Your curated collection of saved posts and media
@BAXUSco @JoshuaRosenthal @Lightspeedpodhq https://t.co/rivY3HfQJZ

@BAXUSco @JoshuaRosenthal @Lightspeedpodhq https://t.co/rivY3HfQJZ

DUDE LMAO THIS IS A GAS STATION😭😭😭 https://t.co/YYFmWJiCQa


3D printed laser zoetrope [📹 Akinori Goto] https://t.co/C8EoilTvuu
Chinese startups are moving FAST with AI 👀🐶🐱 Now there’s an AI-powered pet collar called “PettiChat” claiming to translate barks and meows into human language in real time. According to reports: 🔹 94-95% accuracy claimed 🔹 Uses microphones + motion sensors + AI 🔹 Analyzes body language and vocal tones 🔹 Already has 10,000+ pre-orders 🔹 Costs around $118 This sounds crazy at first… But honestly? We are entering an era where AI won’t just understand humans. It will understand: 🐶 pets 🚗 cars 🏠 homes 🧠 emotions 🌍 behavior patterns The most interesting part is not whether the translations are “perfect.” The real breakthrough is this: AI is starting to detect emotional patterns and intent from non-human communication. That changes everything. Imagine future systems that can detect: ⚠️ stress in pets ⚠️ illness before symptoms appear ⚠️ fear, anxiety, excitement ⚠️ emotional bonding patterns Pet tech could quietly become one of the biggest AI industries of the next decade. And this is probably only Version 1. The future of AI is not just chatbots anymore. It’s real-world intelligence layered onto everyday life. 🚀 #AI #ArtificialIntelligence #PetTech #Startups #Innovation #MachineLearning #AIRevolut https://t.co/f0d78D1Y8S
Seedance 2.0 Prompt Share 🔥 Just came across this clean workflow from @aimikoda — created on @mitte_ai using strong character references + text-to-video. What I love about it is the mindset behind the process: There’s no single “correct” way to create. The best method is simply the one that keeps you in flow and lets you produce your best work. Whether you’re using character refs, storyboards, or pure prompting — honor the process that feels right for you. That’s where real creativity unlocks. Big thanks to Kōda for sharing these openly. Always inspiring to see different approaches in the wild. What’s your go-to workflow right now? Drop it below 👇 https://t.co/1IkDKmxzDb
@safishamsii Great job Safi https://t.co/vBN1ThhvmU

Graphify looks like a missing layer for AI agents. It turns your codebase, docs, schemas, PDFs, images, and videos into a queryable knowledge graph. I’m especially curious about using it with OpenClaw and Hermes Agent for long-running product workflows. Agents need memory + structure, not just prompts. #hermes #openclaw #Ai #Aiagents https://t.co/65xT3kf1mR
More playful hardware, please.✨ https://t.co/pwVQlLCYlk
More playful hardware, please.✨ https://t.co/pwVQlLCYlk
The @AIatAMD Developer Hackathon is back for Act II. @NYSE Wired and @theCUBE just joined. The pulse of global markets and the voice of enterprise tech - now backing the builders. MI300X GPUs, $100 cloud credits, https://t.co/dq9hXb75FL Pro on the table. This is the build that gets you seen. Register → https://t.co/0fbdz4cQ2V.


Upscaling one image shouldn’t feel like buying a plane ticket 😅 https://t.co/0BLVX22O5g
This is exactly where entertainment is going next. Fictional characters won’t stay inside screens anymore — they’ll move into live stages, theme parks, AR/VR spaces, and interactive experiences. The future is not just watching stories. It’s entering them. 🔥 https://t.co/I8HV0fUNWM
You want to know what the https://t.co/ULGu0lK7GX community is made of? Our Hall of Fame keeps growing. And every new name on it makes us prouder than the last. 7 builders. 3 hackathons. 1 conviction: autonomous AI needs a safety layer. https://t.co/muNaKn51AU

The future of AI video is not about perfection — it’s about motion, creativity, and rapid experimentation. This is getting exciting 🔥 https://t.co/LKAUUT5em7 https://t.co/jswugZzgqd
30 teams. 2 days. No internet. Build AI that works when the wifi is off. ExecuTorch Hackathon → San Francisco, June 27-28 Apply by June 15: https://t.co/DojysYqGwL. https://t.co/WL8234xg4M

This is huge. 📸📹 https://t.co/TGQd6VBThX
I’m excited to moderate the ‘Advancing AI/ML in Federal Procurement’ panel at #AIinGov on Mar 22 @ 12 PM ET with panelists: • @aocanizares, @PerkinsCoieLLP • Sam Jo, @PerkinsCoieLLP • @BassHaidar, @Guidehouse Register for free at: https://t.co/ELsuoS4eHJ #ML #aipolicy #gov… https://t.co/JXmZvof147

Join #AIinGov Mar 22 @ 12 PM ET for the ‘Advancing AI/ML in Federal Procurement' panel with speakers: • @kath0134, @Cognilytica • @aocanizares, @PerkinsCoieLLP • Sam Jo, @PerkinsCoieLLP • @BassHaidar, @Guidehouse! Register: Register free at: https://t.co/vIyyLkZ1uk #ML #AI https://t.co/LbI8kdWkbn

Check out this recent @forbes article from @Cognilytica @rschmelzer to learn how the state of MD is building A Data-Driven Culture : https://t.co/PVbz30Lu2d #AI #AIinGov #stategov #data #CDO https://t.co/yExrTXd7uU

Excited for my presentation ‘Avoiding Automation Failure: What, When, and Why Automate’ on Tue., July 12 @ 10 AM ET! I’ll discuss how to avoid failure, benefits & lessons learned in #automation. Register at: https://t.co/lNXyTHyPVC #AI #data @Cognilytica #intelligentautomation https://t.co/eOVPmH0AVM

How The U.S. Department Of Labor Is Leveraging Its Data Rich Environment via @forbes @cognilytica https://t.co/TLraOHYEA1

What are the 20% of successful #AI organizations doing that are setting themselves apart from the failures, leading their projects to success? via @forbes @cognilytica https://t.co/HqvESrSXFh #CPMAI #data #bestpracticesmethodology https://t.co/vnxBNh9mm2
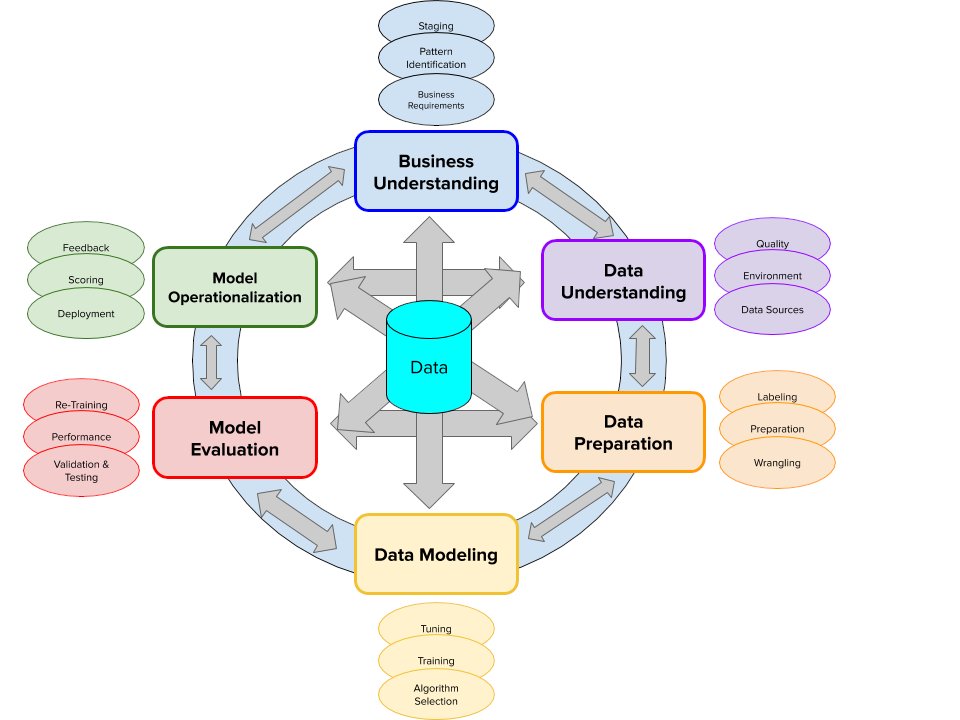
Excited for my presentation ‘The Top Reasons for AI Project Failure - and What you can Do about it’ on Tue., Sept. 20 @ 11:30 AM ET! Join to learn common reasons why #AI projects fail. Register & attend for free at: https://t.co/4NXAXp1sCN @Cognilytica #ML #projectmanagement #PM https://t.co/Z5Ucrg0YFX

I'm excited to moderate the #EnterpriseDataAI ‘Best Practices in AI Project Management’ panel with panelists Krystene Jennings, @Centene & Charles Mendoza, @Maximus_news discussing #AI #projectmanagement on Sept. 1 @ 11:30 AM ET! Register at: https://t.co/Pey6zqEPd1 #data #PM https://t.co/CVqq11Vs2V

Join me at #EnterpriseDataAI for the ‘Best Practices in AI Project Management’ panel with panelists Krystene Jennings, @Centene & Charles Mendoza, @Maximus_news! We'll discuss how to better manage #AI projects on Sept. 1 @ 11:30 AM ET. Register: https://t.co/Pey6zqEPd1 #data #PM https://t.co/KMlJBAoTcM

What A Research Firm Learned From Hundreds Of #AI Project Failures via @Forbes @cognilytica https://t.co/CifwwnMxAt #bestpractices #CPMAI #methodology #data https://t.co/iMnfiFKhXj

Excited for my presentation ‘The Top Reasons for AI Project Failure - and What you can Do about it’ on Tue., Sept. 20 @ 11:30 AM ET! Join to learn common reasons why #AI projects fail. Register & attend for free at: https://t.co/4NXAXoJRLf @Cognilytica #PM #ML #projectmanagement https://t.co/kZdKglNqqW

In this @Cognilytica #AIToday #podcast 'Bringing AI & Agile Together: Interview with Greg Mester, host of the 5am Mester Scrum podcast' hosts @rschmelzer & @kath0134 interview @gemphilly, host of @5amMesterScrum! Full episode: https://t.co/7znCl6cAsP #PM #AI #agile https://t.co/JPlnhen8zb

In this @Cognilytica #AIToday #podcast 'AI in Project Management, Interview with Ann Campea, host of The Everyday PM Podcast' hosts @rschmelzer & @kath0134 interview @AnnCampea asking about #AI in #projectmanagement! Full episode: https://t.co/wm7KmwjKdm #aiprojectmanagement #PM https://t.co/ozc0a9JQHm
