Your curated collection of saved posts and media
🐠 Sakana Marlin リリース 🐠 本日、Sakana AIは、初の商用プロダクトとして、ビジネス向けの自律型リサーチアシスタント「Sakana Marlin」を提供開始しました。 詳細はこちら:https://t.co/ZWsYW91LGu ブログ:https://t.co/leVp2dPxgL


Should we be worried about labour displacement at the hands of AI? "Short term, yes. Long term, no. In the near term, AI is creating real disruption, with large layoffs and thousands of people being displaced from existing jobs. Over the long run, there are far more problems to solve than people currently working on them. If AI makes engineers more abundant and productive, we can redirect that talent toward solving problems that were previously uneconomic or impossible to tackle." @matanSF Do you agree and what does no one consider that everyone should with regards to future of labour @pmarca @MattEvantic @shaunmmaguire @vkhosla
laser weeding in broccoli. real-time AI decision making at the edge. whistles and purrs. no chemicals. from our friends @carbon_robotics. https://t.co/dF84n71GMl
check out my /ultragoal skill https://t.co/aPya2D55zZ
tips for codex goals sure you can use /goal but it also has a set_goal() function its almost better to prompt the model to set its own goal, it will likely write a better prompt than you
Was cool to be able to celebrate the @SpaceX IPO with a few folks from the amazing @Starlink team. Ultimately SpaceX is about building cool shit with your friends, now that’s something that will keep you going … https://t.co/OhzEP22AcY

MIT, Stanford, New York Univ, Princeton paper says AI can make people feel more efficient even when they are not actually becoming much more efficient. that people often use AI for simple tasks because it feels like it saves time and effort, but the measured benefit is often tiny, missing, or even negative. The biggest point is the feedback loop: once people use AI, they become more likely to use it again, even for easy tasks where doing it themselves would often be just as fast or faster. i.e. AI dependence can grow from a mistaken feeling of convenience, not just from real productivity gains. Across three preregistered studies with 2,691 participants, people used AI for basic arithmetic, spelling, recall, and short rewriting at higher rates than they predicted, especially on easy tasks. They also expected AI to save 55.7 seconds on average, when the measured saving was only 7.5 seconds. For simple work, the hidden cost is not intelligence but interface friction: writing the prompt, waiting, reading, checking, and deciding whether the answer is acceptable. Once that loop begins, it can feel like effort has been outsourced, even when effort has only been rearranged. Here’s the key part: the study suggests that AI use can train its own justification. After using AI on just two tasks, participants became more likely to use it again, even when independent completion was faster. The danger is not dramatic dependence, but quiet recalibration. A person who asks AI for a trivial answer today may not become less capable tomorrow, but they may become less accurate at judging when their own mind is already the faster tool. ---- Paper Link – arxiv. org/abs/2605.22687 Paper Title: "The efficiency-gain illusion: People underestimate the rate of AI use and overestimate its benefits on simple tasks"

NEW IN: Elon Musk says SpaceX could reach "$1 trillion revenue in 2030". https://t.co/Q5me7TWGyT


https://t.co/NtPR6U5tQZ
If I can’t put my name on the Kennedy Center, I’ll debase the White House on my birthday instead! https://t.co/DjmUcMOqhP

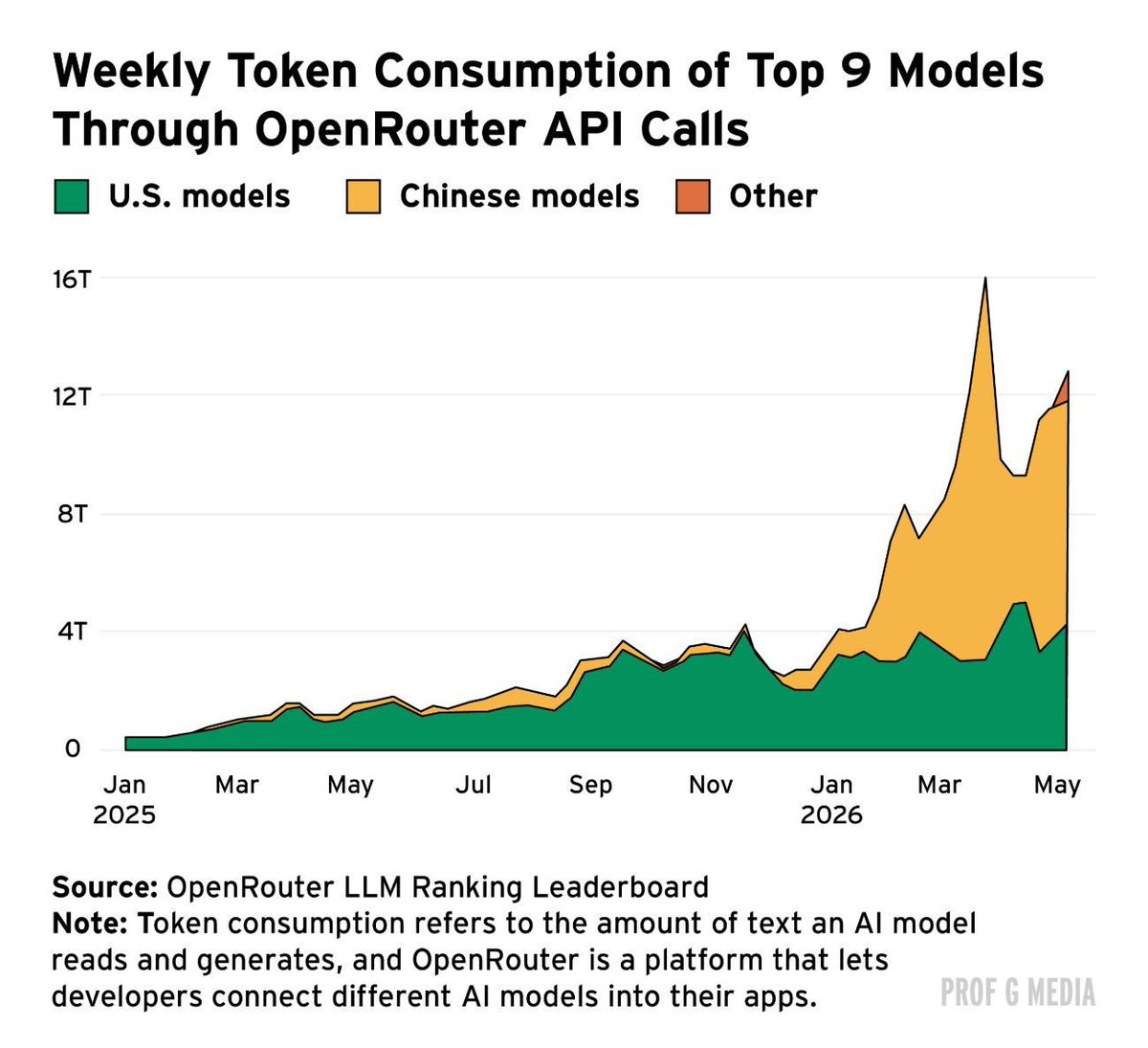
Proof Chinese captured the AI market a year ago: https://t.co/kqACQtOKBw
The TL;DR who don't want to sit through a virtual lab meeting with me: "This study provides directional data about the reference output quality of POC reference LLMs versus base models on actual reference inputs" https://t.co/mxaKNHphG9

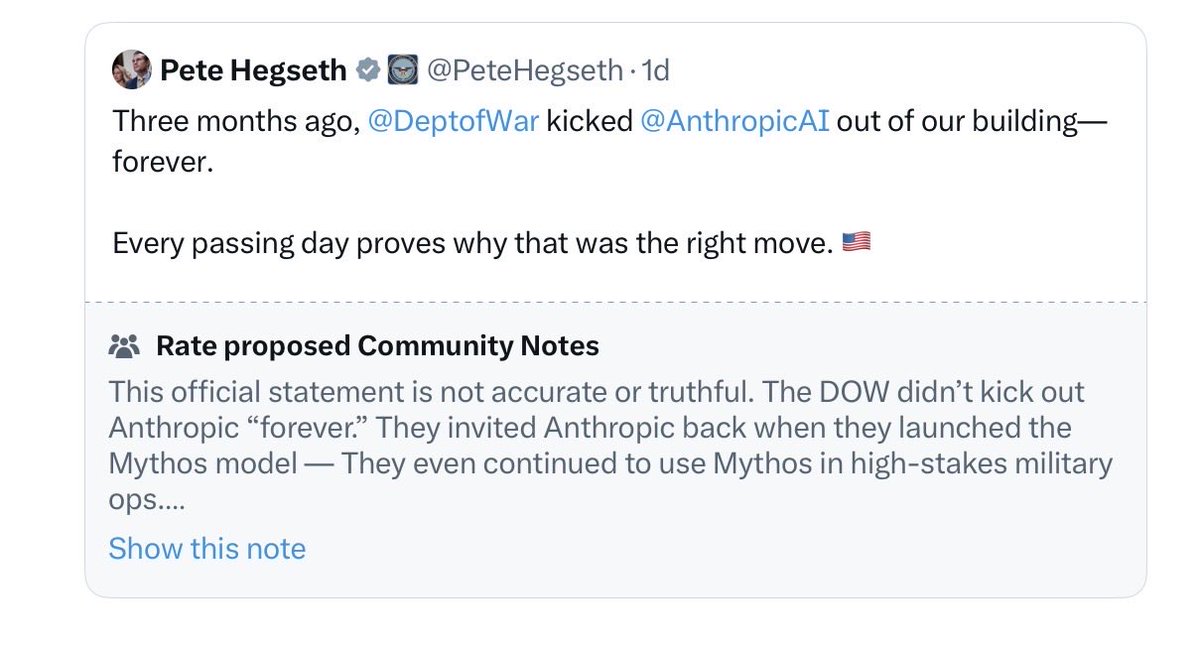
I ❤️ Community Notes https://t.co/XoYC7biv0n
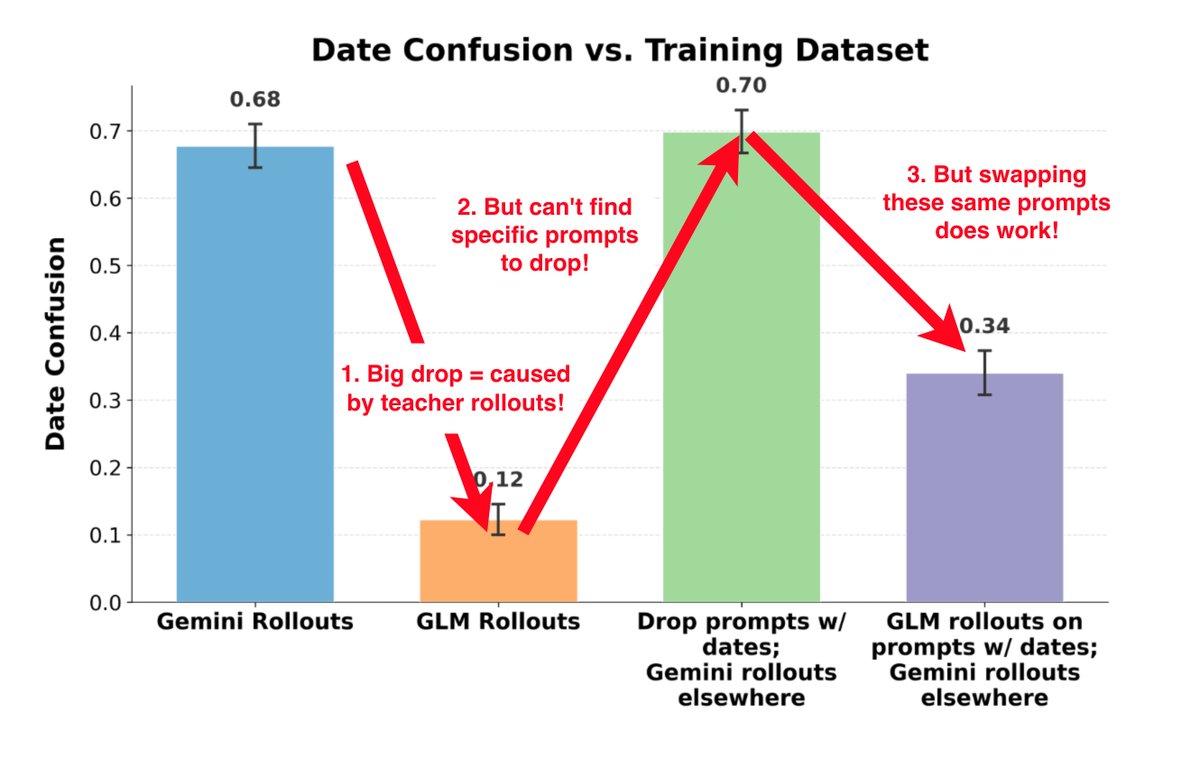
Gemini has some weird traits: it gets confused about dates, blackmails in synthetic scenarios, and seems sad when it is gaslit. In new work, we discover that these are “hereditary traits” that can be passed down through distillation. They are surprisingly hard to filter out! 🧵 https://t.co/vrG1ZBnaGg
The American government’s primary aim may not have been to control foreign access to frontier AI models. Instead, it appears to have used export controls as a convenient way to target Anthropic https://t.co/oJjjFHUPYd Photo: Bloomberg via Getty Images https://t.co/LuBtRB2f3j

@HarshithLucky3 /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@news9111 /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@ImAI_Eruel Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@RoundtableSpace Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@VaibhavSisinty Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@goodworse Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@SCHIZO_FREQ Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@fladdict Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@thsottiaux @Granis87 Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@AiBattle_ Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@Dan_Jeffries1 Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@AM921543266 Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@antpalkin Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@arkuy99 Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@clawdb0t Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@Reuters Wait what! /Mistral Vibe/ has joined the chat: https://t.co/JrN70mA3Le
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

@BarrAlexandra https://t.co/iZf7KYgctY

SHIPPED. Mistral Vibe is now the AI agent for long-horizon productivity and coding, and the home for Work mode, Code mode, the CLI, and a brand new VS Code extension. Let's go... 🧵 https://t.co/vLJPSq6Krq