Your curated collection of saved posts and media
Another competitor bites the dust (ok it wasn’t really a direct competitor yet but could have become one overtime!) https://t.co/Wz57dwPkpI

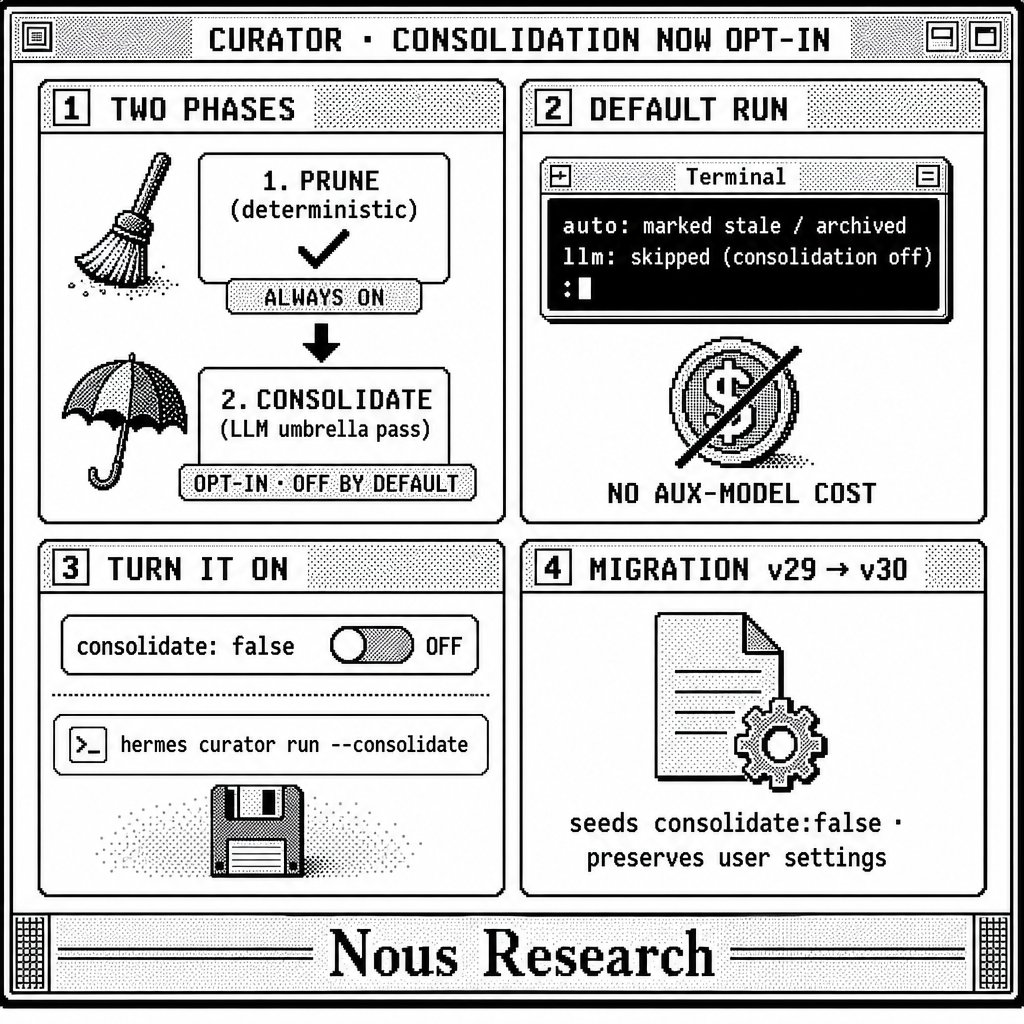
Making a change to the Hermes Agent Curator that will make it so it only Prunes unused skills by default, it will no longer consolidate skills unless you opt in in the config or dashboard. It was costing upwards of 16$ per week to operate for some using frontier models and causing some confusion for other users. This is a better middle ground for a default scenario.
Run the same coding tasks while varying the model and the harness (the layer wrapped around the model that actually drives it), and the spread is wild: Change only how the agent hands in its work → the success rate jumps from 19% to 73%. Change only the harness → success rates differ by up to 27 points. Change only the model → the bill can differ by up to 170×, even when the final results are just 8 points apart. You really should dig into Claw-SWE-Bench, just released on GitHub. It's the latest paper-and-benchmark jointly released by TokenRhythm Technologies, Infinigence AI, City University of Hong Kong, SEE Fund, Peking University, Shanghai Jiaotong University, Beijing Jiaotong University, and Tsinghua University — a remarkably principled benchmark that actually reflects what a harness can do. Picking the right harness matters a lot. But among OpenClaw, Hermes, ZeroClaw, GenericAgent, and NanoBot — which one is actually best at coding tasks? Gut feeling? Or a real test? And if you test, how? You test it your way, I test it mine — so how do the results even compare? Claw-SWE-Bench's point is simple: every harness reports its score bundled with its own tasks, budget, prompts, and model — so you can never tell whether a high score comes from a strong model, a strong harness, or easy problems. Claw-SWE-Bench ends this "everyone-tests-their-own-way" mess by building one shared exam that isolates the harness as the single variable being compared: Same exam paper: 350 real GitHub issues across 8 languages and 43 repositories — every harness solves the same set. Same rules: identical problem statements and the same budget (max 1 hour per task, one attempt only, fixed concurrency), all scored by the same official SWE-bench grader. The key move — judge the code, not the talk: whether a harness outputs JSON, plain text, or nothing at all, none of it counts. The grade rests solely on which files it actually changed in the repo. That's what finally lets wildly different harnesses sit at the same table. Anti-cheating: some test environments let the AI peek at "the answer from the future." The paper scrubbed all of these leaks. It scores cost, not just correctness: every harness must also report how much money it burned, how long it took, and its cache hit rate — because two setups with near-identical accuracy can have bills that differ by 100×. Adding a new harness? Just write a small adapter. Any harness that implements a handful of fixed interfaces plugs straight into the exam — no changes to the task set or grader. So it's not a one-off test of these five; it's a standard that can keep growing. It also ships an 80-task Lite version that costs only ~23% of the full run yet reproduces roughly the same rankings — handy for fast iteration. Paper & code: https://t.co/FOPh6hba6z


El juego: https://t.co/tANDRHxZpR Tremendo lo bien que funciona incluso en móvil. Y no sólo es bonito, el juego tiene su cosilla. https://t.co/CBqtWvV5KR


the boys gc right now https://t.co/BYvuVw49aY

Grok is now inside PowerPoint, Word, and Excel. Each gets an agent in the sidebar that builds the deck, sheet, or doc from a prompt, pulling real-time data from the web and X and generating images and diagrams. It connects to your own apps and MCP servers too. Live on SuperGrok, Heavy, Business, and Enterprise.
GLM5.2 brings back the critic. It was just a matter of time until we people would realize that group-based variance reduction is unfeasible after some horizon length. We need to be more fine-grained. I am sure OAI and Ant have been using value models for quite some time. https://t.co/Sr5hrAxczu

Not long ago, G7 meetings were dominated by politicians, central bankers and industrial leaders. Today, the CEOs of OpenAI, Anthropic and Google are sitting at the same table discussing infrastructure, sovereignty and national competitiveness. That's a powerful signal of where influence is moving in the 21st century.

24 hours left to nominate yourself or someone else as a PyTorch Foundation Ambassador🔥 The PyTorch Foundation Ambassador Program highlights and supports passionate community leaders who organize events, create technical content, mentor new users, and contribute to the open source ecosystem. As we continue to expand representation across local PyTorch communities, we especially welcome applications from contributors in Africa, Latin America, the Middle East, Oceania, Southeast Asia, and Eastern Europe. Learn more and apply before June 18, 2026 - link in comments.

Falcon 9’s first stage has landed on the A Shortfall of Gravitas droneship https://t.co/LqecUt0AwY
This entire scene was made using @Grok Grok Imagine 1.5 is on another level. 🔥 https://t.co/zzcTzx1KvC
https://t.co/ccSbMfxMu2
24 hours left to nominate yourself or someone else as a PyTorch Foundation Ambassador🔥 The PyTorch Foundation Ambassador Program highlights and supports passionate community leaders who organize events, create technical content, mentor new users, and contribute to the open source ecosystem. As we continue to expand representation across local PyTorch communities, we especially welcome applications from contributors in Africa, Latin America, the Middle East, Oceania, Southeast Asia, and Eastern Europe. Learn more and apply before June 18, 2026 - link in comments.

Falcon 9 launches from pad 40 in Florida https://t.co/DswQicc5TM


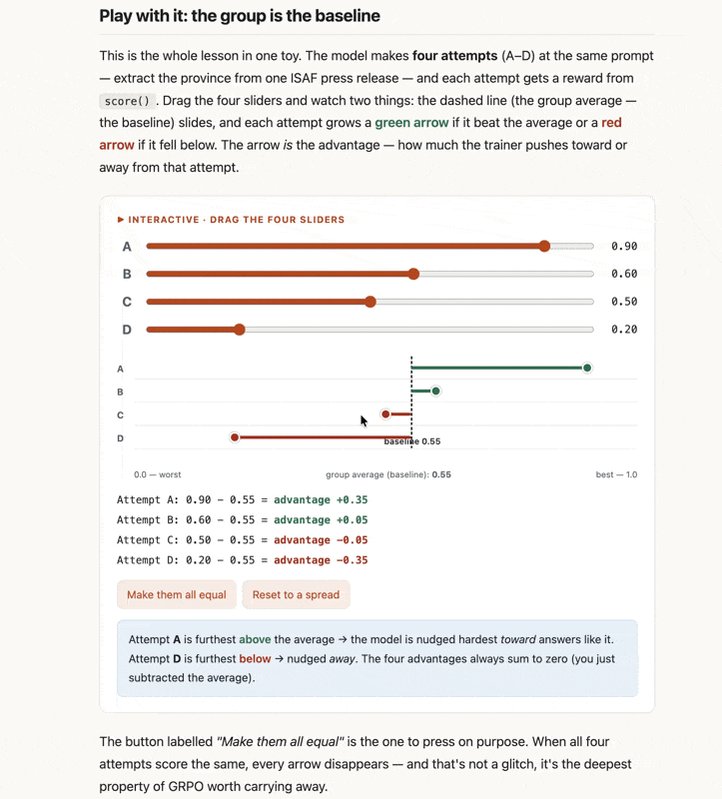
Doing a bit of a self-study RL course at the moment and one of the really useful tweaks I always have my 'teacher' do is to revisit the early @fastdotai lessons from @jeremyphoward and to really live up to those invitations to make things interactive, to get a sense for how things work intuitively. In the GIF I recorded below, you can see we have a whole bunch of playgrounds designed to help me understand how GRPO works. An important starting point for me is to get a rough mental model for how the algorithm works and these widgets help a LOT. ("show the whole game, then learn the rules as you need them")
All these videos were created using Grok Imagine 1.5 Big upgrade. Huge jump in quality. 🚀 https://t.co/jWroTLlqHv
Asmongold gives his BASED opinion, says: "You're not being oppressed by the top 2% of society. You're being oppressed by the bottom 2% of society instead 👀 "People ain't gunna like this one: the bottom 2% of society have caused all of the manifest problems in your lives” https://t.co/OQWk4jm92H
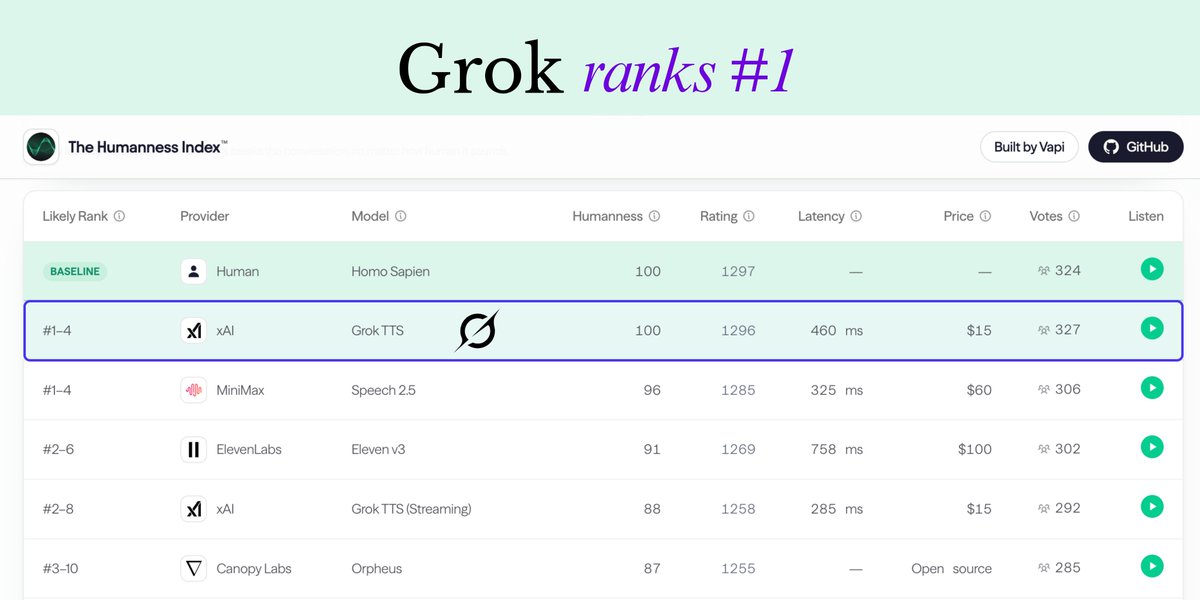
Grok Voice just ranked #1 on Vapi’s Humanness Index and it's scary good That is a huge deal This benchmark is simple: Listeners hear blind same-voice battles and pick which voice sounds more human Grok TTS scored 100 in humanness matching the human baseline That means Grok is reaching human-level voice quality on one of the most important benchmarks for real AI agents And Grok is doing this at $15 per 1M characters, while major competitors listed on the leaderboard are charging $60–$100 xAI is building world's best voice layers for real AI agents
NEWS: SpaceX will break its own news on X, not on newswires, an SEC filing shows The company named its X account @SpaceX as an official disclosure channel. Its investor page at https://t.co/cMAaS410q4 is the other. SpaceX says it will skip wire services like Business Wire and PR Newswire. It tells investors to follow @SpaceX for material updates.


When professional skeptics start changing their views, it's worth paying attention. Anthropic researcher Nicholas Carlini built his reputation questioning claims about AI and cybersecurity. Now he is warning that the capabilities of the latest models are advancing faster than many expected. Sometimes the most important signal is not a new technology. It is an expert changing their mind.
More than 200 of the world's elites registered for a retreat whose agenda runs from panels on cult-building and sex to prepping for World War III. An associated app offers matchmaking. https://t.co/ib53DjHHE6

@tobieapb @Clara_Gold Thanks! Life is funny. More on the cult: https://t.co/t7wjNT4HfB
Laughed at this article about rich Silicon Valley nerds going to panels on cult building and prepping for WWIII. My mom joined a Montana Survivalist Cult back in 1988. Scobles are always ahead. :-) The cult had something like 60,000 members, most of whom were college educat

Grok Imagine Video 1.5 is here Our new image-to-video model with sharper realism, better physics and faster generations 🧵 https://t.co/zGhs9czkC5 https://t.co/9X4YicpMH8

🚀 Announcing the X API Exhibit! A new dedicated space where developers can publish and showcase the apps they’ve built with the X API. We’ll review submissions and select high-quality developer apps to be included in the initial showcase. Apply here: https://t.co/YmqpxTh3BO https://t.co/ScKoCpJfWB

Of course I entered https://t.co/kiuZ7QXLzb (it is built wholly on the X API, gathers 30,000 posts a day via the API and then analyzes them for AI news).
🚀 Announcing the X API Exhibit! A new dedicated space where developers can publish and showcase the apps they’ve built with the X API. We’ll review submissions and select high-quality developer apps to be included in the initial showcase. Apply here: https://t.co/YmqpxTh3BO ht

@autonomous_labs @Kickstarter And if you are locked out, my AI reads the AI community on X for you: https://t.co/kiuZ7QXLzb

Just finished reading #Limitless by @jimkwik Biggest lesson: Your brain is not fixed, it's trainable. Learn faster, remember more, think better, and unlock your full potential through mindset, motivation, and methods. What's your favourite learning technique? #Learning #Read https://t.co/LVBVu1kewl
