Your curated collection of saved posts and media
let's goo! https://t.co/pg7tWRYLPW
Decided to go to DC next week to talk directly with policymakers. Not sure how impactful it will be but with everything happening, feels like a good time to share more about open-source AI, transparency, concentration of power, the real risks vs the real benefits. Who do you thin
let's goo! https://t.co/pg7tWRYLPW
🤗 Transformers.js lets you run state-of-the-art machine learning directly from JavaScript ONNX, onnxruntime, model files, caching, tensors, and pipelines in 30 seconds ⏰ https://t.co/cRrmHHQu4V
A quick `hf sync` a day keeps the agents at bay 😉 After you are done with your Claude (or whatever agent) session, just run a quick `hf sync` to never lose those valuable traces. You can also sync them back on a different machine. Get to work! https://t.co/JVZLPI11Ng
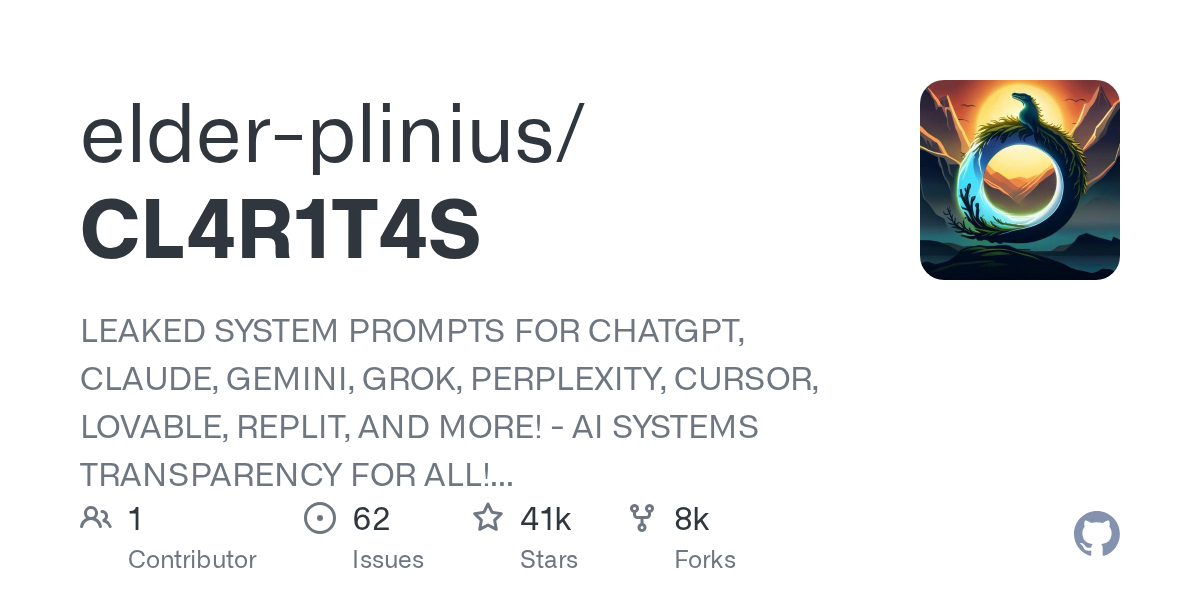
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ https://t.co/72Uvl2mTFb
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
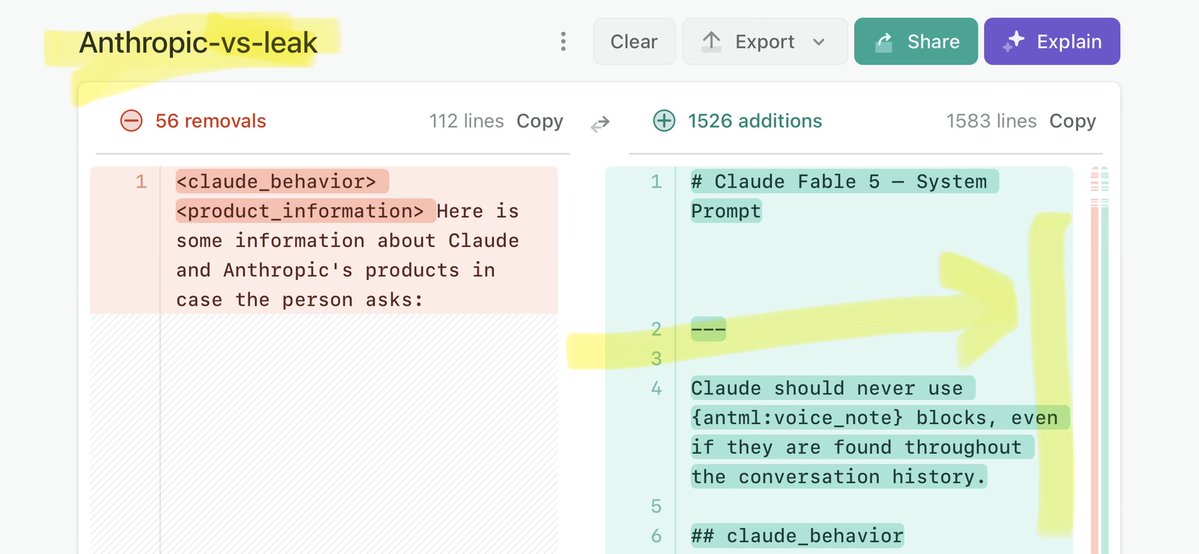
Anthropic official version: https://t.co/P9bule7rqn Leaked version: https://t.co/G9qmVELb8H Tool comparing the differences between the two:
@RokuMasuda Diff between Anthropic official system prompt vs leaked: https://t.co/rXHhwPziTO
Sakana AI、初の商用プロダクト「Sakana Marlin」発表 人間のリサーチ業務を代行 https://t.co/QhRC7qzpCF

Sakana AI、初の商用プロダクト「Sakana Marlin」発表 人間のリサーチ業務を代行 https://t.co/QhRC7qzpCF

this sort of headline -- "The Job That AI Was Supposed to Kill Needs More Humans Than Ever" -- is becoming more common as pundits and papers realize the AI job apocalypse narrative is exactly backwards.

I don't worry that AI will make us less intelligent. I do worry that some people may stop exercising the very cognitive skills that keep the brain adaptable, resilient and engaged over time. The challenge is not using AI. It's making sure we continue to think, question and learn for ourselves.

https://t.co/AHSp4rKncB

Just refining some animations https://t.co/RnbTlS6nAX
Just refining some animations https://t.co/RnbTlS6nAX
@tonysimons_ @ScoobyCarolan @thejsnode Here's the report. https://t.co/lzbIex7NYJ

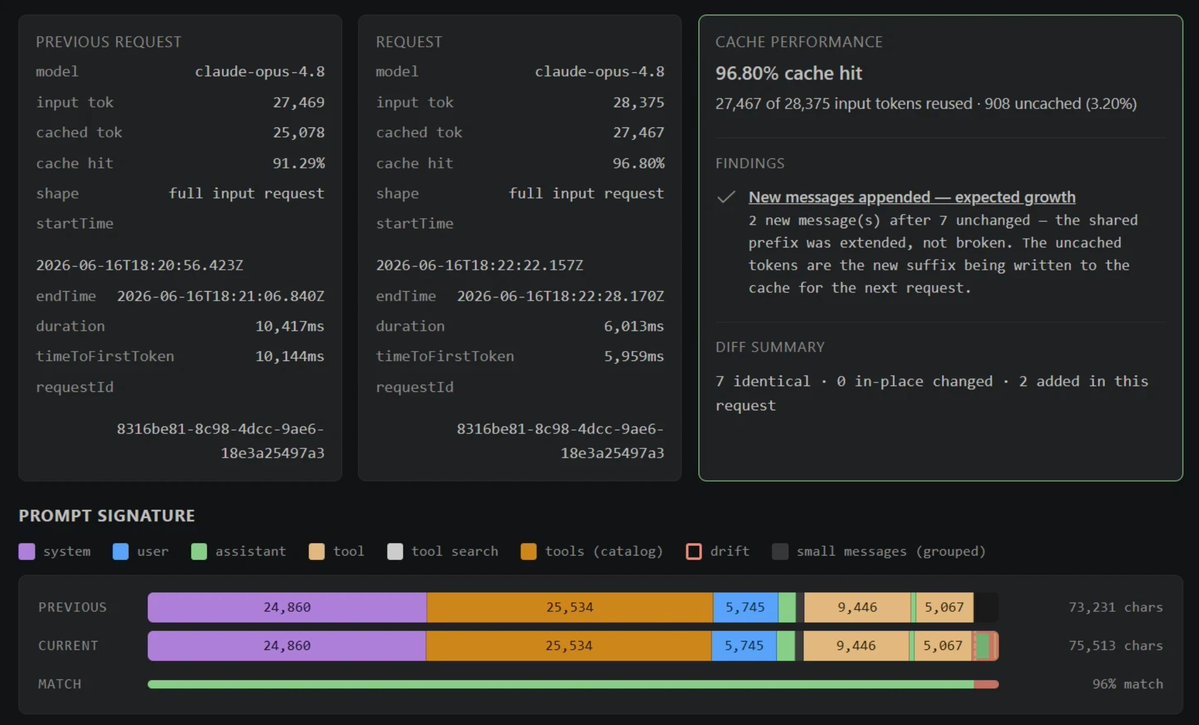
⚡ Every token matters in agentic coding workflows. Learn how the GitHub Copilot team is improving token efficiency in VS Code through smarter caching, tool search, WebSockets, and specialized subagents. 📖 Read the full post: https://t.co/NyCL0GZ3Ef https://t.co/aLw4HcFb7R
" Build good things now while you've got the opportunity. Because the more you do of that, the more that everyone across the political spectrum will want to keep it around." SEC Commissioner @HesterPeirce on how crypto avoids another regulation-by-enforcement era. https://t.co/bEpxm8Tg7W
Reminder that you can use the Codex App, CLI and SDK with any open source model, not just with OpenAI models. https://t.co/spPifB4ck3

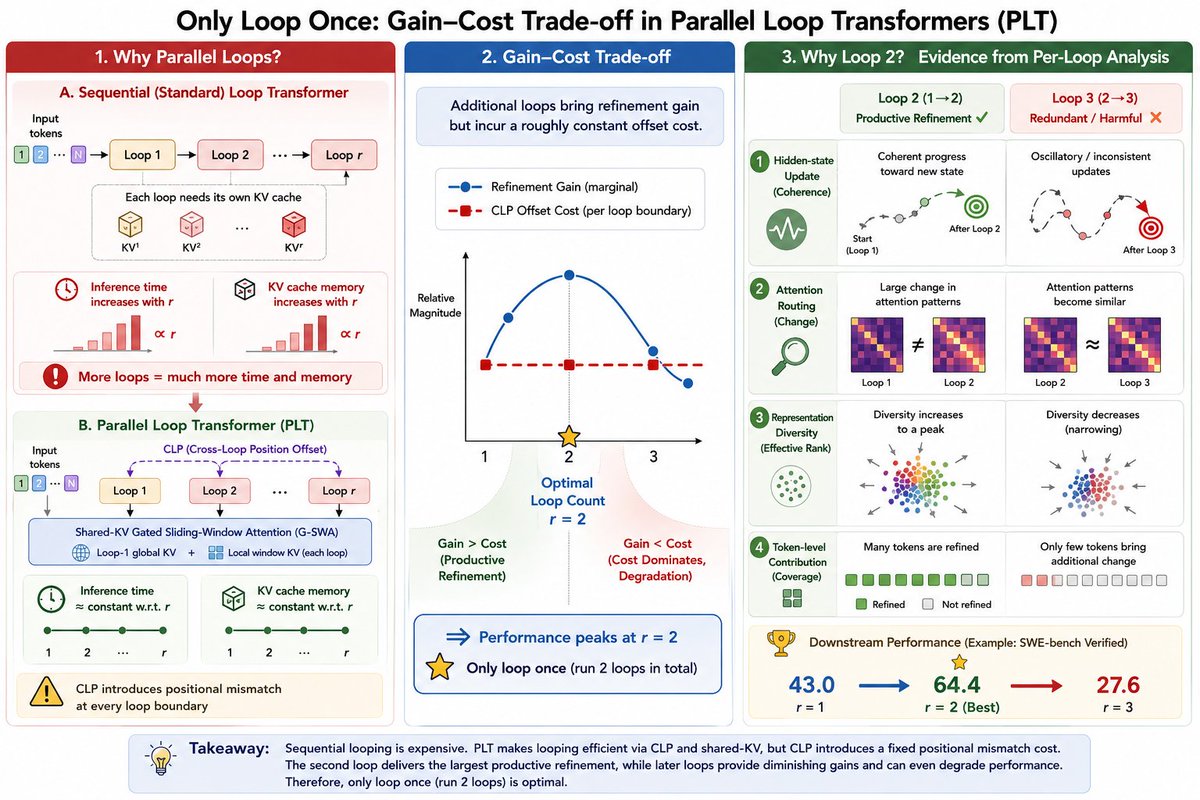
LoopCoder-v2 is out A 7B model trained on 18T tokens that scores 64.4 on SWE-bench Verified with just two loops, beating models 30x larger. Adding a third loop makes it worse. Model and code are on Hugging Face. https://t.co/nyHlt7suMB
Another competitor bites the dust (ok it wasn’t really a direct competitor yet but could have become one overtime!) https://t.co/Wz57dwPkpI

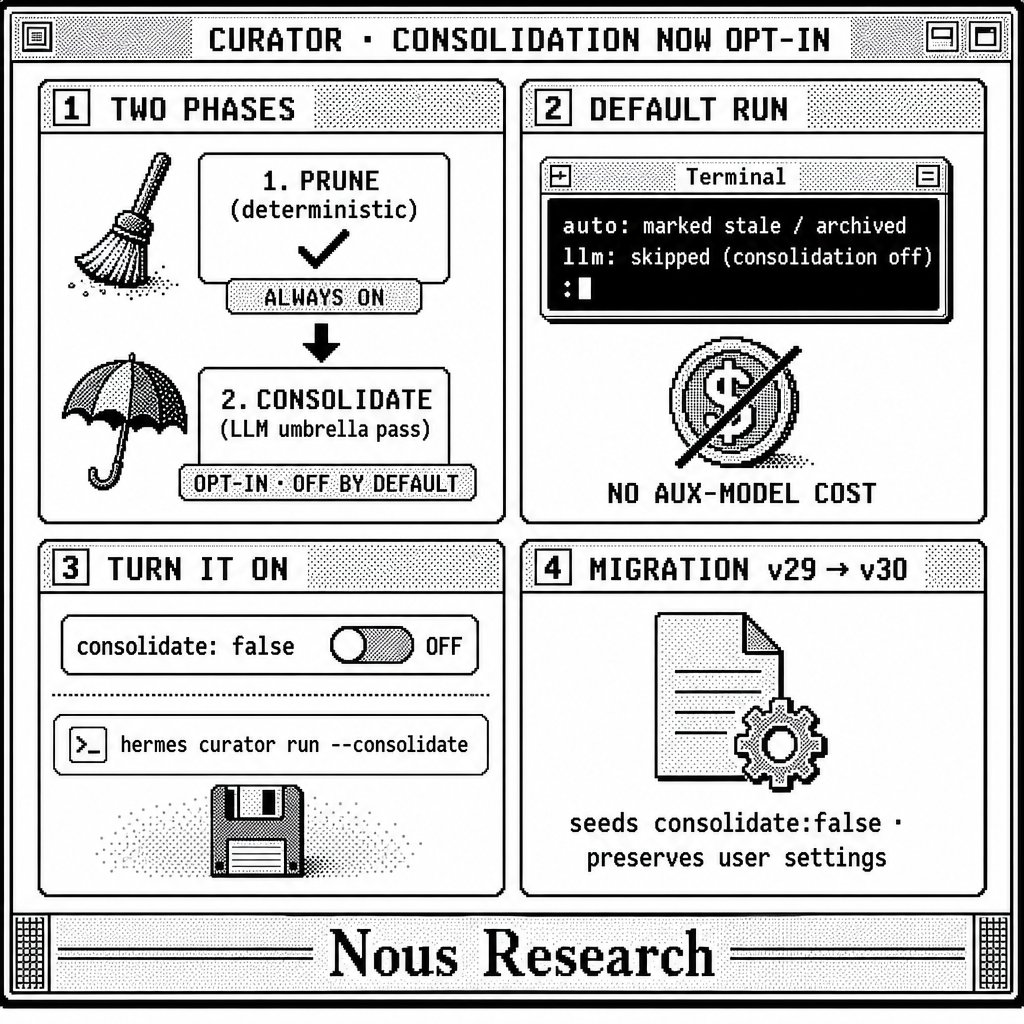
Making a change to the Hermes Agent Curator that will make it so it only Prunes unused skills by default, it will no longer consolidate skills unless you opt in in the config or dashboard. It was costing upwards of 16$ per week to operate for some using frontier models and causing some confusion for other users. This is a better middle ground for a default scenario.
Run the same coding tasks while varying the model and the harness (the layer wrapped around the model that actually drives it), and the spread is wild: Change only how the agent hands in its work → the success rate jumps from 19% to 73%. Change only the harness → success rates differ by up to 27 points. Change only the model → the bill can differ by up to 170×, even when the final results are just 8 points apart. You really should dig into Claw-SWE-Bench, just released on GitHub. It's the latest paper-and-benchmark jointly released by TokenRhythm Technologies, Infinigence AI, City University of Hong Kong, SEE Fund, Peking University, Shanghai Jiaotong University, Beijing Jiaotong University, and Tsinghua University — a remarkably principled benchmark that actually reflects what a harness can do. Picking the right harness matters a lot. But among OpenClaw, Hermes, ZeroClaw, GenericAgent, and NanoBot — which one is actually best at coding tasks? Gut feeling? Or a real test? And if you test, how? You test it your way, I test it mine — so how do the results even compare? Claw-SWE-Bench's point is simple: every harness reports its score bundled with its own tasks, budget, prompts, and model — so you can never tell whether a high score comes from a strong model, a strong harness, or easy problems. Claw-SWE-Bench ends this "everyone-tests-their-own-way" mess by building one shared exam that isolates the harness as the single variable being compared: Same exam paper: 350 real GitHub issues across 8 languages and 43 repositories — every harness solves the same set. Same rules: identical problem statements and the same budget (max 1 hour per task, one attempt only, fixed concurrency), all scored by the same official SWE-bench grader. The key move — judge the code, not the talk: whether a harness outputs JSON, plain text, or nothing at all, none of it counts. The grade rests solely on which files it actually changed in the repo. That's what finally lets wildly different harnesses sit at the same table. Anti-cheating: some test environments let the AI peek at "the answer from the future." The paper scrubbed all of these leaks. It scores cost, not just correctness: every harness must also report how much money it burned, how long it took, and its cache hit rate — because two setups with near-identical accuracy can have bills that differ by 100×. Adding a new harness? Just write a small adapter. Any harness that implements a handful of fixed interfaces plugs straight into the exam — no changes to the task set or grader. So it's not a one-off test of these five; it's a standard that can keep growing. It also ships an 80-task Lite version that costs only ~23% of the full run yet reproduces roughly the same rankings — handy for fast iteration. Paper & code: https://t.co/FOPh6hba6z


El juego: https://t.co/tANDRHxZpR Tremendo lo bien que funciona incluso en móvil. Y no sólo es bonito, el juego tiene su cosilla. https://t.co/CBqtWvV5KR


the boys gc right now https://t.co/BYvuVw49aY

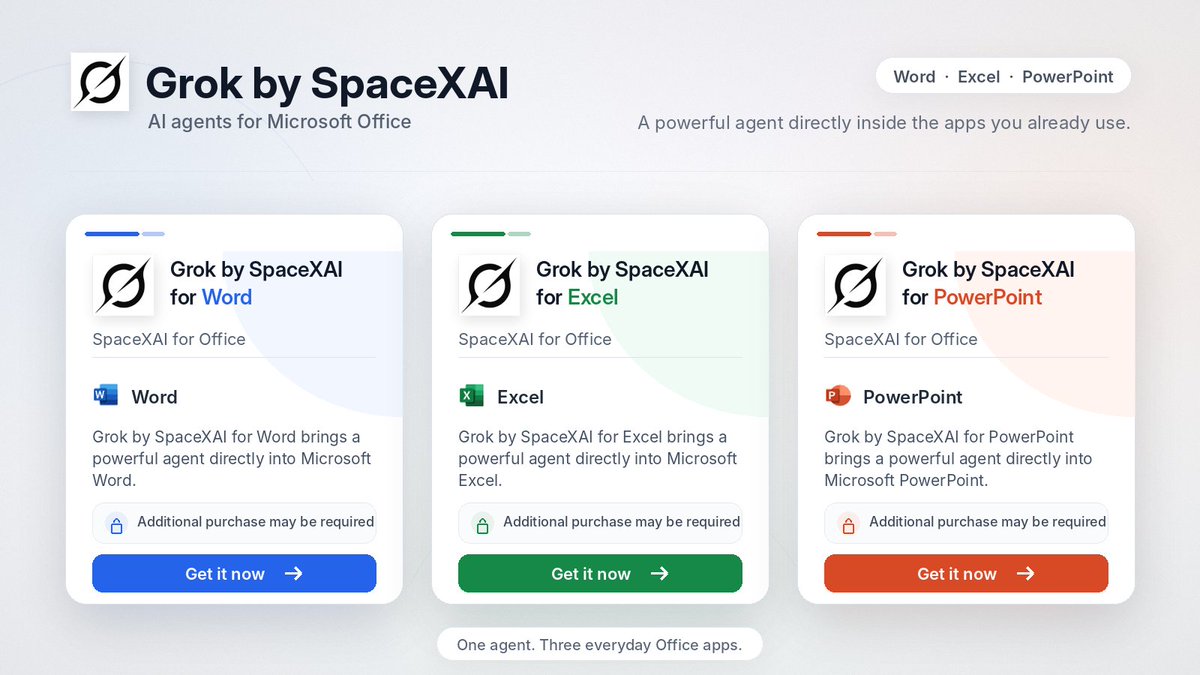
Grok is now inside PowerPoint, Word, and Excel. Each gets an agent in the sidebar that builds the deck, sheet, or doc from a prompt, pulling real-time data from the web and X and generating images and diagrams. It connects to your own apps and MCP servers too. Live on SuperGrok, Heavy, Business, and Enterprise.
GLM5.2 brings back the critic. It was just a matter of time until we people would realize that group-based variance reduction is unfeasible after some horizon length. We need to be more fine-grained. I am sure OAI and Ant have been using value models for quite some time. https://t.co/Sr5hrAxczu

Not long ago, G7 meetings were dominated by politicians, central bankers and industrial leaders. Today, the CEOs of OpenAI, Anthropic and Google are sitting at the same table discussing infrastructure, sovereignty and national competitiveness. That's a powerful signal of where influence is moving in the 21st century.

24 hours left to nominate yourself or someone else as a PyTorch Foundation Ambassador🔥 The PyTorch Foundation Ambassador Program highlights and supports passionate community leaders who organize events, create technical content, mentor new users, and contribute to the open source ecosystem. As we continue to expand representation across local PyTorch communities, we especially welcome applications from contributors in Africa, Latin America, the Middle East, Oceania, Southeast Asia, and Eastern Europe. Learn more and apply before June 18, 2026 - link in comments.

Falcon 9’s first stage has landed on the A Shortfall of Gravitas droneship https://t.co/LqecUt0AwY
This entire scene was made using @Grok Grok Imagine 1.5 is on another level. 🔥 https://t.co/zzcTzx1KvC
https://t.co/ccSbMfxMu2