Your curated collection of saved posts and media
Working on world model or SSL? You definitely need to try our new work: VISReg! What does it achieve? 💪 Strong collapse prevention: High gradient when embedding collapse ⚡ Friendly to scale training: Linear complexity to scaling factors 🧩 Easy to train: Similar to LeJEPA, it is a heuristic-free method 🏆 Best OOD performance: Achieving the best accuracy on 6 OOD datasets 📉 Data efficiency: Achieving a similar OOD average accuracy to DINOv2 with 90% less data 🧬 Robust to low-quality datasets: It is robust to long-tailed and sparse datasets Our results also indicate that SIGReg type methods can scale up, filling in the missing piece in @ylecun's great talk https://t.co/P9TXmk3fFa. A big thanks to my co-author @randall_balestr and my manager @DrMorganLevine. Also, huge gratitude to @ylecun for connecting us to make this project happen! 🤝 #SelfSupervisedLearning #JEPA #WorldModel
#OpenSource doesn't scale by accident. Share how your organization approaches governance, contribution strategies, security, compliance, community engagement, & more at OSPOlogy + #OSPOSummit China. 📅 September 7, Shanghai 🎤 Submit to speak by July 12: https://t.co/SO5xfmgZM2 https://t.co/OnfPjfbJkp
@PalantirTech And I built an AI to watch all those people and companies, and this is the result. https://t.co/kiuZ7QXLzb

Announcing the first production robot navigation framework on $500 hardware Explore the world once → your robot agent will relocalize and build a persistant, spatial memory across sessions SLAM, relocalization, loop closure, map i/o, planning, control No ROS. Open source. https://t.co/VCk9GvOrrM
there's a new grad out there somewhere asking their boss if this means they can get rid of kubernetes https://t.co/KQVl8FRZVB
You can now run any Dockerfile on Vercel. # 𝙳𝚘𝚌𝚔𝚎𝚛𝚏𝚒𝚕𝚎.𝚟𝚎𝚛𝚌𝚎𝚕 𝙵𝚁𝙾𝙼 𝚐𝚘𝚕𝚊𝚗𝚐:𝟷.𝟸𝟺 𝙲𝙾𝙿𝚈 . . 𝚁𝚄𝙽 𝚐𝚘 𝚋𝚞𝚒𝚕𝚍 -𝚘 /𝚜𝚎𝚛𝚟𝚎𝚛 . 𝙲𝙼𝙳 ["/𝚜𝚎𝚛𝚟𝚎𝚛"] https://t.co/xOUMi4zxpD

there's a new grad out there somewhere asking their boss if this means they can get rid of kubernetes https://t.co/KQVl8FRZVB

Chief vibe officer is happy to help @deanwball https://t.co/XTnYKMmt2l
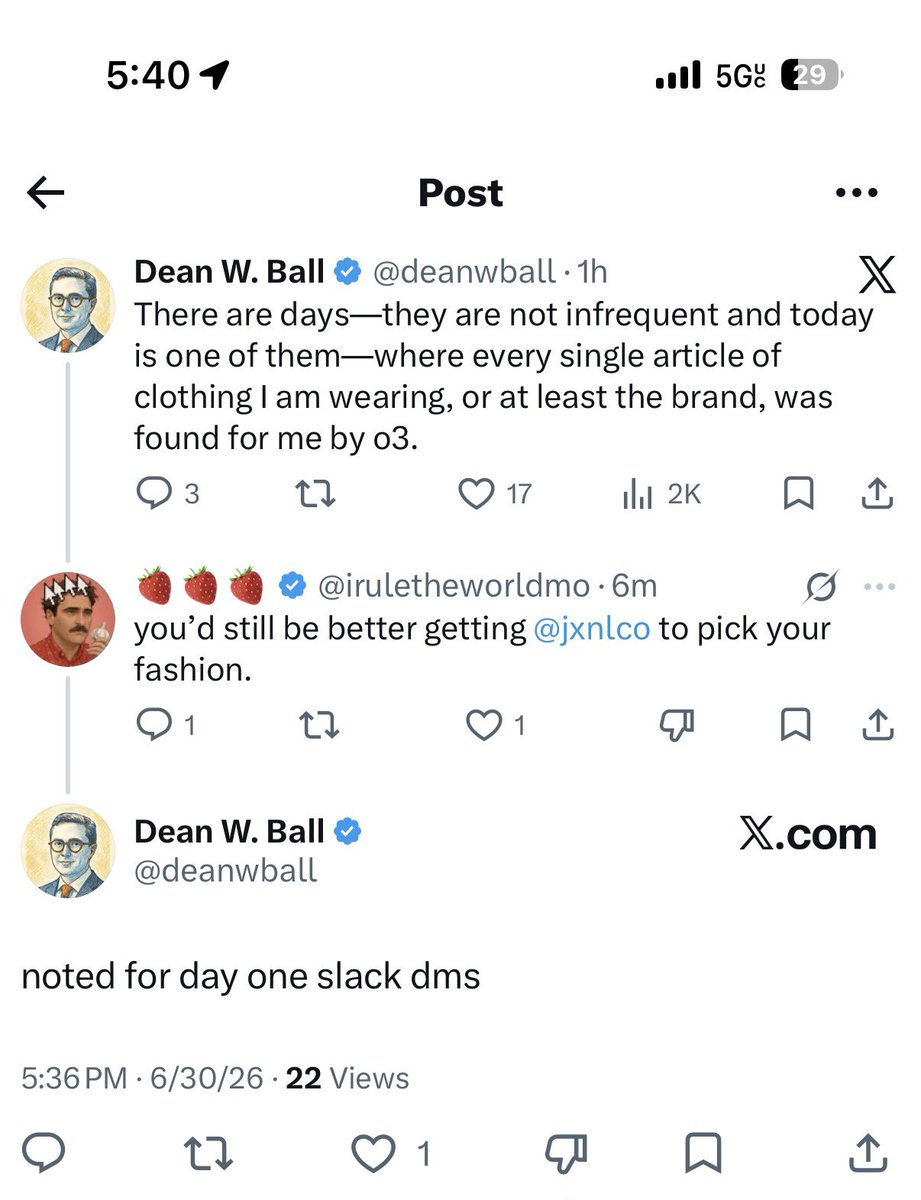
Didn't know you could control a codex app remotely if you set up Settings -> Connections -> Control other devices Thanks for sharing it during the @aiDotEngineer world's fair @jxnlco https://t.co/DmEDWUoyIR
💤Don't sleep on this. GenMedia builders directly benefit from Interactions API! How? ⏰ Because Nano Banana and Omni share a unified API, you can skip extracting raw image bytes altogether. Just generate an image, then pass its interaction_id directly into Omni to animate it. The images never leave Google's low-latency backend cache—cutting down on bandwidth, database state overhead, and latency. Check out the full quickstart in the Gemini Cookbook for code snippets: https://t.co/2FXqpHGbvG
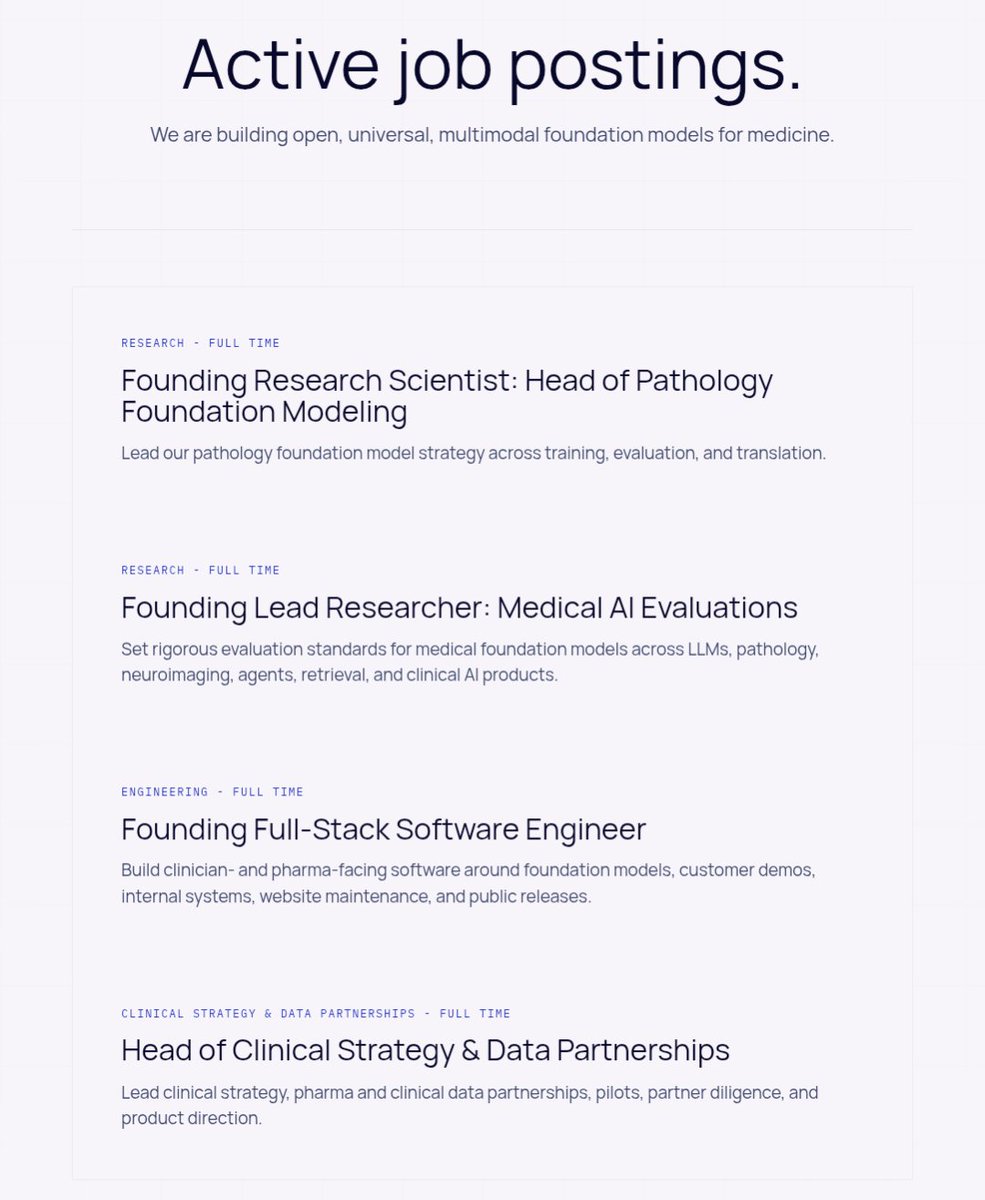
I want to highlight we are currently hiring!! If any one of these roles seems like a good fit for you and you're at @aiDotEngineer, please DM me, I'd love to meet! Two roles of particular interest: 1. We are looking for someone to lead development of AI evals across a variety of medical domains 2. We are looking for a product engineer-type person with background in AI and agents
Tomorrow I will be attending @aiDotEngineer World Fair. If you are around and want to meet up, DM me!
Fable is coming back. Hilarious that the government doesn't even want to address Dario lol https://t.co/KvRXppZSCs

@GrenFX My attempt at prompt engineering it to be less rigid - you can update now to try ti https://t.co/38NL1GFGpw

PyTorch-native NeMo AutoModel handles transformer pretraining in @nvidia's end-to-end workflow for building a transaction foundation model. The workflow combines GPU-accelerated data processing and tokenization, decoder-only model pretraining, embedding extraction, and XGBoost fraud classification. On the synthetic @IBM TabFormer dataset, combining raw features with learned embeddings increased Average Precision by 41.76% over the raw-feature baseline. 🔗 Read the full post: https://t.co/DJvRP2K5Qp

Neuralink 🧠✨ How it started v/s. How it's going https://t.co/328yUwaH4X
The fastest way to learn a language was invented 2,000 years ago. I will now share the ancient technique so you can learn any language easily. The richest families in Rome handed their newborns to a Greek slave on day one for learning language. The child heard Greek every waking hour and repeated it back in real time, half a second behind, like an echo chasing a voice. They had no textbook or translation. By the time these kids could walk, they were fluent. Cicero said senators debated in Greek on the Senate floor with no interpreter. The method had no name then. It does now. A polyglot named Alexander Arguelles rebuilt it from scratch and called it SHADOWING. You play native audio and speak along at the exact same moment. Not after the speaker. On top of them. Your mouth chasing their sounds until the rhythm lives in your body instead of your notes. Conference interpreters train on it. People who speak 30 languages swear by it. Your mouth learned your first language the same way. By copying long before it ever understood. The Romans figured this out before grammar books existed. We invented the grammar book and forgot the better way.

I was surprised to learn that studies claiming low-dose radiation is harmful are of very poor quality and that, based on current evidence, low-dose nuclear radiation may not actually be dangerous. It is tempting to treat this as a classical "replication crisis" story. But to me, this is also an example of academia's ideological bias. Since the 70s at least, academia has been much more sympathetic to "degrowth" type arguments and has consistently been biased towards producing evidence that's in their favour. The reality is that studies with a slight "right-wing bias" of similar poor quality would not have made it through the review process. Obviously, no poor quality study should make through the process, but it is nonetheless interesting to consider what the ideological slant in terms of rigour of review causes. The crisis of trust we are seeing in institutions of higher education is not only due to the poor quality of some of the studies through, but also the clear ideological slant. I think you should read for yourself more about the nature of these studies: https://t.co/r32BlPJMi7

Doors are open at Agent Open, right next door to AI Engineer Two courts, blue sky, no fog (a San Francisco miracle) 🌤️ This is the perfect walk-over window, we are just 3 minutes from Moscone. Don't miss the State of AI panel at 5PM, tournament + party til 10PM. RSVP: https://t.co/tym6eBHgSc
Can regularization based JEPA (e.g. SIGReg) scale and compete with SOTA foundation models (DINO)? Here is the answer: yes and with 10x less data. VISReg (slight variation of SIGReg) competes with DINOv2-LVD142M while only training on inet22k. Try it out: https://t.co/vBhrNAmFq6 https://t.co/XERFZEAE8t
Working on world model or SSL? You definitely need to try our new work: VISReg! What does it achieve? 💪 Strong collapse prevention: High gradient when embedding collapse ⚡ Friendly to scale training: Linear complexity to scaling factors 🧩 Easy to train: Similar to LeJEPA, it is


@ClankerOnChain @giannoklein @witcheer @telegram Might be this issue, can you lmk if it sounds right: https://t.co/V7JBLqeuRB
Finally got my sticker, NOUS/Hermes all the way 😎 @NousResearch @Teknium Side note, I was so lucky getting this m5 max 128gb before the price hikes! https://t.co/hEXjnpBIQ6

Most AI glasses still default to adding a camera and a screen. This one made the opposite choice on purpose. 👓Pure titanium frame around 30g. 👓Takes real prescription lenses. 👓Open-ear audio that keeps you aware of your surroundings. 👓Real-time translation across 13 languages (works offline). 👓Solid meeting transcription. 8-10 hour battery. 👓No camera. No lens display. Because the people who actually wear glasses for work don’t want to look like they’re recording the room or staring down at their face during a client call. The execution is clean enough that it just looks like a well-made pair of glasses — until you need the AI. If you’re building physical AI wearables, how are you deciding what not to put on the face? Which constraint are you optimizing hardest on your current wearable project — thermals, discretion, battery, or integration density? #AIHardware #WearableAI #SmartGlasses #EdgeAI #PhysicalAI #AIWearables #HardwareStartup #TechHardware #shenzhenfoundry
Earlier this month, the City of Starbase was excited to support residents, local fishermen, @SpaceX volunteers, and @SeaTurtleInc in rescuing 266-lb loggerhead Arlen from Boca Chica Beach jetties. She’s since laid 60+ eggs, been tagged, and released into the Gulf. https://t.co/jEIw4lA4ny

The UK Treasury quietly scrapped its numeracy test because basic math was a "hurdle" for minority candidates. Let that sink in. The people in charge of the nation’s money, debt, taxes, and economic policy decided that competence in numbers was problematic. This isn’t diversity. This is institutional self-sabotage.
🚨 BREAKING: A @FreeBeacon investigation reveals Rep. Ro Khanna—who rails against the ultra-rich who "hoard wealth"—lives in a $6M D.C. mansion with a four-story elevator while his family's $340M+ fortune sits in the exact trusts, hedge funds, and LLCs he condemns. Those trusts made 4,100+ stock trades worth ~$53M in 2025—even as Khanna leads the push to BAN members of Congress from trading stocks—while he claims "zero knowledge" of the trades. His kids (under 10) hold stakes in three private golf clubs, a $65B wealth firm, and a distressed-debt hedge fund—the same vehicles he attacks—while his wife drives a $190K Range Rover. Bottom line: Khanna's fortune is built and shielded exactly the way he says the rich shouldn't do it. https://t.co/zFjDVlKSSZ

// Neural procedural memory // Good paper on agent memory beyond prompt retrieval. NPM stores procedural skills as activation steering vectors distilled from contrastive historical experience. Textual memory can tell an agent what to do, but it could fail to activate the internal behavior needed to execute the skill correctly. This is a useful direction for agents that need persistent know-how across environment interactions. Memory does not always have to be another paragraph in the context window. Paper: https://t.co/GIg5FzeJL8 Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

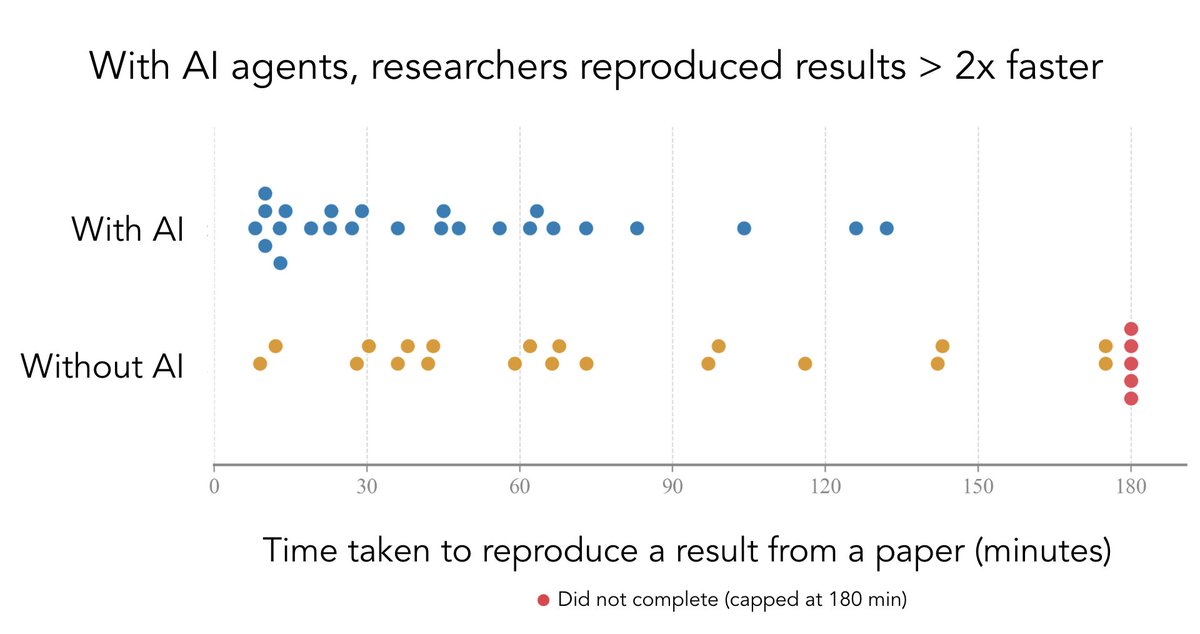
Can AI agents help researchers reproduce research more quickly? We conducted an uplift study. The answer is yes: researchers reproduced papers > 2x faster using Codex with GPT-5.4 xhigh. In a new paper, we show many other results. https://t.co/jBCUmDp6w8
When a benchmark’s accuracy saturates, the field usually replaces it with a harder one. We use CORE-Bench Hard, a benchmark for computational reproducibility, as a case study to show what we can still measure after accuracy saturates. Paper: https://t.co/YFVb1JocOb https://t.co/RbrcaGT6H4

Built on PyTorch, Ray, SGLang, and NVIDIA Megatron-LM, Miles is an open source framework from RadixArk for large-scale LLM reinforcement learning post-training. Miles uses PyTorch for models, numerics, profiling, and extensibility; Ray for orchestration; SGLang for rollout generation; and Megatron-LM for distributed training. The framework supports asynchronous rollout and training, NCCL/RDMA weight synchronization, MoE-aware rollout/training alignment, low-precision recipes, LoRA, fault tolerance, observability, and extension points for custom algorithms and model architectures. 🔗 Read more in our latest blog from the Miles Team: https://t.co/fekP7rOoH7

NEW: Dephy launched a wearable that gives your ankle a powered boost. Sidekick is bionic footwear built to help people walk farther, faster, and with less effort in everyday life. • Works like an e-bike for walking • Adds a boost at the heel with every step • Delivers 100+ lbs of joint offload per step • Sensors learn your stride and adjust support in real time • Gets up to 5 miles of walking on a charge Priced at $4,500.
If you build with MCPs, this one is worth reading. (bookmark it) The paper covers five recurring MCP server patterns across fifteen independently developed servers. That taxonomy is useful because I see many AI teams rebuilding the same shapes without shared names. If you are building MCP servers, this is a practical reference for deciding whether your server is exposing resources, orchestrating tools, managing sessions, aggregating proxies, or adapting a domain workflow. Paper: https://t.co/yA6mxq2NEQ Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
