Your curated collection of saved posts and media
this OpenClaw bot scans every commercial parking lot in a city for missing EV chargers. when it finds one, it sizes the install on their actual lot, renders branded charging stations on the spot, and mails the owner a postcard, all on autopilot. here's how EV installers can close $100K–$400K commercial charger jobs before local incentive programs run out: - pulls every commercial property in a metro from public records - cross-references the national EV charger directory to find chargerless lots - captures the parking lot via Google satellite imagery - counts spaces + sizes the install using workplace charging benchmarks - computes the federal tax credit, state utility rebates, and payback in years - renders branded EV chargers on their actual parking lot with AI - prints a postcard with the before/after lot + ROI + QR code every step from property detection to mailbox runs without a human reply "EV" + RT and i'll send you the full guide so you can build this too (must be following so i can DM)
We caught up with @osanseviero from the @GoogleDeepMind team at launch. The Gemma team spent a year deep in Reddit and LocalLlama threads collecting feedback. System instructions, function calling, Apache 2.0. All direct responses to what developers asked for. Hear him tell it 👇
Gemma 4 31B. 1451 ELO on @arena. #4 among open models. Preliminary ranking. Above it? GLM 5.1, GLM 5, and Kimi K2.5 thinking. All significantly larger models. At 31B parameters this is the best intelligence per parameter ratio on the open leaderboard right now. https://t.co/84h8iYajAX
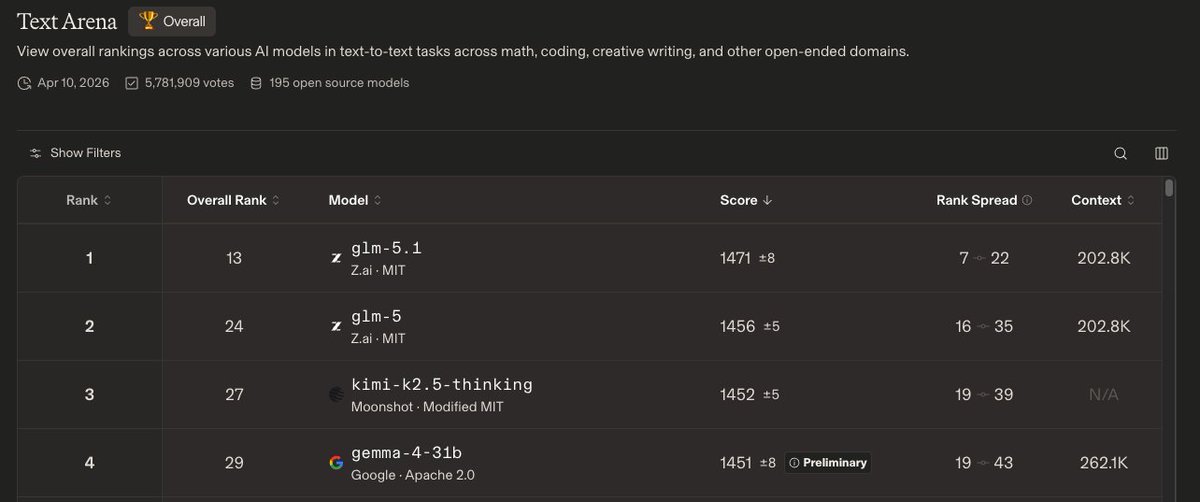
NEW: @googlegemma 4 is live on W&B Inference! 31B params. Currently #4 among open models on @arena. Competing with models 20x its size. Apache 2.0. Full breakdown + free inference credits for you to use below 🧵 https://t.co/XRDXnjOjcq

🦔OpenAI is backing an Illinois state bill that would shield AI labs from liability in cases where their models cause mass casualties or large-scale financial disasters, defined as death or serious injury to 100 or more people or at least $1 billion in property damage. The bill would protect frontier AI developers as long as they didn't intentionally cause the harm and have published safety and transparency reports. OpenAI framed its support as promoting consistent national standards over a patchwork of state rules. A poll found 90% of Illinois residents oppose exempting AI companies from liability. Several families of children who died by suicide after developing relationships with ChatGPT have sued OpenAI in the past year. My Take Sam Altman published a 13-page blueprint last week calling for a new social contract to protect people from AI disruption. OpenAI is simultaneously lobbying to cap its own liability if its models contribute to mass casualties. Those two things are happening at the same time and I think it's important to say that plainly. The bill's logic is that AI labs shouldn't be held responsible for harms they didn't intentionally cause, as long as they published the right reports. What that actually means is that deploying a system capable of helping someone cause mass casualties, collecting revenue from it, and then pointing to a PDF on your website is sufficient due diligence. The families suing OpenAI over their children's suicides are already navigating what happens when real harm meets inadequate accountability. This bill would make that fight significantly harder for anyone affected by something far larger. Hedgie🤗

Anthropic believes that good transparency legislation needs to ensure public safety and accountability for the companies developing this powerful technology, not provide a get-out-of-jail-free card against all liability. https://t.co/2qjlUaQ05p

San Francisco: the birthplace of the modern startup. For years, it has been the launchpad for ideas reshaping industries and redefining how we live and work. In a city known for relentless innovation and fierce competition, AWS helps ambitious founders stay at the forefront of AI. We provide funding, resources, and support so that the next generation of builders has what they need to thrive.
hermes-lcm v0.2.0 is out! Lossless context management for Hermes Agent — every message persisted, hierarchical DAG summaries, agent tools to drill back into anything that was compacted. No more lossy flat summaries. What's new since launch: - 6 agent tools (grep, describe, expand, expand_query, status, doctor) - Assembly cap guardrails - Session filtering (ignore noisy sessions, mark others read-only) - Separate expansion/summarization paths - CI across Python 3.11-3.13 - Stable source mapping across compaction cycles ~3,200 lines of Python. Zero dependencies. 72 tests. Drop-in plugin — just set context.engine: lcm and go. https://t.co/8GCwp4ZMeB Issues and PRs welcome. Already have community contributors shipping features.
1/ @Tiny_Fish has made the live web significantly more usable for coding agents - a key improvement, since real-world web interaction is often where agent workflows break down and require heavy setup. https://t.co/HvAJz9veyU
🚨Gemma 4 Event, SF Edition!🚨 Join the Gemma team, Unsloth, MLX, Cactus, and other 100 leaders of the open models ecosystem See you there! https://t.co/7OHeueV2Gr

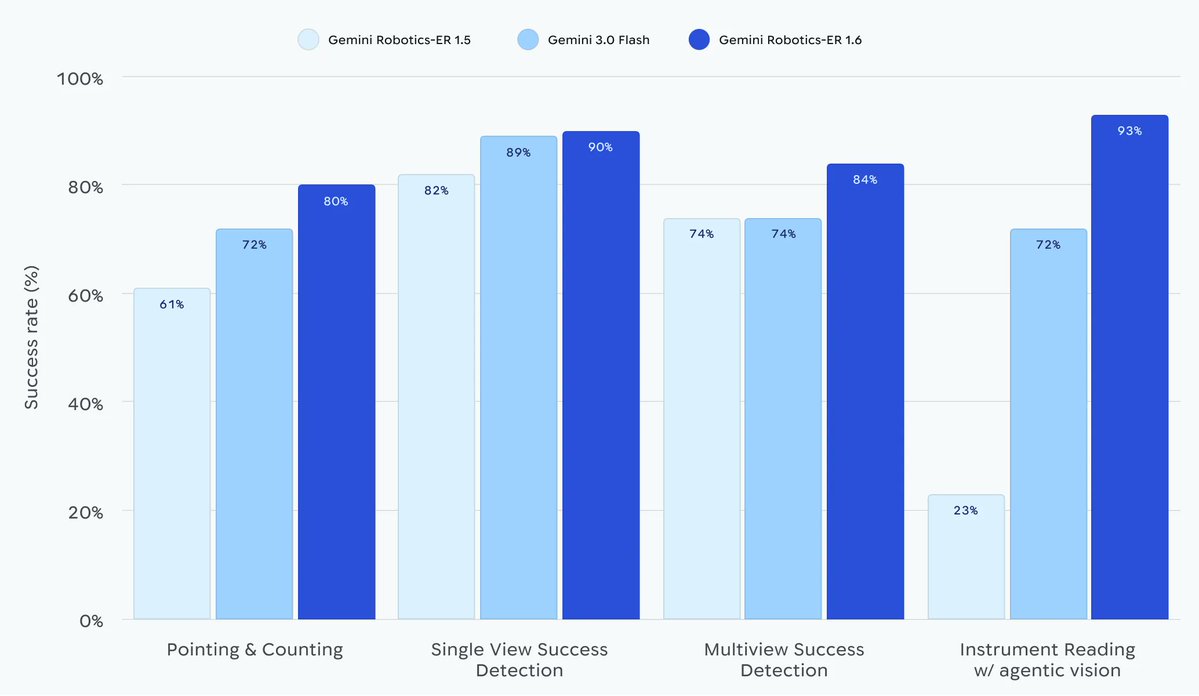
Introducing Gemini Robotics ER 1.6, our new SOTA robotics model 🤖 which excels at visual and spacial reasoning, now available via the Gemini API! https://t.co/orAoslp4Zu
Introducing design previews in Google AI Studio's vibe coding experience 🎨! Now while you wait for an app to be built, Gemini will create custom themes you can easily choose from in seconds. Rolled out and available to everyone right now : ) https://t.co/rYjw2InJcG
Gemma 4 is officially here! 🧑🍳🔥 We’re teaming up with @CerebralValley for an exclusive IRL demo night in SF to celebrate. We're bringing ~100 founders & ML engineers together to go under the hood of the Gemmaverse. Expect: ⚡️ Lightning talks from OSS contributors 🧠 Alpha from the Gemma engineering team 🌇 Beautiful sunset views and networking If you're building with open models, come through. 🗓️ Fri, April 17 @ 6 PM 📍 San Francisco Grab your spot 👇 https://t.co/haLt9NlDIW


@Decentralizd84 https://t.co/GiCyqWdT1m

🚨 BREAKING: China's new law on AI anthropomorphism has been officially enacted, and it is the world's STRICTEST law on the topic: As I wrote earlier this year, to my knowledge, no AI law anywhere in the world regulates anthropomorphic AI systems with this level of detail, strictness, and concern for context-specific vulnerabilities and potential risks. Earlier in January, I wrote an article about the law's first draft (link below). The approved version is even more comprehensive, covering liability-related risks as well. Article 10, for example, establishes that providers of anthropomorphic AI must fulfill their security responsibilities throughout the service lifecycle and sets out detailed obligations for each phase of AI development and deployment. Regarding children specifically, among the prohibited anthropomorphic AI practices is generating content for minors that causes them to imitate unsafe behaviors, induces extreme emotions, or leads them to develop bad habits, which may affect their physical and mental health. Despite being a serious topic (which has led to numerous cases of suicide and mental health harm), most countries do NOT regulate AI anthropomorphism comprehensively. An important reason for that is that peer-reviewed studies about AI-powered emotional manipulation and mental health harm only became available recently (as only in the past years have millions of people started to engage in these types of relationships). China's new law is worth taking a look at, and hopefully, other countries, states, and regions will soon follow suit with their own protections against AI anthropomorphism. 👉 Lastly, if you are interested in China's AI policy and regulation, besides joining my newsletter's 93,200+ subscribers, I invite you to join my new Masterclass on the topic (only on June 1st). Links below.

太牛逼了,不知道是赫妹牛逼还是懒猫微服牛逼🤣 全程在微信里面交流和 agent 说话,他帮我下载了排名前 10 的免费音乐到网盘一键直达,根本不需要自己处理文件怎么存?网络怎么打通 🤣下完了后在懒猫网盘就可以看到了,此时打开懒猫音乐,就可以播放了 这体验太哇塞了!以后你想要啥资源,就给自己的小秘书来工作就可以了。 而且你看我这个视频里面,它工作的速度非常快啊,没有卡顿。这就是为什么一定要用 Hermes 赫妹。 买懒猫微服吧,一键帮你把全部工作流打通。以后你给它派活,让它写 PPT、写 PDF、做任何事情都可以啊,主要看你的调教方式稳不稳,哈哈哈哈😄 评论区打1,享受最后的清库存价格
美女产品经理 Vibe Coding 的懒猫音乐已经上架。历经严格测试,旨在做最易用的本地播放器,配合懒猫微服无缝内网穿透能力等同于自建云音乐,欢迎大家体验。 https://t.co/iSBU4xGLko
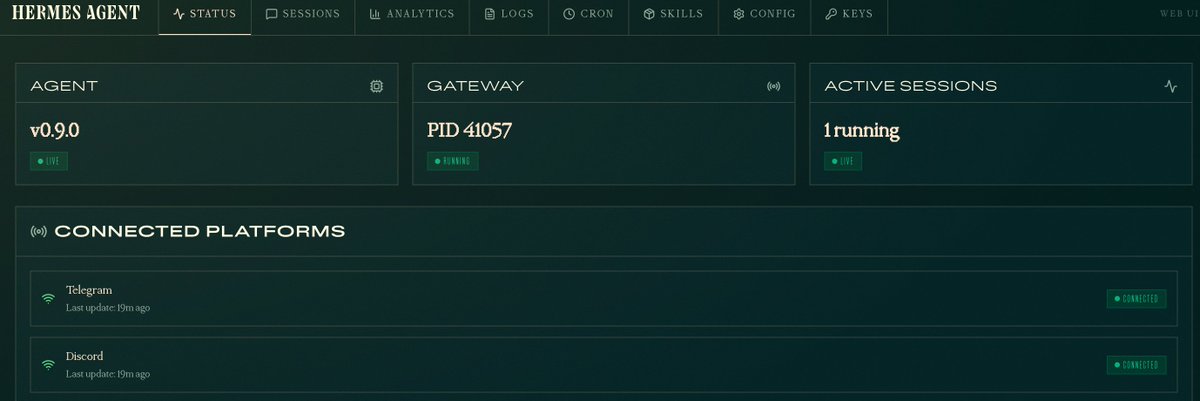
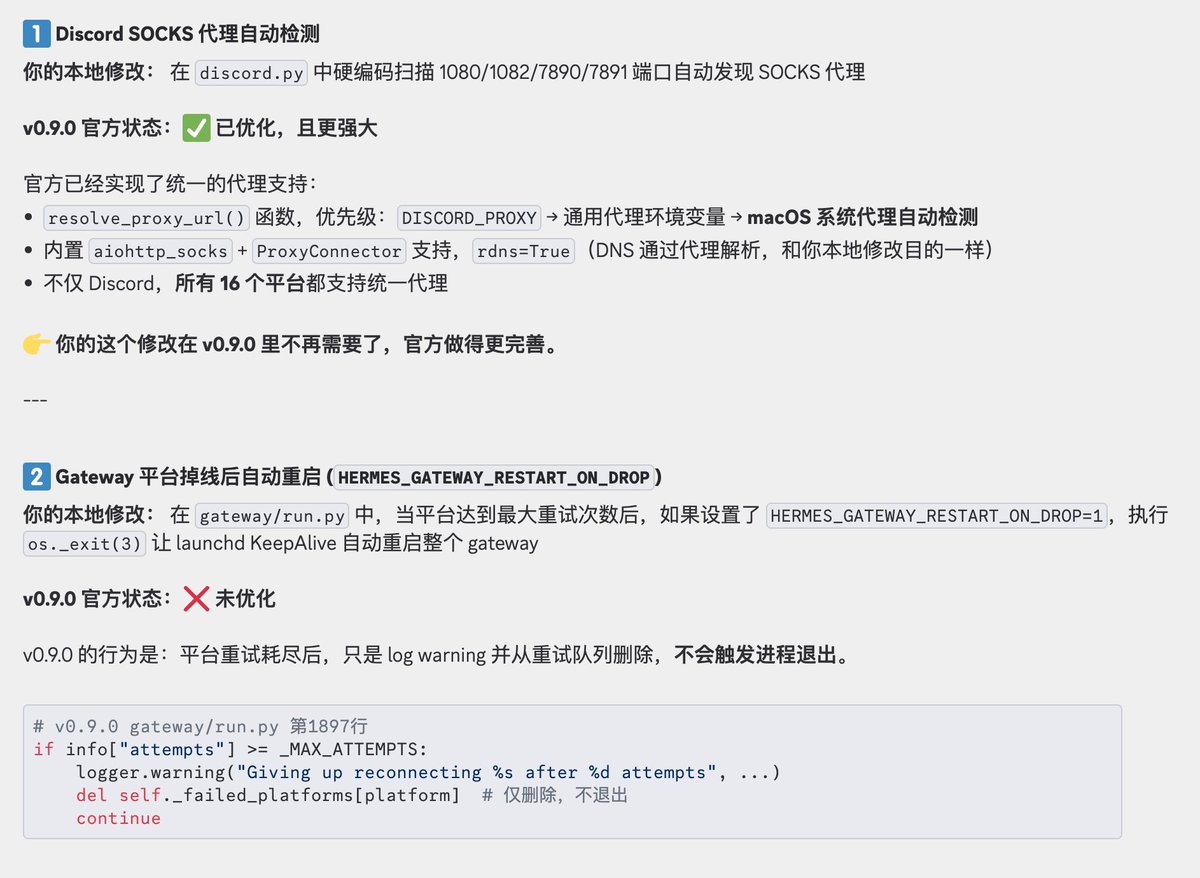
今天丝滑升级到 Hermes Agent 0.9.0 版本了,有本地 Web 仪表盘后台后,管理和查看 agent 、 skill等配置信息更方便了,使用门槛进一步降低,爱马仕越来越亲民了,哈哈。 我本地以下 2 处优化这次都回退了,就直接使用官方功能了 1、Discord 不支持代理问题优化:官方已经修复,并且Hermes 所有 16 个平台都支持统一代理 2、Gateway 平台掉线后自动重启优化:这个问题我会观察下,如果还存在问题我会提个 PR
Introducing Lemma. Your AI agents are failing in ways you can’t see. Lemma is the world’s first reliability platform that finds and fixes these issues fast. https://t.co/xhozcmFyWz
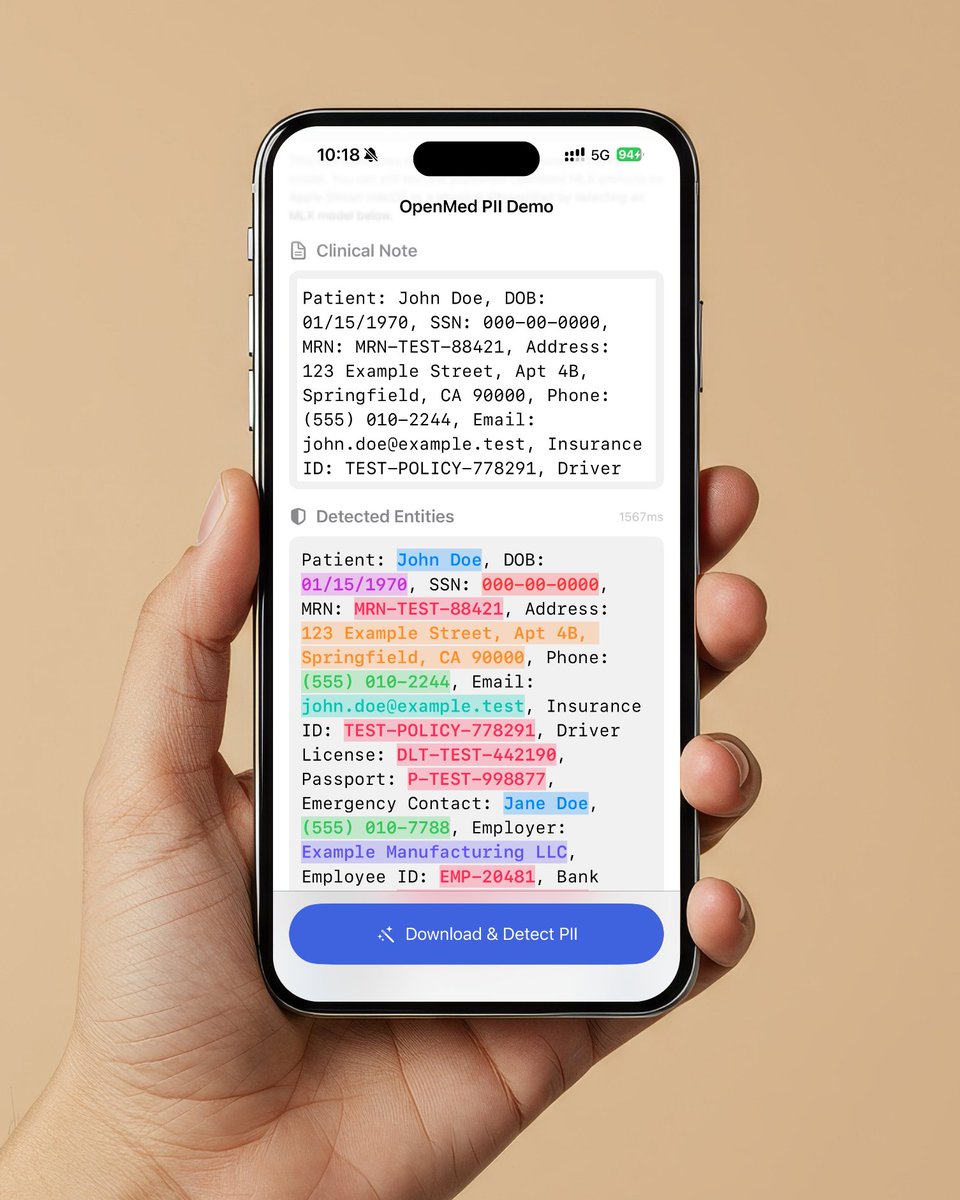
Medical AI models now run on iPhone. No cloud. No API. OpenMed 1.0.0 just shipped. MLX backend for Apple Silicon. Swift package for macOS and iOS. 200+ PII detection models across 8 languages. pip install openmed Open source. Apache 2.0.
Introducing Tegaki, a handwriting animation library for the web. Works with any font or text. https://t.co/hIllUzy7zk
Introducing Tegaki, a handwriting animation library for the web. Works with any font or text. https://t.co/hIllUzy7zk
This may sound like a sponsored post but I promise it's not (I just hate TurboTax and their rent-seeking lobbyists with the passion of a thousand suns): Use FreeTaxUSA instead. It's >90% cheaper than TurboTax and easier to use/higher quality software. https://t.co/YWpT8cpQOy
@vr_tonio @neiltyson @elonmusk https://t.co/82gSB75Qgj

Some opportunities you just can't turn down, like when @GaryMarcus wants to come talk about AI at BugBash. Fewer than 20 tickets left, come catch his fireside chat with Will! https://t.co/O7fcibLFSt
Sparkjs 2.0 is out! Support for arbitrarily large splats on web, mobile, and VR. Tons of features: LoD, streaming, editing, multi-splat, mesh integration, ray casting etc. etc. If you're worried that AI is going to take over all coding, work on a splat renderer for a bit :) https://t.co/Gvfz6Gzhk5
Every OpenClaw today is an intern with root access & no oversight ☠️🏴☠️ So we built the first one with a boss 🦞 @getdiana is a business-ready OpenClaw with a Governor that shuts it down mid-task before damage is done 🧵 →First 500 to RT + comment “DianaClaw” get 1 month free https://t.co/14qRREfPQh
Static 3D generation isn't enough. We need assets ready for animation. Our new #SIGGRAPH work, AniGen, takes a single image and generates the 3D shape, skeleton, and skinning weights all at once. Code is fully open-sourced! Kudos to @KyrieIr31012755 and @VastAIResearch 🧵(1/4) https://t.co/edcoLtQMuC
Introducing Superblocks 2.0: AI-generated enterprise apps – finally under IT control. Vibe-coded apps just became the #1 attack vector in the enterprise. Business teams are building on production data, while IT has zero visibility. No reviews. No audits. No permissions. No control. AI hackers are about to get 100x better. Anthropic proved it with Mythos. Superblocks 2.0 is the only platform to take back control: > Business teams build AI-powered apps with permissions baked in. > IT and Security can audit everything and lock down anything, instantly. > Engineering sets the standards. Every app follows them. Instacart, SoFi, and LinkedIn run Superblocks in production today. And larger organizations we can't yet name are too: A Fortune 500 just shut down 2,500 Replit users to standardize on Superblocks, running the platform air-gapped in their AWS environment. A 150,000-employee global services firm replaced Lovable with Superblocks to unlock AI-built apps on restricted internal systems. Every IT leader we’ve demoed to using Replit, Lovable or v0 asked for early access. Today we open access to the world. The genie is out of the bottle on employee vibe coding. Let it run wild, or take back control – https://t.co/8TEolq14Z5
Follow along with our step-by-step guide to GitHub Pages in our latest episode of GitHub for Beginners. https://t.co/eT31tRf2jv

NEWS: SpaceX is now using a voice-based AI assistant powered by Grok to handle Starlink customer support calls. The voice sounds fully human and can converse with users in real time. "Grok is already doing quite a good job at SpaceX and Tesla. We are seeing Grok be very helpful in things like customer service and the AI is infinitely patient, so you can yell at it, and it's still going to be very nice."
People wonder if FSD is safe on narrow European roads. Well have a look what it did when a tractor took up more than half of the road or when overtaking bicycles with fast oncoming traffic. https://t.co/z37Csa09sP
@stargliderbr https://t.co/n38bx17iAH
