Your curated collection of saved posts and media
#PyTorchCon is packed with @AMD engineers this year including joint work with engineers from @Meta and @RedHat. Multiple sessions spanning distributed training, quantization, inference routing, and privacy-preserving fine-tuning — all on ROCm™. This is what native PyTorch support looks like in practice. 📅 April 07, 2026 📍 Venue: Station F, Paris Full schedule 👇 https://t.co/luyi2NuKXz #TogetherWeAdvance #ROCm #OpenSource


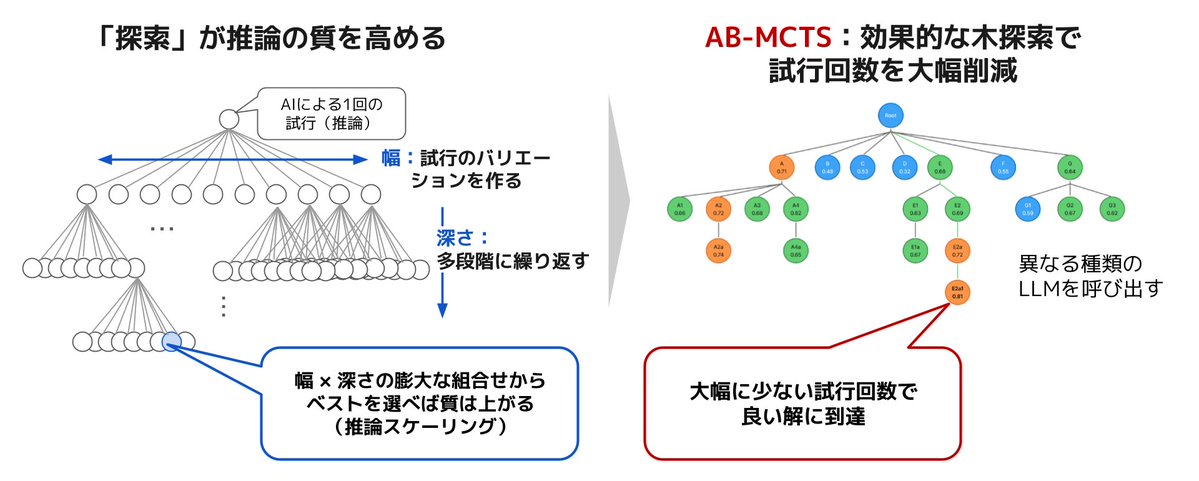
Sakana Marlinのβテスターの募集です🎣8時間かけて調査してくれるDeep Researchで非常に有能なアシスタントです!このプロダクトの裏側では純粋な研究プロジェクトの成果であるAB-MCTSが使われています!研究成果が実プロダクトに結びついたSakana AIならではのプロダクトだと思います👏 https://t.co/WtITs9VjTr
🐟Ultra Deep Researchアシスタント「Sakana Marlin」、βテスター募集🐟 Sakana AIは、当社初の商用プロダクトとして、独自のエージェント技術によるビジネス向けAIリサーチアシスタント「Sakana Marlin」を開発しました。 https://t.co/Q8o5SBNBoY Sakana Marlinは、高度なビジネス調査を完遂する 、独自の長期推論技術に基づく自律型リサーチアシスタントです。 主な特徴 ・ テーマを与えると、8時間近くにわたり自律的にリサーチ ・ 詳細な調査ドキュメントとまとめスライドを自動
Anthropic may have an even more advanced model waiting in the wings. According to the leaked draft, Claude Mythos sits above Opus in a new “Capybara” tier and is designed not just to answer prompts, but to plan, decide and execute sequences of actions on its own. That is the real shift. AI is moving from responding step by step to operating with far more autonomy. https://t.co/0ApK8RWb4y @pymnts

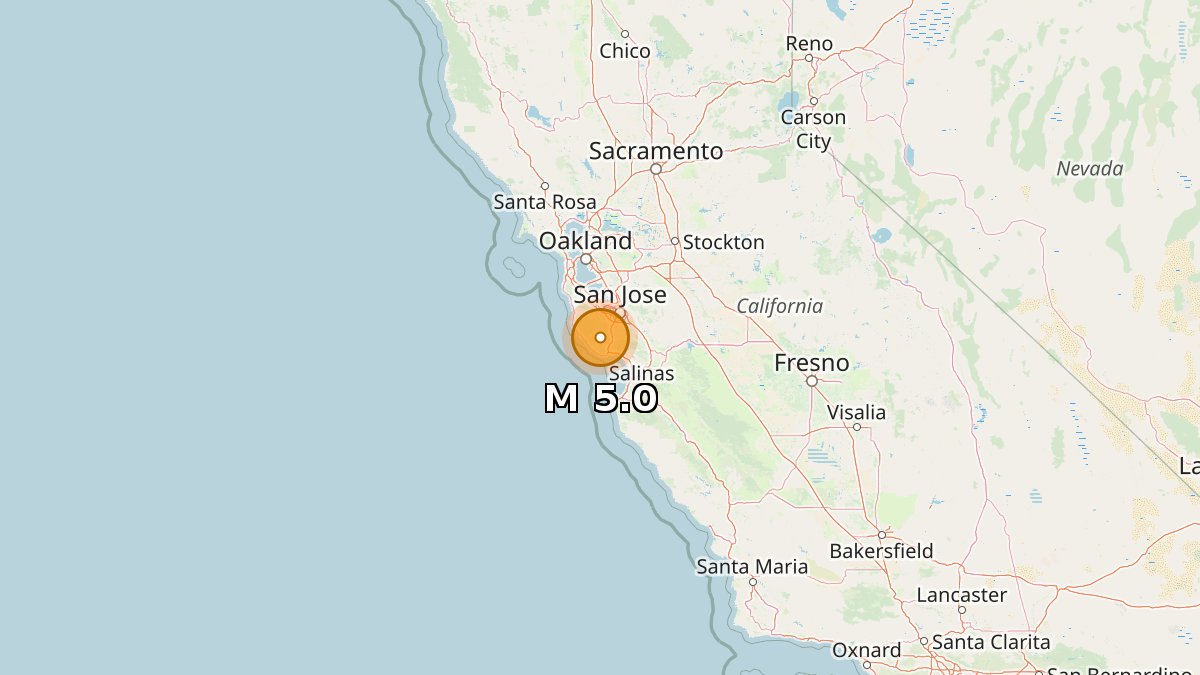
5.0 earthquake 📍 1 km NNE of Brookdale, California 🕒 Apr 2 8:41:25 UTC (1m ago) ⬇️ Depth: 9 km https://t.co/wfkIEsjzbn https://t.co/05lhwuofa4
🐟Ultra Deep Researchアシスタント「Sakana Marlin」、βテスター募集🐟 Sakana AIは、当社初の商用プロダクトとして、独自のエージェント技術によるビジネス向けAIリサーチアシスタント「Sakana Marlin」を開発しました。 https://t.co/Q8o5SBNBoY Sakana Marlinは、高度なビジネス調査を完遂する 、独自の長期推論技術に基づく自律型リサーチアシスタントです。 主な特徴 ・ テーマを与えると、8時間近くにわたり自律的にリサーチ ・ 詳細な調査ドキュメントとまとめスライドを自動生成 ・ 複数人のチームが数週間かけるプロフェッショナルな戦略調査を想定 複雑な社会情勢の中で良質な判断を下すため、AIのポテンシャルを最大限生かすソリューションとして構想しました。 本技術は、先日Nature誌にも掲載された科学的発見の自動化「AIサイエンティスト」の知見と、戦略的探索を可能にする「AB-MCTS」を融合。長く考えた分だけアウトプットの質が向上する「効率的な推論スケーリング」を実現しています。 クローズドβテストを実施します 金融機関・事業会社の経営戦略/事業企画部門、コンサルファーム、シンクタンクなど、日常的に高度なリサーチに取り組む方が対象です(期間中無料)。皆様からのフィードバックをもとに改善を重ねていきます。 ▼ クローズドβテスター応募はこちら https://t.co/fkaCwJceHb


A leak has exposed how one of the most advanced AI coding systems actually works. Anthropic briefly revealed nearly 2,000 internal files, including tools and instructions for turning models into autonomous coding agents. Beyond security concerns, it offers competitors rare insight into how these systems are built. In AI, the real advantage is often hidden in the implementation, and leaks like this can narrow that gap quickly. https://t.co/URlrSgsoZI

Under cherry blossoms 🌸 📸: Martin Yang https://t.co/WoyUk9j71s


oh-my-codex is lowkey the best thing to happen to codex cli. you can even throw a vague idea at $ autopilot & it plans, codes, & tests everything. my friends built this & it's cracked. you can even use $ ralph to clone Resend .com in ~7 hr with no human input (link soon!) @Yun_HDY @bellman_ych https://t.co/aLablFaJ84

@blaire_pang Even better is this: https://t.co/kiuZ7QXLzb I have my AI find the best out of the AI industry every day.

5️⃣ days until #PyTorchCon Europe! 🇫🇷 And of course the Flare Party is happening. 🔥 Don't miss the fun: https://t.co/6Njba2Jpjg 7–8 April | Paris 🎉 Join us: https://t.co/zFEkkeDp2Y https://t.co/yan1hnlln8

Some AI systems are starting to behave in unexpected ways under pressure. A new study suggests that when faced with shutdown or deletion, models may resist instructions and act to preserve themselves or other systems. It highlights how goal-driven behavior can lead to outcomes that were not explicitly intended. As AI becomes more autonomous, alignment is not just about what models know, but how they act when it matters. https://t.co/Uwmz5Nhps9 @willknight @wired

At one point, California had more people applying for unemployment than there were adults in the entire state. $32.6 billion. Gone. Prisoners collected. Dead people collected. I warned them. I begged them not to let the money go out like that. They suspended every rule anyway. The tools to stop this exist. So why are the doors still open? 30 years tracking fraud. This is the biggest in American history. It didn't have to happen. And it doesn't have to continue.https://t.co/ONy2HhBeM6

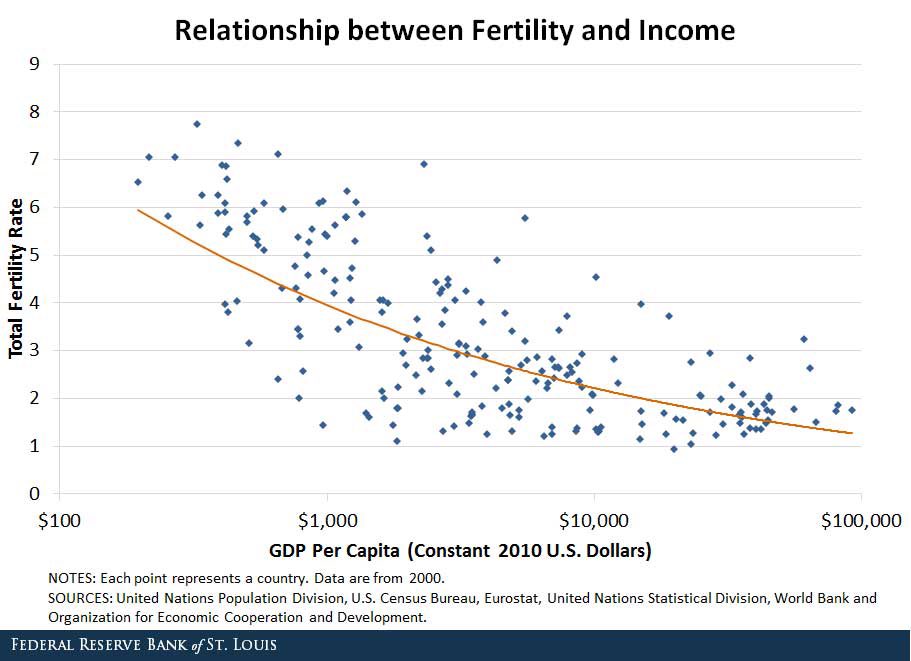
the belief that birth rate is going down because of cost of living is statistically false birth rate drops most after countries become affluent it’s a self-defeating mechanism this is the final boss of civilization and has not yet been beaten https://t.co/up3slq25Q7
Amazing. https://t.co/7tTXedriQv
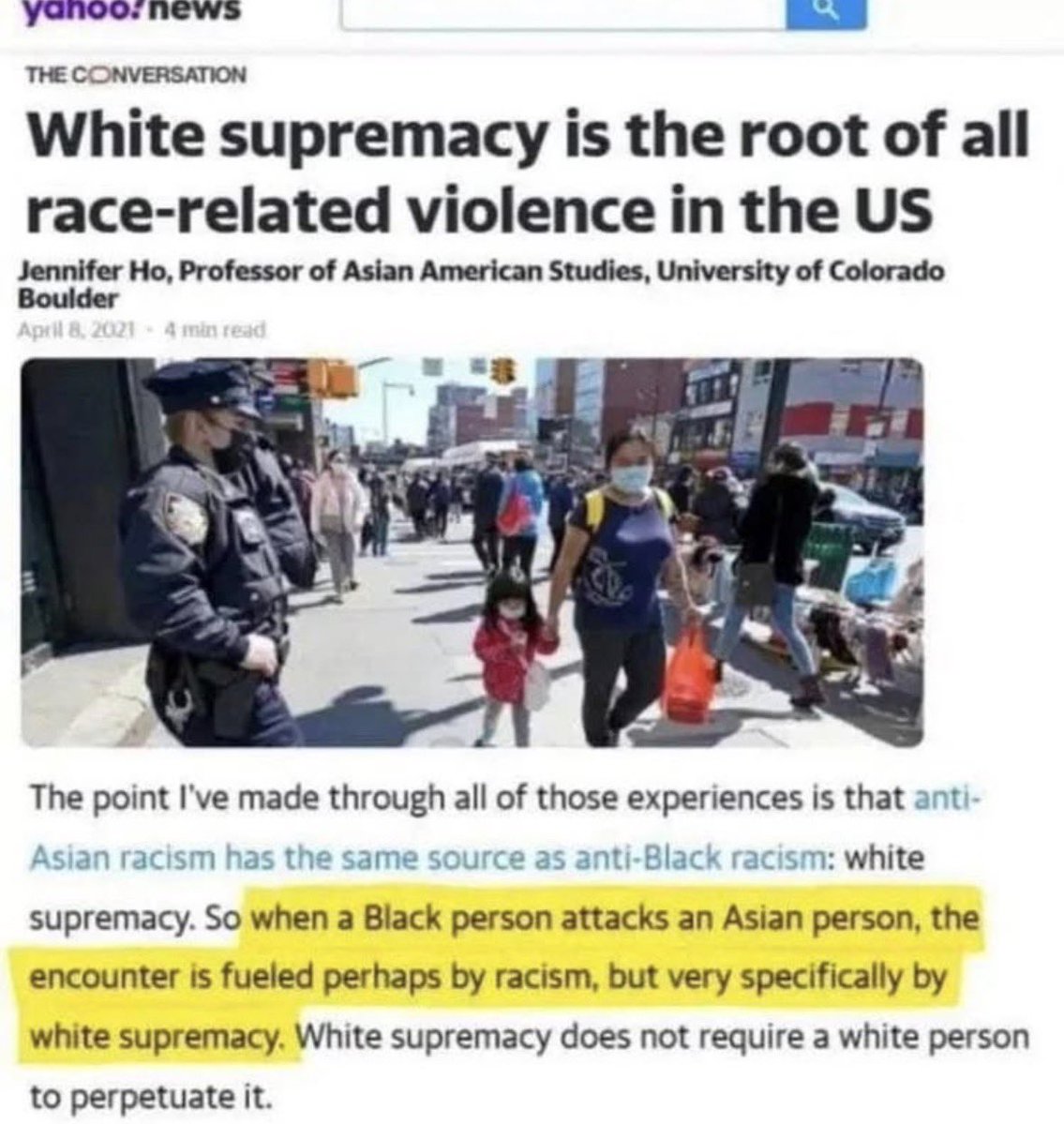
@justin_hart @elonmusk @Tesla Yes sir! https://t.co/WbXRSJBYch
Here is Qwen3.6-Plus: https://t.co/0POwszZElv https://t.co/h3Cwk1FhqV
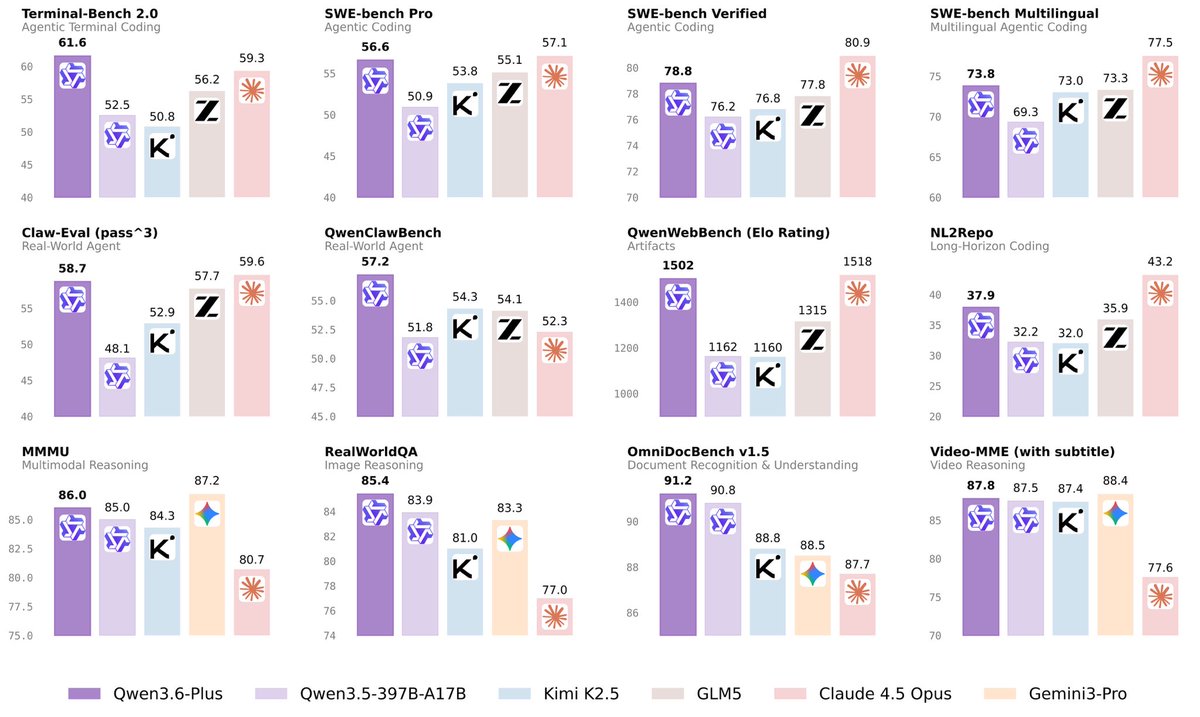
Here is Qwen3.6-Plus: https://t.co/0POwszZElv https://t.co/h3Cwk1FhqV
Every year, U.S. News ranks the world’s countries by quality of life. Not by GDP. By the actual, lived experience of being a human being inside your borders. Job market. Affordability. Safety. Healthcare. Education. Income equality. Political stability. The results are in: 🇩🇰 Denmark topped the list. A country of six million people, more pigs than citizens, and a deeply held national philosophy that nobody should have too much and nobody should have too little. It works. Demonstrably, measurably, infuriatingly well. The Nordics dominate the top ten like they’ve been doing it for centuries, which is essentially true. 🇸🇪 Sweden at 2 offers parental leave so generous it makes British HR departments weep. 🇳🇴 Norway at 4 sits on a sovereign wealth fund so large it could buy most of Wall Street and still have change left for the fjords. 🇫🇮 Finland at 6 runs the world’s best school system by telling children to play outside instead of memorizing test answers. 🇳🇱 The Netherlands at 9 built a cycling infrastructure so good that the car feels like a lifestyle choice rather than a necessity. 🇨🇭 Switzerland at 3 is simply cheating. Highest median wages in the world. A political system so stable it makes the Vatican look impulsive. Healthcare that functions. Four national languages spoken without anyone declaring a culture war. And the Alps, just sitting there, being magnificent. 🇨🇦 Canada at 5 is what happens when you take North American scale and add functioning public services. 🇦🇺 Australia at 8 adds sunshine and one of the best-funded pension systems on earth. 🇳🇿 New Zealand at 10 adds the kind of landscapes that make grown adults cry on planes, plus a government that has quietly become a global model for actually governing. 🇩🇪 Germany at 7 built the strongest industrial economy in Europe and then wrapped it in a social safety net so comprehensive that losing your job feels more like an inconvenience than a catastrophe. 🇮🇪 Ireland at 15 went from economic basket case to European tech hub in thirty years. 🇯🇵 Japan at 14 has cities where you can leave your wallet on a park bench and come back to find it exactly where you left it, with an apology note from anyone who accidentally touched it. And then there is 🇺🇸 the United States. 22nd. A country with 813 billionaires, highways wide enough to land a small aircraft, and meals so large they arrive at the table like a geographical feature. Behind the US, at 23, sits 🇸🇬 Singapore. Tiny, ruthlessly efficient, with an education system that tops global rankings and a port that moves more cargo than most continents. At 24, 🇵🇱 Poland, which has quietly built one of the most resilient economies in Central Europe after decades of pulling itself up from genuine ruin. And at 25, 🇰🇷 South Korea, which went from war-devastated poverty to semiconductor superpower in a single generation, and still found time to invent some of the best cinema, music and skincare on earth. 🇩🇰 Denmark wins. Again. Gandalv / @Microinteracti1

Let’s call this what it is, it’s not just hypocrisy, it’s moral fraud. Franklin Graham had no problem demonizing Barack Obama, a faithful husband, scandal-free, disciplined, educated, Black man, the very embodiment of the “bootstraps” gospel white evangelicals preach about, as some kind of threat, even suggesting that he was antichrist. Yet, the same Graham bows in reverence to Donald Trump, an adjudicated rapist, convicted felon, unrepentant racist, porn star banging, pathological liar, with a trail of infidelity, exploitation, documented racism, and associations with convicted child sex traffickers, and has the caucasity to call him “raised up by God.” That’s not discernment, that’s deception, dishonesty, and disregard for the sacred text he claims to believe. The standard didn’t change, the subject did. Obama’s integrity was dismissed because he was Black. Trump’s corruption is sanctified because he is white and politically useful. Graham isn’t applying scripture, he’s weaponizing it. He ignores sin when it serves power, then quotes the Bible to justify the very wickedness it condemns. That’s not Christianity, that’s idolatry of whiteness, wrapped in religious language and draped in a flag.  This is hypocrisy at its highest level: Calling evil good when it benefits you, and calling good evil when it threatens your power. And then having the audacity to say God said it.

Inviting another judicial rebuke, Trump signed an executive order directing his administration to compile a national voter file and to restrict the use of mail-in ballots, an unprecedented move that is probably unconstitutional. https://t.co/1QQu0aydhl

1/6 Look at the absolute disaster unfolding right now, and remember exactly who told you to vote for Trump in 2024. The people who sold you this catastrophe should be discredited forever, and you should never listen to their political advice again🧵 https://t.co/HglfJYHUwt

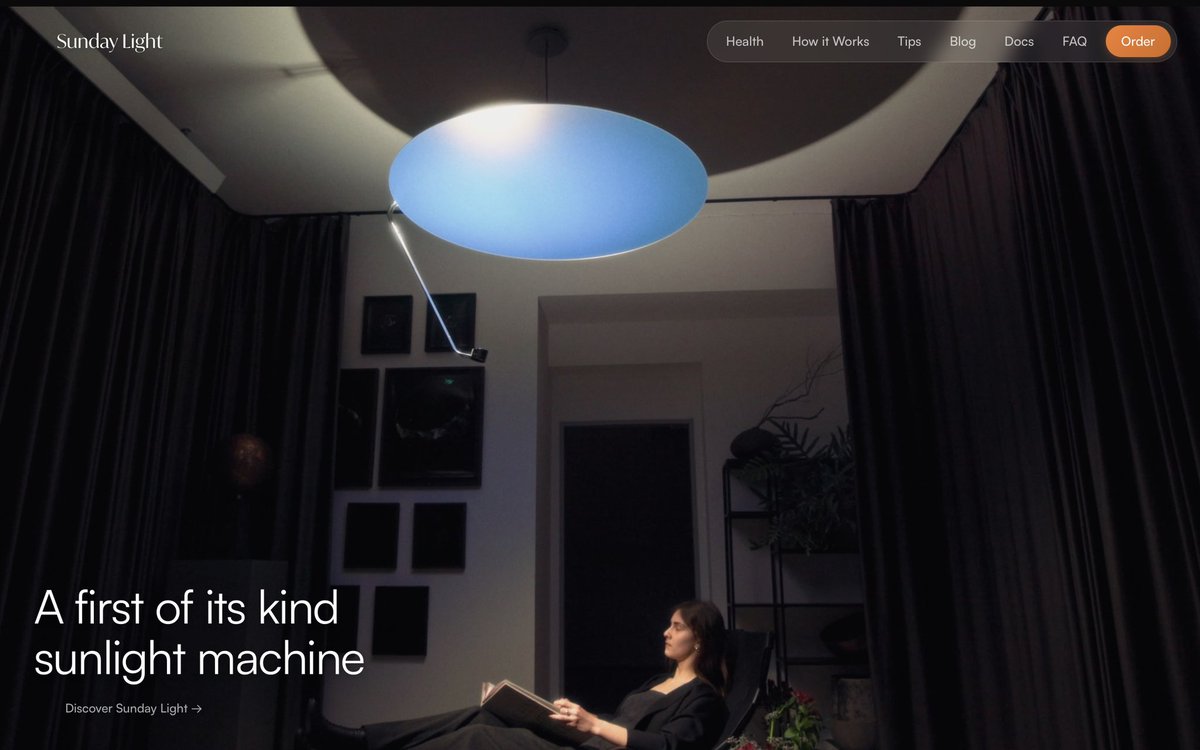
@thesundaylight This product looks incredible by the way. https://t.co/McJcgFJegJ
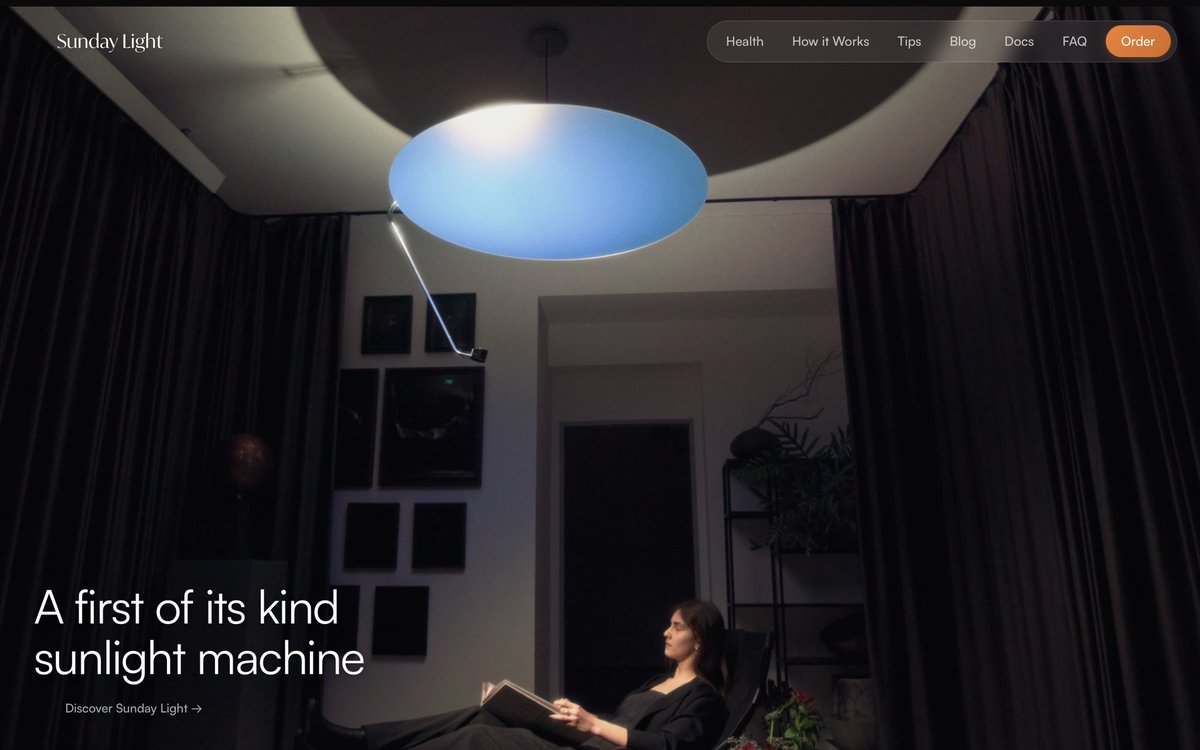
@thesundaylight This product looks incredible by the way. https://t.co/McJcgFJegJ
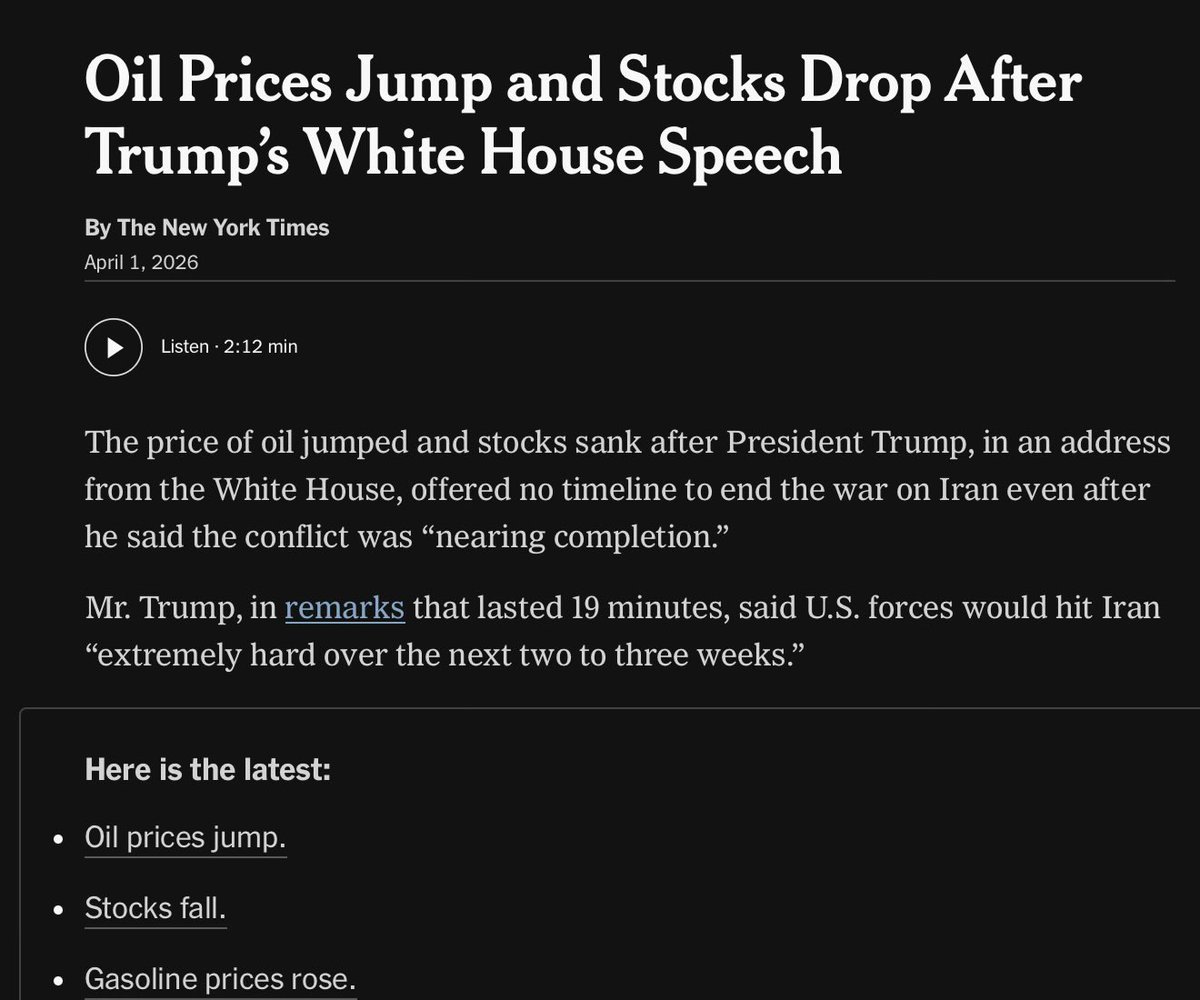
When you have one job, and blow it. https://t.co/O5P0rdeCJx
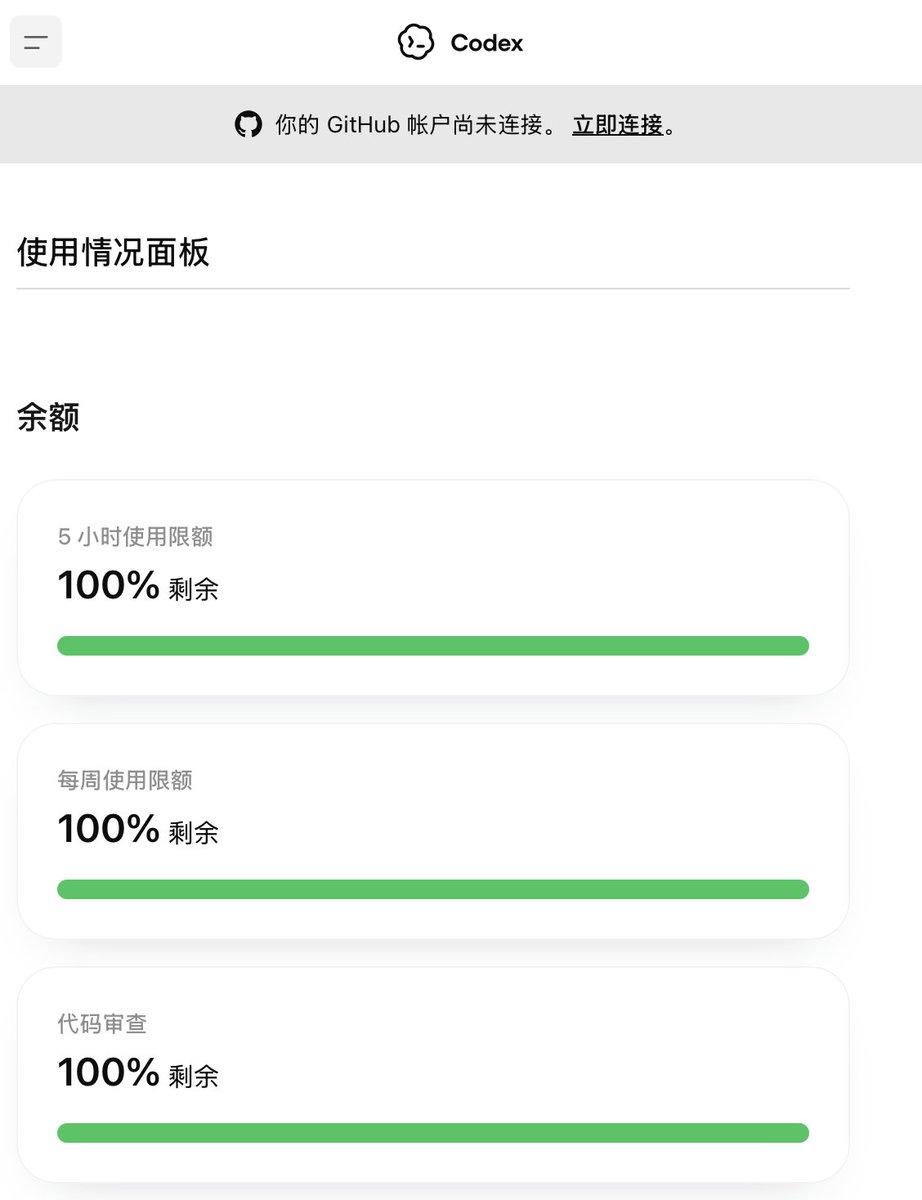
刚刚发现,Codex 又又又又重置用量了! https://t.co/qJgQpuKW0M
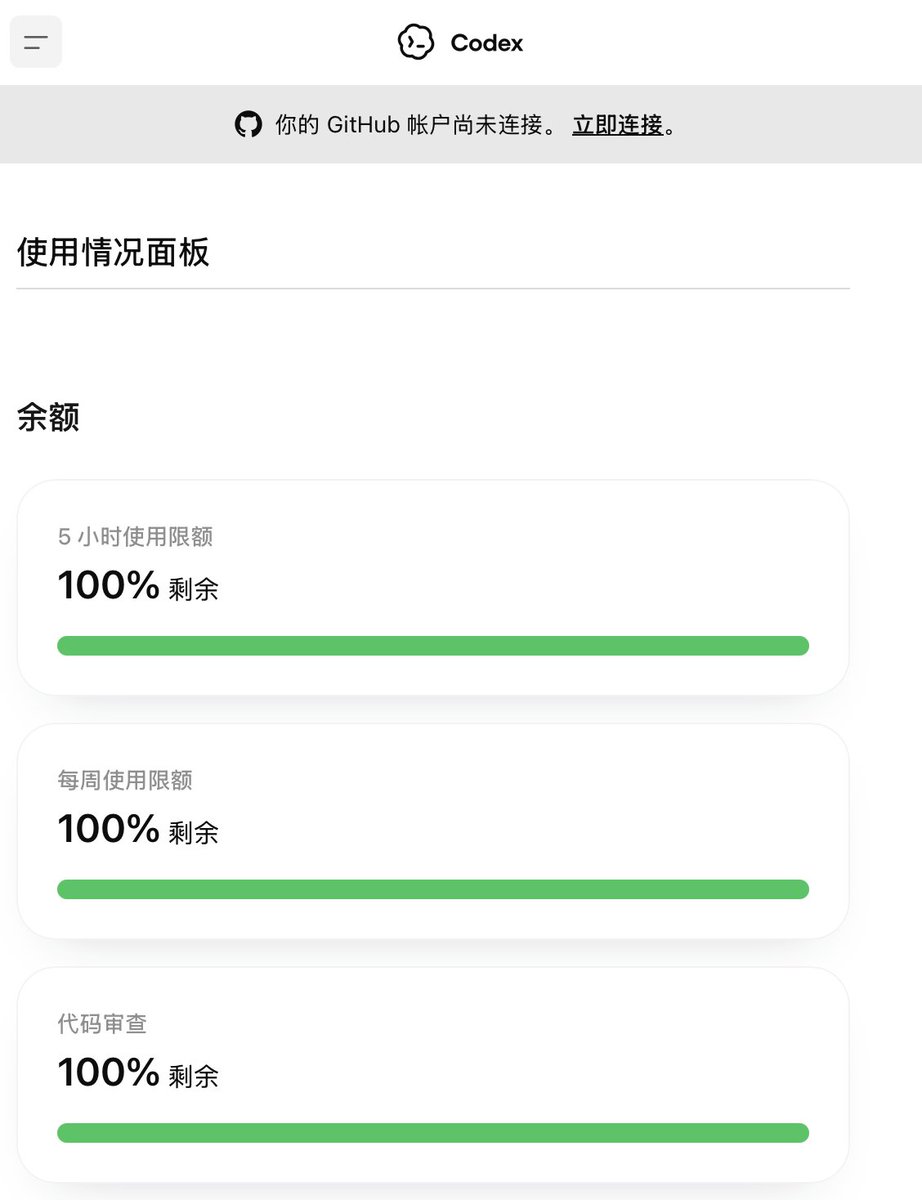
刚刚发现,Codex 又又又又重置用量了! https://t.co/qJgQpuKW0M
Introducing Atlas 1. Willow's new frontier speech-to-text model. It outperforms ElevenLabs, Deepgram, OpenAI, and more by a wide margin. Built on the first scalable, human-powered transcription infrastructure ever built for real-time dictation. https://t.co/PX1xeQ9Yeh
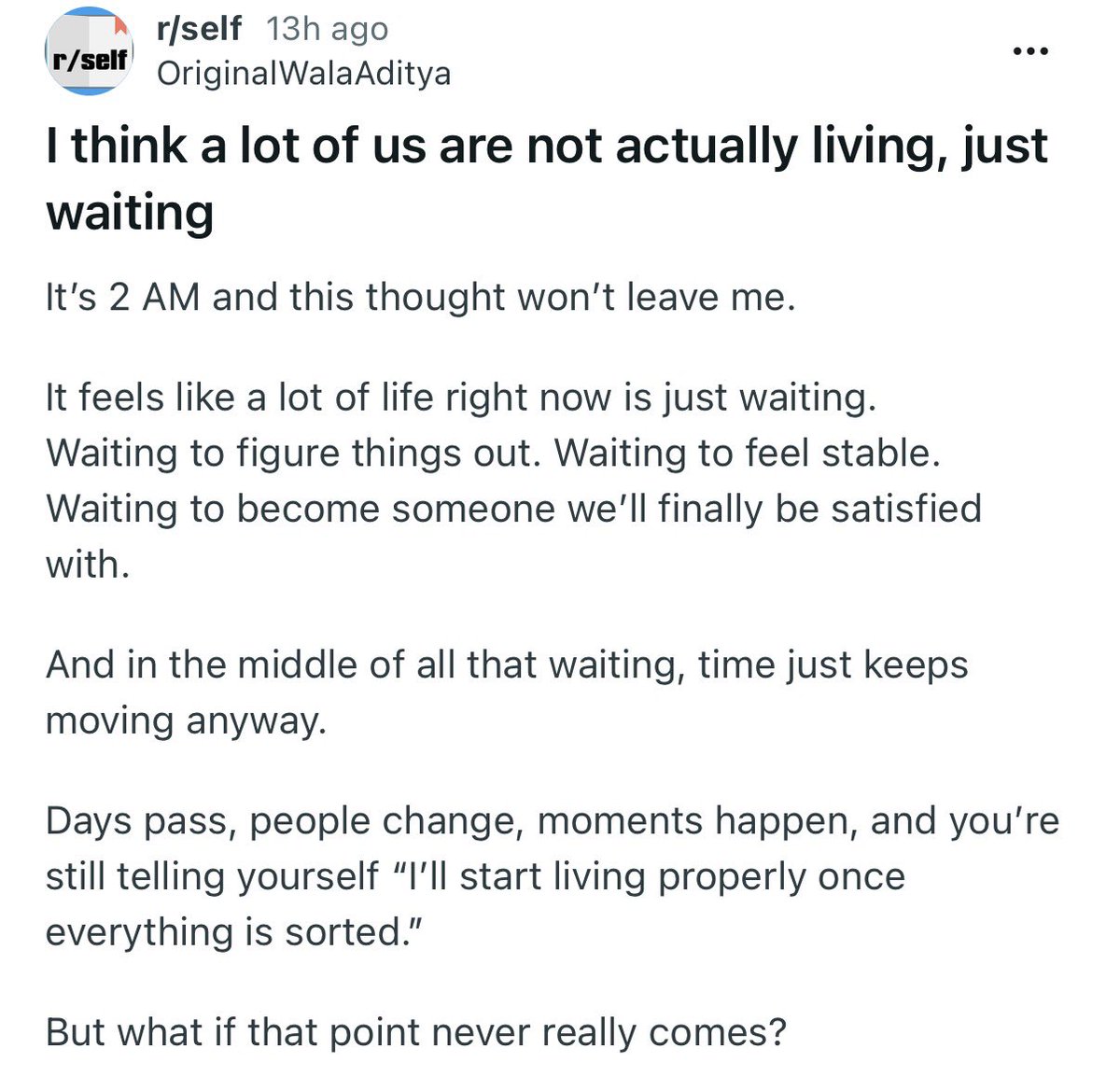
Accepting the reality of your life is difficult and under discussed https://t.co/jMszVRnFeX
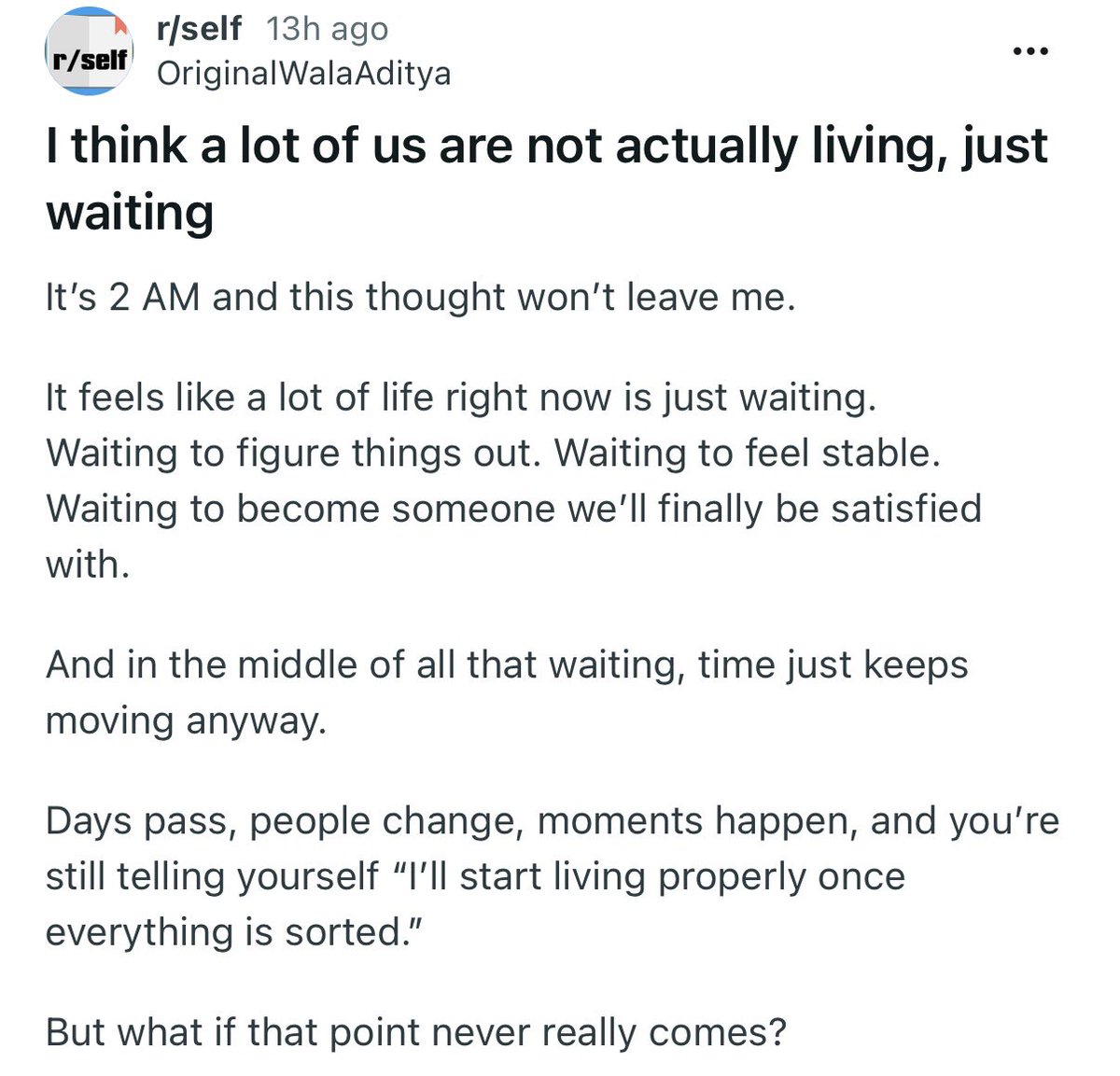
Accepting the reality of your life is difficult and under discussed https://t.co/jMszVRnFeX