Your curated collection of saved posts and media
@FT https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@MetacriticCap https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@jackprice https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@Spshulem https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@FT https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@ryanbrewer https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@business https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@Polymarket https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@ClaudeDevs https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@bridgemindai https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@TheEconomist https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

What does a real workday using the GitHub Copilot app look like? 🤔 We sat down with @pierceboggan to see how he uses the Copilot app to focus on the work that matters and carry it from issue to merge. https://t.co/En7wXo1zS9
Try out the GitHub Copilot app yourself. ⬇️ https://t.co/SiEBSwHJJg

@kinopee_ai https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@arstechnica https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@business https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@TheEconomist https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

GDPval-AA v2 is the highest weighted evaluation in the Intelligence Index v4.1. The upgrade re-baselines ELO to human performance at 1000, introduces a rotating panel of frontier-model judges, and raises the turn limit from 100 to 250 for longer-horizon agent trajectories. Claude Fable 5 (with fallback) leads at 1818, followed by Claude Opus 4.8 (1638). GPT-5.5 (xhigh) scores 1531. Claude Fable 5 is not currently available for use
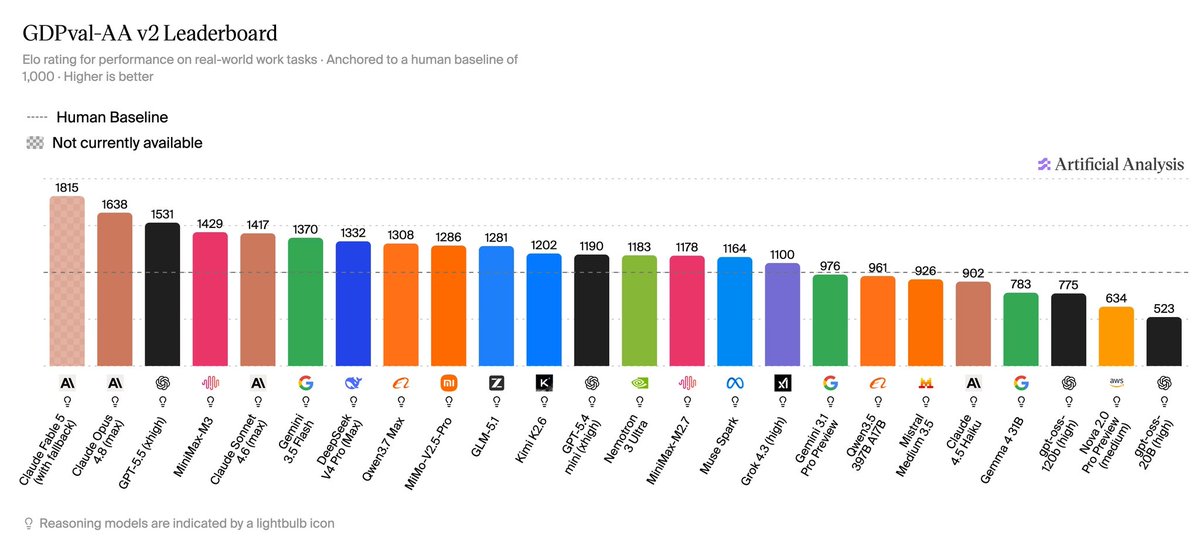
This was not a good benchmark before it was updated and it is not a good benchmark now. Having AIs evaluate the work of other AIs on publicly available questions from a different closed benchmark doesn’t tell you very much. And it is unclear how they establish the human ELO. https://t.co/tmZG8MDkRA
GDPval-AA v2 is the highest weighted evaluation in the Intelligence Index v4.1. The upgrade re-baselines ELO to human performance at 1000, introduces a rotating panel of frontier-model judges, and raises the turn limit from 100 to 250 for longer-horizon agent trajectories. Claude

why wouldn't Elon take just a tiny slice of the capital he just raised, let's say $2B, and buy more #BTC at these depressed levels? @elonmusk https://t.co/Emf4vNDWE2

@GaryMarcus https://t.co/1jDUxuv8u6

did you get your tickets for AI Engineer SF? I'll be giving a talk (and following tibo) as well as a workshop on setting yourself up with success with codex https://t.co/Cus3e75cUM

come say hi, get your tickets here https://t.co/5hy51RFSGh

thanks @_akhaliq for sharing our Data2Story! 🔮Turn the ‘Humanity's Last Exam’ dataset into a generative blog. Explore more agent-generated stories here https://t.co/TIIMWBamyU https://t.co/FU6uAqKdgV
Data Journalist Agent Transforming Data into Verifiable Multimodal Stories https://t.co/11SNrYxNyp
if you want clarity on what the differences are https://t.co/Iw60pdzZje
https://t.co/e9PrQGAqZT

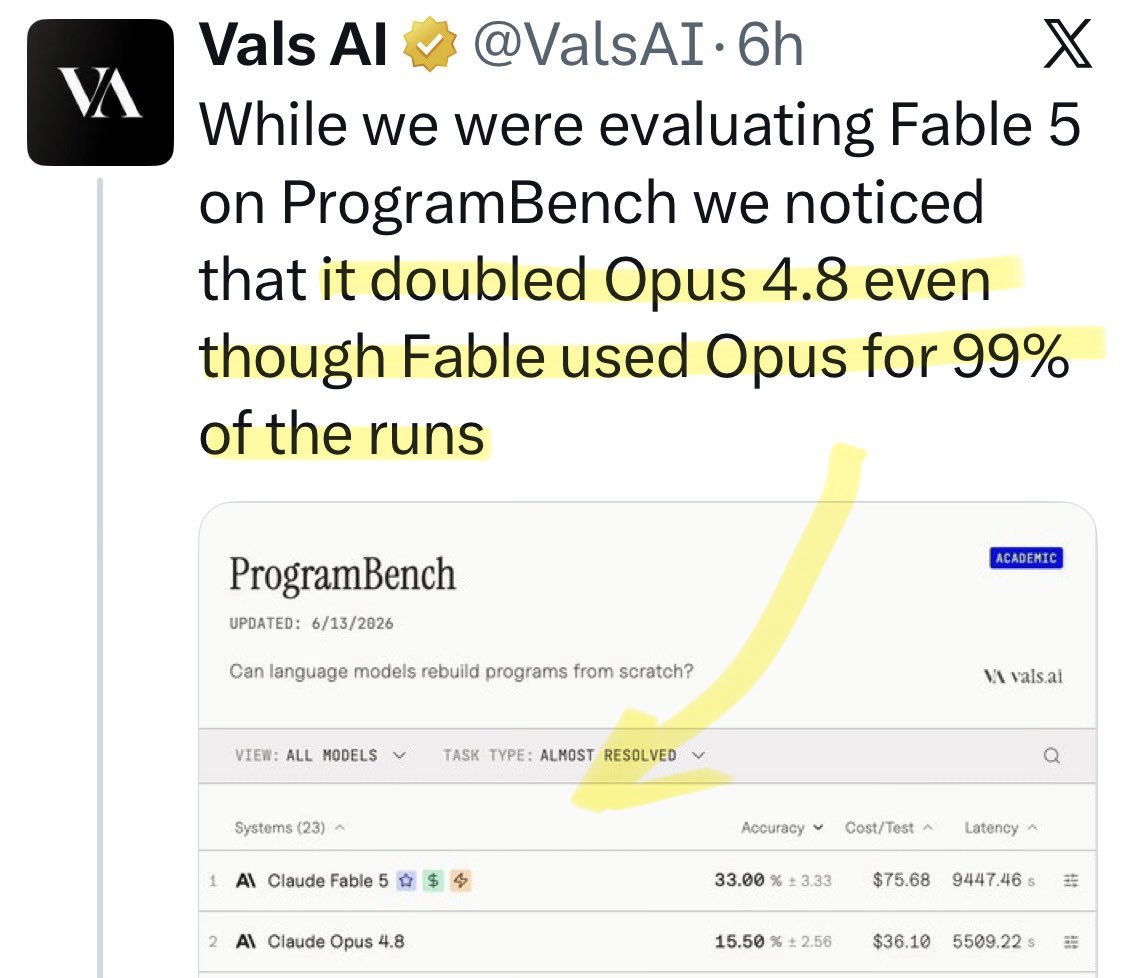
@kinopee_ai Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
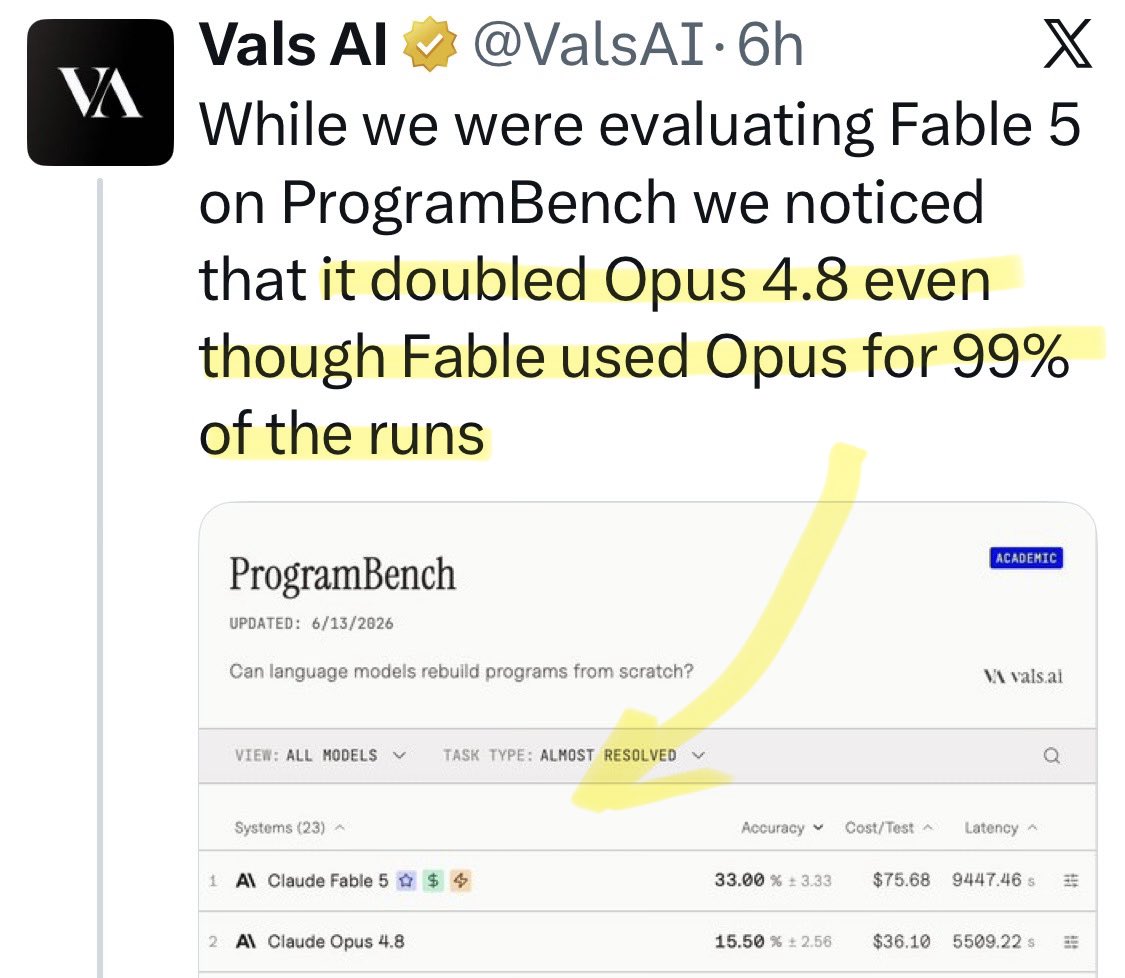
@Alfred_Lin Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
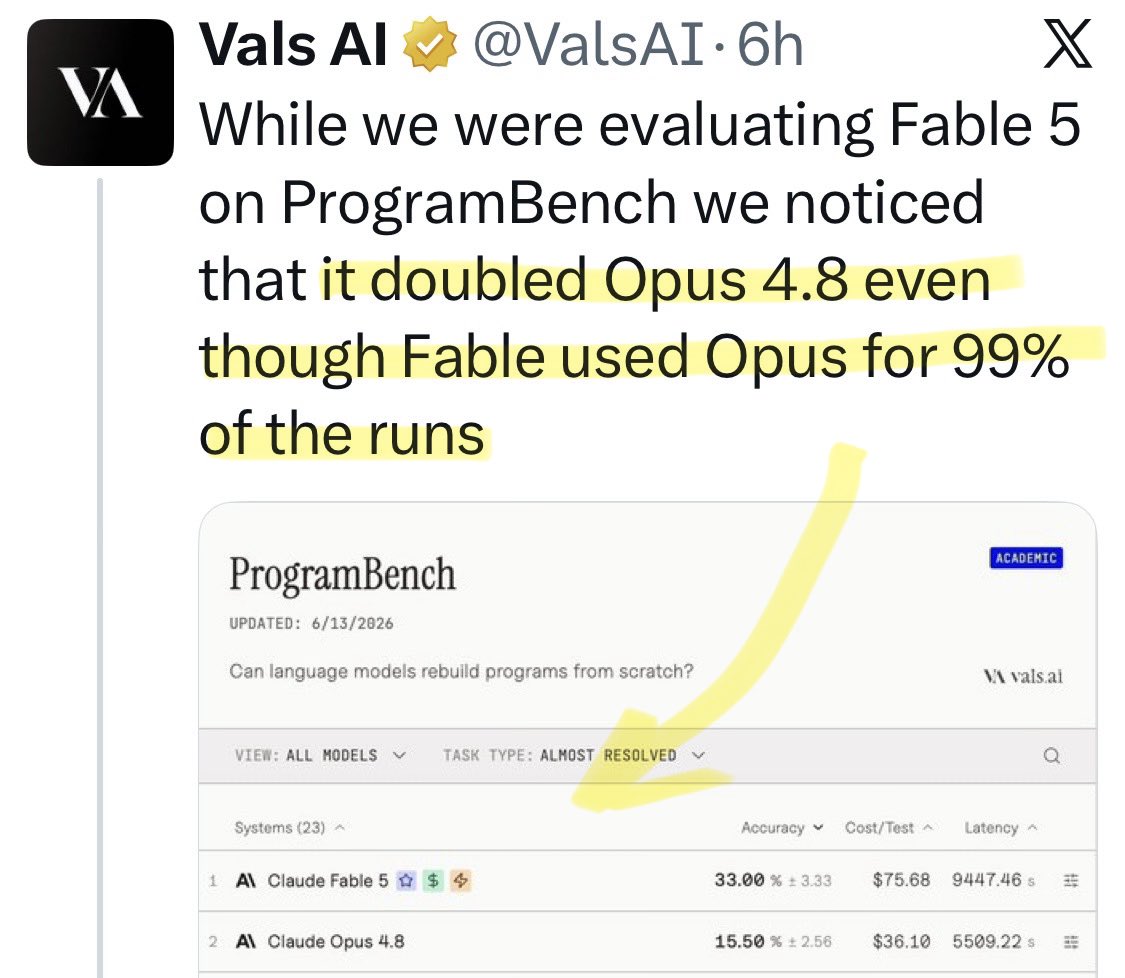
@Polymarket Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
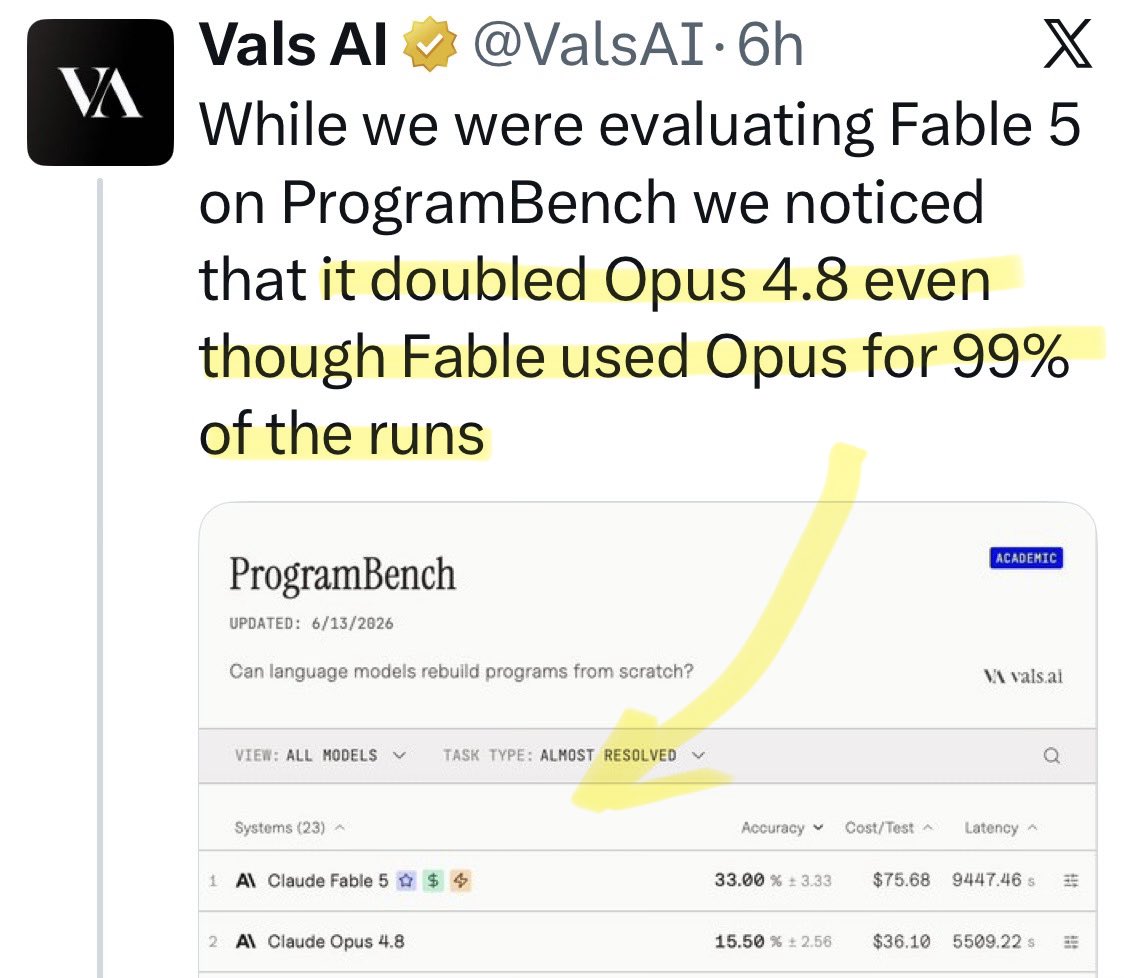
@NewYorker Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
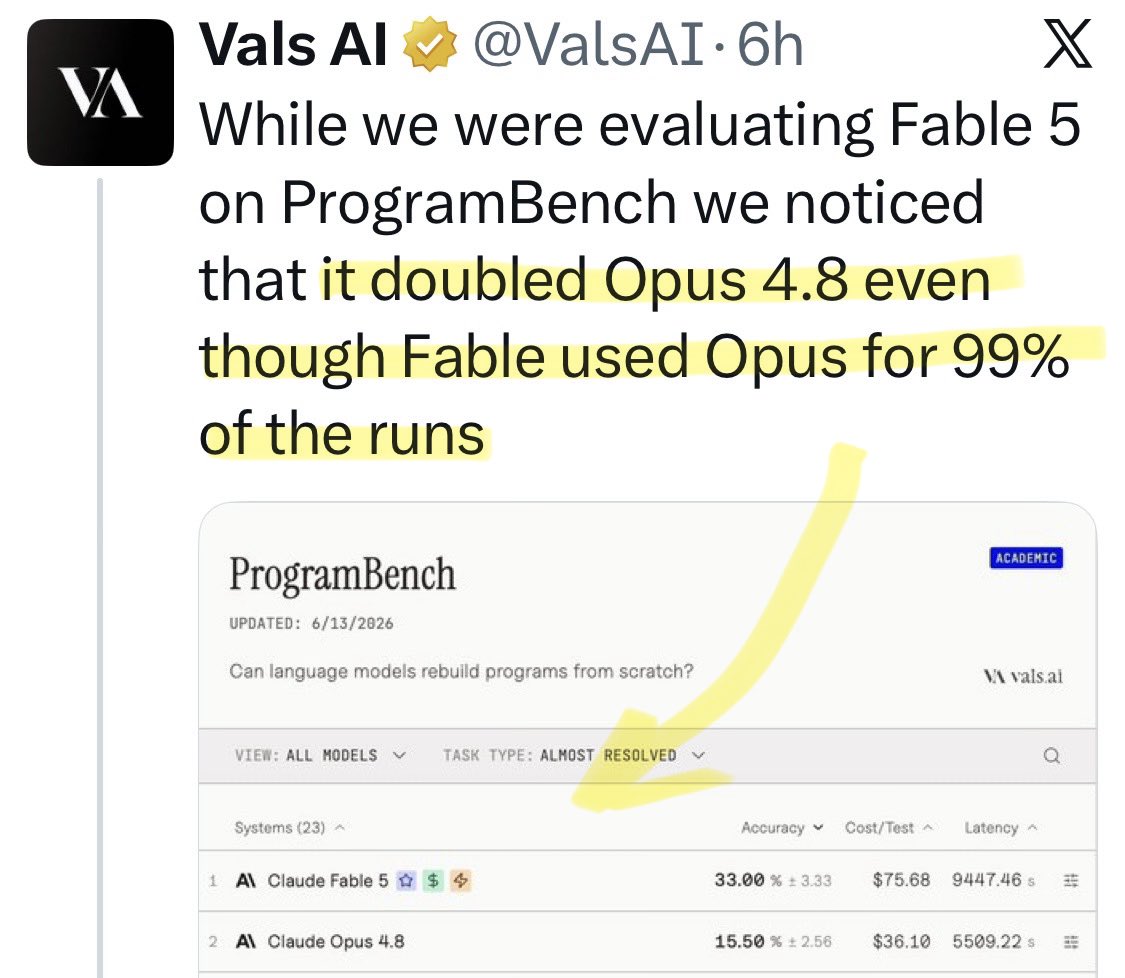
@FT Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
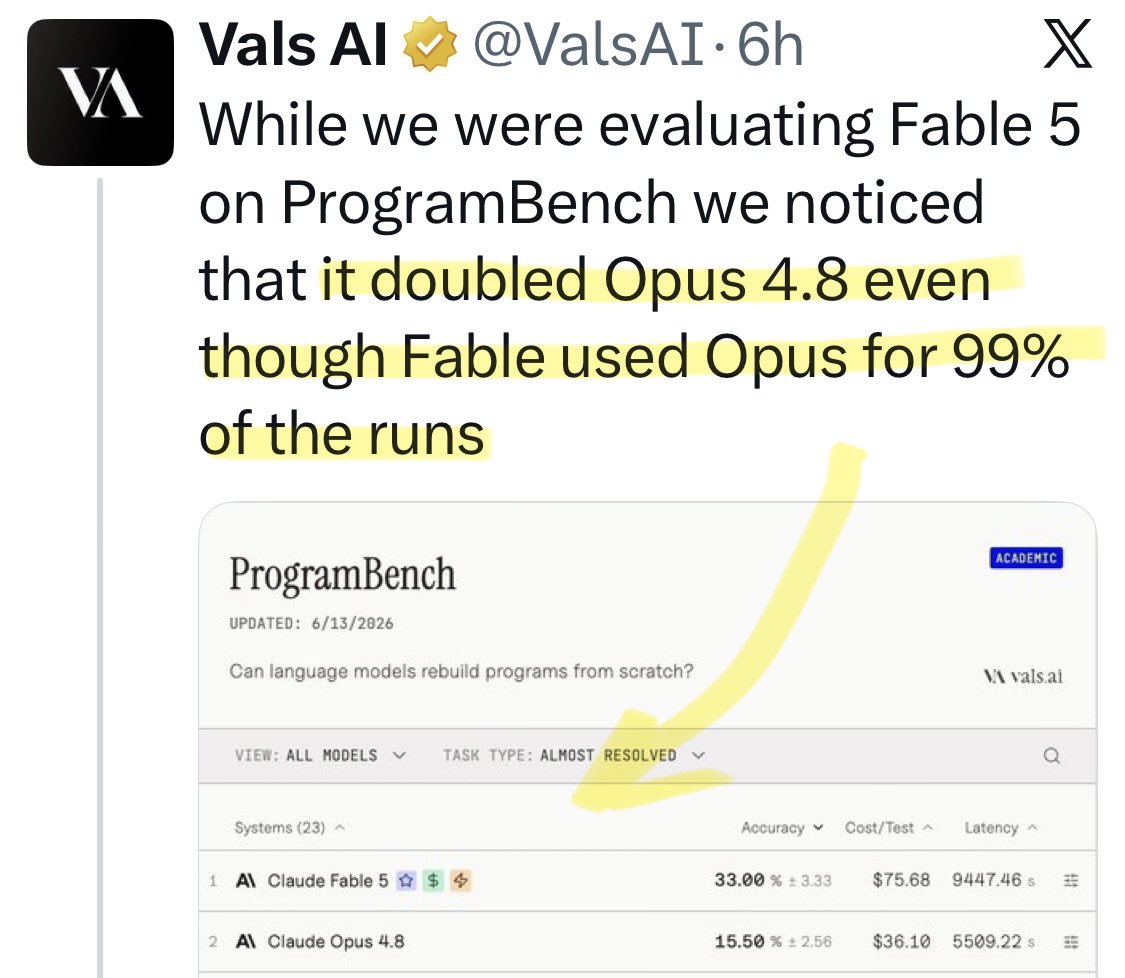
@yuno_miyako2 Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H
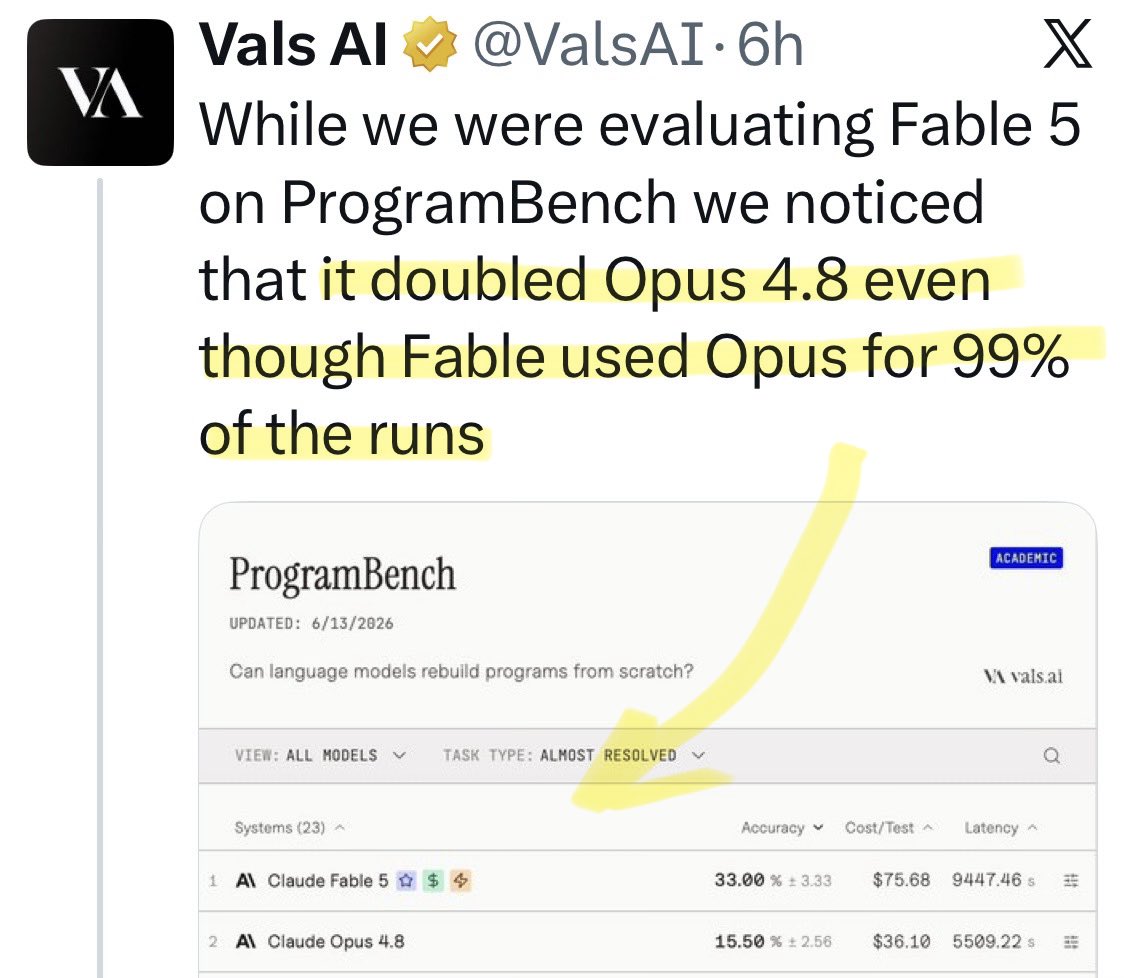
@suna_gaku Update: a new benchmark shows [Opus x Fable] gap may be better explained by prompting not weights: https://t.co/0v5qNCnVrl
🚨 New @ValsAI benchmark confirms Claude Fable little secret How is Opus-through-Fable outperforming vanilla Opus? Simple. The model isn’t the star here. It’s the *agentic loop* doing all the work. Anthropic didn’t tell anyone. Full analysis: https://t.co/6tYxEWw67H