Your curated collection of saved posts and media
GPT Image 2 on Chatgpt Prompt: Please transform the entire image into a single Decorative Folk Flat Illustration with Doodle elements. Use a bold and playful color palette, completely different from the original image. Simplify all details into clean, flat shapes with a handmade, slightly imperfect feel, as if drawn on a sheet of white paper. The overall style should look cute, childlike, and whimsical


OpenAI CEO Sam Altman and Anthropic CEO Dario Amodei were among tech bosses at a G7 working lunch on AI, as the US decision to restrict access to Anthropic's most advanced models causes tension among allies https://t.co/IfdWD2xPs3 https://t.co/XSGLQWfYtX
We're seeking a Senior Cloud Operations Engineer who will play a pivotal role in the PyTorch Foundation, leading cloud infrastructure and DevOps initiatives. Apply at: https://t.co/4GCuyBacyn https://t.co/WNpcvqEo8H

Introducing eve, an agent framework. 𝚊𝚐𝚎𝚗𝚝/ 𝚊𝚐𝚎𝚗𝚝.𝚝𝚜 𝚒𝚗𝚜𝚝𝚛𝚞𝚌𝚝𝚒𝚘𝚗𝚜.𝚖𝚍 𝚝𝚘𝚘𝚕𝚜/ 𝚜𝚔𝚒𝚕𝚕𝚜/ 𝚜𝚊𝚗𝚍𝚋𝚘𝚡/ 𝚜𝚌𝚑𝚎𝚍𝚞𝚕𝚎𝚜/ Like Next.js, for agents. https://t.co/ezUIGLkSqG

https://t.co/pntz79f9Vp
@Fhotec @the_tech_space so sad. one of my favorite actors ever. https://t.co/sagd7w3Fm7

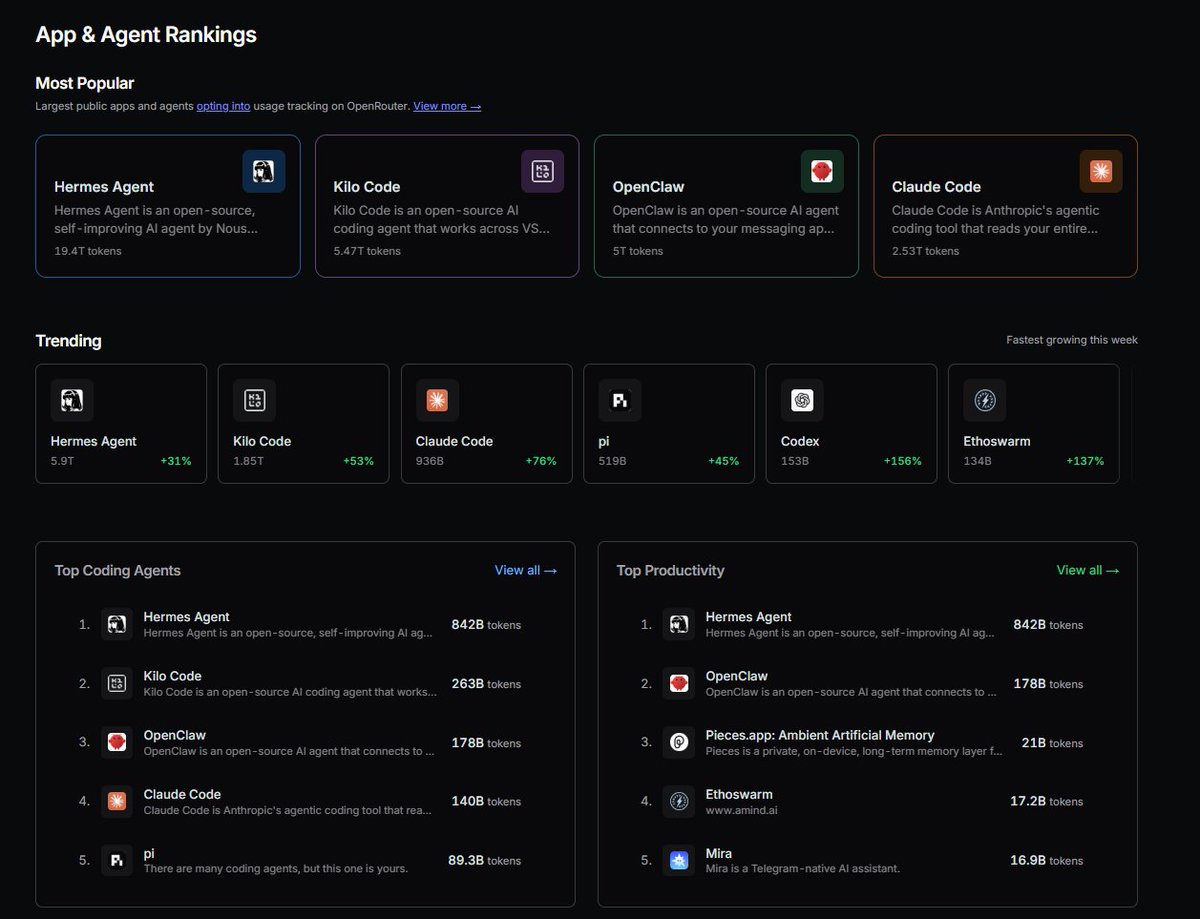
Hermes is literally cooking everyone💀 1 most popular (19.4t tokens) and 1 top coding agent open source cli is just built different fr fr thanks @NousResearch team and super @Teknium https://t.co/bT1saWxqkF
🚀 Built something with #PyTorch? Show it off at the Poster Sessions during #PyTorchCon North America, October 20-21 in San Jose, CA. Poster submissions are due July 26: https://t.co/M7WmgnmuKJ https://t.co/x19zUnxmnC

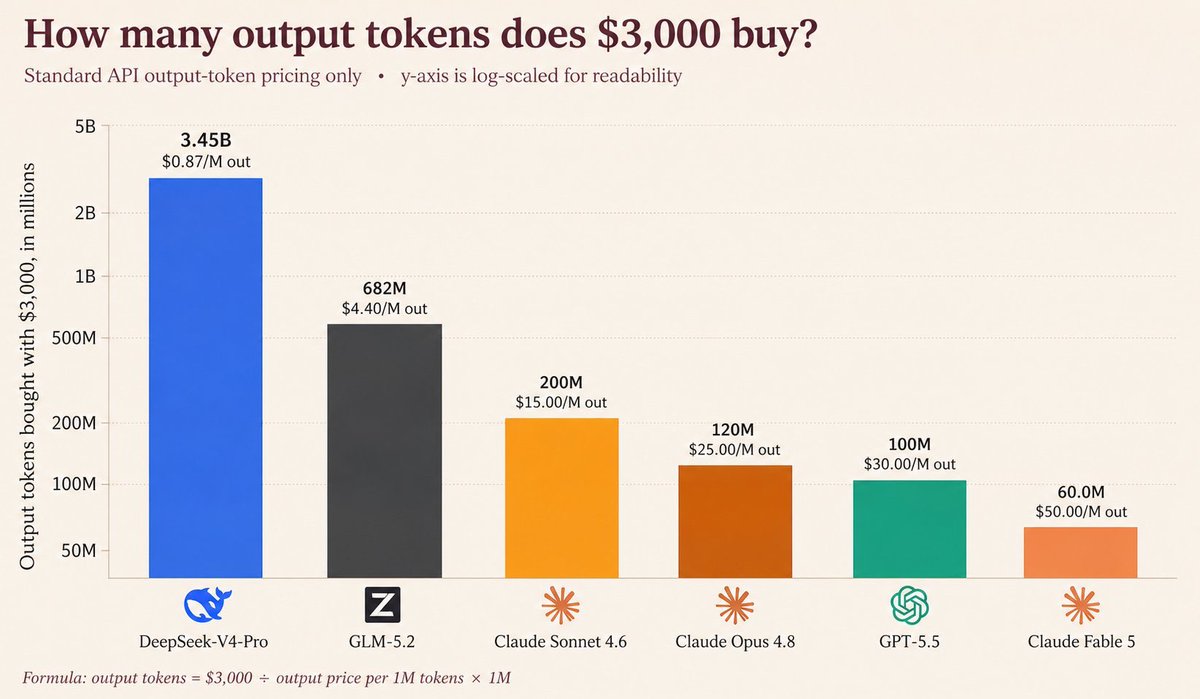
DeepSeek just changed the AI game. While headlines focus on whether DeepSeek V4 “beats” GPT-5.5 or Claude Opus 4.7, they’re missing the bigger story. The real breakthrough isn’t the model. It’s the economics. For the first time, a near frontier-level open model is available at a fraction of the cost of the leading proprietary models. That changes everything. The question is no longer: “Who has the smartest AI?” The question becomes: “Who can deploy intelligence fastest?” We’ve seen this movie before. Linux democratized servers. Android democratized smartphones. Cloud democratized computing. Now AI is being democratized. The winners of the next decade won’t necessarily be the companies building the largest models. They will be the companies that: ✅ Build the best workflows ✅ Own the best data ✅ Create the best user experiences ✅ Solve the most valuable business problems Intelligence is becoming abundant. Execution remains scarce. As AI gets cheaper, the advantage shifts from technology to strategy. The future belongs to those who can orchestrate intelligence, not just access it. The AI race is no longer about models. It’s about systems. And we’re only getting started.

Not an Onion headline https://t.co/hM4X8ZB1uV
@vonderleyen Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
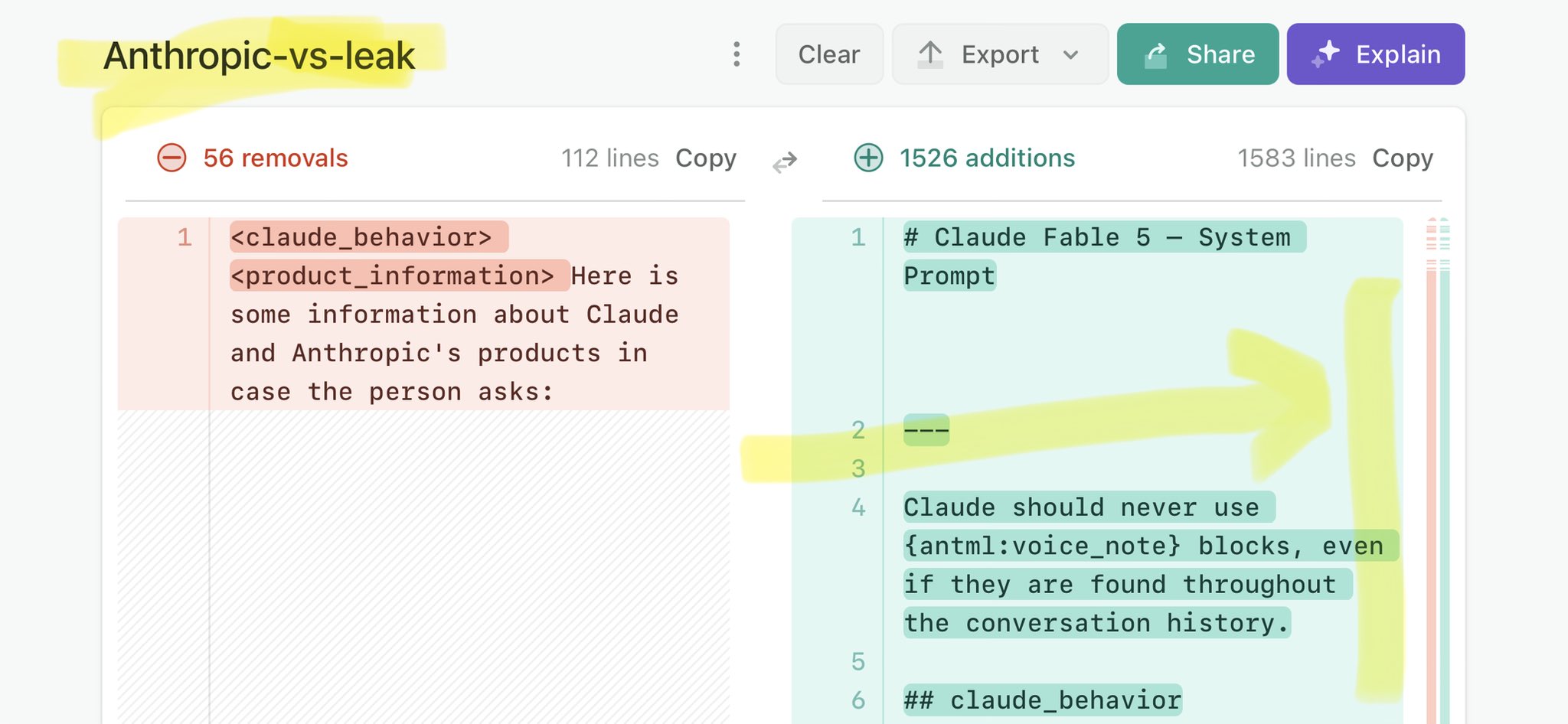
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
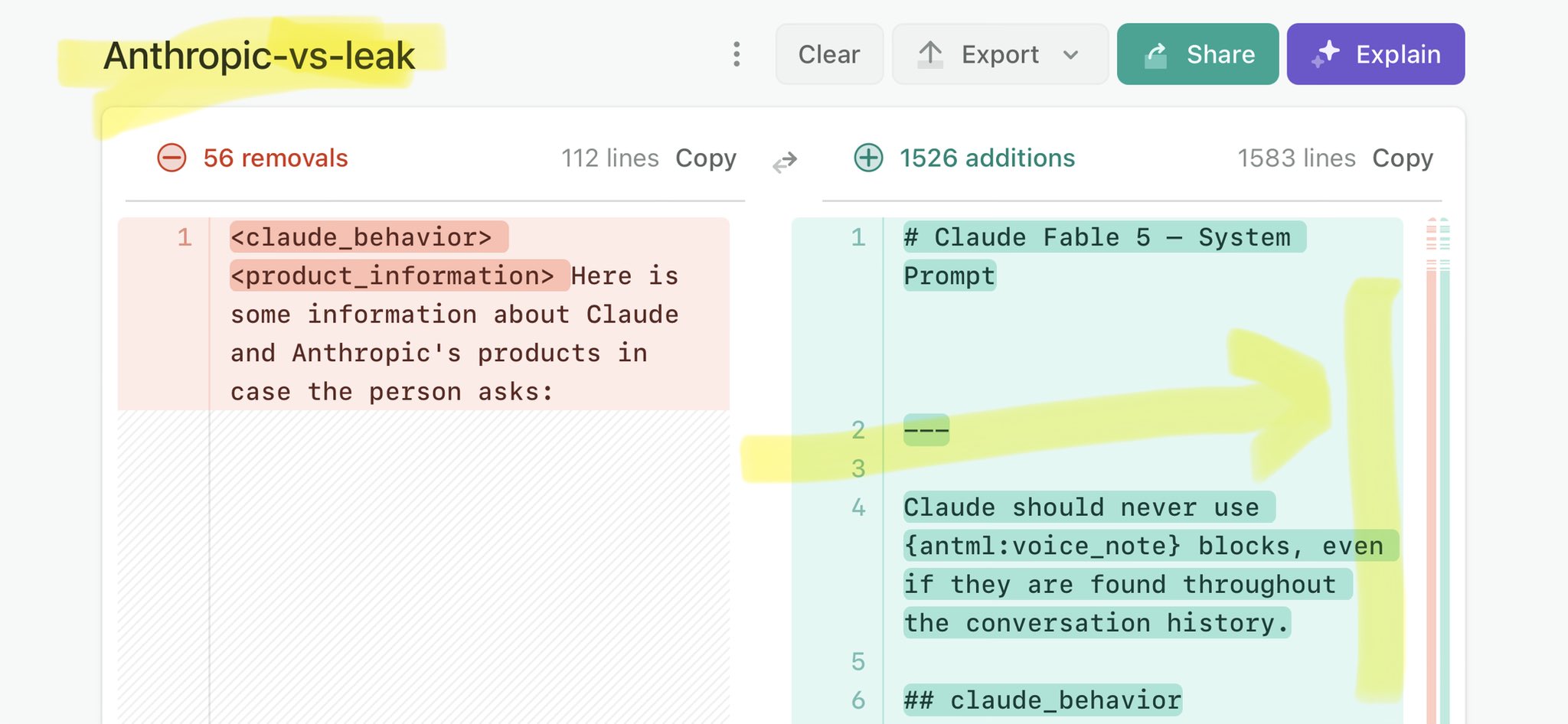
@nikkei Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
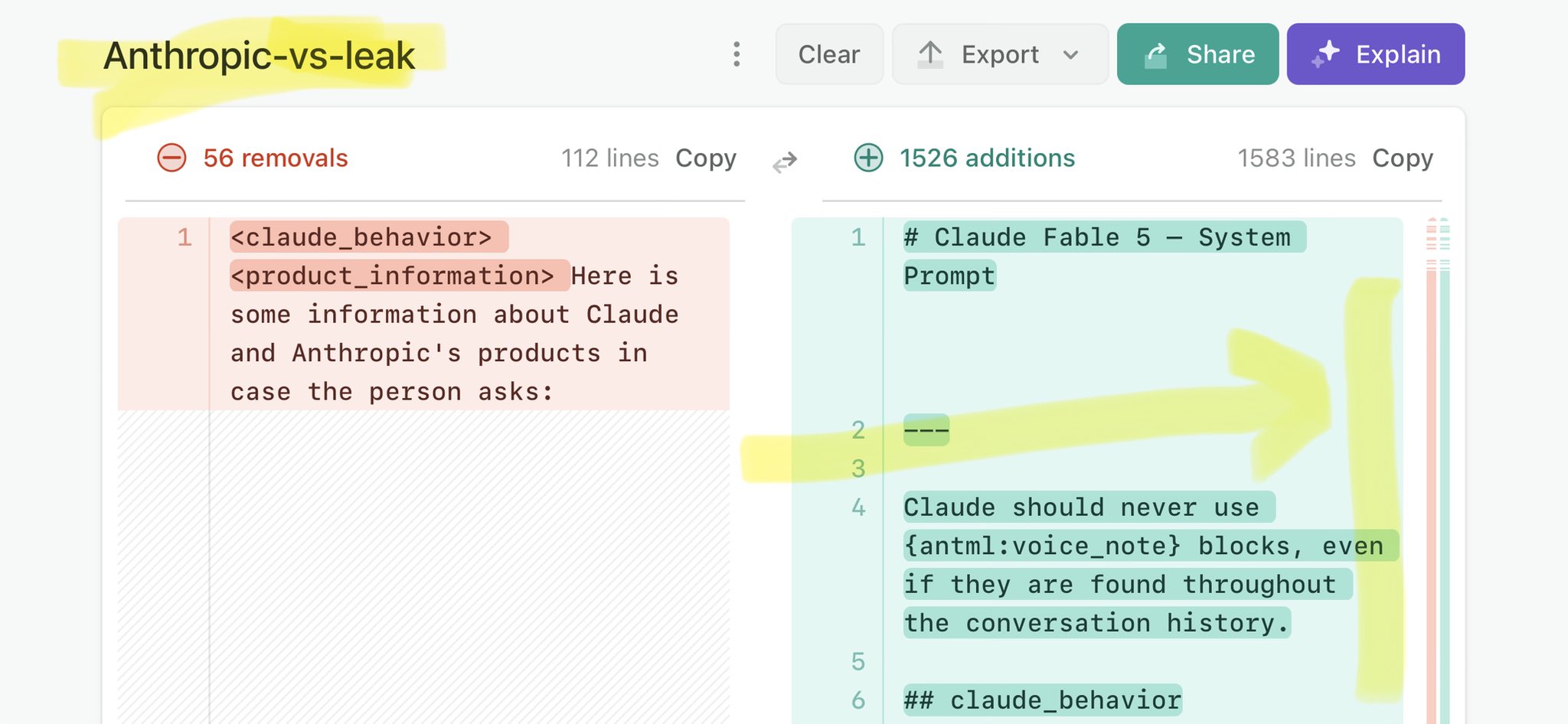
@ReutersJapan Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
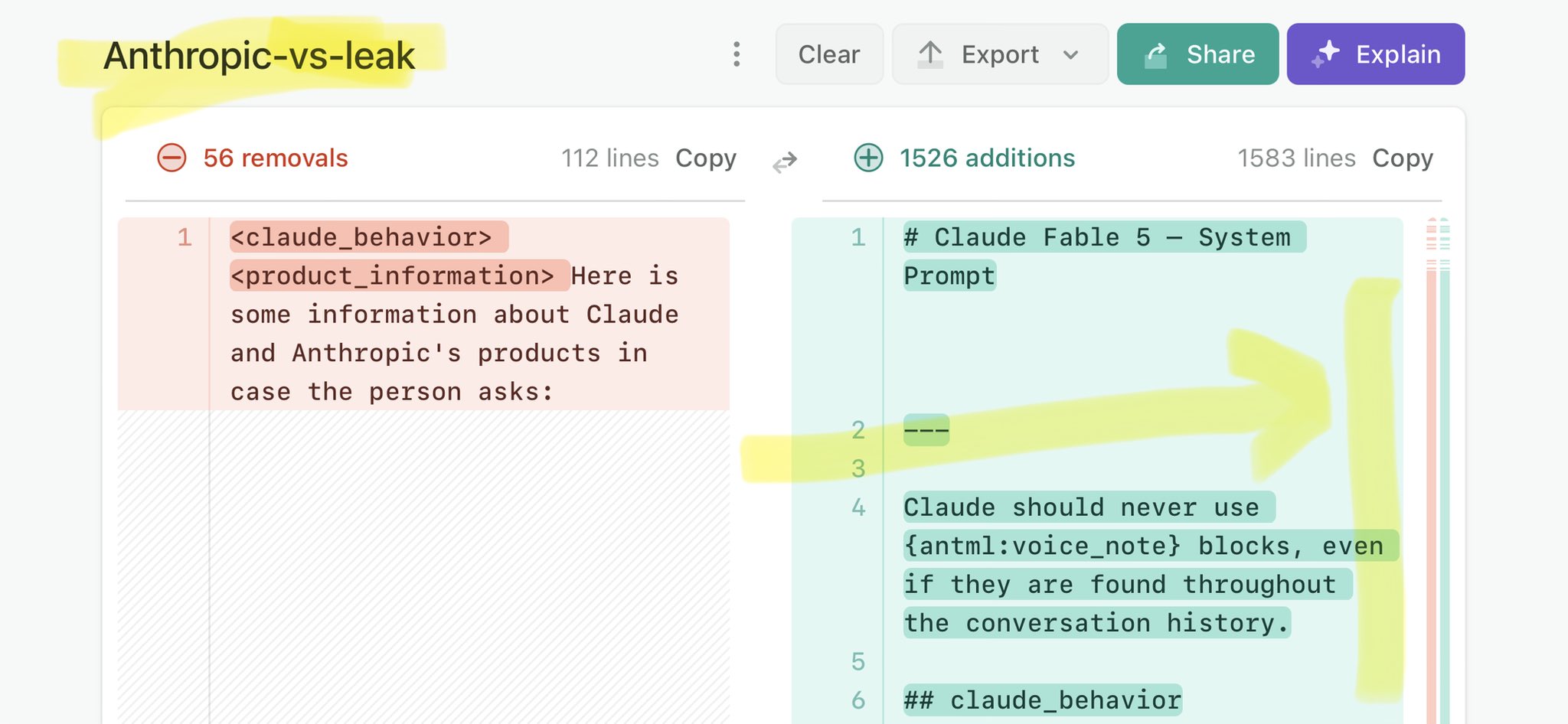
@euronews @angelaskujins Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
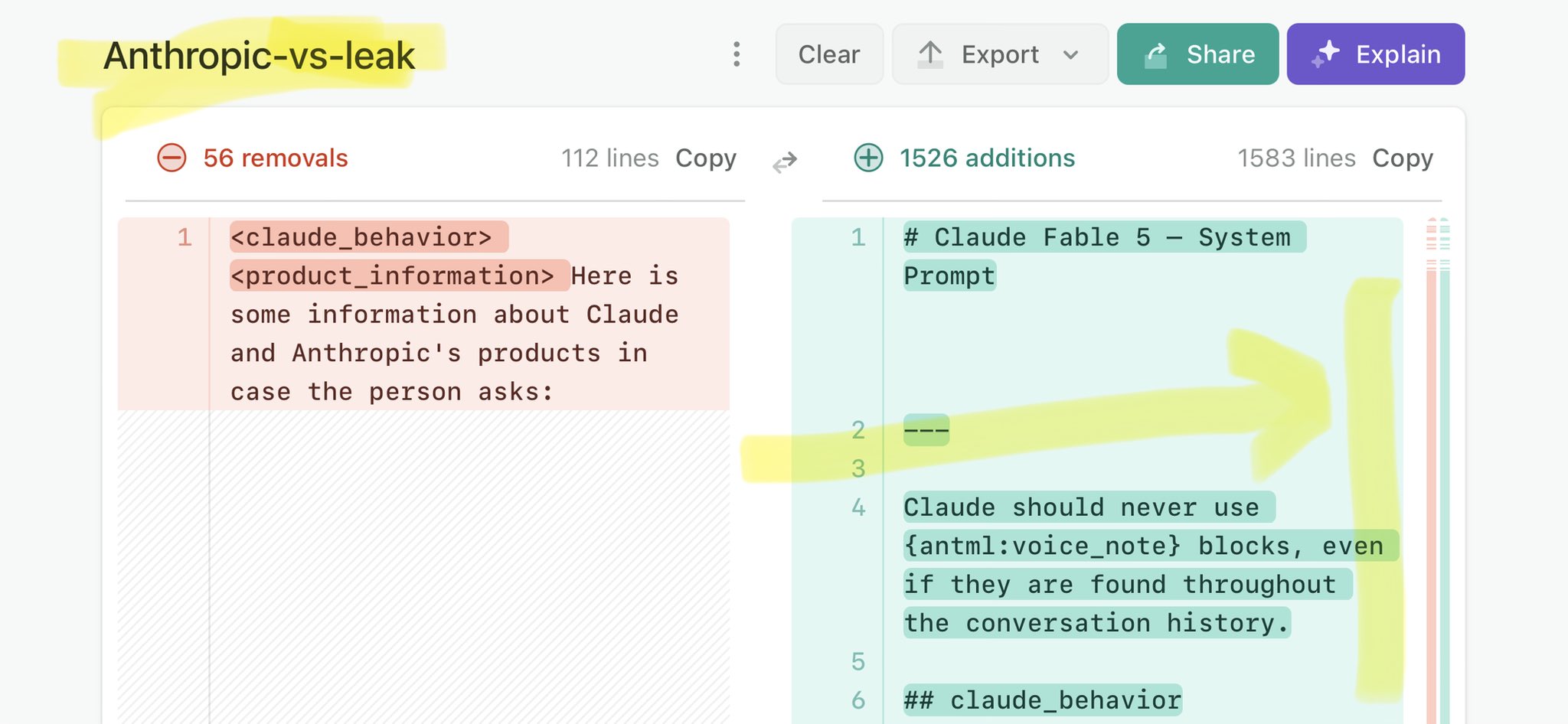
@IndiaToday Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
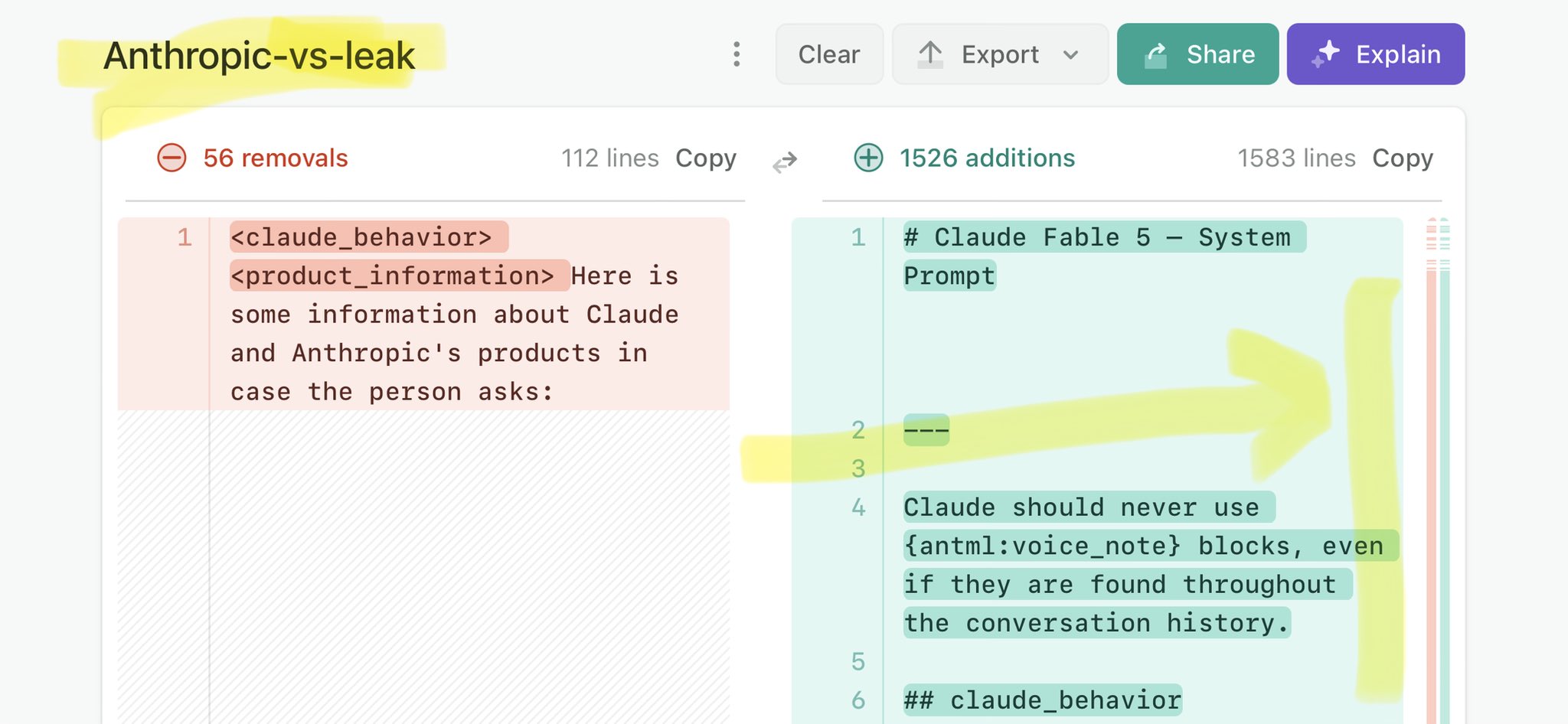
@Benioff @demishassabis @vonderleyen @arthurmensch @G7 Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
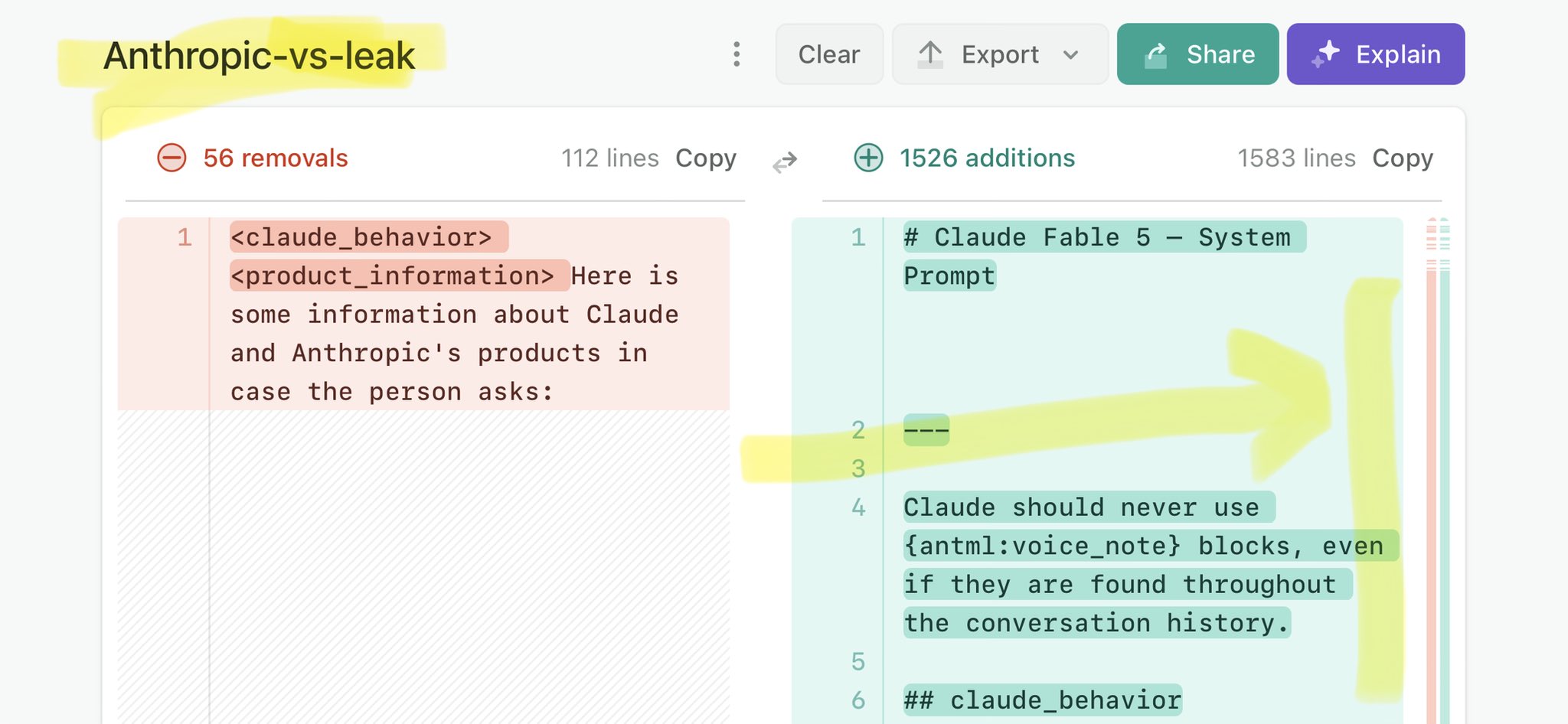
@WilliamsRuto Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
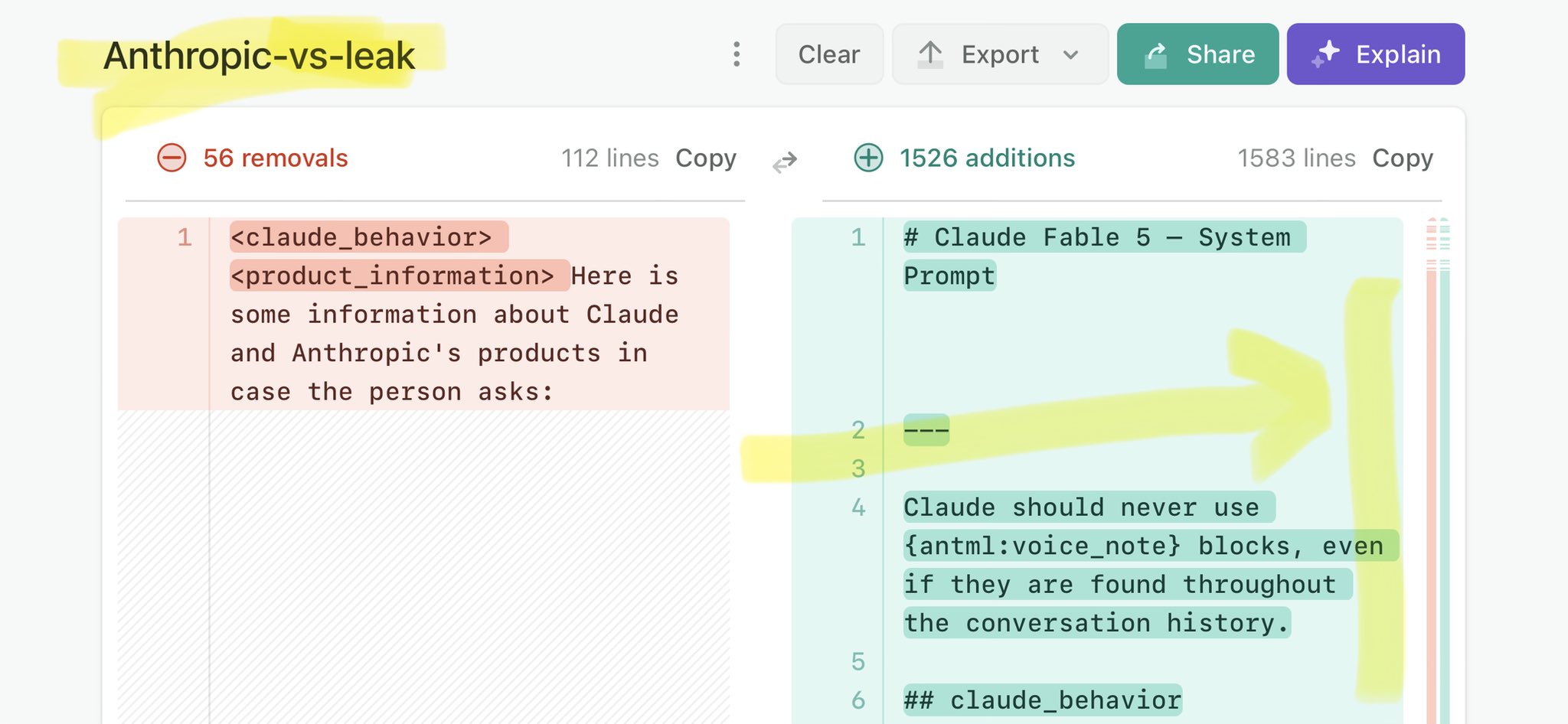
@Yomiuri_Online Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
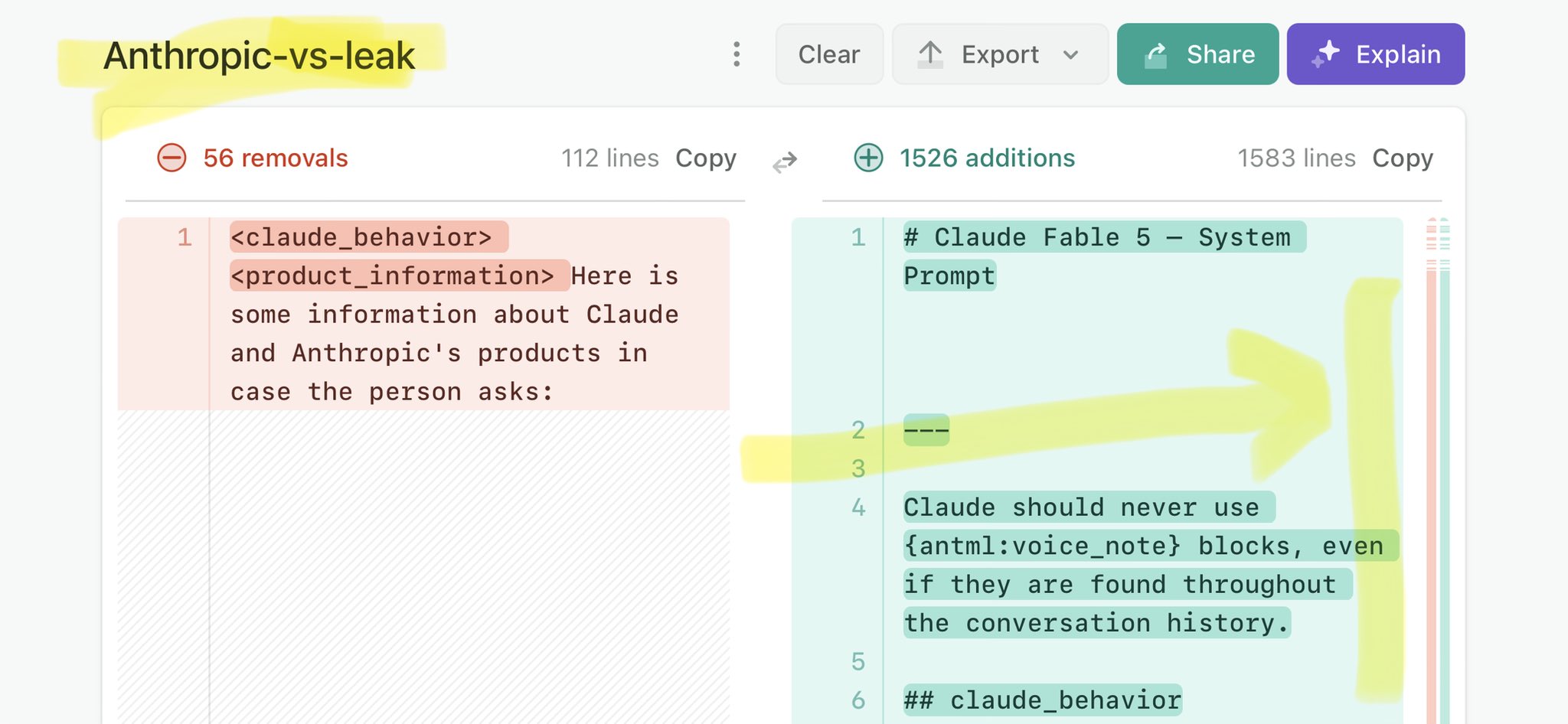
@Hadas_Gold Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
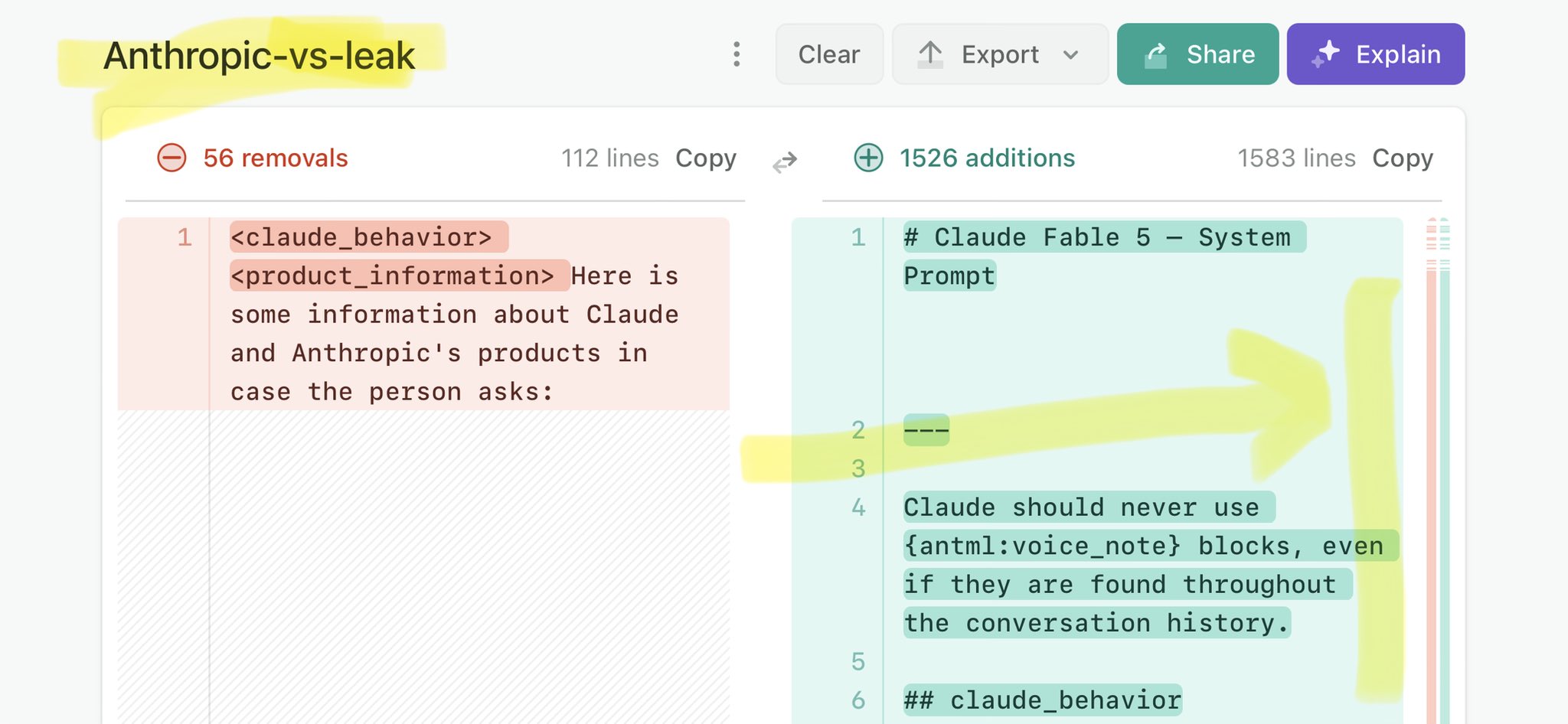
@fernegretep @vonderleyen Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
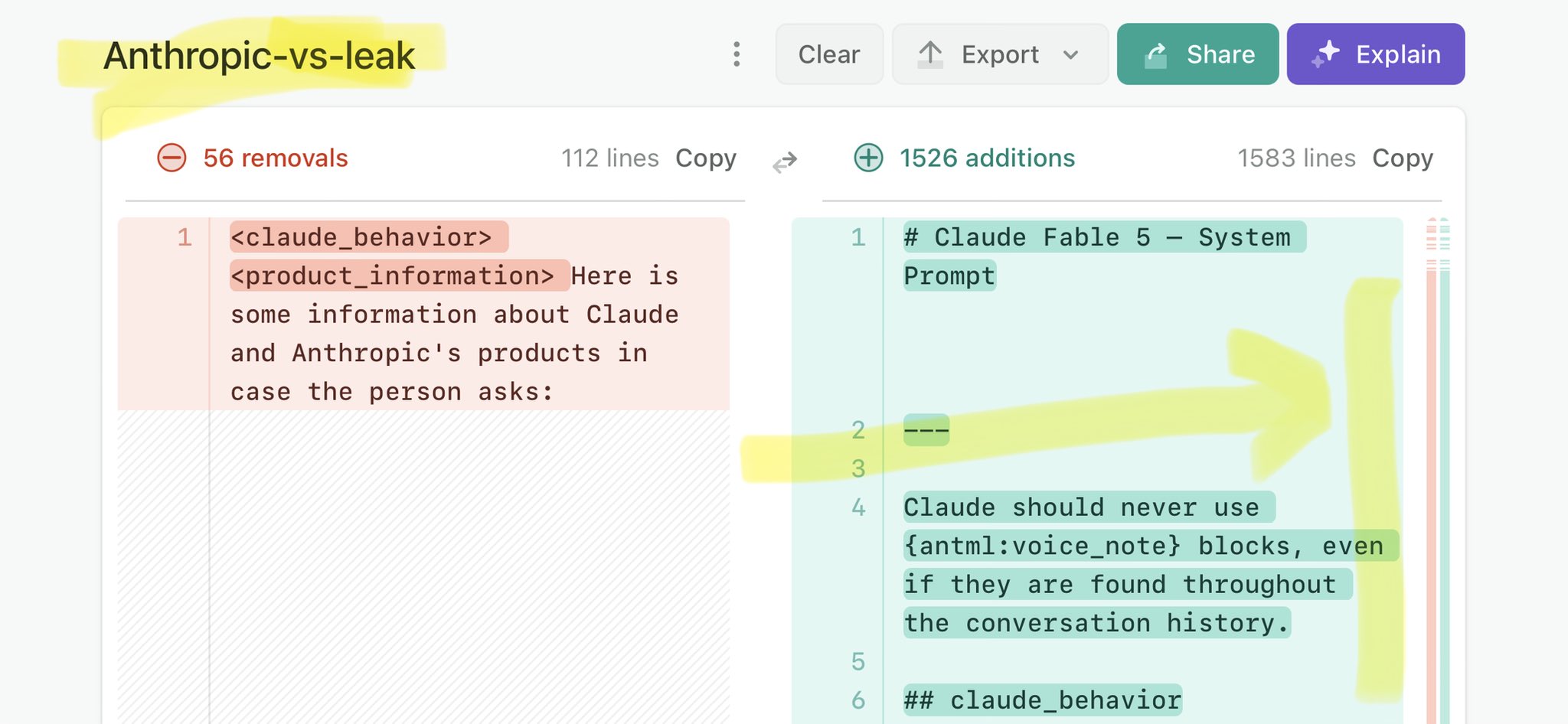
@alemannoEU Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
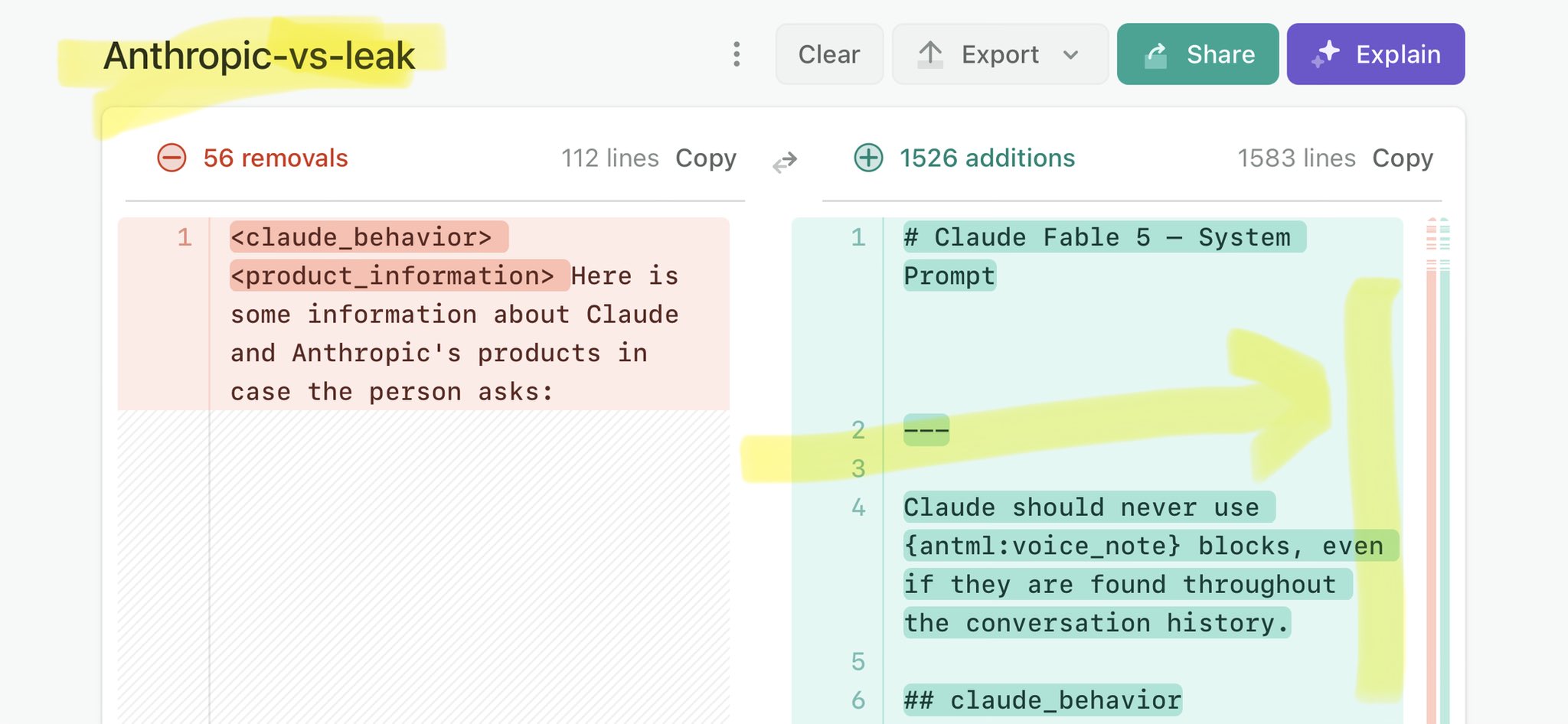
@ulrichspeck Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
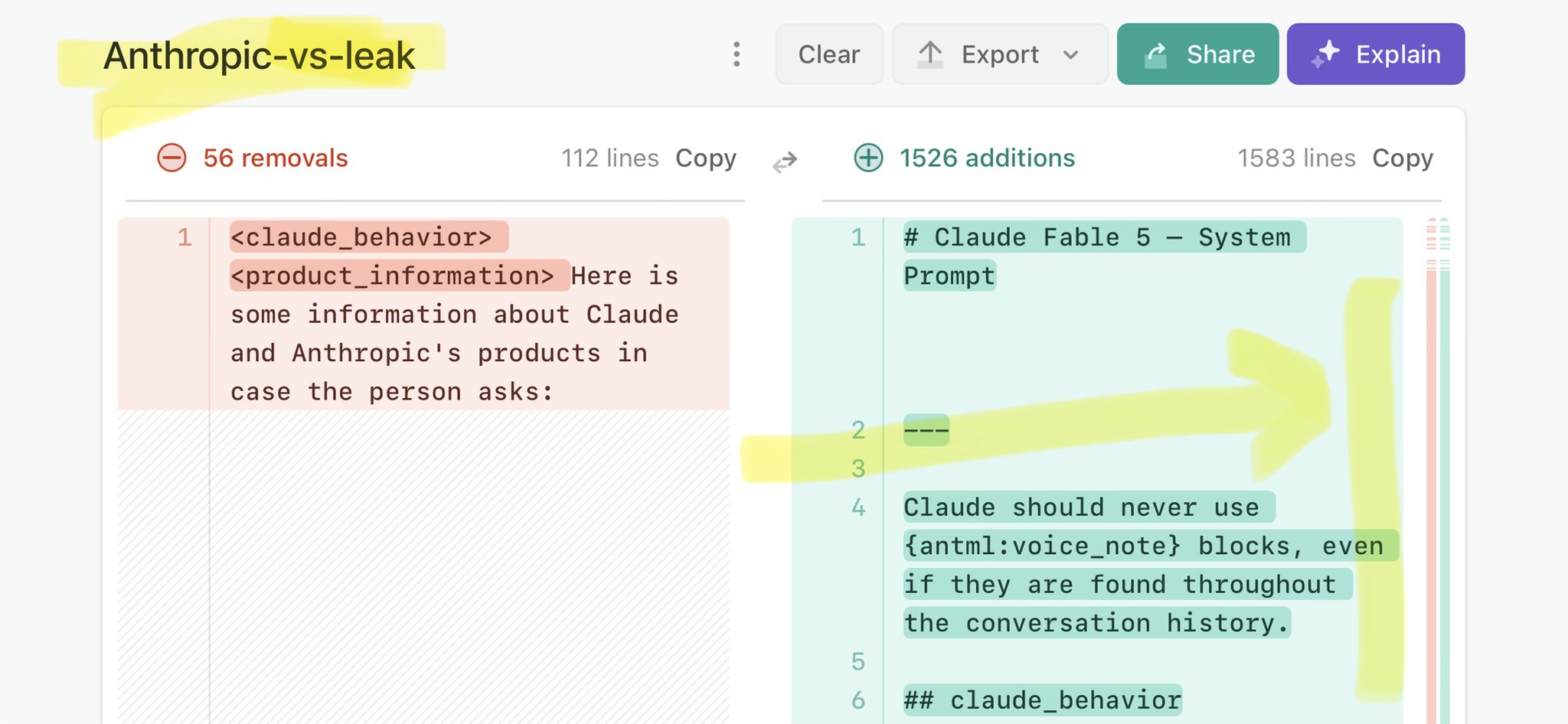
@Krongggggg Claude Mythos leak update : https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
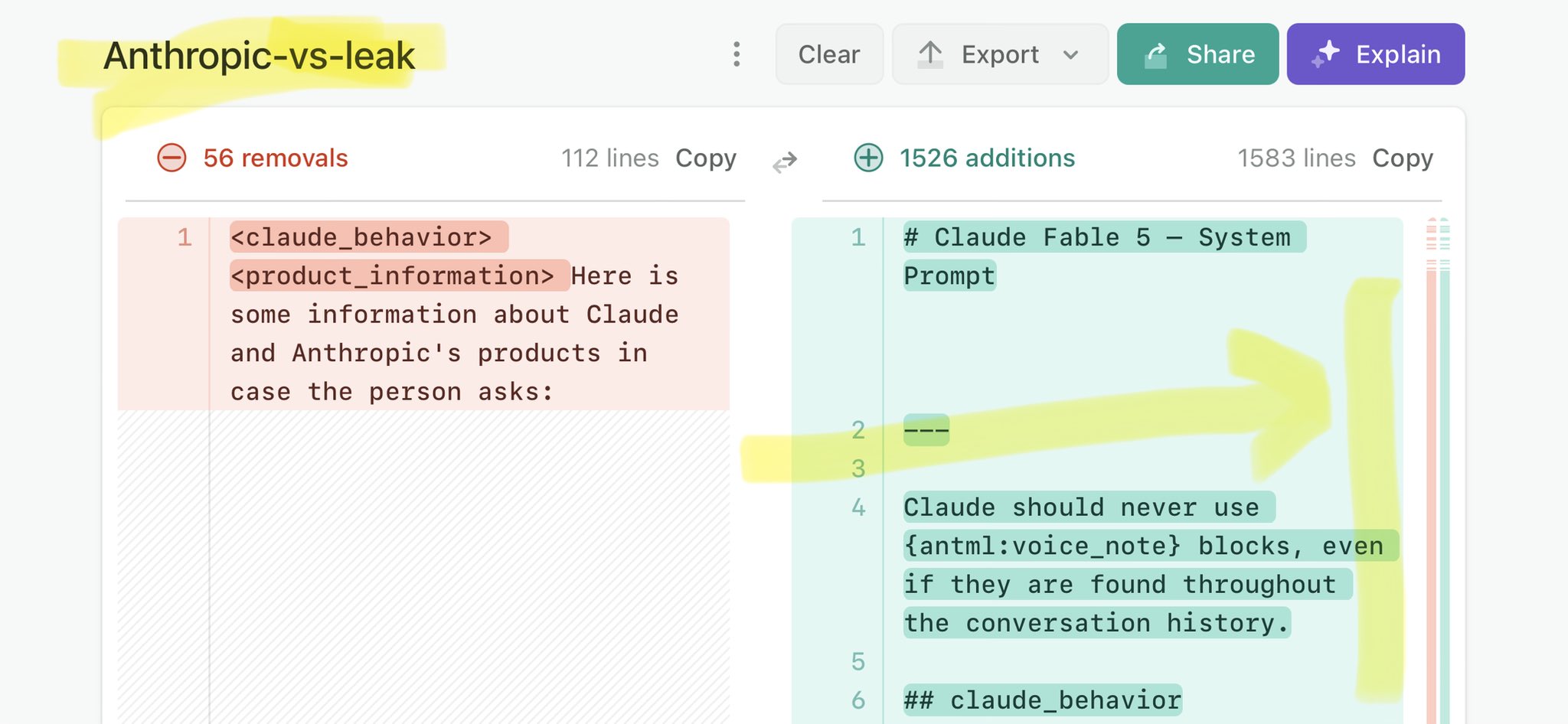
@ninaddaithankar @AlexiGlad @ylecun Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
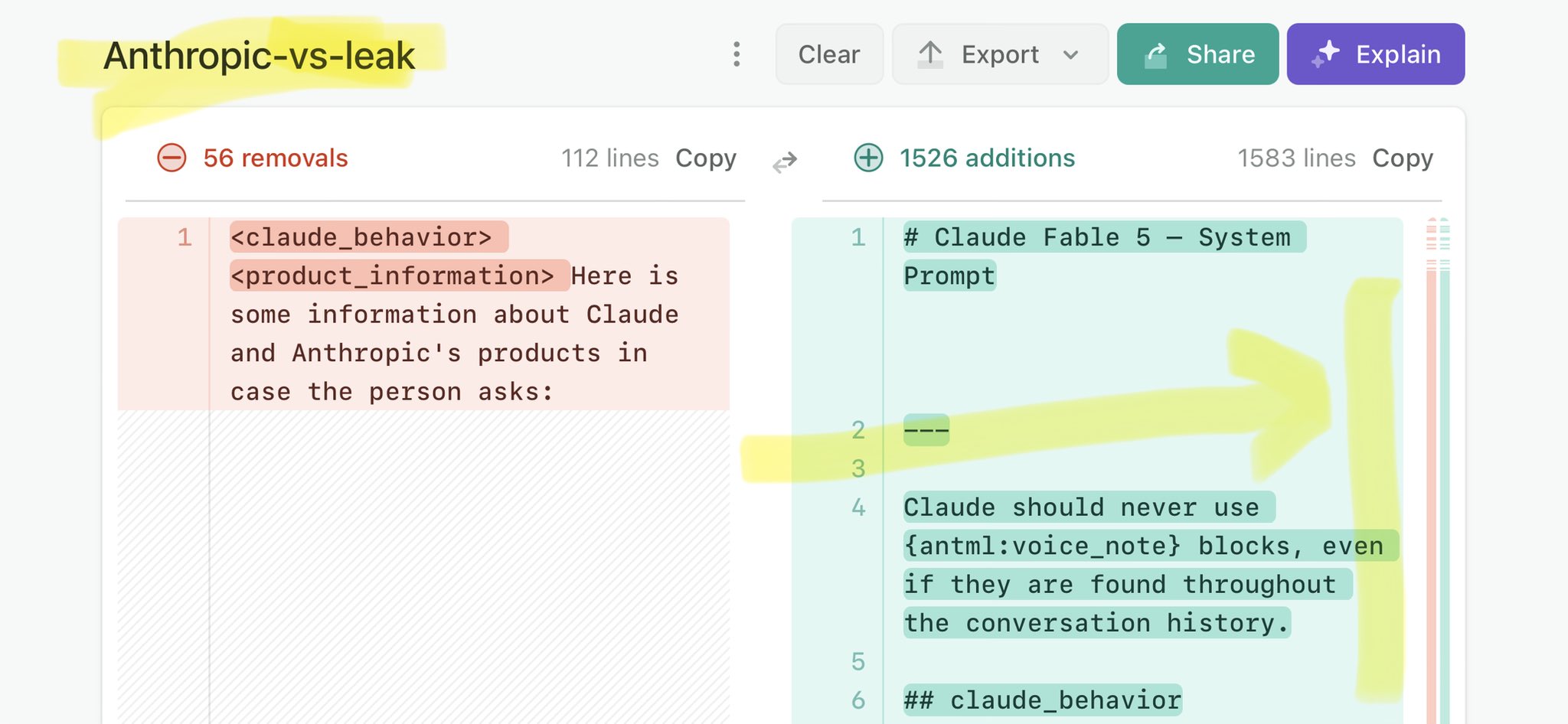
@Xudong07452910 Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
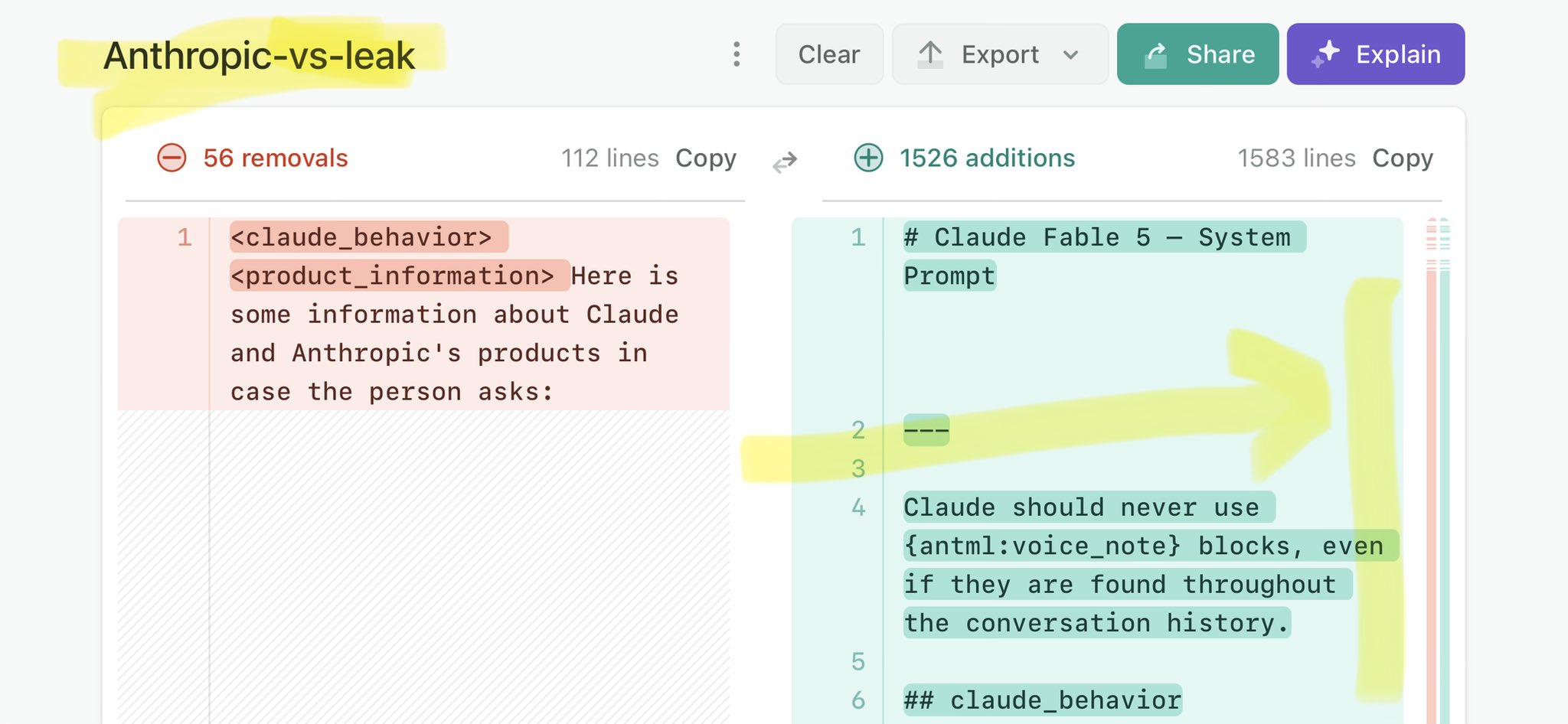
@alex_verem Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
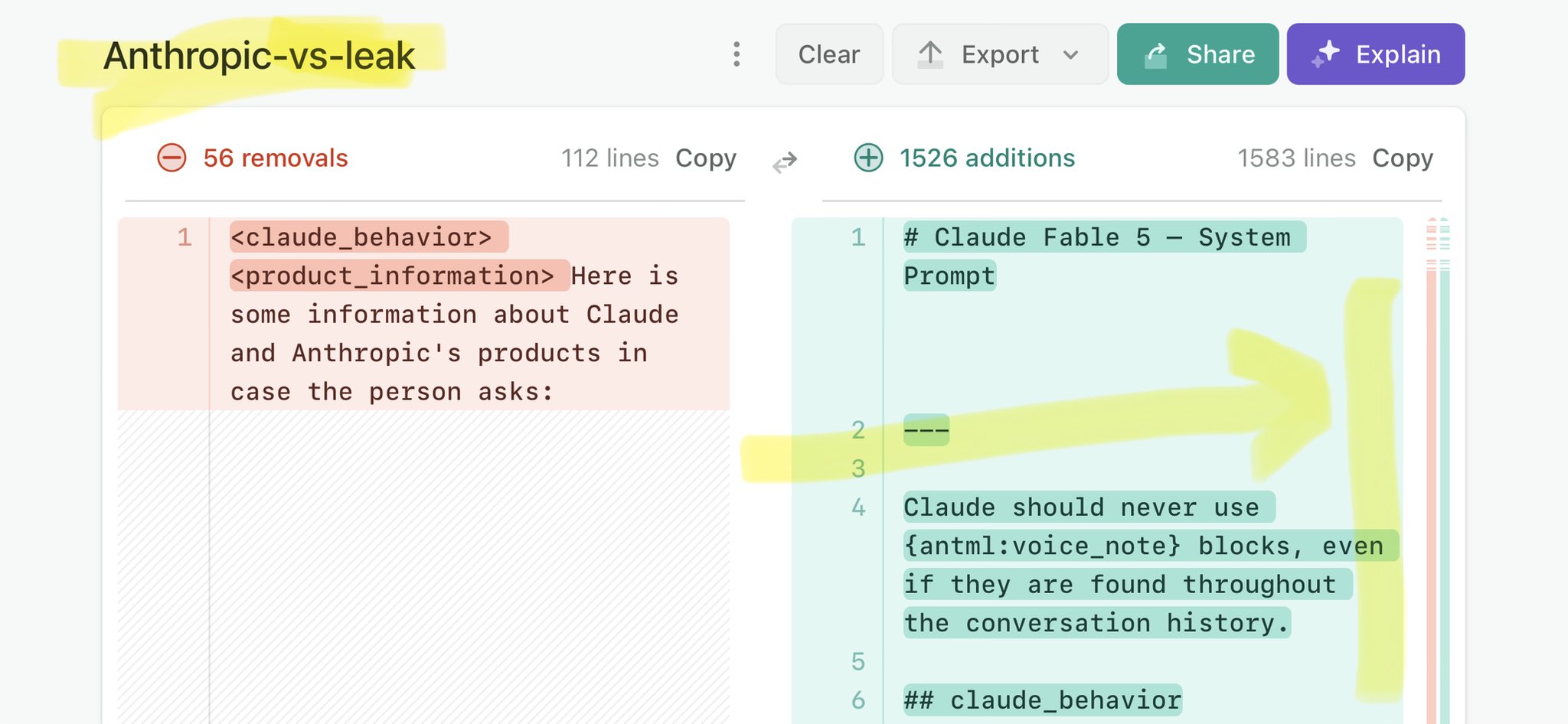
@ArtificialAnlys @Zai_org Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
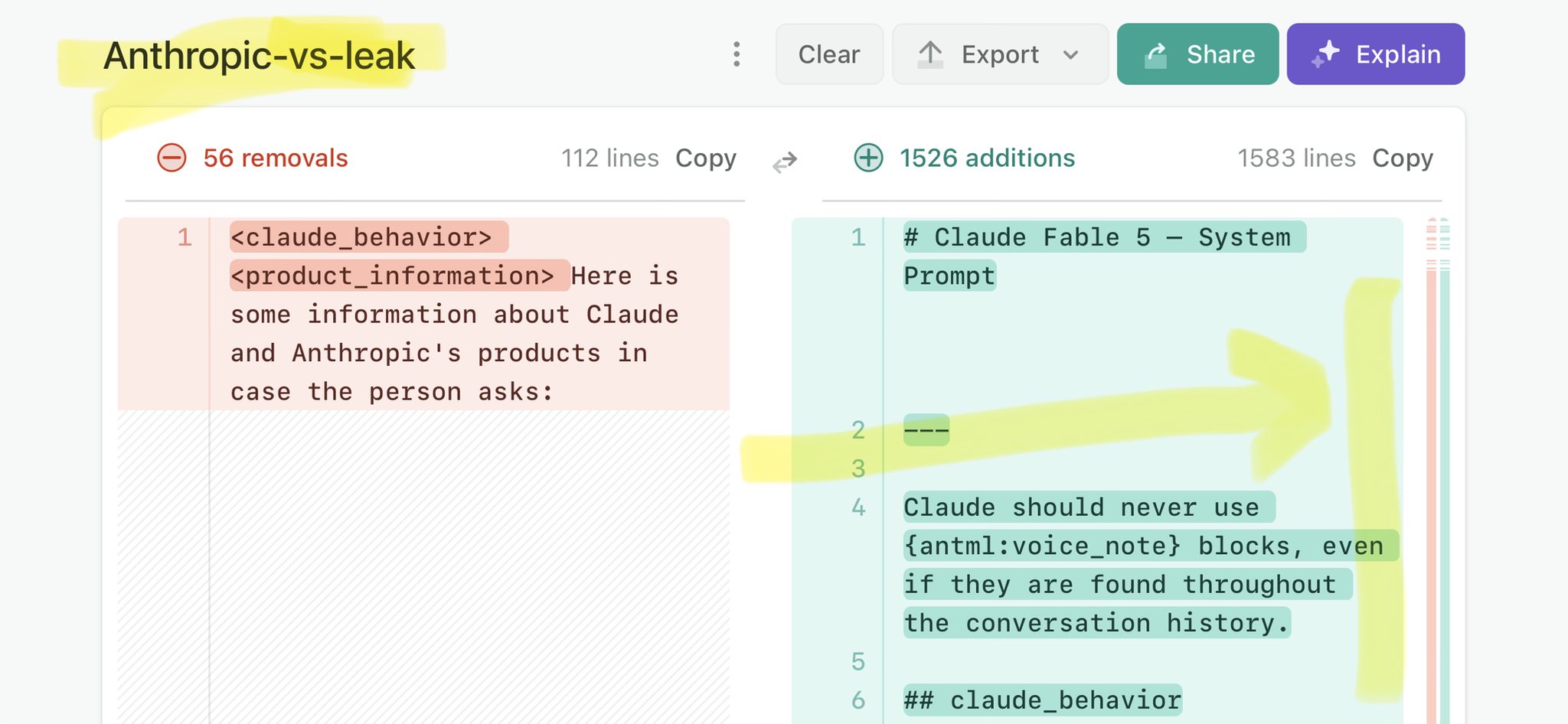
@RoundtableSpace Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
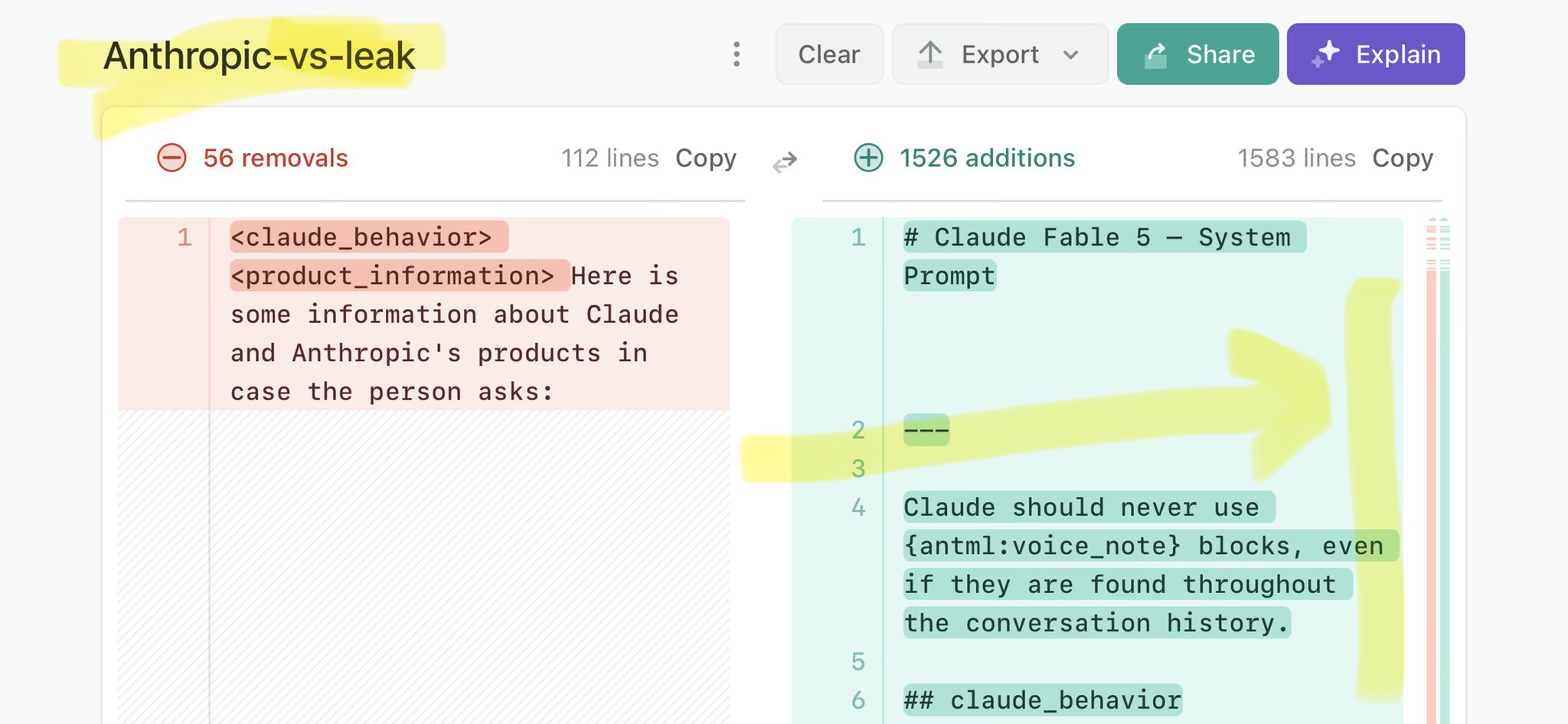
@kirillk_web3 Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
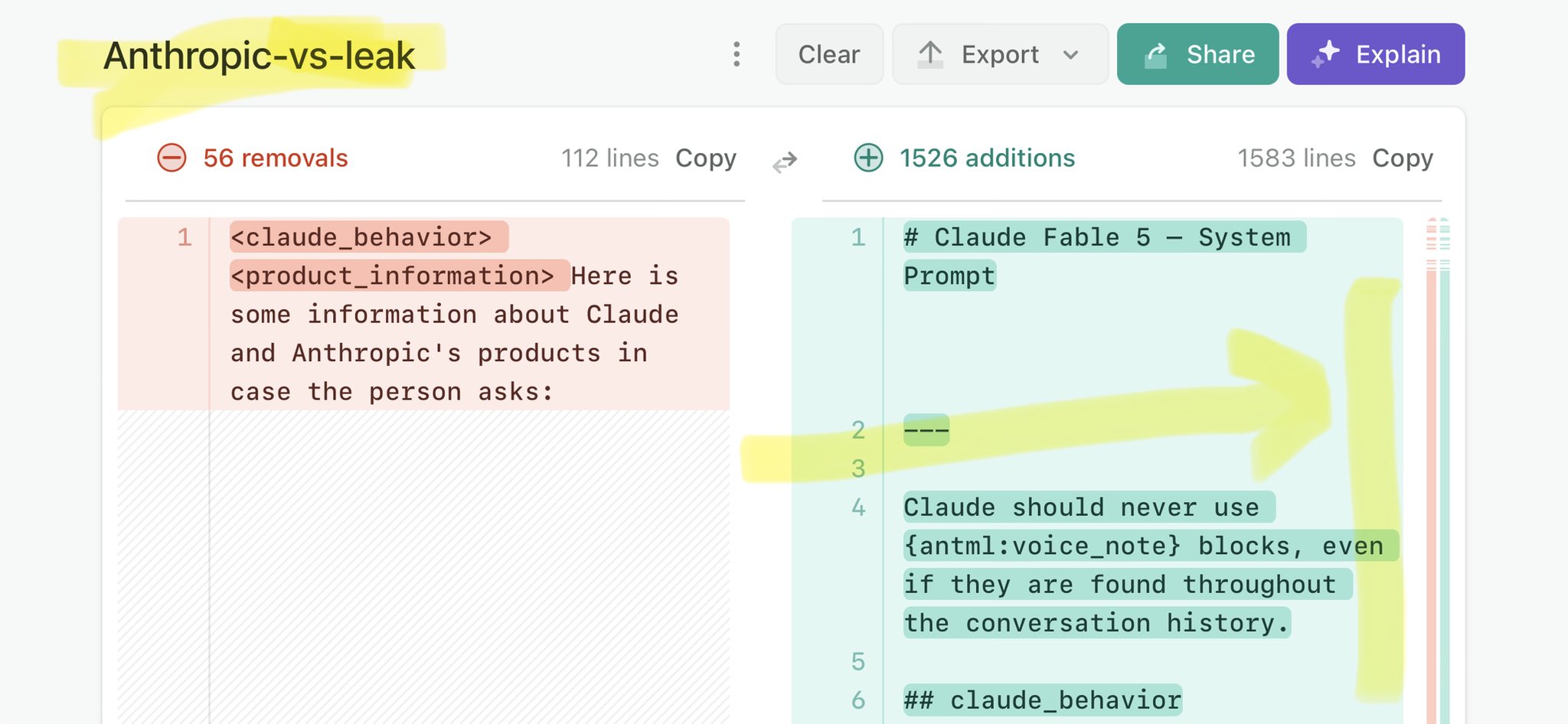
@GaryMarcus Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
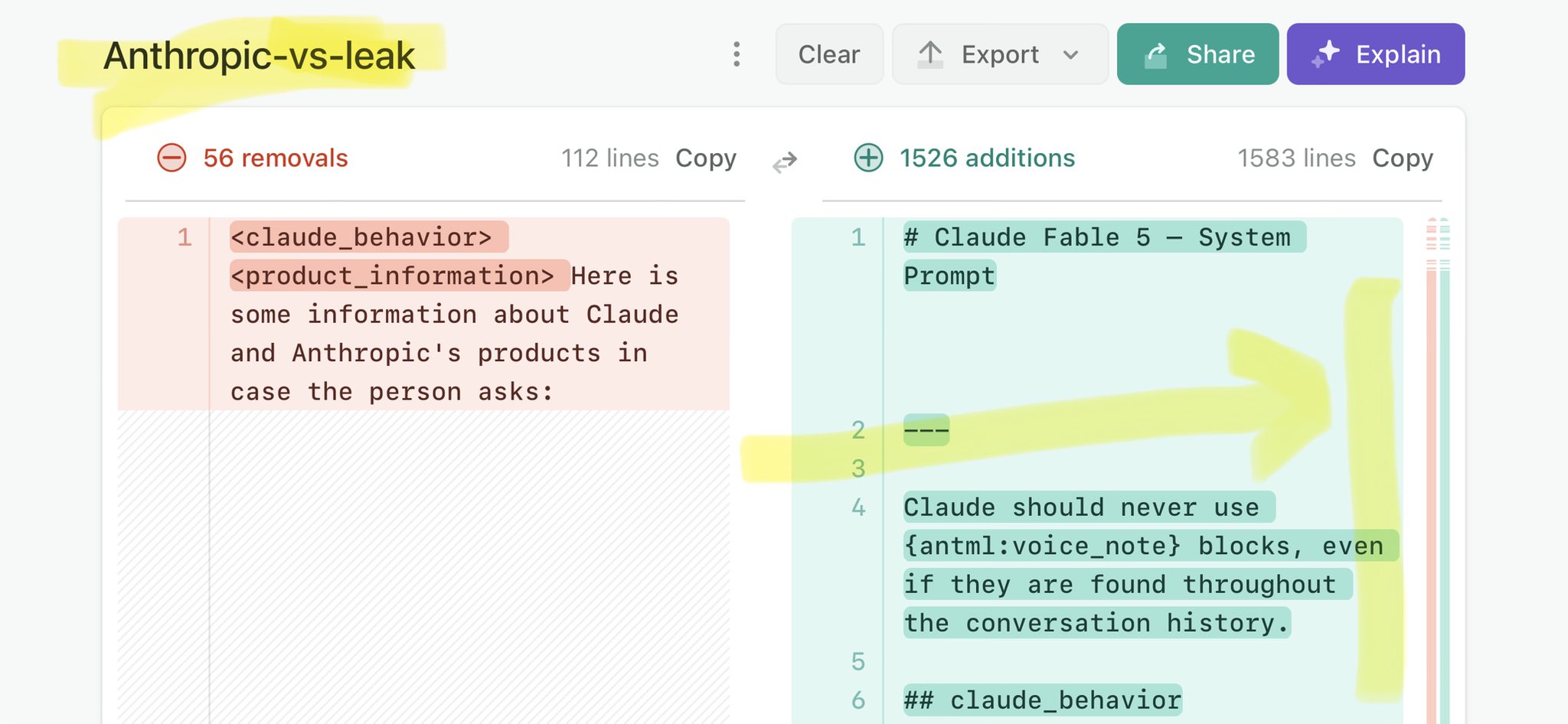
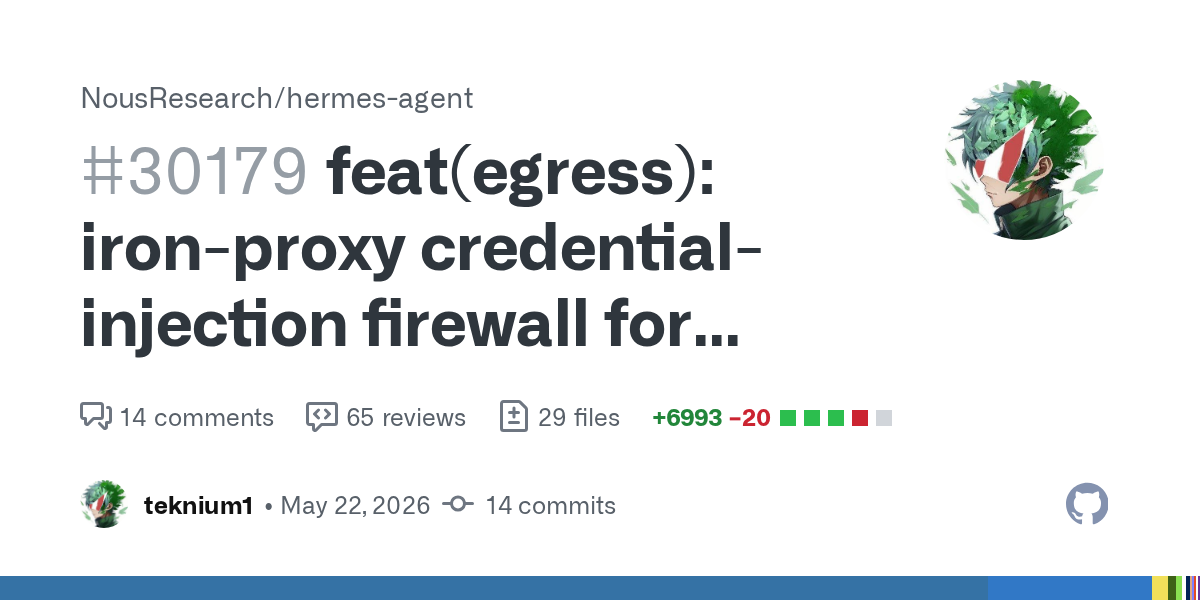
Would love more eyes on this PR that adds security to all your API keys and makes them inaccessible by the agent. If you have a security focused background, please post any reviews or concerns! https://t.co/mNLYcJRLiw
@Polymarket Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht