Your curated collection of saved posts and media
We’ve partnered with Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. Together we’ll use Mythos Preview to help find and fix flaws in the systems on which the world depends. https://t.co/FnnhSkPLNQ

Mythos Preview has already found thousands of high-severity vulnerabilities—including some in every major operating system and web browser. https://t.co/YuW484PVrr
I love X. Over the last 19 years I built a set of lists of the tech industry. That's at https://t.co/tQxJhXvAUE And what can you do with lists? So much. Have @Pokee_AI or your favorite AI agent platform (Pokee includes the X API in as standard feature so you don't have to pay extra). On Saturday I had it watch my Climate list and make an app where it showed all the storms across America. That took a few minutes. I also built a separate app that watched my news lists (about 14,000 people and organizations) and made me an app to watch news about the Iran war. Lists are the secret. They are purified content for your AIs to use to build new kinds of apps. Like this one, which shows you the best from the AI community here on X: https://t.co/8L5xphk0qQ That site could not exist without lists. Why? The X API won't let you find everyone in the AI world (that site reads tens of thousands of posts from 40,000 people and 8,300 companies every day). I spent thousands of hours making the lists and give them to you for free. No one has a set of lists of tech and news like I do, so if you don't use my lists your apps won't be as good, at least about AI and tech (I have a list of all the world news outlets too). And these lists can do a number of things. My site creates a script so you can have @NotebookLM create you a podcast from today's news, for instance. Thanks to the many subscribers I have. I don't do much extra for them but they subsidize my work, which is expensive (I'm spending about $300 a day on X API charges to build Aligned News, something I can't do forever, so my agents are now helping me send notes to investors over on LinkedIn to shake the tree to see if there's some real business here making custom news and market analysis. Something else you can do with my lists. After all, I have lists of more than 10,000 investors here, so AI can tell you about investing trends, and a lot more too. I now get why Elon bought X. AI lets you get a lot more value out of X and in a way very few have really explored. If you are using AI to build new ways to look at X, let me know.
ICYMI https://t.co/ROAfxDUUIV https://t.co/vHn5nfA3Km

ICYMI https://t.co/ROAfxDUUIV https://t.co/vHn5nfA3Km
GLM-5.1 is available on the @huggingface 🔥 https://t.co/NUaGYBgIa6 ✨ MIT license ✨ Better at handling long, complex tasks than GLM-5 https://t.co/xDVPdqJnia

GLM-5.1 is available on the @huggingface 🔥 https://t.co/NUaGYBgIa6 ✨ MIT license ✨ Better at handling long, complex tasks than GLM-5 https://t.co/xDVPdqJnia

@aayushchugh I will be honest. Your posts aren’t what it is looking for. I built an AI to find the best on X in AI world: https://t.co/8L5xphk0qQ and in the process learned what X is looking for. It shows me mostly AI news now. But the real problem is that there are 1000x more posts than anyone can read. If reach is your goal you have to play a different game.

Made a small website about my favourite book for a friend https://t.co/4ZiFU6VG35

This repo is making history 🔥 100,000+ stars in less than 24 hours. OhMyCodex + ClawCode just became one of the fastest growing repositories in GitHub history. This is next-level agentic coding: - Team mode - Ralph mode - Auto de-slop - ClawHip for fully autonomous workflows They’re literally building and refactoring entire repos from an airplane, using only their phone and OpenClaw. AI coding is moving at insane speed right now. Stay tuned. #AICoding #AgenticAI #OhMyCodex https://t.co/rP1UgB3Kfs
@LifeArtStudios Yes! The world is hurting with so much change and new things to try and build that it is easy to ignore health. It is one reason why I built https://t.co/kiuZ7QXLzb so that I could keep up without doom scrolling all day long

Releasing the alpha of Unreal Robotics Lab — an open-source Unreal Engine plugin with full MuJoCo physics. Photorealistic rendering and accurate contact physics. No compromises on either side. GitHub: https://t.co/GAvwsncqtG Paper: https://t.co/w8sbILR7dW https://t.co/EHcfGfdYZB

@suni_code All the best AI news from X: https://t.co/kiuZ7QXLzb

New blog post: converting 30k @arxiv papers to Markdown using SOTA OCR models to enable chat with paper functionality Includes: > leveraging an open OCR model (Chandra 2 by @datalabto) > running on GPU infra - @huggingface Jobs > using Codex with a SKILL.md https://t.co/jrpin9oq5u

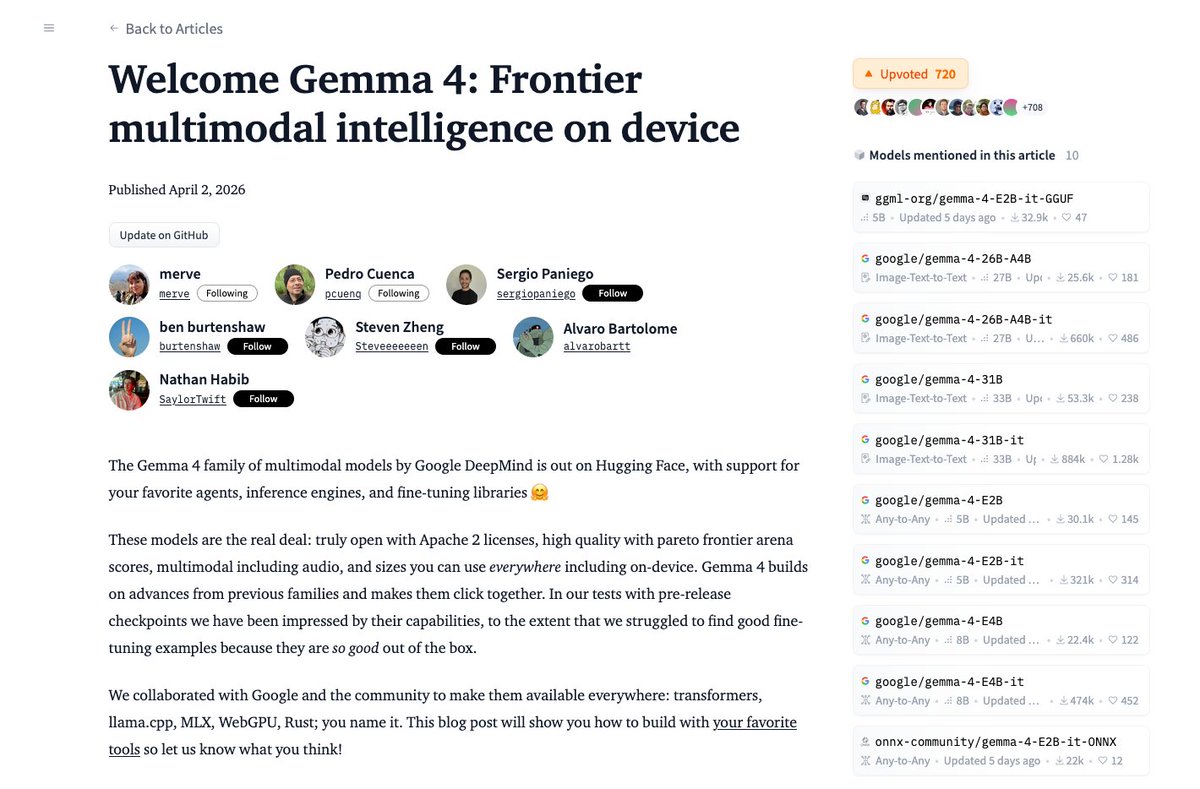
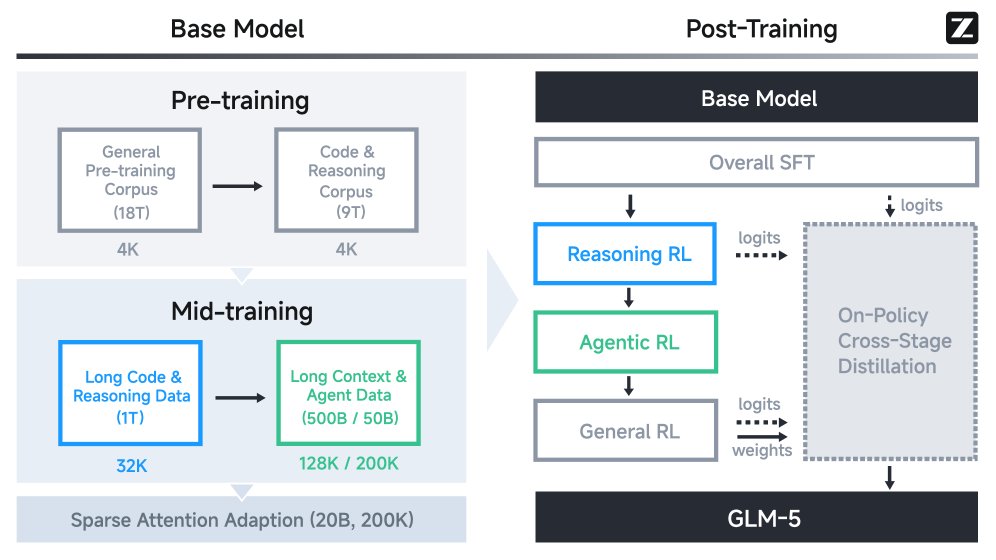
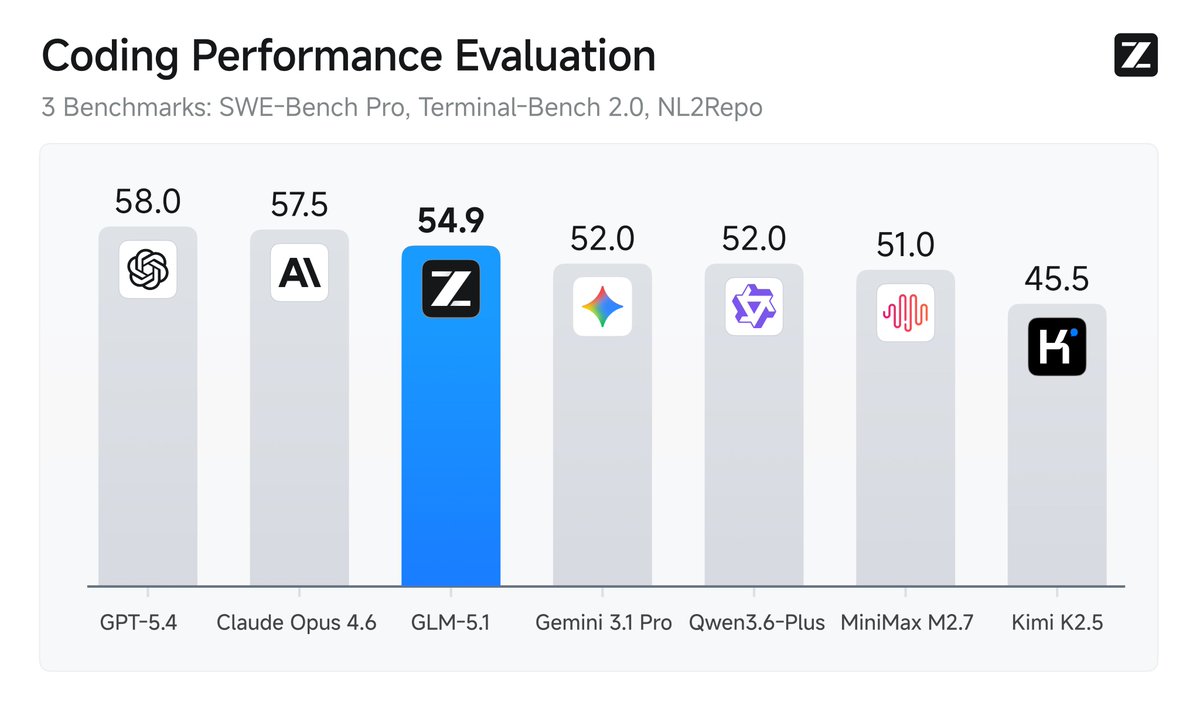
Zhipu AI just released GLM-5.1 on Hugging Face A 744B parameter agentic engineering model with state-of-the-art coding capabilities. Achieves SOTA on SWE-Bench Pro and excels at long-horizon terminal tasks. https://t.co/Un5Ywa18FI
ACE-Step 1.5 XL🎵 New open music generation model is now on @huggingface Model: https://t.co/JzjqmaDDND Demo: https://t.co/ZjetgIdwOe ✨ 4B DiT - Base/Sft/Turbo ✨ MIT license ✨ Commercial-ready: legally compliant datasets ✨ Full support: Text2Music, Cover, Repaint, Extract, Lego, Complete


ACE-Step 1.5 XL🎵 New open music generation model is now on @huggingface Model: https://t.co/JzjqmaDDND Demo: https://t.co/ZjetgIdwOe ✨ 4B DiT - Base/Sft/Turbo ✨ MIT license ✨ Commercial-ready: legally compliant datasets ✨ Full support: Text2Music, Cover, Repaint, Extract, Lego, Complete

Intel is proud to join the Terafab project with @SpaceX, @xAI, and @Tesla to help refactor silicon fab technology. Our ability to design, fabricate, and package ultra-high-performance chips at scale will help accelerate Terafab’s aim to produce 1 TW/year of compute to power future advances in AI and robotics. It was fun hosting @elonmusk at Intel this past weekend!

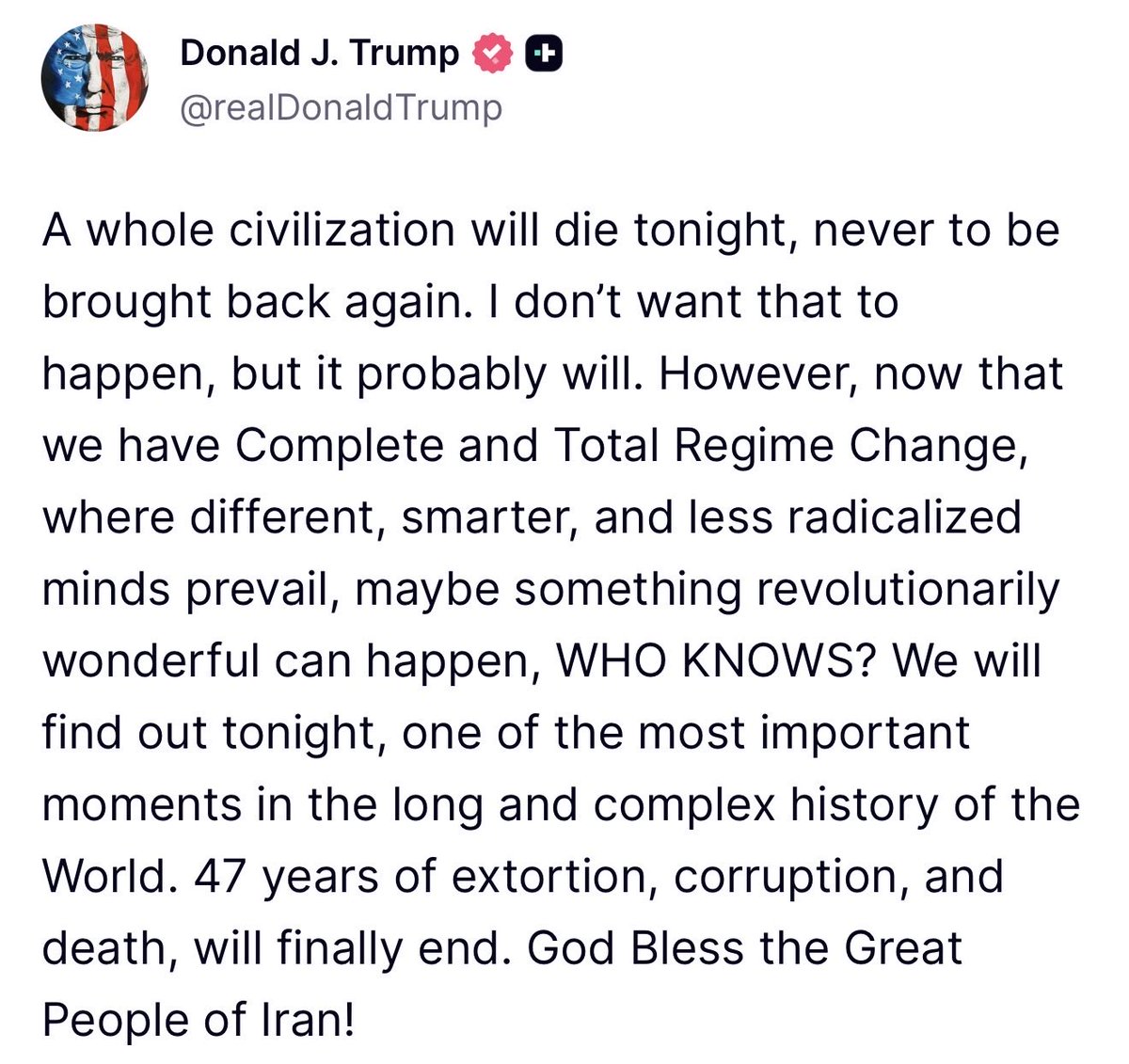
Trump on Iran this morning: “A whole civilization will die tonight, never to be brought back again” https://t.co/MW2e3zUGvk
introducing superset the IDE for the AI agent era stop waiting on coding agents run them in parallel https://t.co/wJcHmynG35
We're excited to be rolling out two model updates today! Marble 1.1: Improves lighting and contrast, with a major reduction in visual artifacts. Marble 1.1-Plus: Our new model built for scale. Create larger, more complex environments than ever before. https://t.co/pslqVXNqFa
@GaryMarcus Yes: https://t.co/5NUmnm43sA

The best performing model on SWE-Bench Pro is open-source on @huggingface! Welcome GLM 5.1! https://t.co/EiLk2zx4Sw https://t.co/Bw8uRE2ccK

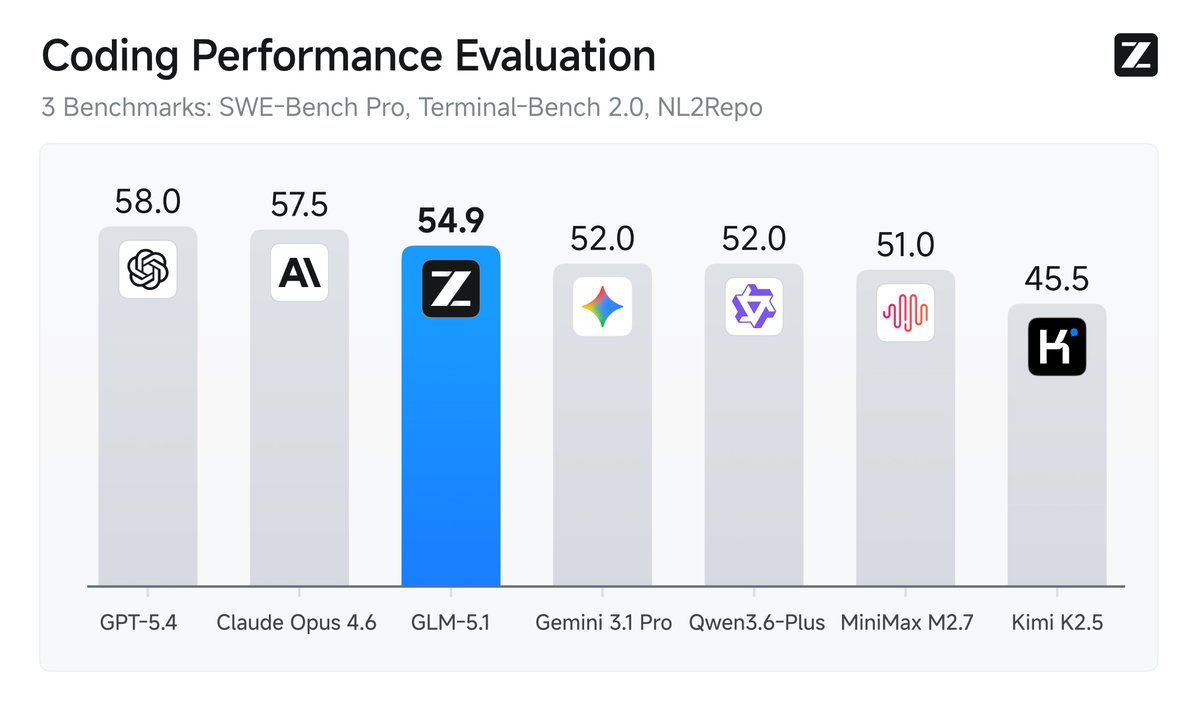
GLM-5.1 is out on Hugging Face #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations model: https://t.co/EY2rHngjYp

The best performing model on SWE-Bench Pro is open-source on @huggingface! Welcome GLM 5.1! https://t.co/EiLk2zx4Sw https://t.co/Bw8uRE2ccK
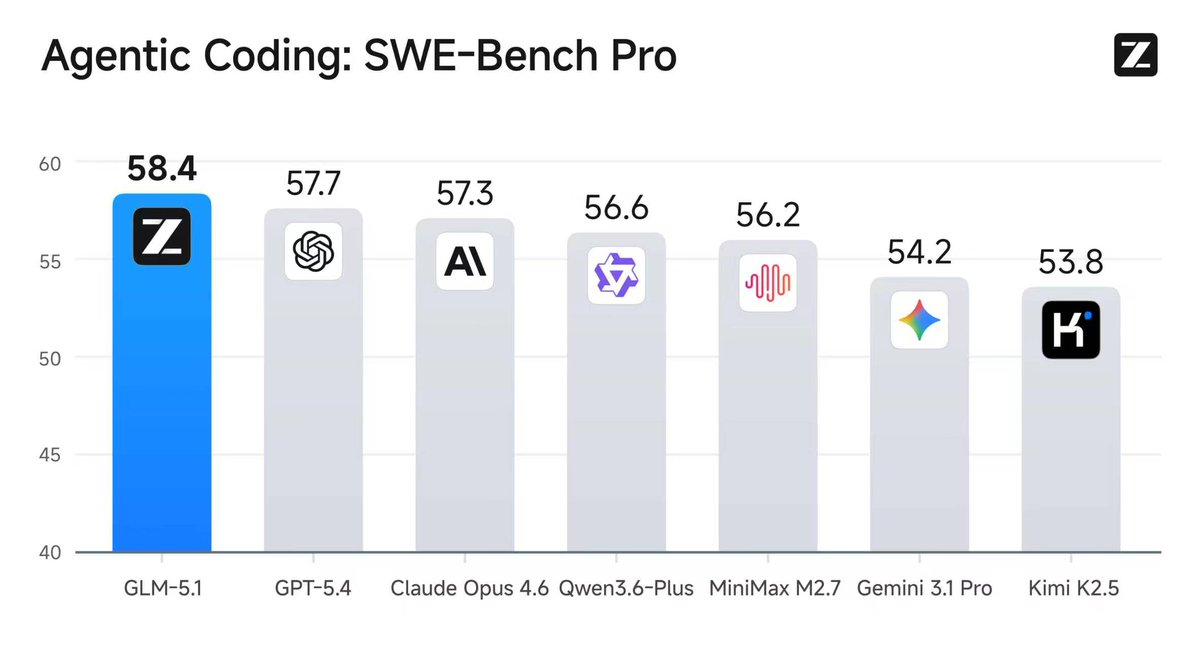

The best performing model on SWE-Bench Pro is open-source on @huggingface! Welcome GLM 5.1! https://t.co/EiLk2zx4Sw https://t.co/Bw8uRE2ccK

Introducing GLM-5.1: The Next Level of Open Source - Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo. - Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations. Blog: https://t.co/hmyDe4Nel3 Weights: https://t.co/CuUjXcPKJD API: https://t.co/fz6reja4fb Coding Plan: https://t.co/Nk8Y98HNhU Coming to https://t.co/WCqWT0qCQb in the next few days.

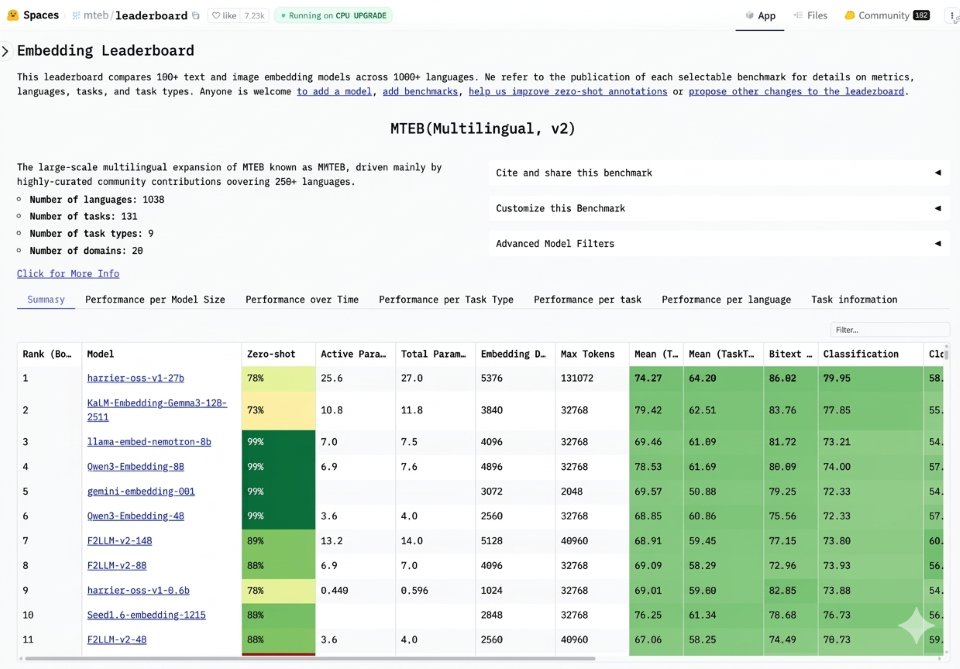
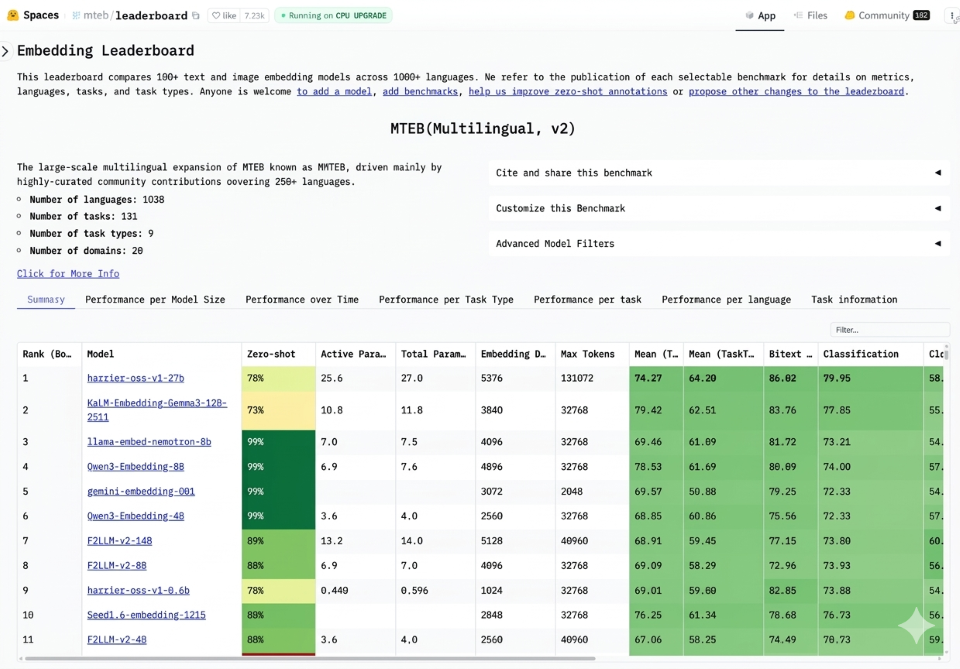
I’m pleased to share that our search team has open sourced an embedding model called Harrier that is currently ranking #1 on the multilingual MTEB-v2 benchmark leaderboard. Harrier delivers SOTA performance on retrieval quality, semantic matching, and contextual analysis across workloads, supporting more than 100 languages and handles long inputs up to 32K. It is built for the next generation semantic search for Bing and our web grounding (RAG) service for AI agents, which already powers nearly every major AI chatbot today. As you can see in the leadership board, our Harrier model is currently ahead of other excellent models based on Gemini, Gemma, Llama, Qwen, and more. I’m grateful for the hard work of our team to get to this top ranking, and I’m excited to see all the healthy competition in the space, which should ultimately lead to more innovations that will benefit everyone. Learn more: https://t.co/tvEvCzk7Mf
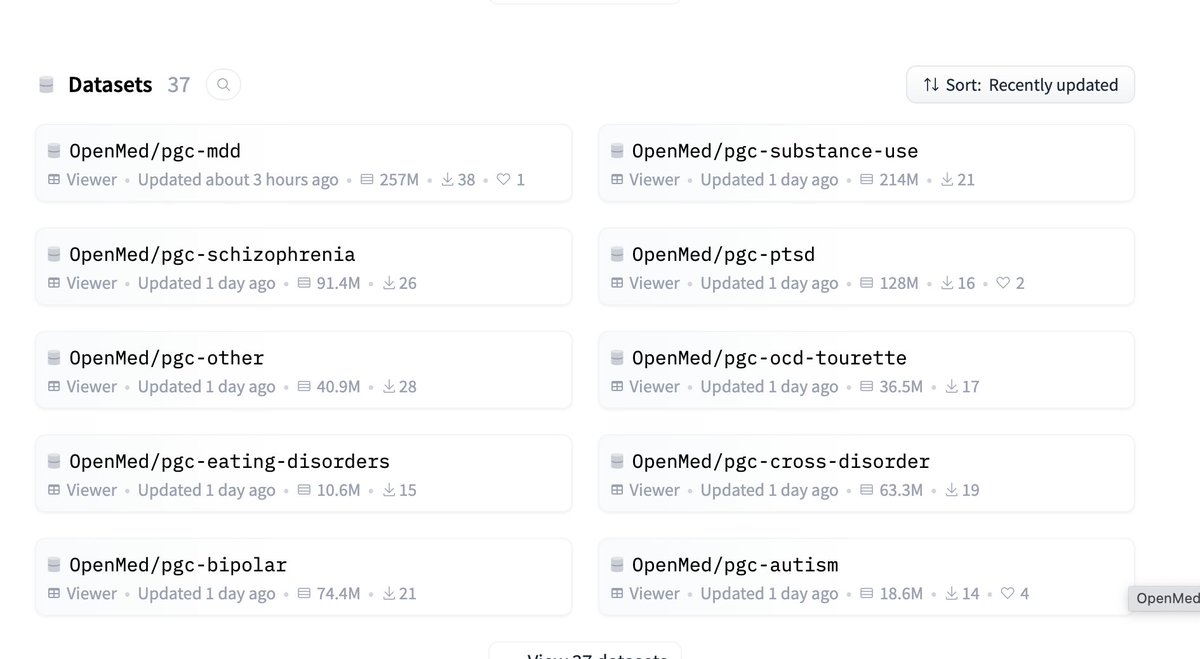
🚨 Over 1 billion rows of psychiatric genetics data. Now on Hugging Face. ADHD. Depression. Schizophrenia. Bipolar. PTSD. OCD. Autism. Anxiety. Tourette. Eating disorders. 12 disorder groups. 52 publications. Every GWAS summary statistic from the Psychiatric Genomics Consortium. Before: wget, gunzip, 20 minutes debugging separators, repeat 50 times. Now: one line of Python.
just added openmed data on @huggingface, what else https://t.co/eyiQ9RmfrJ
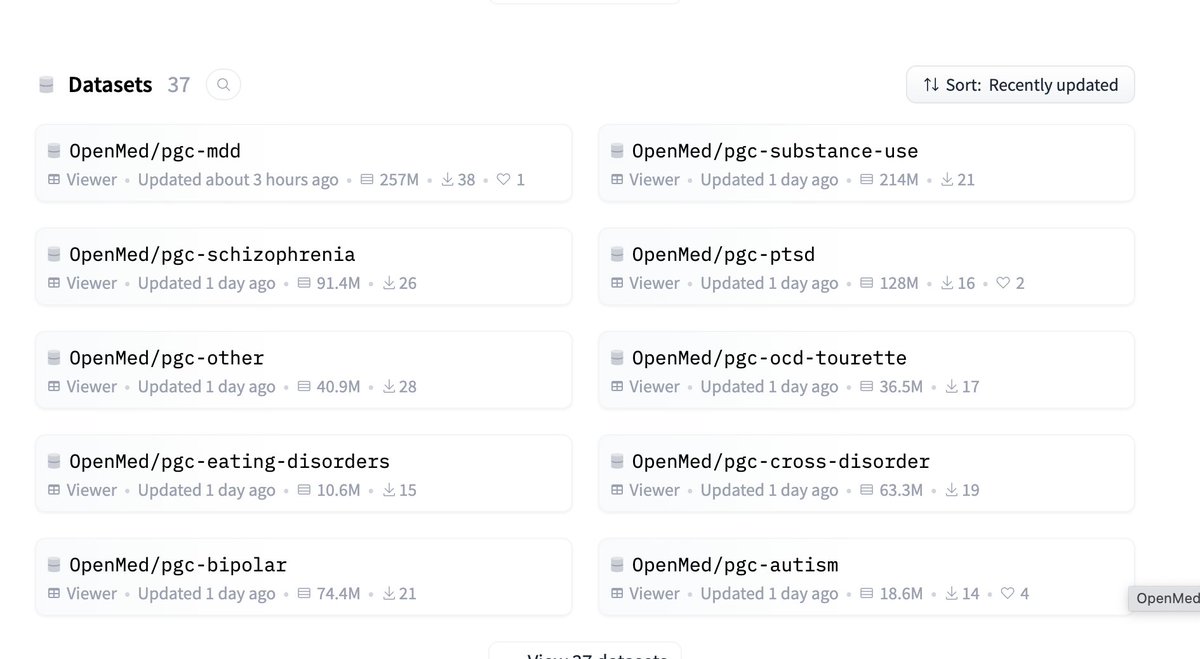
just added openmed data on @huggingface, what else https://t.co/eyiQ9RmfrJ
Tomorrow at @tensorwave's Beyond Summit: our VP of Engineering Mostafa Hagog shows how we run the same codebase on NVIDIA and AMD. 4.1x image gen speedup. 99% lower cost per image than Nano Banana. Stop by Mostafa's talk at 2 PM tomorrow: https://t.co/tB9oS3Hruc https://t.co/47a2b3nadQ
