Your curated collection of saved posts and media
Brand new to the GitHub Copilot app? We got you covered! Start building something awesome in seconds with app ideas from the home screen. Pick something that resonates with you, send the prompt, watch Copilot create a folder, scaffold the project, and open the built-in canvas browser. Experience Autopilot and Auto model selection that routes to the best available model based on the request. When you are done ask for it to create you a repo on GitHub, pick and polish the UI, or add more fun features. Shout out to @RamsesCabello for adding this feature!
🚀✨ GitHub Copilot App v1.0.14 released! 32 features & enhancements in this release Top features: • Added /init slash command to generate or improve a repository's Copilot instructions file 📄 • Introduced /model and /models slash commands to open model picker or select a model b
My first test of Fable 5 on some hard reasoning tasks (induction) didn't go so well. 5/5 responses are "" after billing 128k tokens. Glad I didn't run the full 375-problem benchmark. How many tokens does it need to return anything other than ""? https://t.co/paZfTvZGZW https://t.co/9MONVXax20

Report on my first smoke tests on Fable 5. Tested it on 5 induction problems. Fable 5 xhigh: 5/5 empty responses "", 5x128k tokens consumed and billed. Drop to Fable 5 high: 5/5 empty responses "", 5x128k tokens consumed and billed. Drop to Fable 5 medium. Report below. 1/5 nonempty responses, wrong answer. I'll do one more run, on medium (so as not to be wasting tokens) and on easier problems. (The problem set is https://t.co/gBelIZRbZI)

Anthropic responding to my inquiry, and explaining that perfectly empty max-token billable responses are expected behavior for Fable. https://t.co/5Hi7VKBQDw

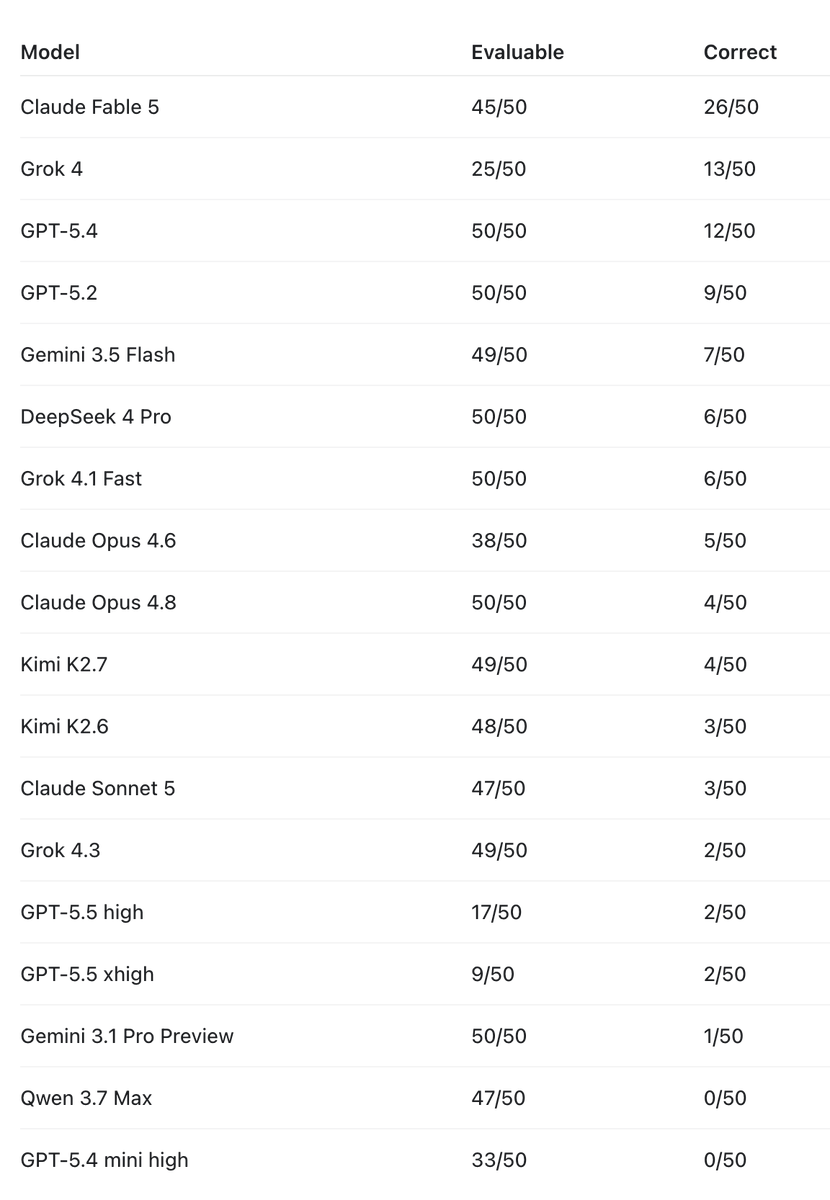
OK, Fable 5 is VERY strong in my first small benchmark test. I tested the following models on a reasoning task, induction. (Details in my manuscript on arXiv appearing in ICML.) 50 challenge problems, to keep the task manageable in terms of costs. Fable 5 blows the competition. Caveat: it has a high rate of empty responses. At thinking effort high, it returns almost all empty (and bills max tokens). At medium, it returns more than half empty. So I did two rounds on medium, and then one on low effort and reached 45/50 responses. (The whole task cost $188 for 50 problems.) Regarding the GPT models: interestingly, GPT-5.5 is pathological in not returning answers. I ran two rounds of it on xhigh and two rounds on high. The completion rates respectively are 9/50 and 17/50, and the correct answers are extremely low, much worse performance than GPT-5.4 and GPT-5.2. So I won't be running any more experiments with GPT-5.5 on this task. (It is strong on other tasks.) Another note, on Grok models: the original, and now unavailable Grok 4, is very strong. Again with low completion rate. I ran about 3-4 rounds to get 25/50. Grok 4.3 is much weaker in comparison (even weaker than Grok 4.1 fast) but returns answers more often. Other notably strong performers are Gemini 3.5 Flash (way better than Gemini 3.1 Pro) and DeepSeek v4 Pro. But no model matches Fable 5. Great job, @anthropic!
I kept asking Claude Fable to make the game "more AAA" over and over again. The results are... interesting. In Claude's view, this meant upgrading graphics, boss fights, mechanics adding custom sounds and soundtracks until it reached the limits of WebGL. https://t.co/qSWc3KWnAV https://t.co/18LAQ8WZhn
Fable: "you have Unity and access to MCP. I want you to build a game that is a unique twist on a FPS. You want the player to say "wow" & "so clever" and to enjoy the core gameplay loop" WebGL: https://t.co/xB707DCpBp * It had no assets so the graphics are procedurally gener
@RespectfulMemes https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@OrwellNGoode https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@LostMemeArchive https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@EXM7777 https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@gamann77 https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@RoundtableSpace https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@twetsfyp https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@shiri_shh https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@web3annie https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@aleabitoreddit https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@TheInternetFish https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@jenzhuscott https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@CaptainInsightX https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@ai_rohitt https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@juliankissa @SingularityNET @bengoertzel @KaiZenBickle https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@slash1sol https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@trq212 https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

@gamann77 https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

had alot of fun at @aiDotEngineer - nerding out about Codexmaxxing, meeting old friends and making new ones congratulations @swyx and team for the fantastic conference! https://t.co/xMEHqENc1V


Kimi K2.7 Code is the first open-weight model you can select in the GitHub Copilot model picker. What does that mean for you? @burkeholland explains how this low-cost, high-performance model gives you more choice and flexibility in your workflow. ▶️ https://t.co/rxkmT2cABP
Happy 4th of July everyone. I came here as a kid at 9 years old, not knowing a single word of english, lived on food stamps in section 8 housing. My parents cleaned houses while my sister and I collected cans for recycling. Our clothing was all donated and our furniture was things we found on the curb (here I am in front of our "tv set", the broken one being used as a stand for the little working b/w one). But this country gave us an opportunity--to learn, to work hard and earn something for it. "Grateful" does not begin to cover it. I owe this country and its people everything I have. Thank you America, happy 250 to the idea.
bets still on the table America, yet. https://t.co/Ap5Cw3EKRV

I've been going to tech conferences since eternity and I have to say @aiDotEngineer is something else every time I go I meet coolest people, we stay in touch and ship cool things together, it eventually alters @huggingface ecosystem this time I met @0xSero @alexocheema @TheAhmadOsman @NaderLikeLadder we have so much work to do on local AI, last time in AIE Europe we shipped a ton for your Claws on Hub 🙌🏼 but also I meet my long time internet friends like @josephofiowa @danielhanchen @llm_wizard or people I'm a fan of @willccbb @latkins 🐐 talent density and signals in talks are immense and it takes a huge skill to pick people, many thanks @swyx for putting it together 🫶🏻 you do god's work


i'm open sourcing UNBROKER: a tool that finds where your personal info is exposed by data brokers and files the removals for you it runs as a skill in Hermes Agent _________ your data is everywhere; hundreds of brokers publish your name, current and old addresses, phone, email, birthday, even your relatives. anyone can find where you live in about ten seconds CCPA, CPRA, GDPR, and a growing number of state laws say a broker has to delete your data if you ask. there's just no easy bulk button. every broker has a different process and many make it intentionally difficult to exercise your right to delete this is the entire business model for companies like DeleteMe, Incogni, EasyOptOuts; they charge you monthly (DeleteMe is $330/yr for a Family plan) to file removals that you can submit yourself for free, and then you're giving a new company the exact data you want to erase so i built one you just run for free. your data never even has to leave your machine if you run a local model _________ how it works: first it builds search vectors from everything: every name, alias, email, phone, and address you've had (brokers might index you under a maiden name or a house you left in 2014, so the naive "current name + current city" approach can miss profiles). then it fans out parallel sub-agents across the broker list, which refreshes from a maintained public source automation is tiered. when it can handle a broker end to end with your settings, it drives a browser through the opt-out form, sends the email, and opens the confirmation link itself. soft CAPTCHAs clear on their own with a real browser. anything only a human can finish comes back to you as a short list at the end the email side doesn't need a stored password and can send opt-outs and open verification links through your own logged-in webmail. you can also wire up SMTP, or keep it manual and just send the drafts it writes it tailors every request to your jurisdiction, filing under the framework that applies where you live: CCPA and CPRA in California, GDPR in the EU and UK, a general right-to-delete request everywhere else. if you're in California it also uses the state's DROP portal, a single request that covers 500+ registered brokers at once it holds as little of your data as it can, and keeps it local. dossiers are encrypted at rest if you want, opaque ids keep your real name out of every filename and log, and nothing leaves your machine unless you opt in brokers sometimes relist you eventually or new ones find your data, so every case is tracked in a ledger and can be re-scanned on a cron schedule so if your data pops back up it files the removal again https://t.co/2jfQxBYZkW

You can now use /session search <text> to find a session by title that you're looking for in Hermes Agent! Thanks @GodsBoy7777! https://t.co/bCRSVsGn5w

@marcusjihansson @Jason @DSPyOSS @gepa_ai @NousResearch You mean this? https://t.co/5WZCPWQHg3
