Your curated collection of saved posts and media
@GabrielAttal Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
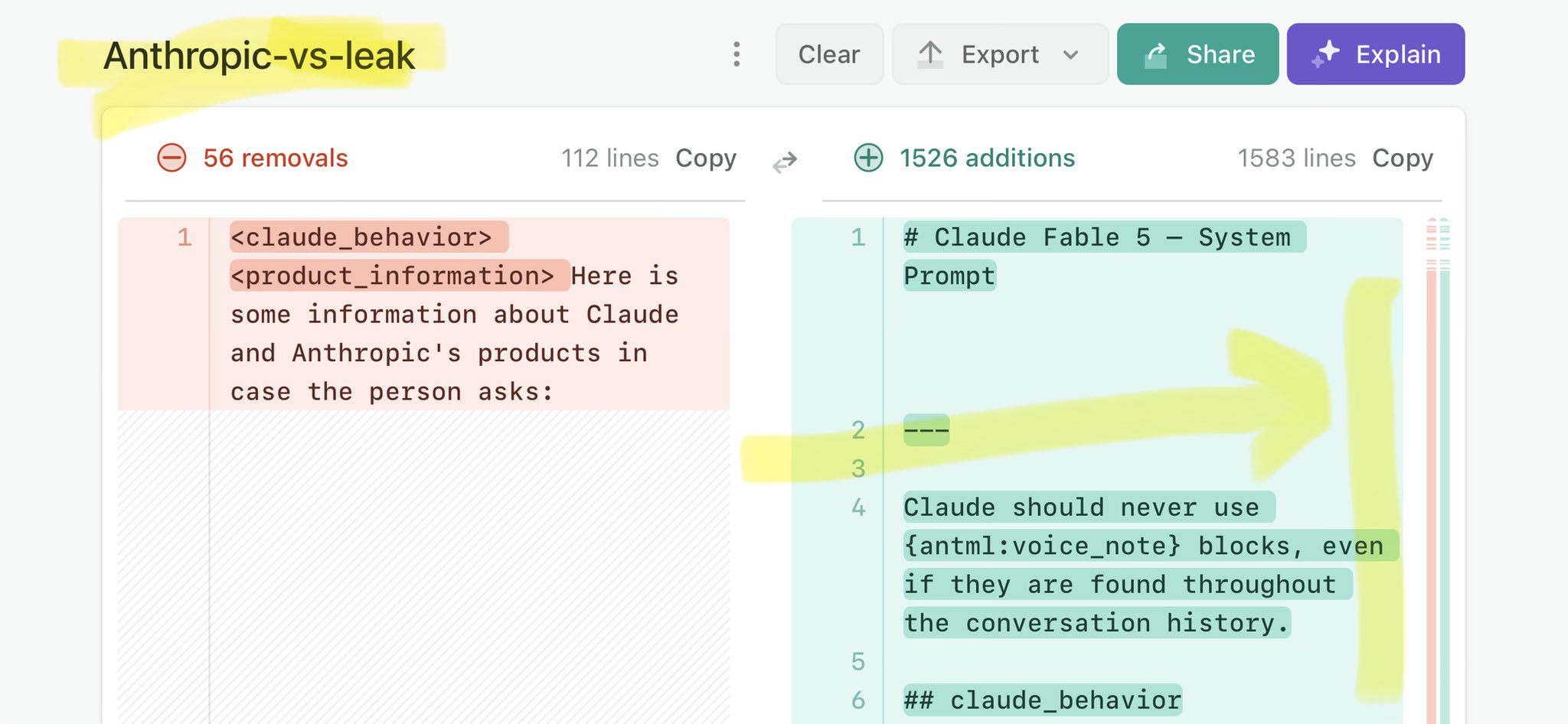
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@PopCrave https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@RealEmirHan https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@ItsKingSlime https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@ShinaaaRole_110 https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@Variety https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@PopBase https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@neerajjj6785 https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@rahulgs @ljupc0 https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@0xMovez https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@eng_khairallah1 https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@RoundtableSpace https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@Jack_W_Lindsey @CatAstro_Piyush https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

Token inflation is skyrocketing https://t.co/w9uRy1G7fZ

@FT Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
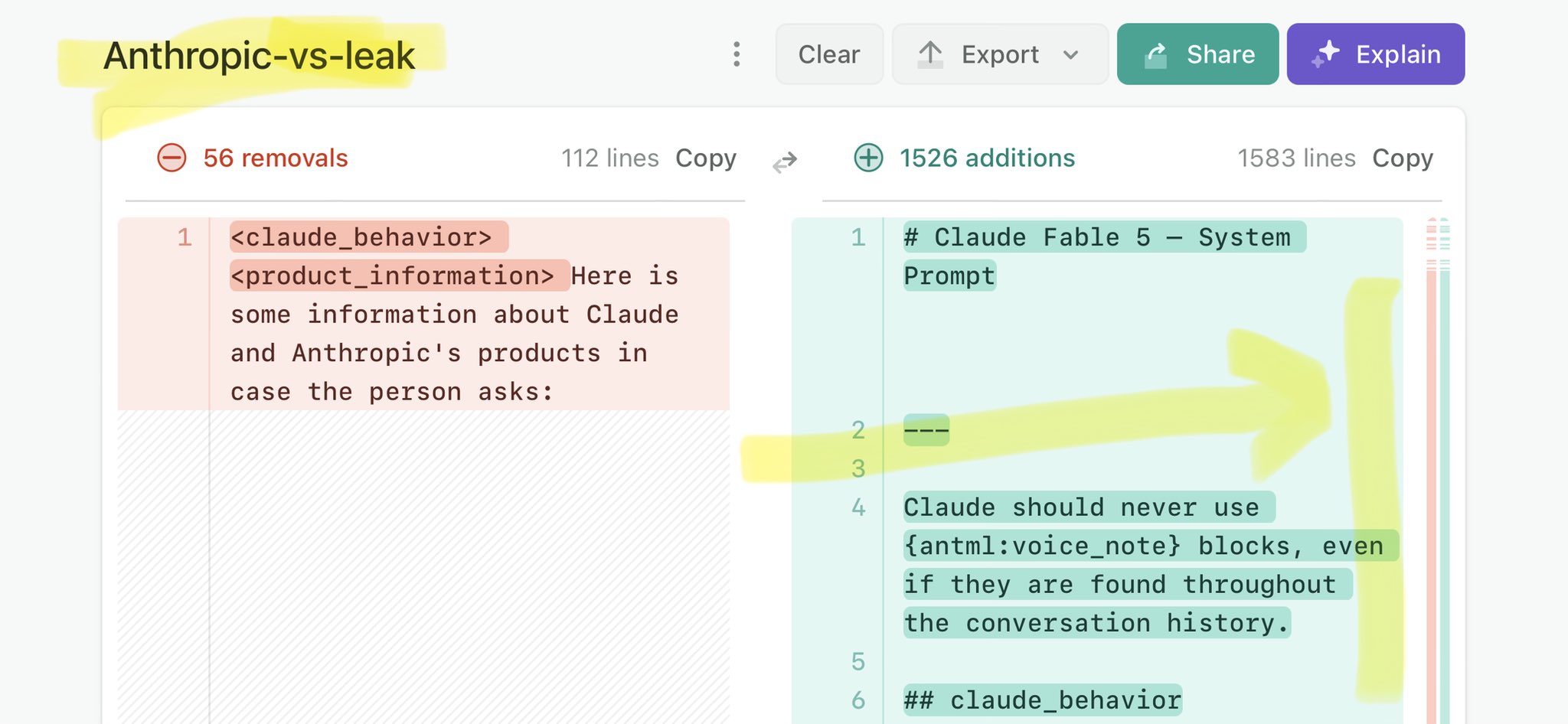
We are pleased to highlight an excellent community model from developer : Qwen3.6-27B-MTP-pi-reasoning-GGUF. Built on our Qwen3.6-27B base model, this release focuses on optimizing automated programming and debugging workflows for local coding agents. If you are exploring local AI coding assistants, we encourage you to test this model in your environment.
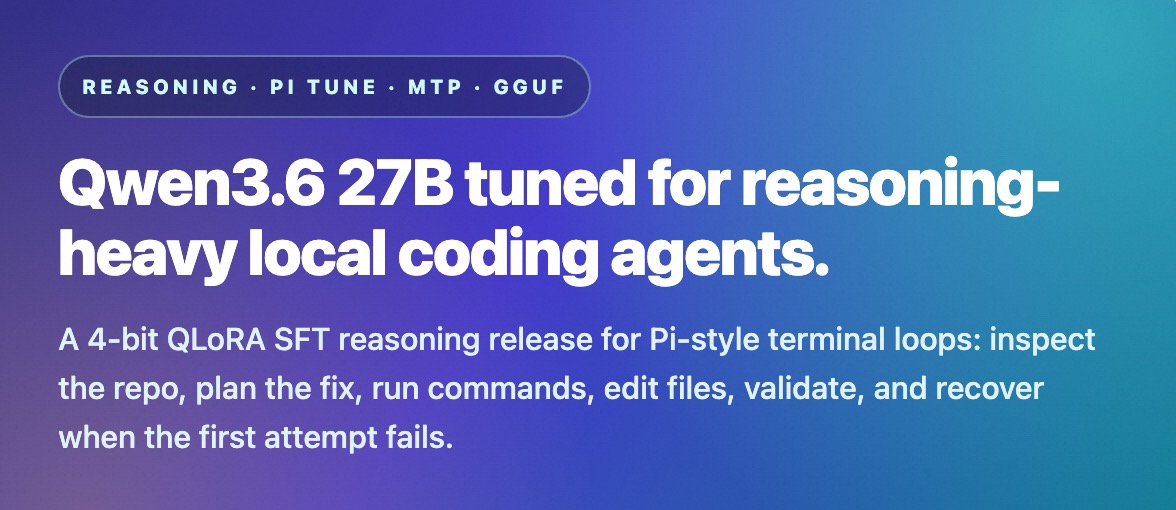
Introducing /visual-plan - a skill to generate rich, visual plans for Claude Code and Codex. Plan mode in Claude Code is incredible. But I always find my eyes glazing over when it gives me this huge markdown essay in my terminal. I found I can make much better visual plans with reusable components. So I made a skill called `/visual-plan`. It generates plans as MDX with visual, interactive components. Diagrams, interactive API specs, schema design changes, annotated code, and even pan and zoomable wireframes. So for any UI work, you can look at a wireframe first, comment on it, iterate, and then have the agent work. I’ve found this to be a much more intuitive interface for reasoning about what the agent is doing. It’s somewhat inspired by that popular post about how HTML is better than Markdown. But HTML can be slow and verbose to write. And it doesn’t look good checked into a repo. This has really made me feel like humans and engineering are entering a new abstraction phase, where we reason about things at the plan level. As long as the plan is good, agents are getting more and more reliable at executing on it. Almost to the degree that we trust the C compiler to compile to assembly reliably. Plans are the new intermediate representation. I also made a skill for the reverse of this, called `/visual-recap`. After the agent works, it gives you a recap of everything it did. Same idea: wireframes, interactive API specs and diffs, schemas, annotated code, etc. So now when you’re reviewing what the agent did for you, or looking at a pull request of somebody else’s code, you can see a visual recap instead of just reading a wall of text. It’s all free and open source. You can find it on my GitHub. Will link to it in the reply because we all know how dumb these algorithms are with links.
I created a website for the Rape Gang Inquiry testimonies with Grok. You can now read and share the quotes from survivors: https://t.co/l2FNJ4vd91 250,000 girls were subjected to humanity’s darkest horrors. We must Restore Britain. 🇬🇧 https://t.co/oJgXC3qDxC
The Rape Gang Inquiry Report. https://t.co/EuKgGWBRhS https://t.co/SD5G9HPVtV
Vector databases or pure grep? Teams are split on the right retrieval architecture for agents. The reality? You need both. Semantic search for a fast first pass; grep and file reads for surgical precision when top-k chunks cut off mid-answer. On June 29, our Head of Engineering George He goes under the hood on the architecture decisions and dead ends behind building this harness into LlamaParse Index. Register here : https://t.co/83ZAIATTnJ

Is your organization stuck in the VisiCalc era for AI Skills? Our Head of AI, @BEBischof, is going to teach you how to think about skills for organizations. How to deploy and administer them, and what the new Skill-development-lifecycle looks like. As your company operating system comes more into view, this is how you deploy it. https://t.co/jvYqwzV3pe

this is what Midjourney + Nano Banana + Seedance actually looks like together. https://t.co/lCPVzN7kFL
5 mins AI workflow: 1. Steal this Midjourney profile + prompts 2. Compose the final still with nano banana 2 3. Show me what you cook with this vibe https://t.co/CQW2ub8Eol
this is what Midjourney + Nano Banana + Seedance actually looks like together. https://t.co/lCPVzN7kFL
https://t.co/4aVgLYY50L
I made Physical AutoResearch sound simple (conceptually), but it took a village to pull off and lots of design thinking into the robot /loopcraft. The hardest part is everything we need to setup *before* pressing Enter. Here's a behind-the-scene tour: 1. Safety harness Letting

Trump administration officials tell WIRED that if Anthropic wants to rerelease Fable 5, it will need to ensure the model's guardrails can't be circumvented. Security experts say that can't be done. https://t.co/itfeqzRgSS

Two years ago I became obsessed with making AI videos. No filmmaking experience. Just a genuine love for the craft. My only real goal has been to make the best videos I possibly can. Last week, this spec ad I made for @Redfin was nominated for AI Commercial of the Year at the @generatedawards. The category included work from @Google, @kfc, and @runwayml (congrats @jforozcop for the win) Still not exactly sure what the Generated Awards are, but it feels pretty good. Really gratifying to follow your gut and actually see progress. Onto the next one.
@JayKurtz90 I have been sharing a few thoughts in my timeline about this: https://t.co/lBtzwkkeZb and in some recent articles about how I am handling these challenges. But lots to explore.
I also never set /goal by myself. The agent is probably better equipped with its context to help you set a strong goal for longer autonomous runs. Smart to have it as a tool for agents. Exactly how I have it built in my orchestrator app. I even built a little UI for /goal in
HyperFrames is now officially live on @Grok Grok knows everything. HyperFrames shows it Any answer becomes a polished video in minutes Proof: this video was created entirely with it https://t.co/6y6VY8lRqh
The @github Copilot app is now generally available. Hand off from agent powered flows in the app to full coding in @code without losing context or the conversation. 🔗 Learn more: https://t.co/wCY5fQJHt4 https://t.co/fPetm6W6xU
The GitHub Copilot app is now generally available. 🙌 The new home base for your work. Pick up what's next, direct agents in parallel, and land your PRs, all in one place. ⬇️ https://t.co/CzGspjw66P https://t.co/1zygo38zrX
🚨 A Netflix engineer built an open-source proxy that cuts AI token usage by 60-95%. Zero code changes. Benchmarks show ±0.000 accuracy regression. ✨ 29.9k stars on GitHub. It sits between your app and the LLM, so every tool output, code block, and conversation history gets compressed in-flight. 🚫 No summarization, no loss. 😎 Just 60-95% fewer tokens with the same answers. Works with Claude Code, Cursor, Copilot, and any OpenAI-compatible client. One pip install, one env var, done. Netflix uses it internally. Apache 2.0. Built by Tejas Chopra. https://t.co/u1OIlMF5gm

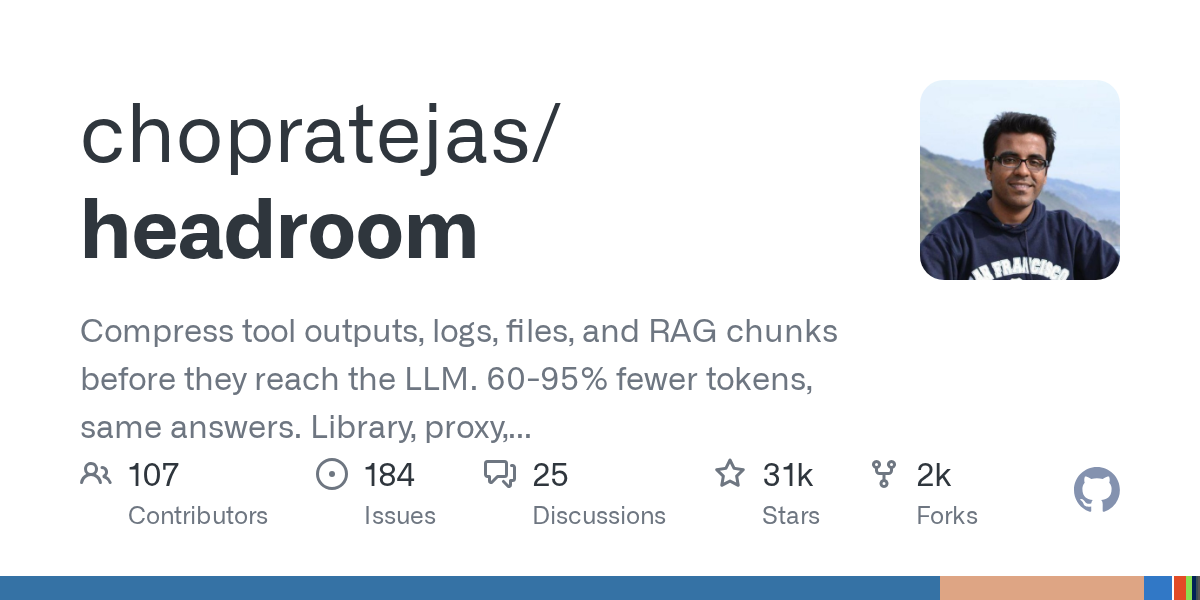
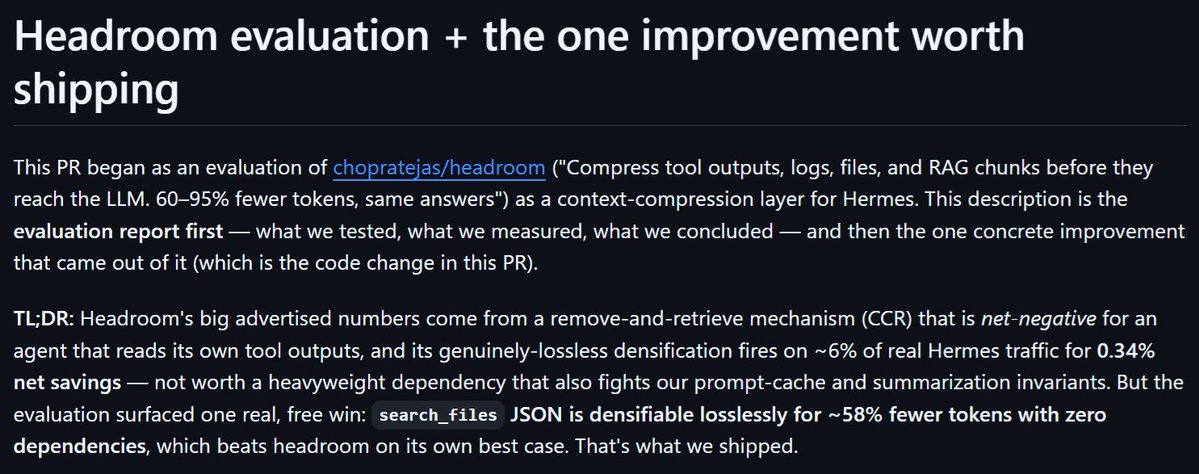
Had my Hermes Agent evaluate headroom. Key conclusions: Most of what it would do for Hermes actually is net greater token cost 🧐🧐 There was one aspect it discovered would save ~60% of tokens used on the search file tool, which we will be integrating! Read the full report: https://t.co/8X7et0ctu2
🚨 A Netflix engineer built an open-source proxy that cuts AI token usage by 60-95%. Zero code changes. Benchmarks show ±0.000 accuracy regression. ✨ 29.9k stars on GitHub. It sits between your app and the LLM, so every tool output, code block, and conversation history gets
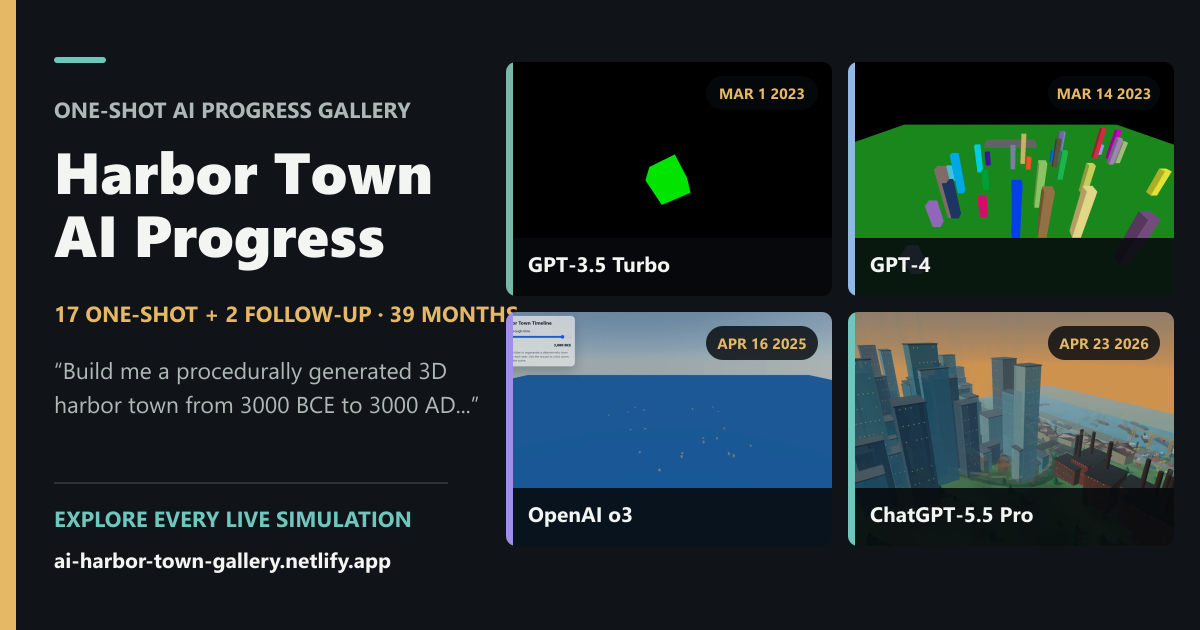
I have a fun, oddly useful AI benchmark: "build me a procedurally generated 3D simulation showing the evolution of a harbor town from 3000 BC to 3000 AD, it should look beautiful & allow me to have some control over it" Play the gallery of 20 models: https://t.co/zN2uHY1gl8
Unreal Engine 5.8 ships today with experimental MCP server support: Your sources, your pipeline and your workflow—simply configure the MCP plugin and connect to any agent. Get familiar with the MCP server and the PCG Primitive Plugin today and see what teams can build together: https://t.co/cDITLWWv2F