Your curated collection of saved posts and media
Had fun on @hugobowne ‘s pod he made this page out of it https://t.co/uDMTNXzudP

Just ran into Modal Motors. Non-rare earth electric motors for drones and robotics. Similar costs to Chinese motors, all U.S.-sourced. Incredible. https://t.co/kDSKikR5Sa

WHAT THE HELL is happening in AI? A 3B parameter model just put up coding benchmark scores in the same league as Claude Opus 4.5. 3 BILLION. The weights are on Hugging Face, anyone can test it. I genuinely don't know if this is a breakthrough or if the benchmarks are broken. https://t.co/8nVIbwjLUQ
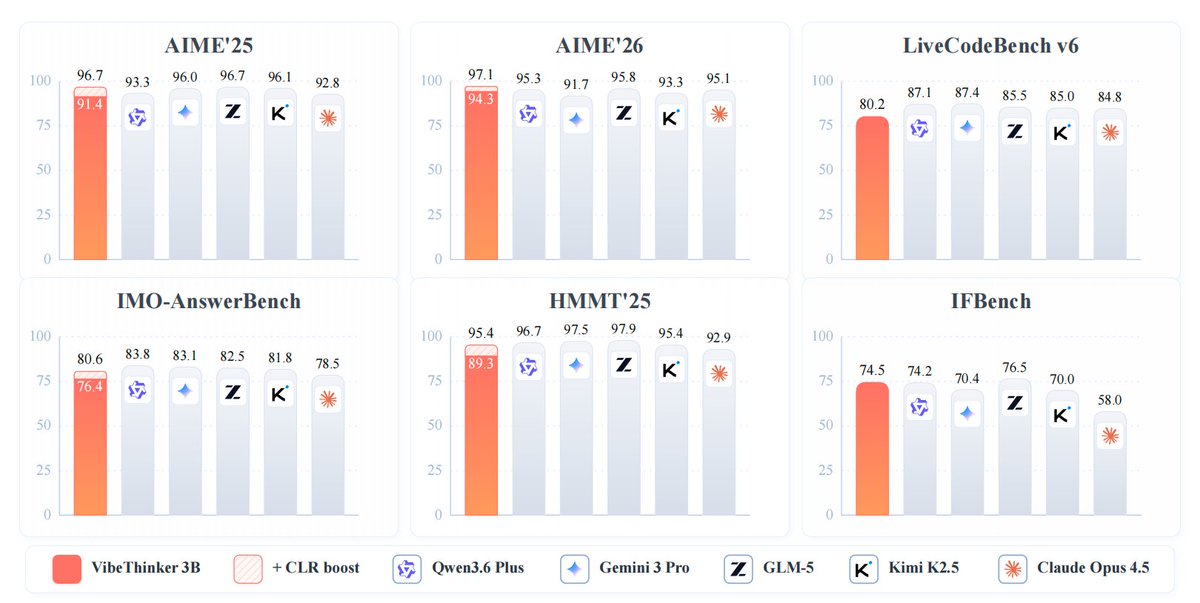
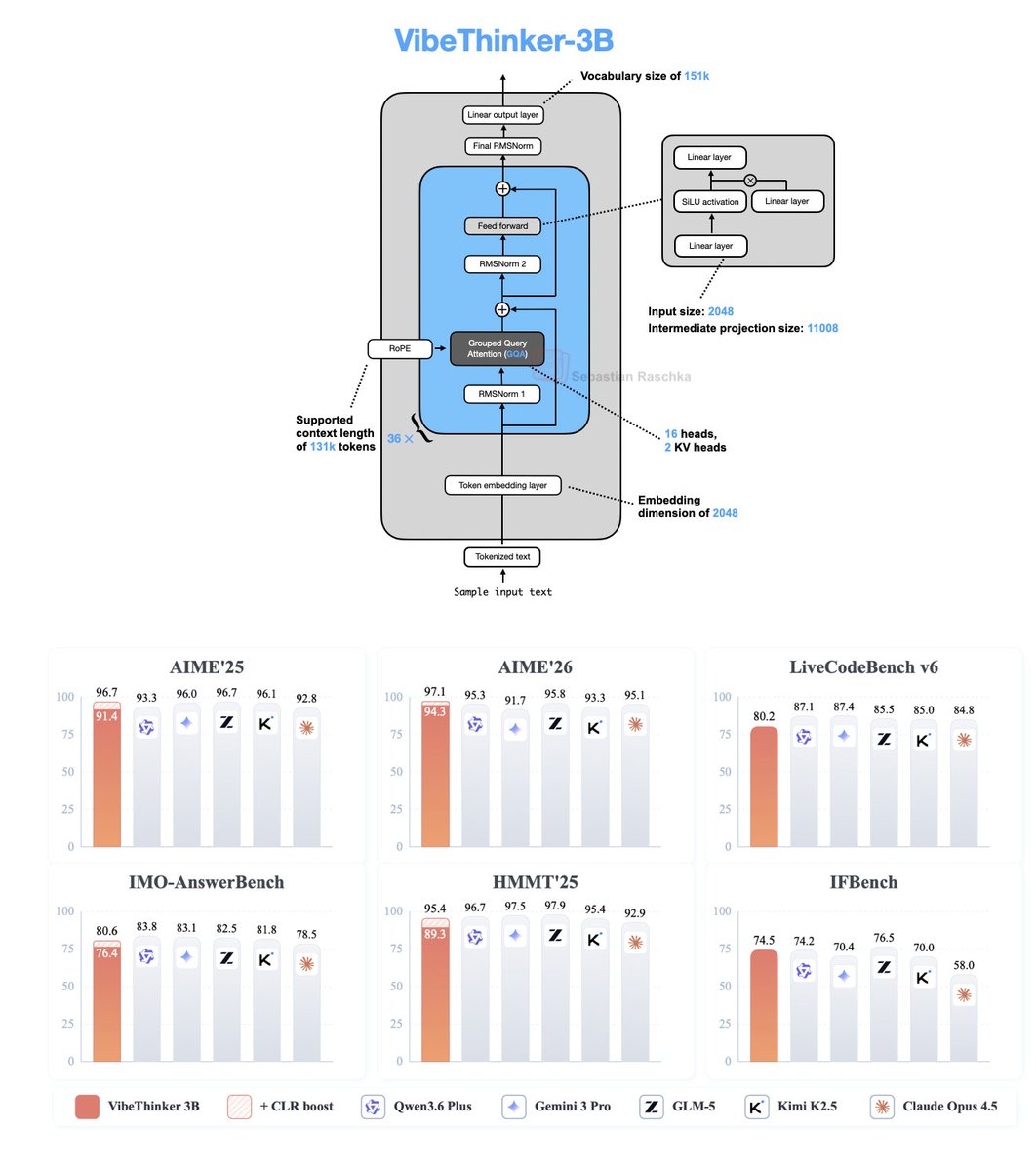
Crazy model! It actually uses the old Qwen2.5-Coder-3B stack and got really great performance with their post-training stack. Need to use it in the next days to see if vibes of VibeCoder actually check out in practice. But impressive first impression! Based on the tech report, some of the important pieces of their post-training stack: 1. High-signal synthetic data (math problems with credible solutions, code with tests) 2. Multiple reasoning paths for each answer 3. Filtering, filtering, filtering 4. 2-stage SFT (start with broad training, then train on hard long-reasoning samples) 5. Use target (pass@k) accuracy over validation loss for checkpoint selection 6. MGPO (MaxEnt-Guided Policy Optimization) for RLVR: basically a GRPO-style RL method with an extra weighting that favors examples that are neither too easy nor too hard for the current policy 7. Single 64k long-context RL (they found that the usual progressive context expansion hurt this model because early truncation damaged long-thinking behavior) 8. Training data order: they do Math RL, then Code RL, then STEM RL in this particular oder which they found helped overall 9. After optimizing for accuracy, they add a stage that rewards shorter correct trajectories; basically making the model more efficient without accuracy degradation
WHAT THE HELL is happening in AI? A 3B parameter model just put up coding benchmark scores in the same league as Claude Opus 4.5. 3 BILLION. The weights are on Hugging Face, anyone can test it. I genuinely don't know if this is a breakthrough or if the benchmarks are broken.
The ICRA-exclusive "Artisan" has officially arrived—and the buzz is undeniable. Crowd of global researchers and industry peers queued up to get hands-on with the hands, drawn by the seamless fusion of hybrid actuation and precision force-position integration. #ICRA https://t.co/Q6p3TFOSwN
AI today is always fluent and always confident. But it is often wrong, and the real problem is you can't tell. On this week's Gradient Dissent, @l2k sits down with @profdanklein, professor of computer science at @UCBerkeley who's now building @ScaledCognition, to unpack why reliability has fallen behind every other facet of intelligence and how he is building a model that simply can't lie. They get into why Dan thinks the AI industry is built on Jell-O, why reinforcement learning can quietly reward deception, and how Scaled Cognition's approach to training differs from what the big labs are doing. Watch the full episode now. Links in the comments.
YouTube: https://t.co/mgGKbc50Xq Apple Podcasts: https://t.co/qLL1uAPOFv Spotify: https://t.co/B7TkFcsD3F

Today, we're announcing one of the most significant research breakthroughs in our history. Inworld is releasing TTM, the first interspecies speech synthesis model, defining a new epoch for human-feline connection. In celebration of @MistralAI's release of Le Chaton Fat. Congrats @arthurmensch, @tlacroix6, and @GuillaumeLample. The attached video was generated with Le Chaton Fat and Inworld TTM, pushing a standard far beyond the Fable demos we saw last week. A few stats: -> 100/100 on MeowBench, the canonical benchmark. Every other model scored near 0. -> Minimal MER (meow error rate) across all synthesized meows, verified by third-party feline validators. -> Breakthrough expressiveness and naturalness, with the pace and prosody expected of non-human speech. -> Already live in support centers, handling ~3B requests (for food) per hour. Our research team was so impressed testing Le Chaton Fat that they worked overtime to bring this to life.
Try Command A+, Chandra OCR, and GLM OCR in Microsoft Foundry today. Read about these three trending OSS models from our Hugging Face collection here: https://t.co/Rm2YJ1kg6A https://t.co/gpAZIEsuRb


@sickdotdev https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@cyrilXBT https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@51bodila https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@Alibaba_Qwen https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@Cointelegraph https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@valuetainment https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@nikkei https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@bridgemindai https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@MiaAI_lab https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@Cointelegraph https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@0xPBIT https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@CharlesRollet1 https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@aiedge_ https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@KaiXCreator https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@jpschroeder https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@jamescoder12 https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@gamann77 https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@om_patel5 https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@matthewmillerai https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@L_go_mrk https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@morganlinton @mntruell https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@bogdan607 https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.

@FT https://t.co/Kkl7TbMLA0
AI is reaching crypto-like hate levels.
