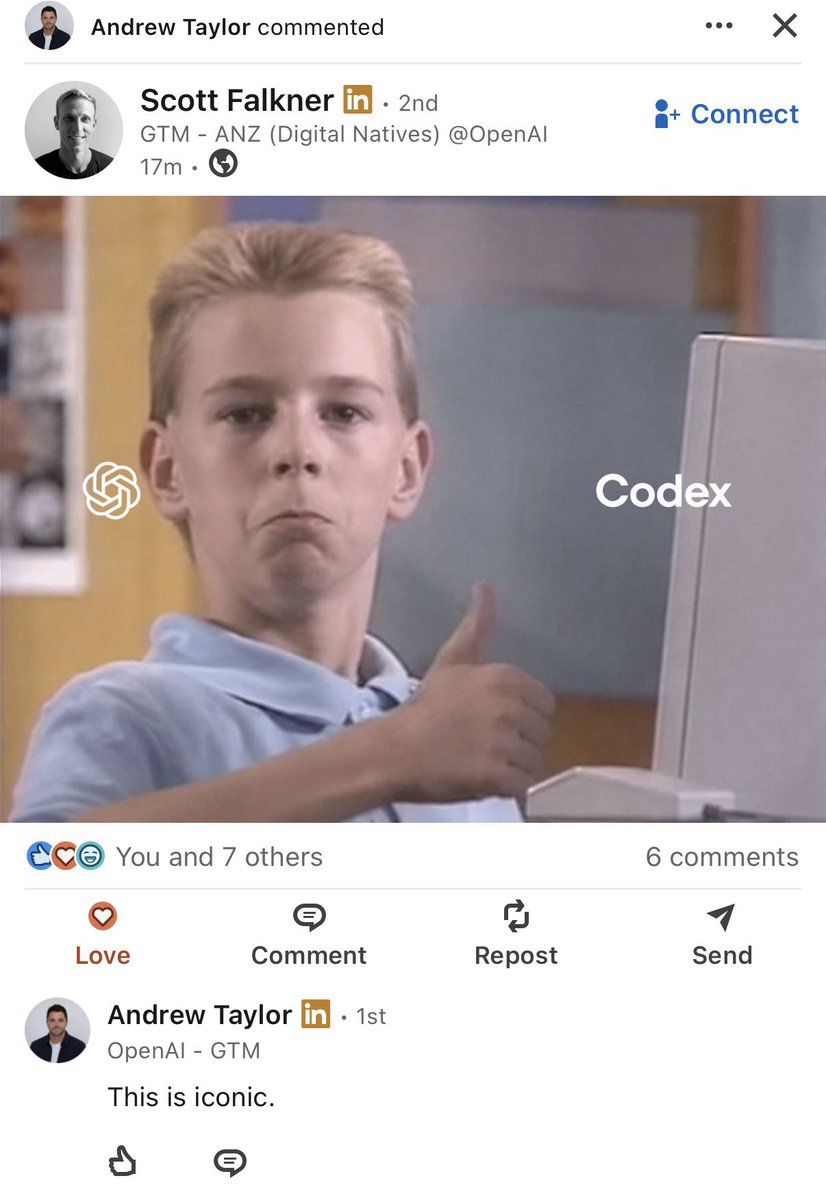
@jxnlco LinkedIn is starting to find it https://t.co/Sy4aMmbmqa
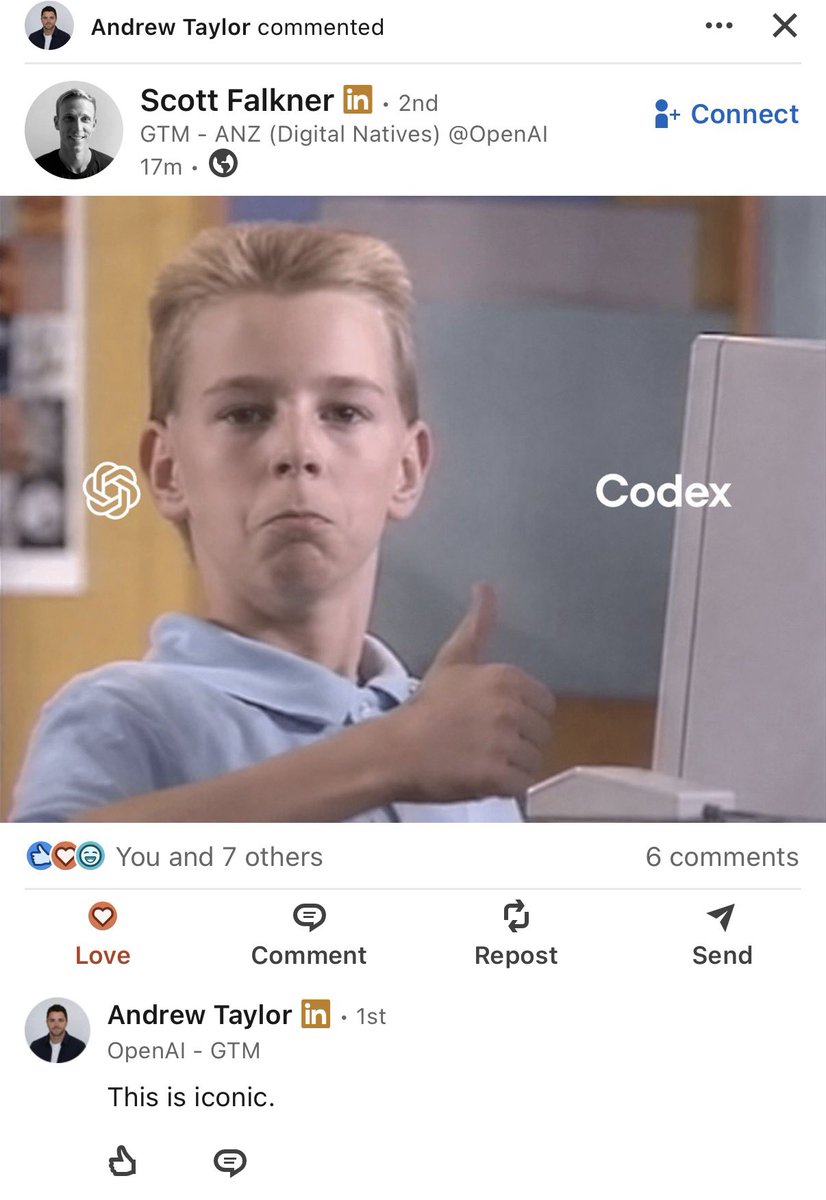
@jxnlco LinkedIn is starting to find it https://t.co/Sy4aMmbmqa