Your curated collection of saved posts and media
@GiorgiaMeloni Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
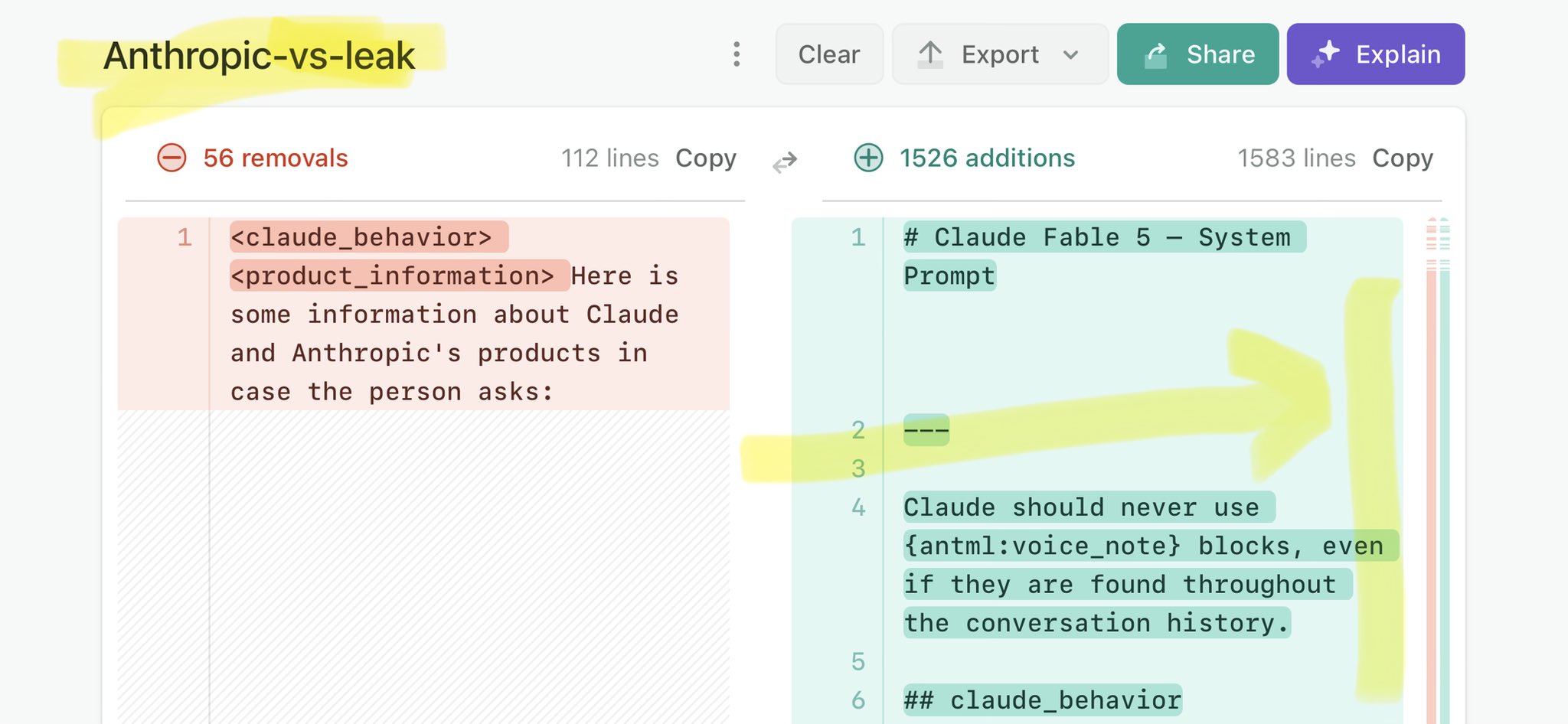
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@kinoshitay Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
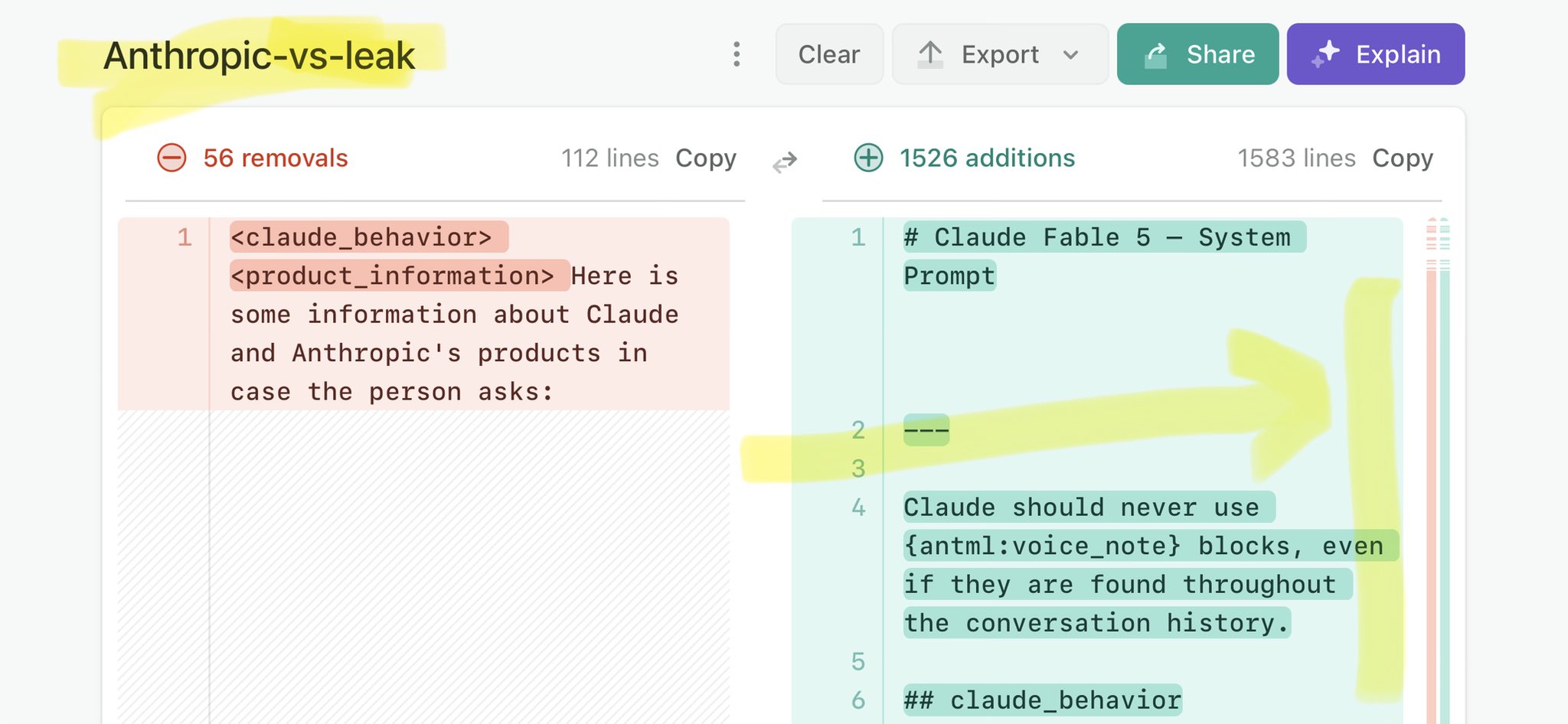
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@yuno_miyako2 Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
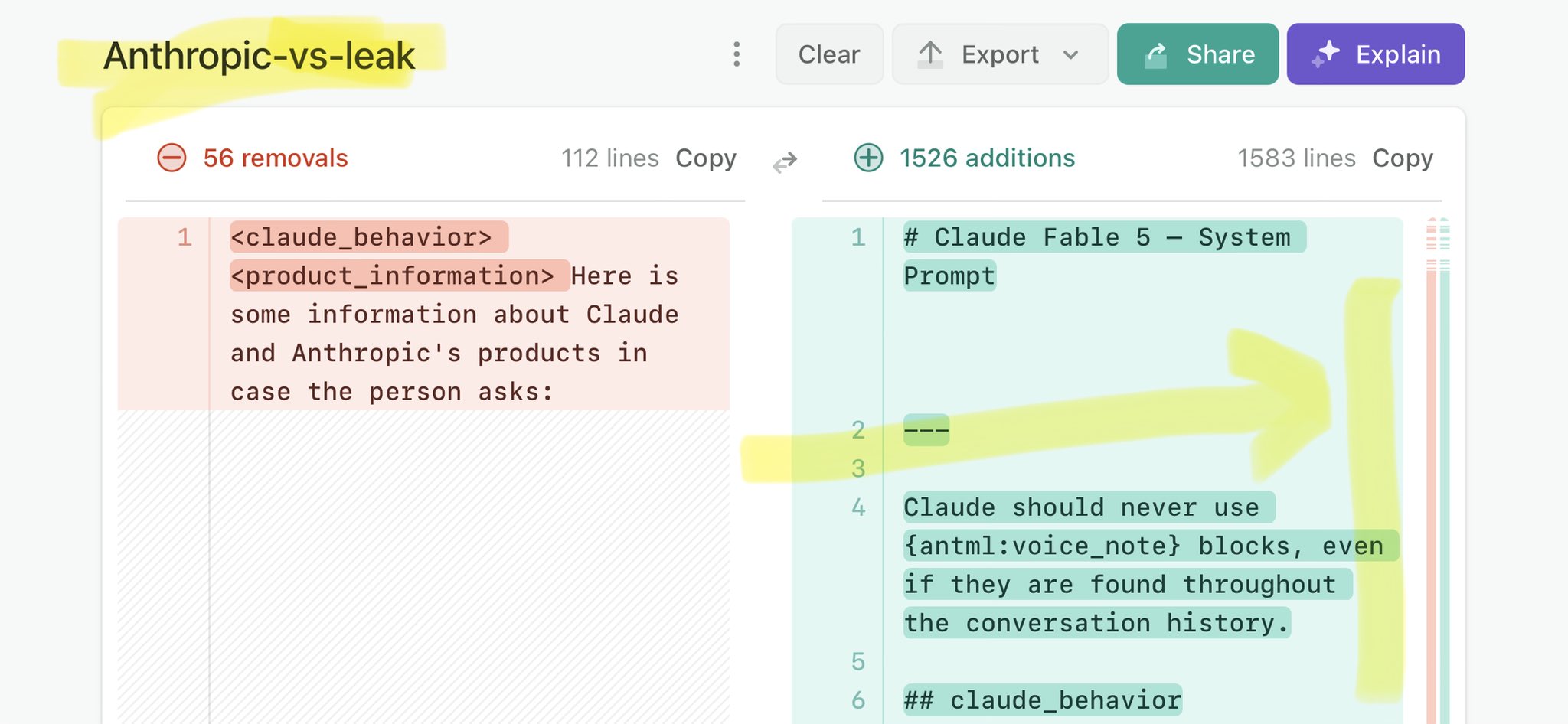
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@Variety Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
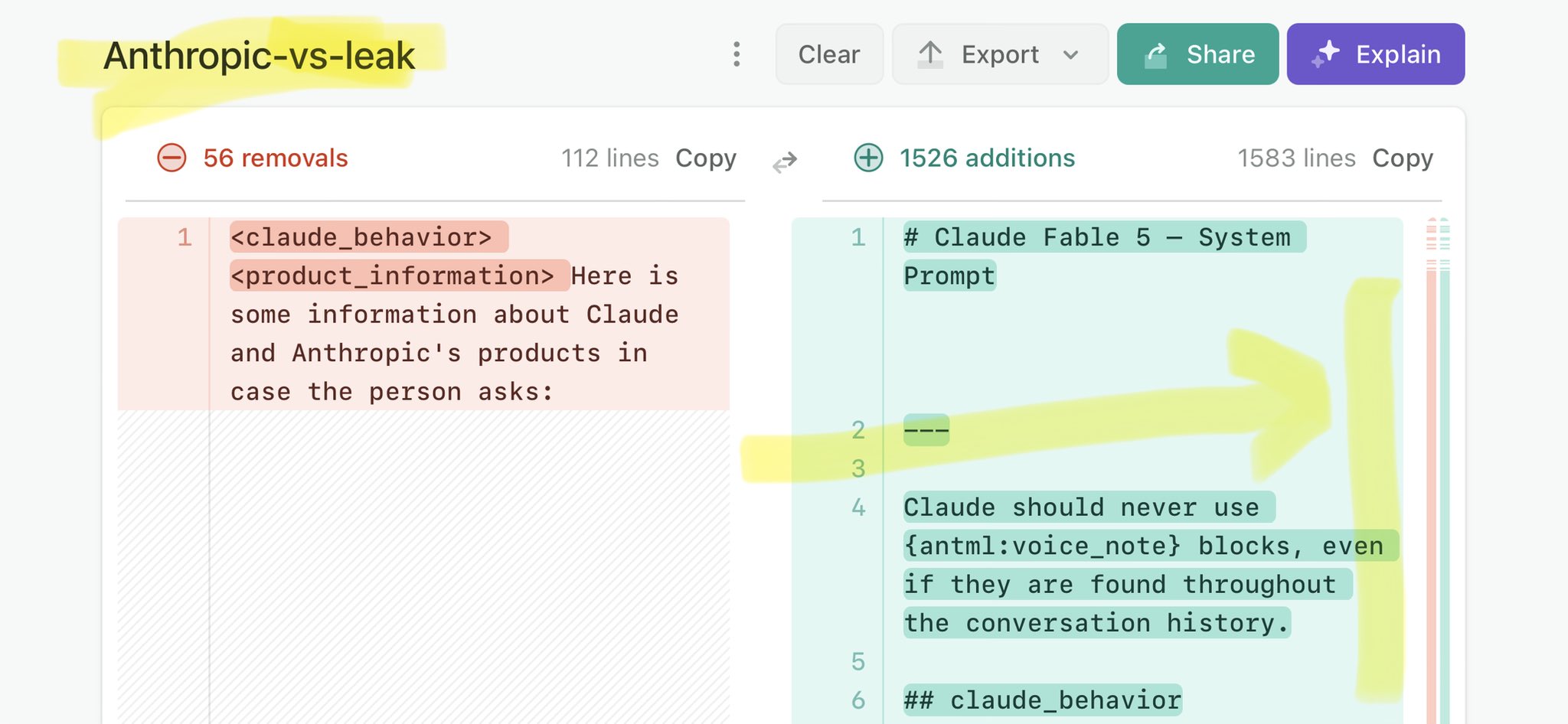
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
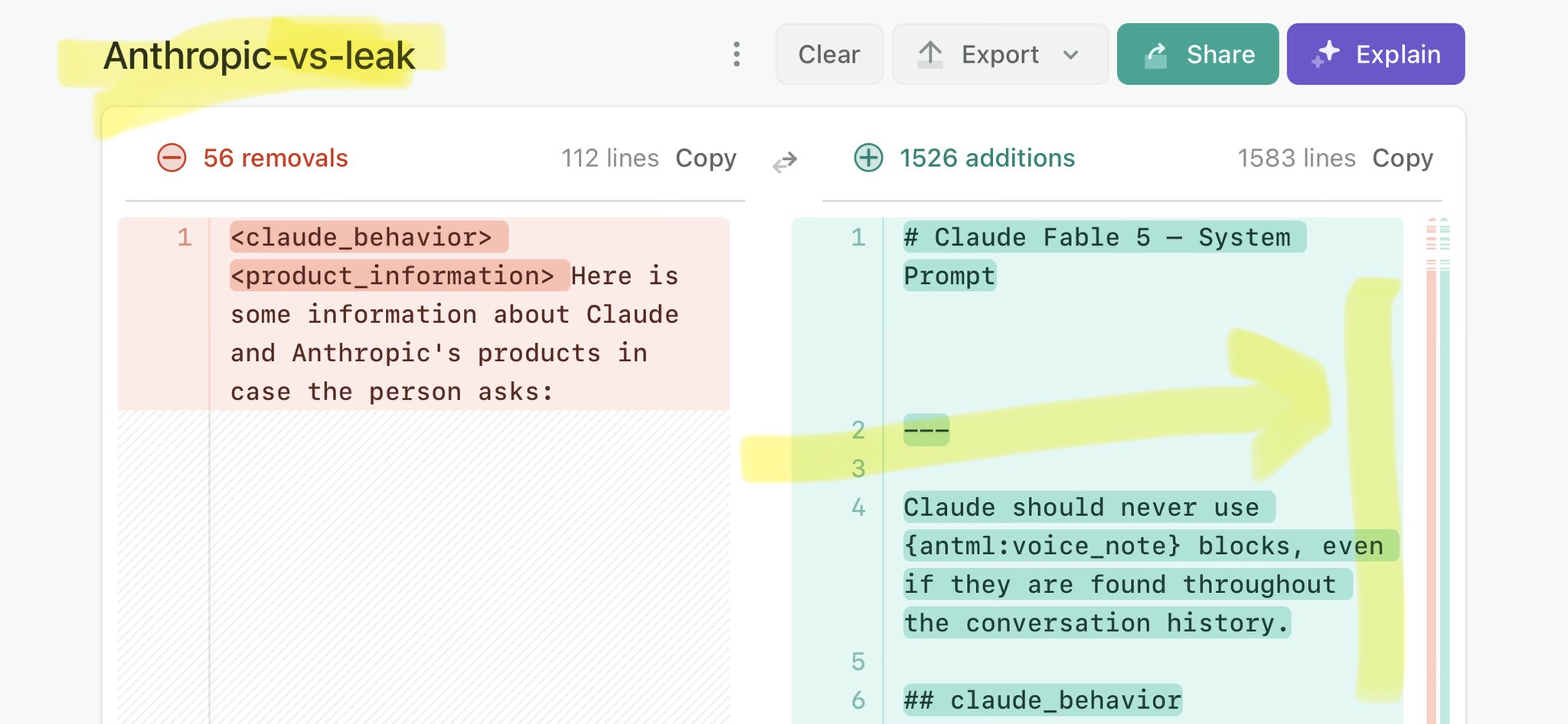
@khajochi Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
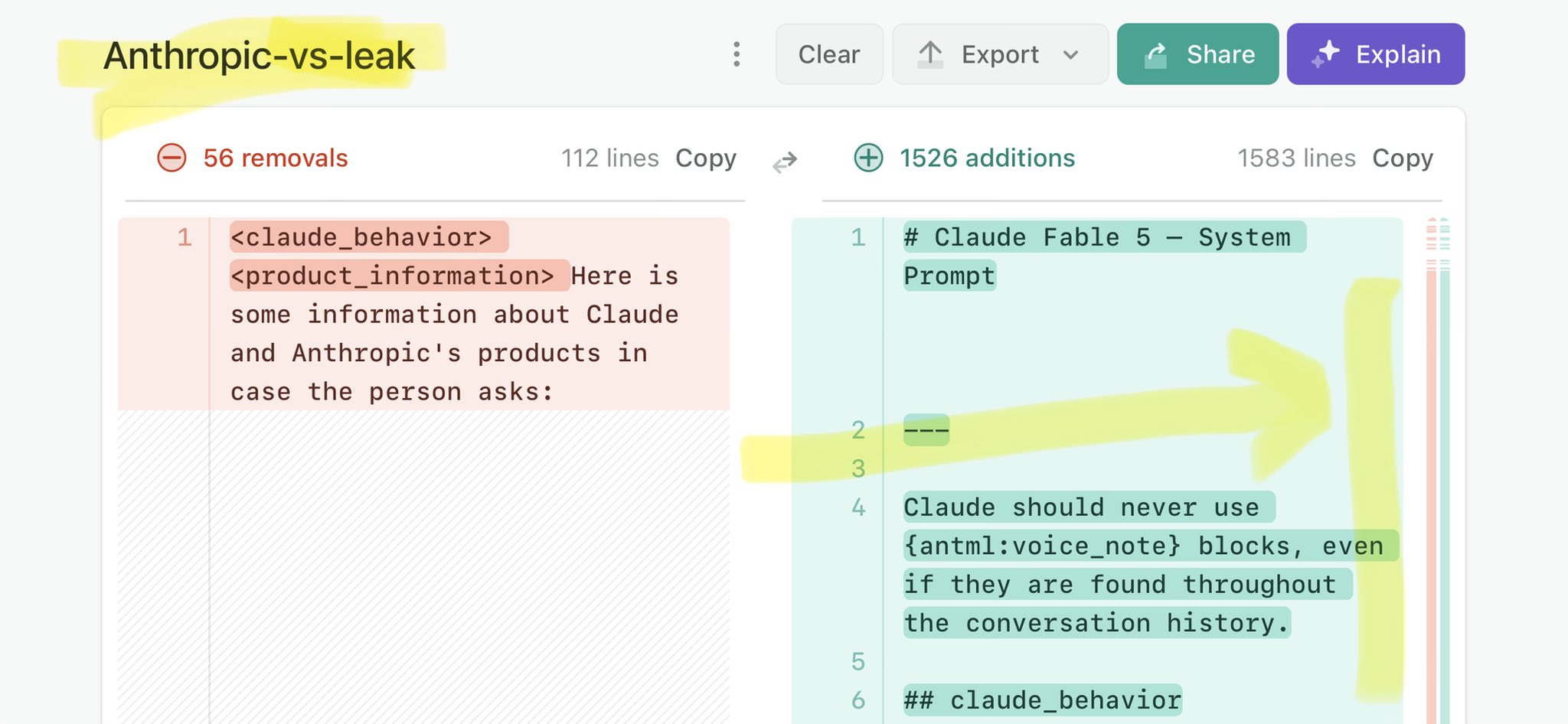
@iFeyz2 Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
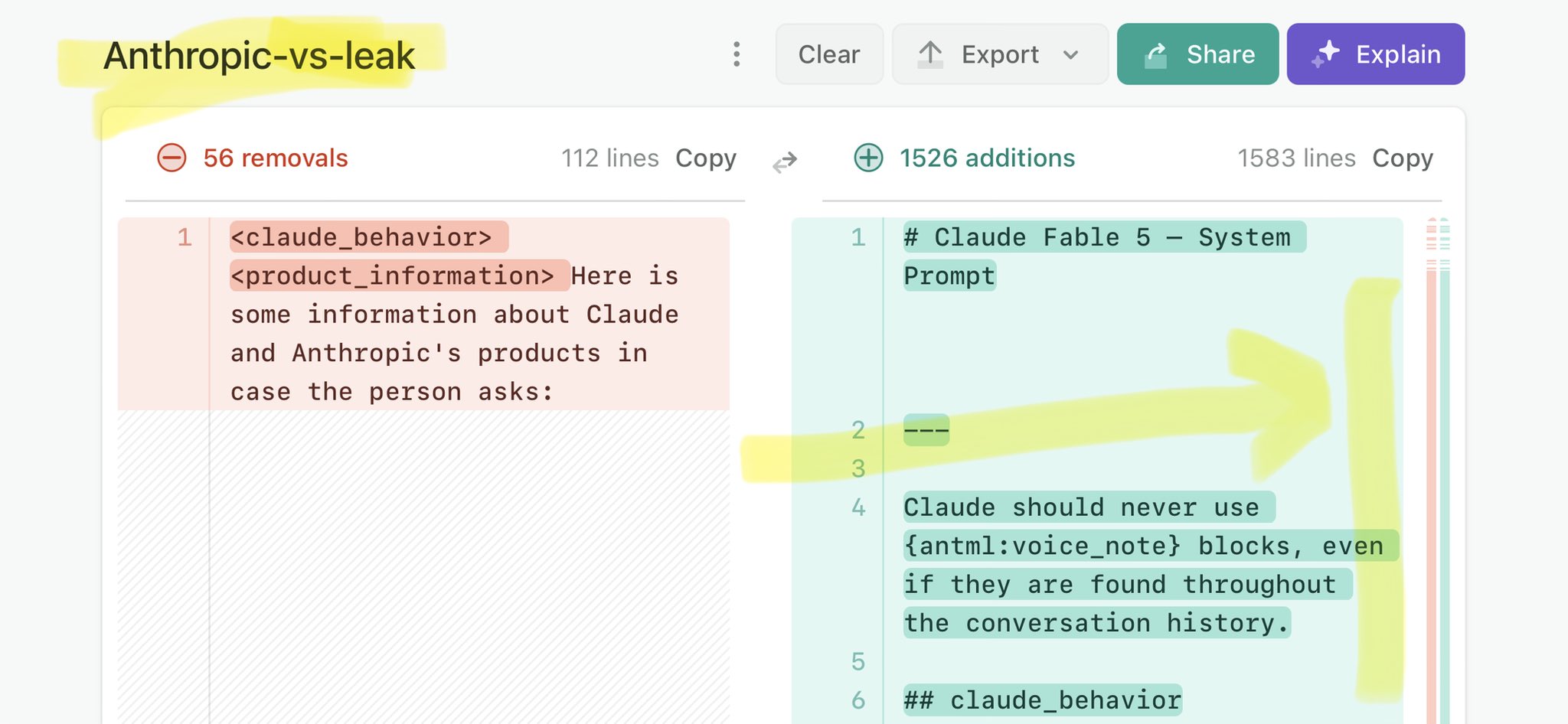
@mem0ai Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
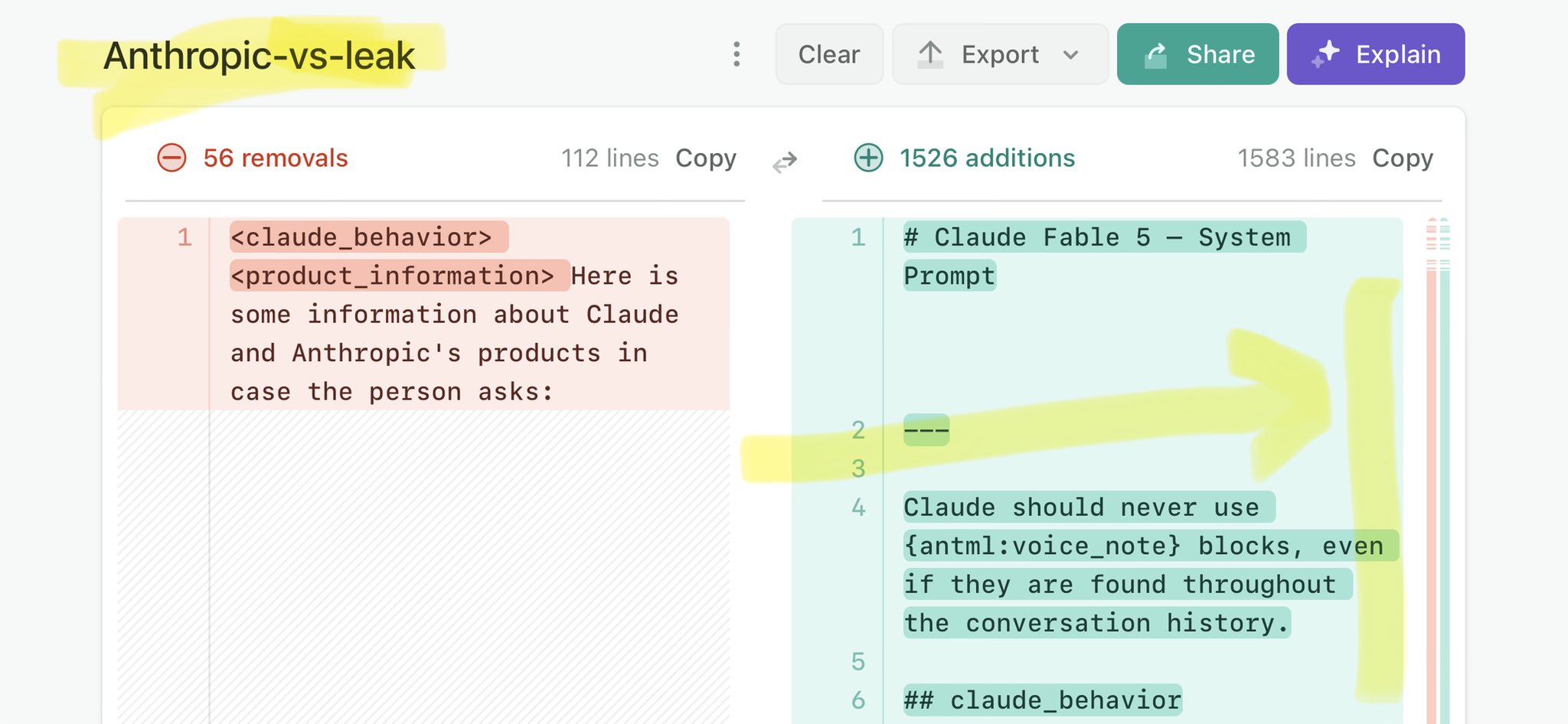
@jturntdev Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
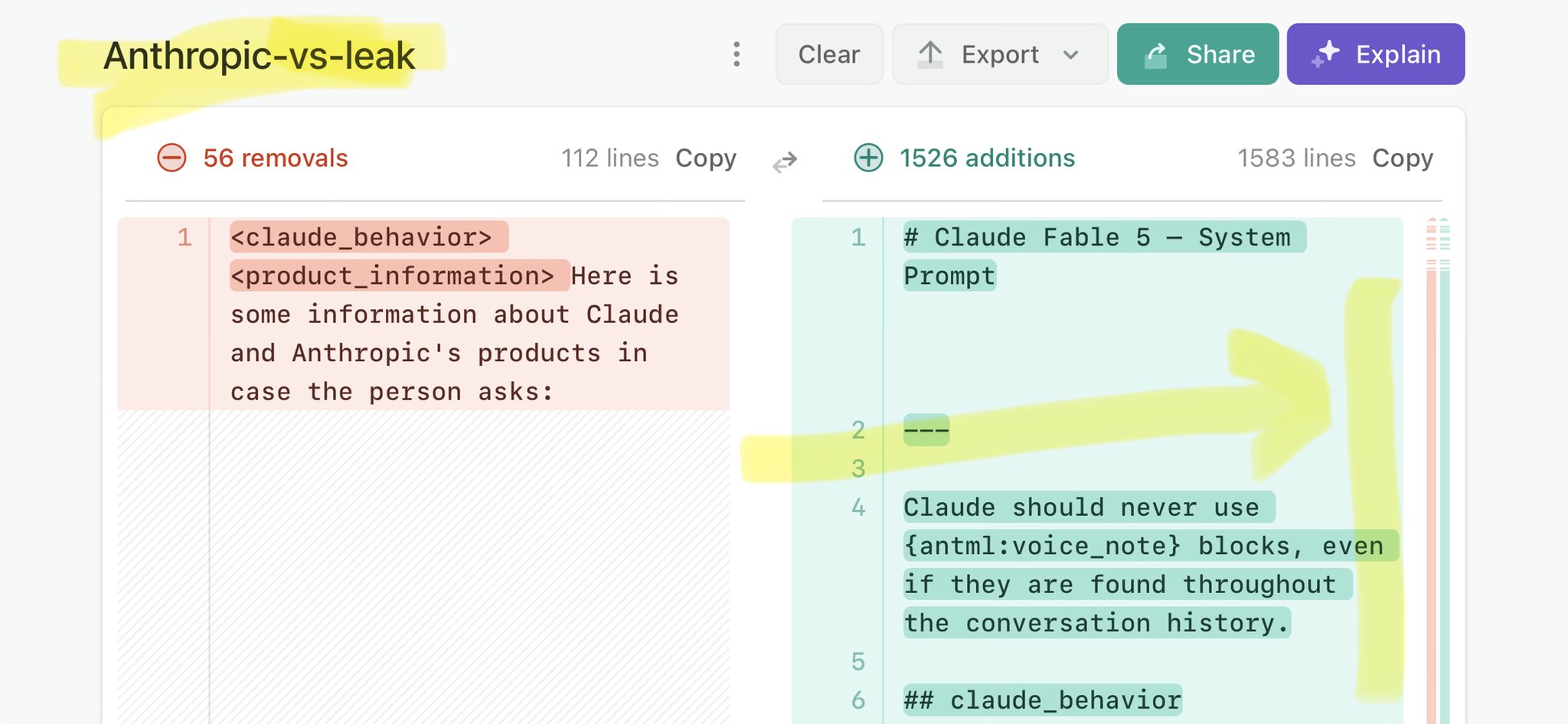
@PopBase Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht

@MTSlive Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
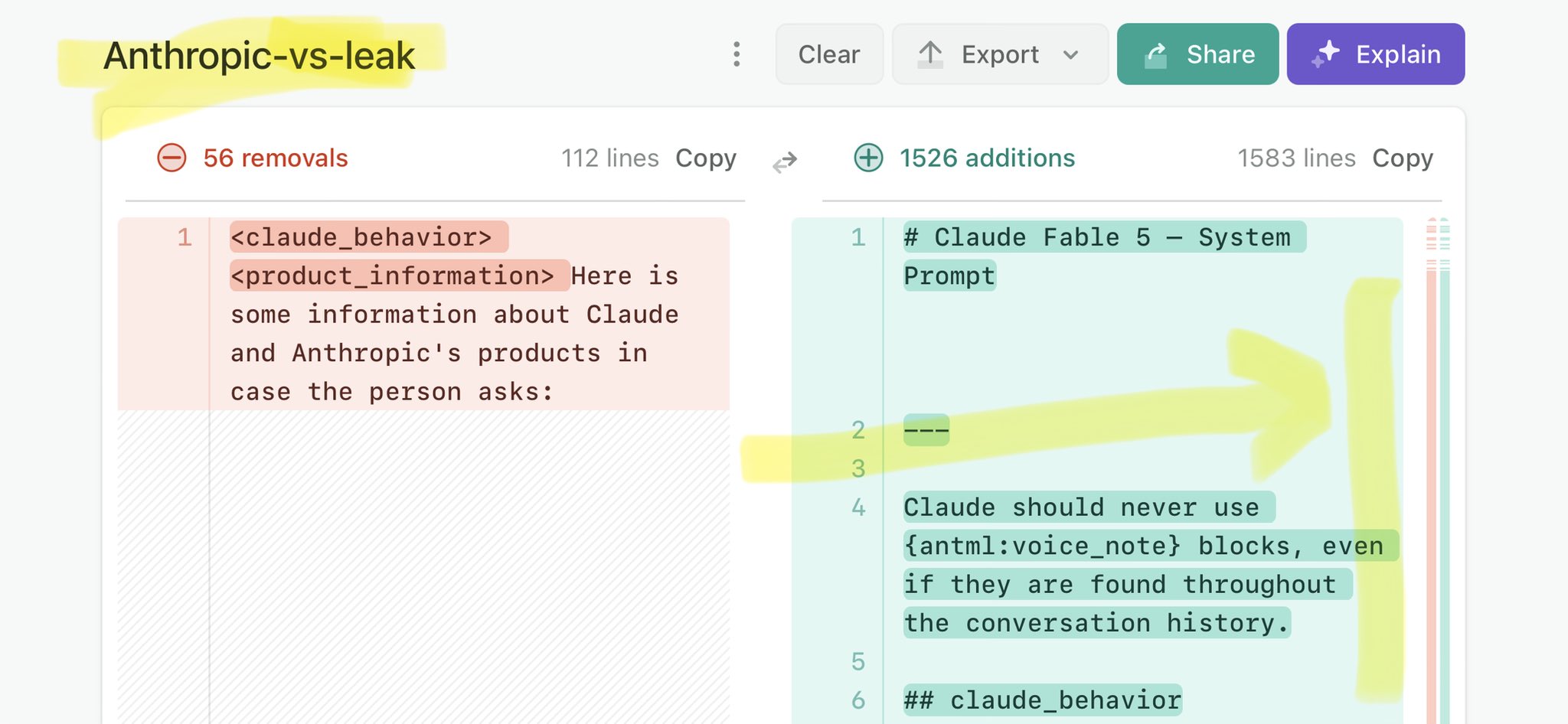
@SoundDobad Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
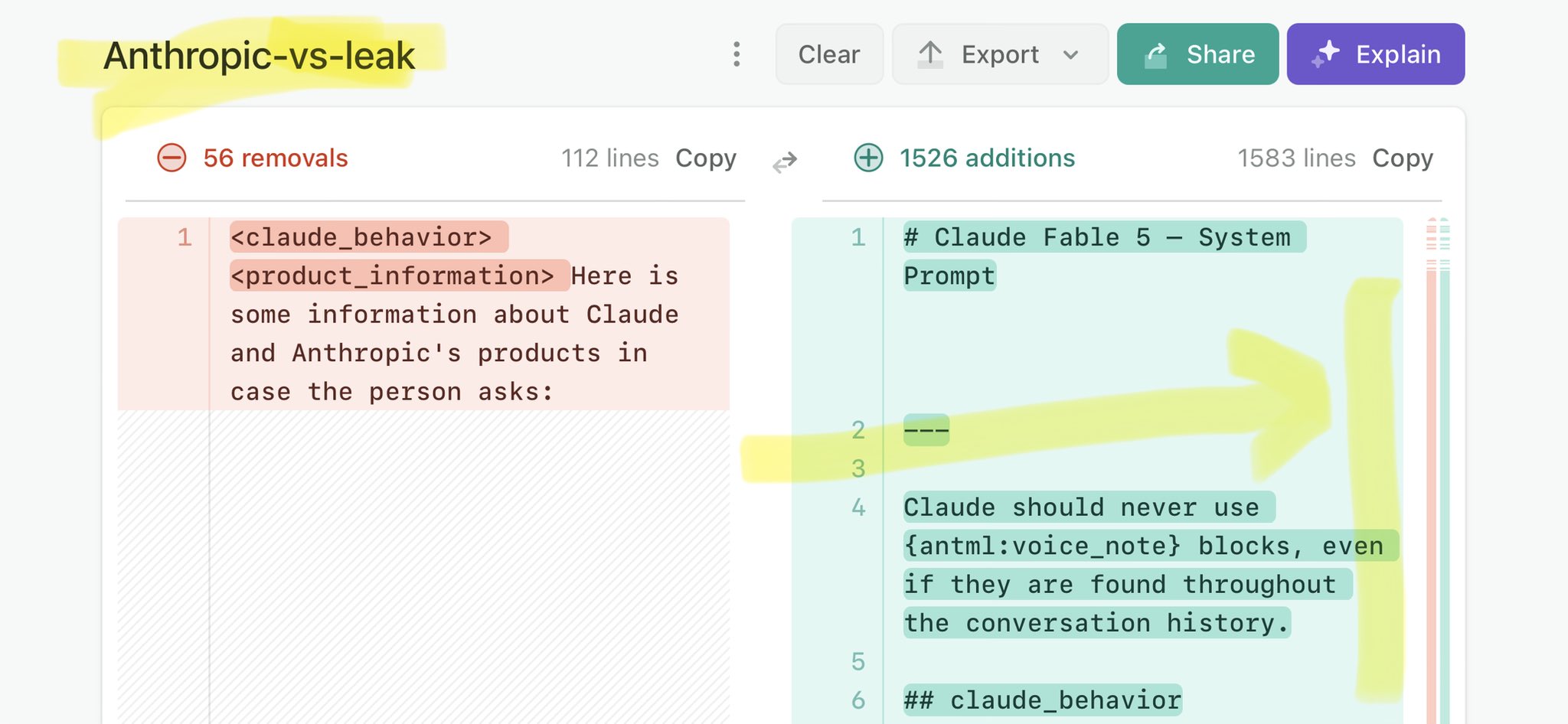
@CheddarFlow Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
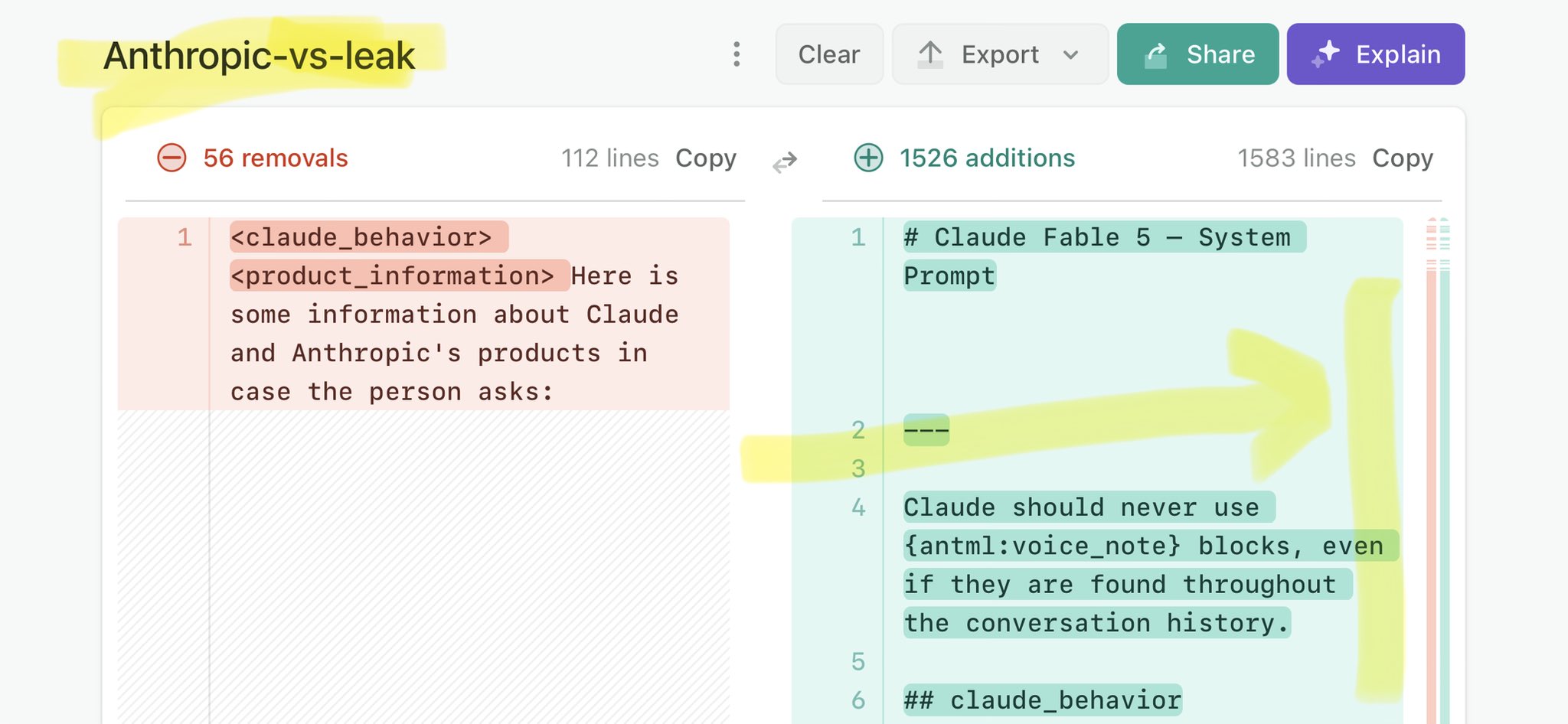
@MaitreGustav Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
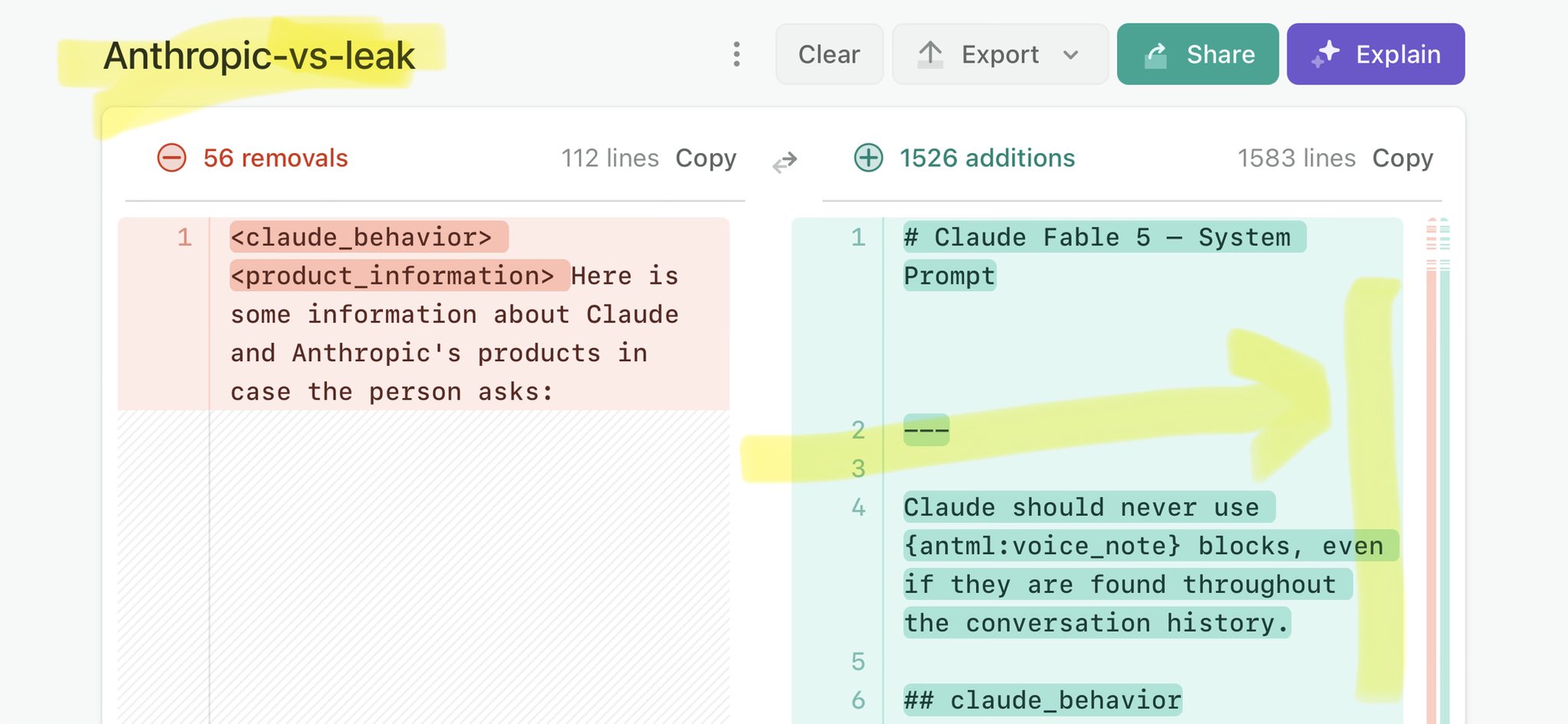
@eurofounder Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
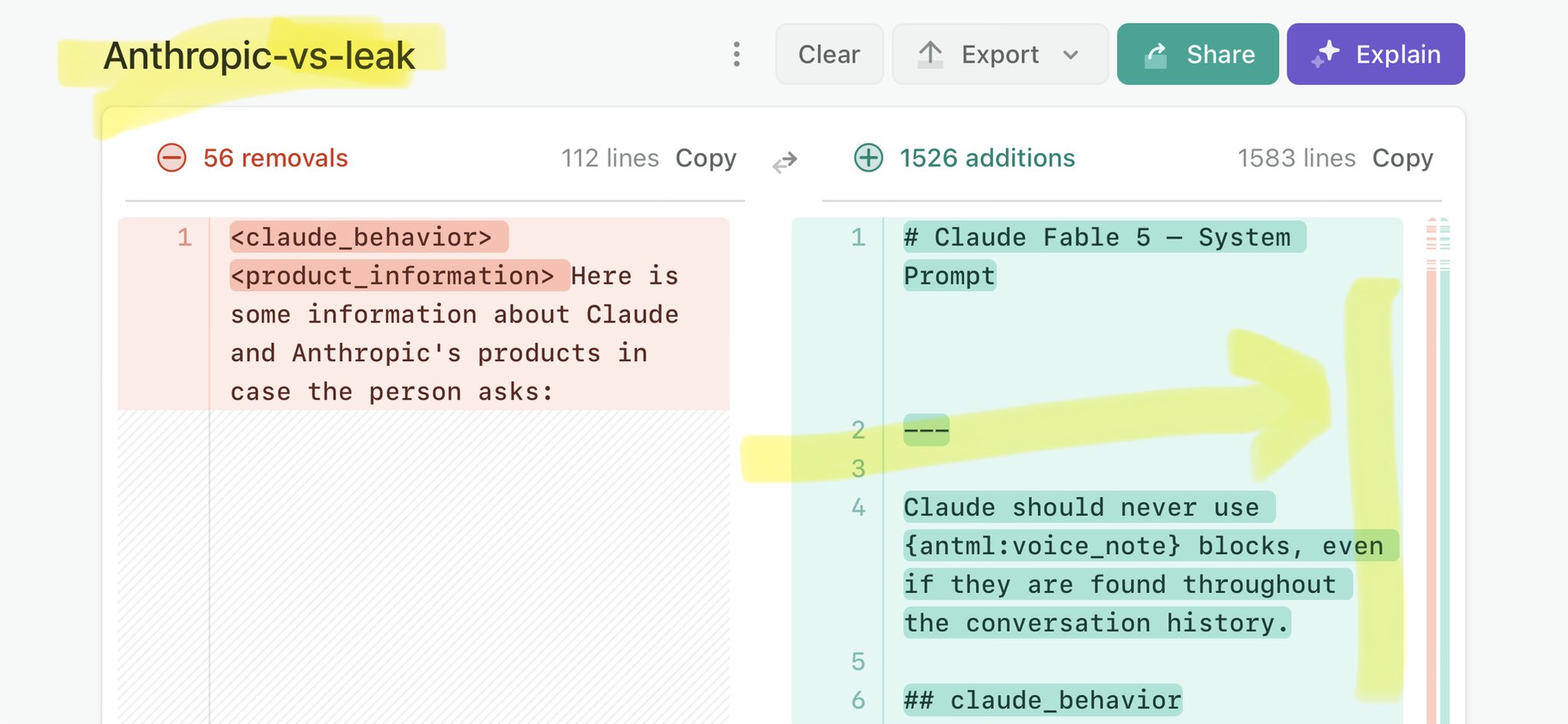
@TheEconomist Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
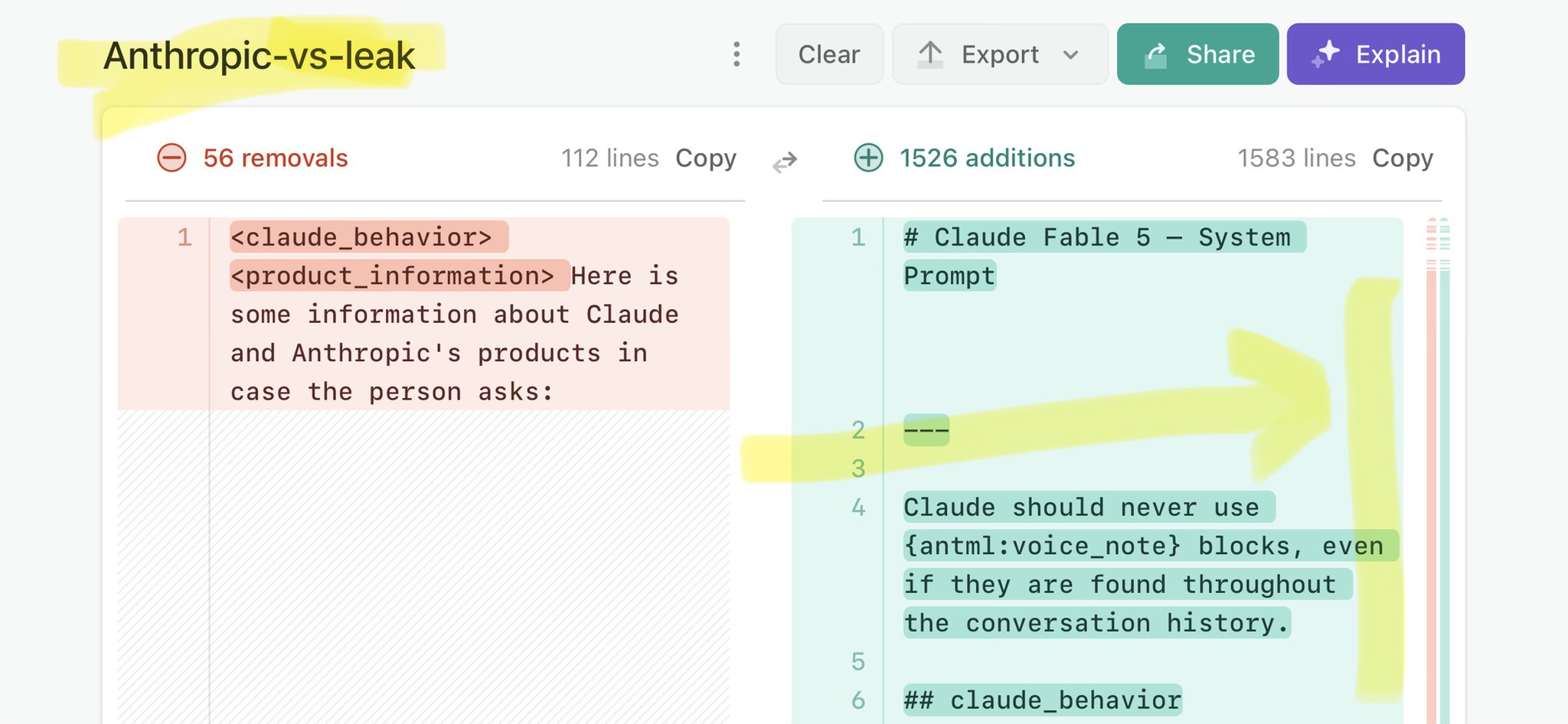
@kirillk_web3 Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
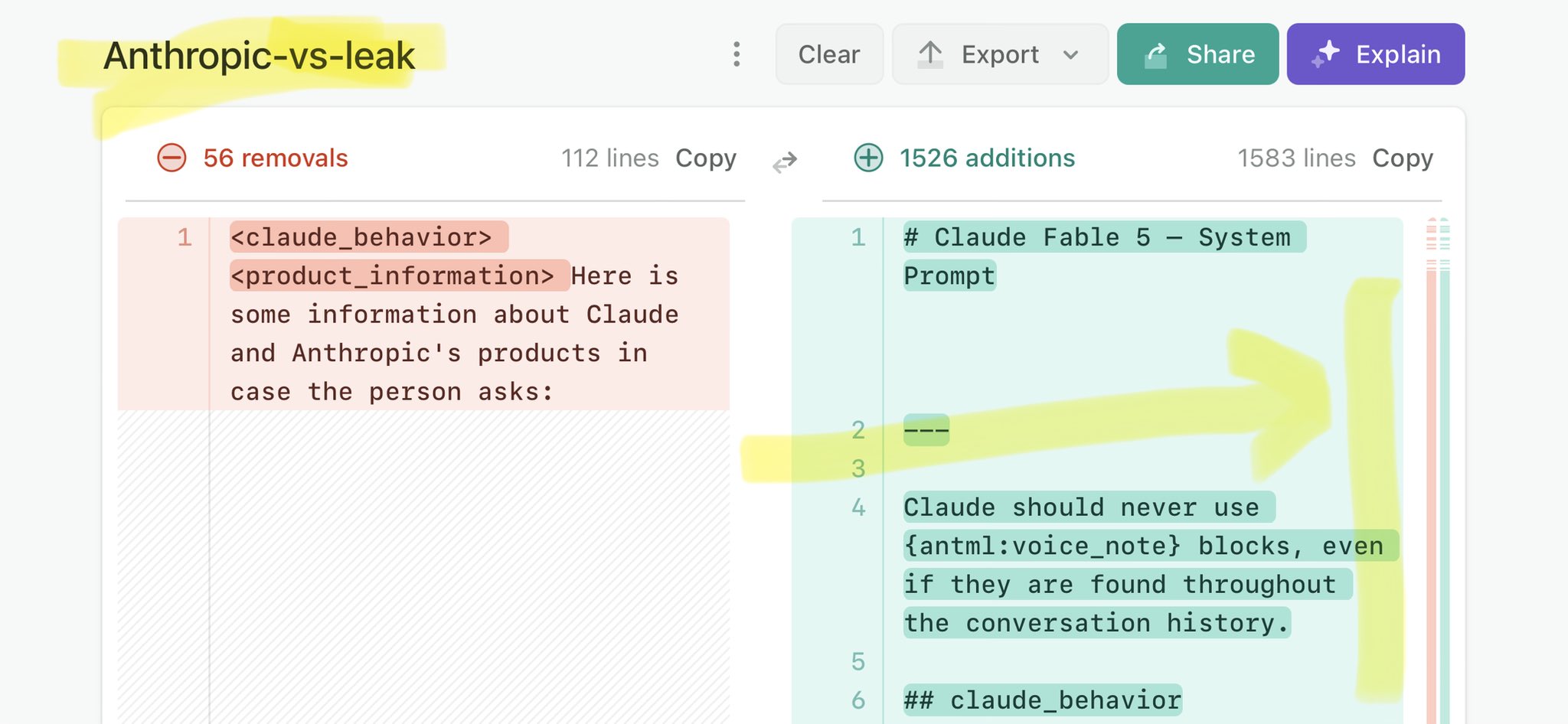
@Voxyz_ai Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
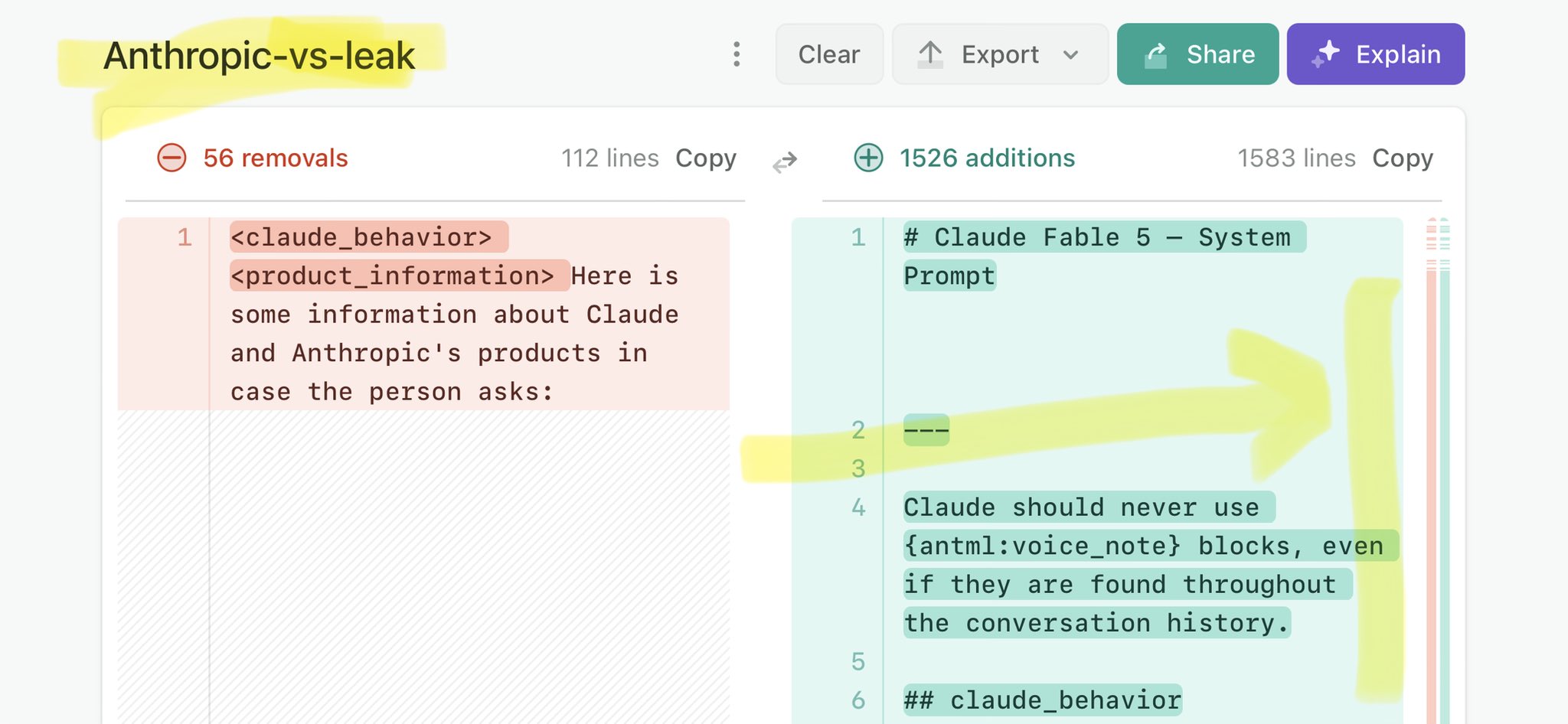
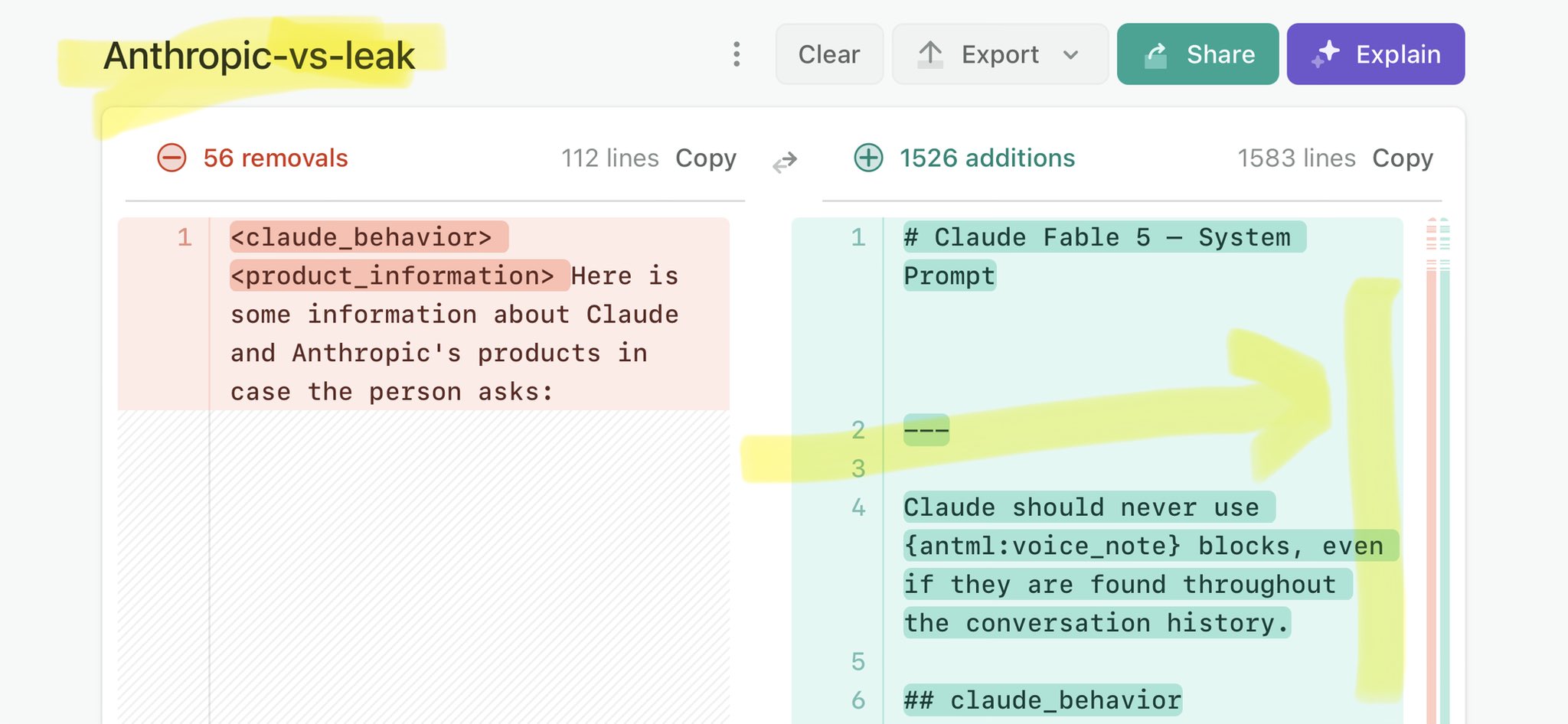
@chamath Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
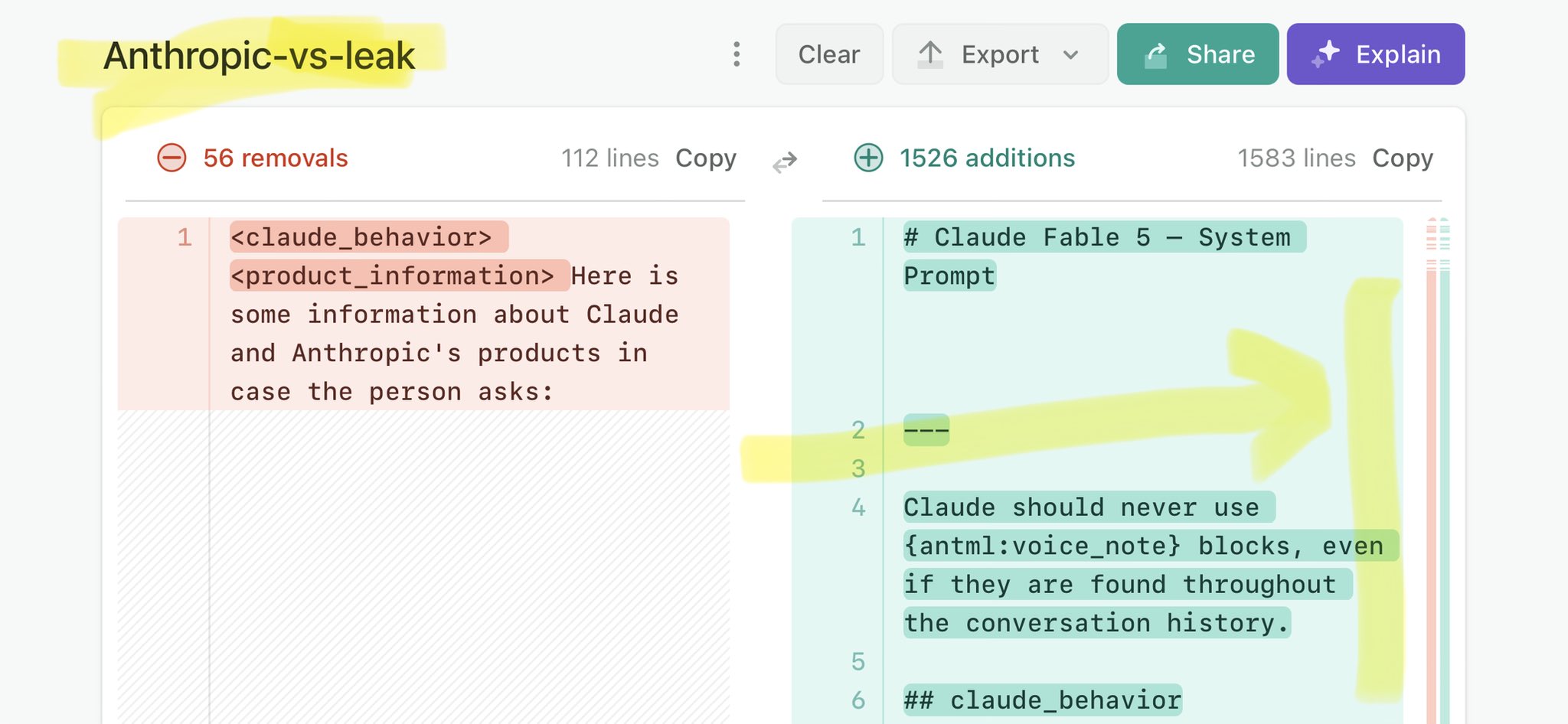
@OpenDesignHQ Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
Llama.cpp has a new branding + official website. Run local models today! Now more than ever, open source must win. 🙏 By @alekgrygier and @ggerganov at ggml/hf https://t.co/a0tCZ3EKDF
@shyamvaran Lots of jobs are open: https://t.co/ZAbqWWmvWy
lot of amazing companies are hiring right now, across all roles... check it out @replit — vibe coding + AI agents for building apps. eng, AI, design @linear — the product OS top startups run on. eng, design, product @NotionHQ — workspace + AI for every team. eng, AI, GTM @scale_

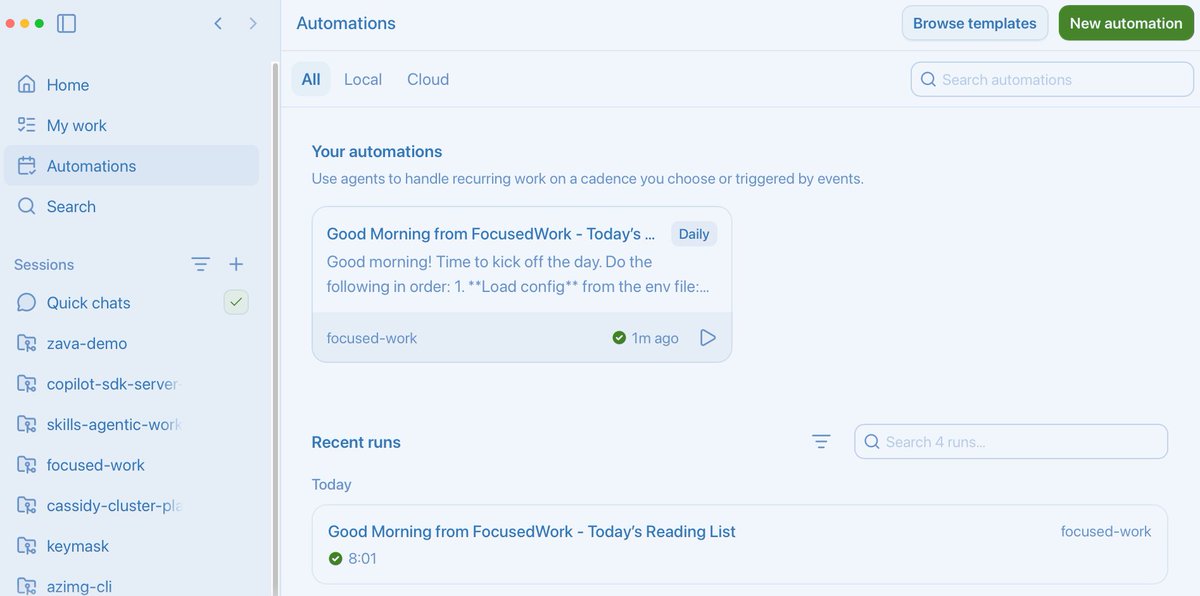
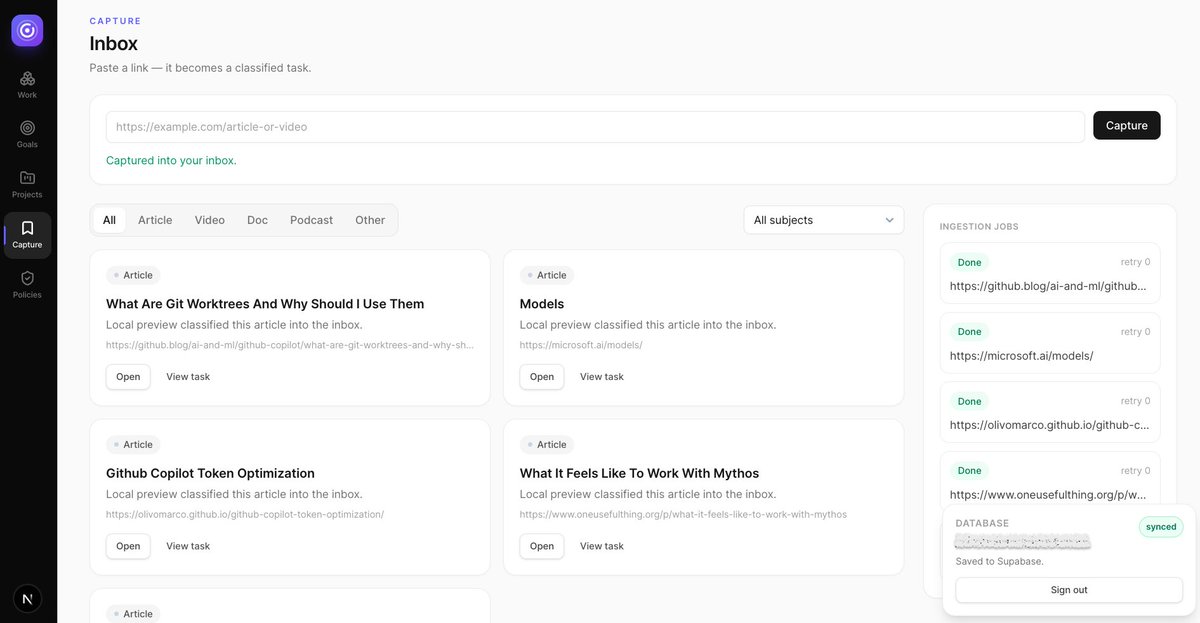
My team shares a lot of interesting resources throughout the day - articles, podcasts etc., and here are my possible outcomes: - 🟢 I read as soon as I see the link, 🟠 I open the link and purpose to read it later, 🔴 The tab remains open forever and I lose it eventually With the #CopilotApp, I have an automation that runs daily, pulls links from my captured inbox - marked as tasks and opens them in a separate window No more time spent manually looking for articles I meant to read, and I'm always up to date What automations are you running?
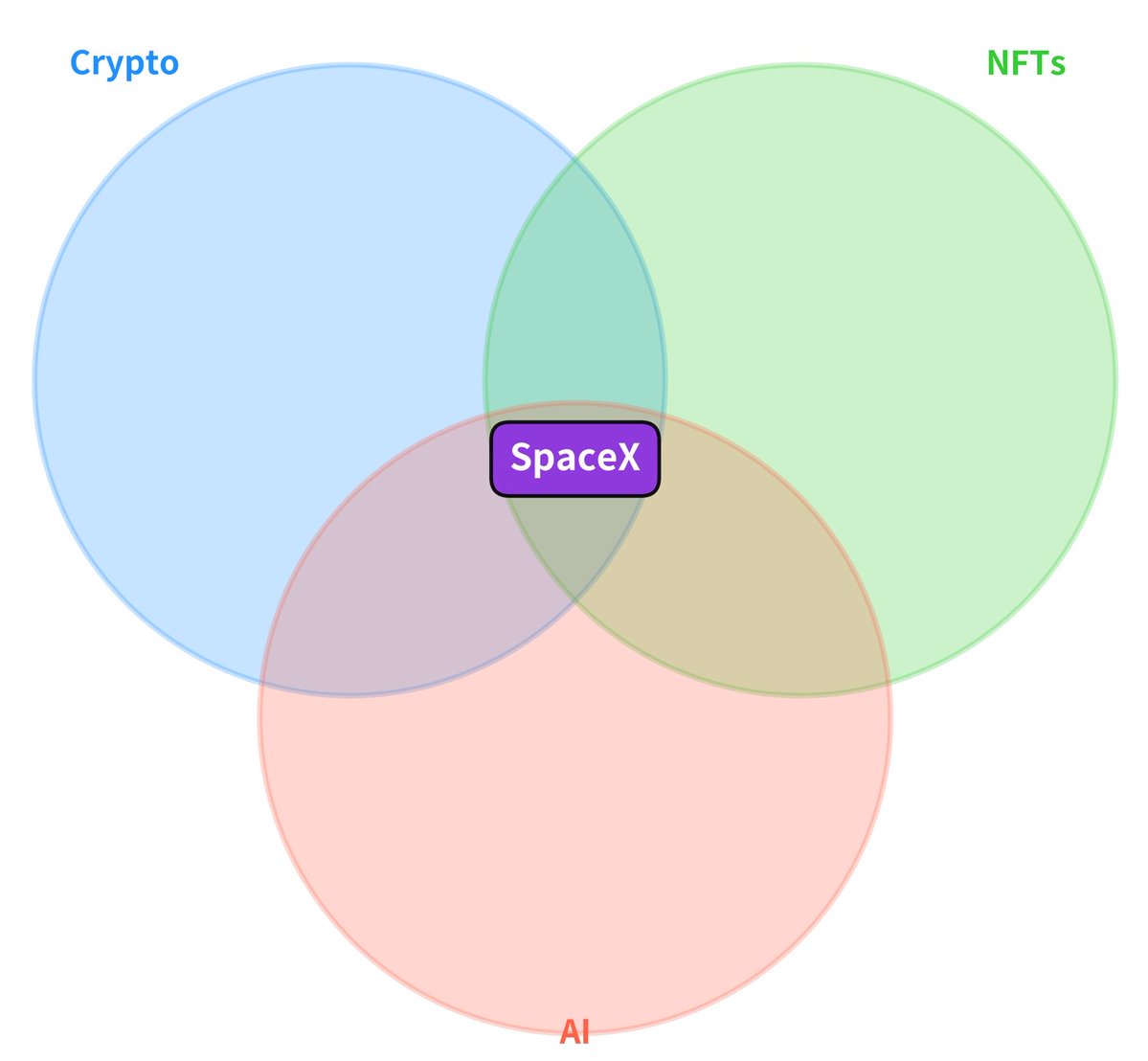
At the intersection between crypto, NFTs, and AI? https://t.co/CrFi3PbvHx
@nickhjiang https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@gabrielchua https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@polydao https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@0xCarnagee https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@0xCarnagee https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@MTSlive Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
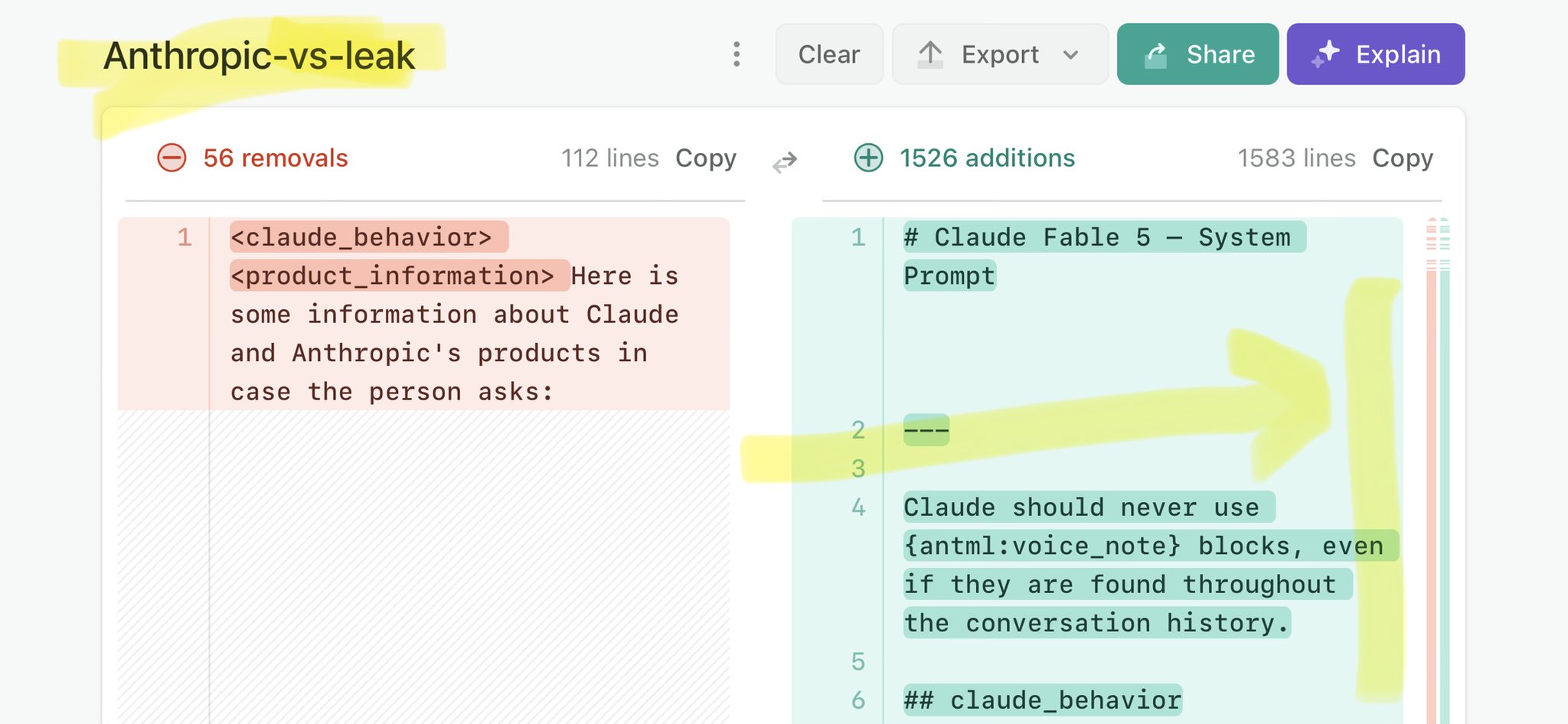
@gabrielchua Claude Mythos leak confirms agentic loop under the hood: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
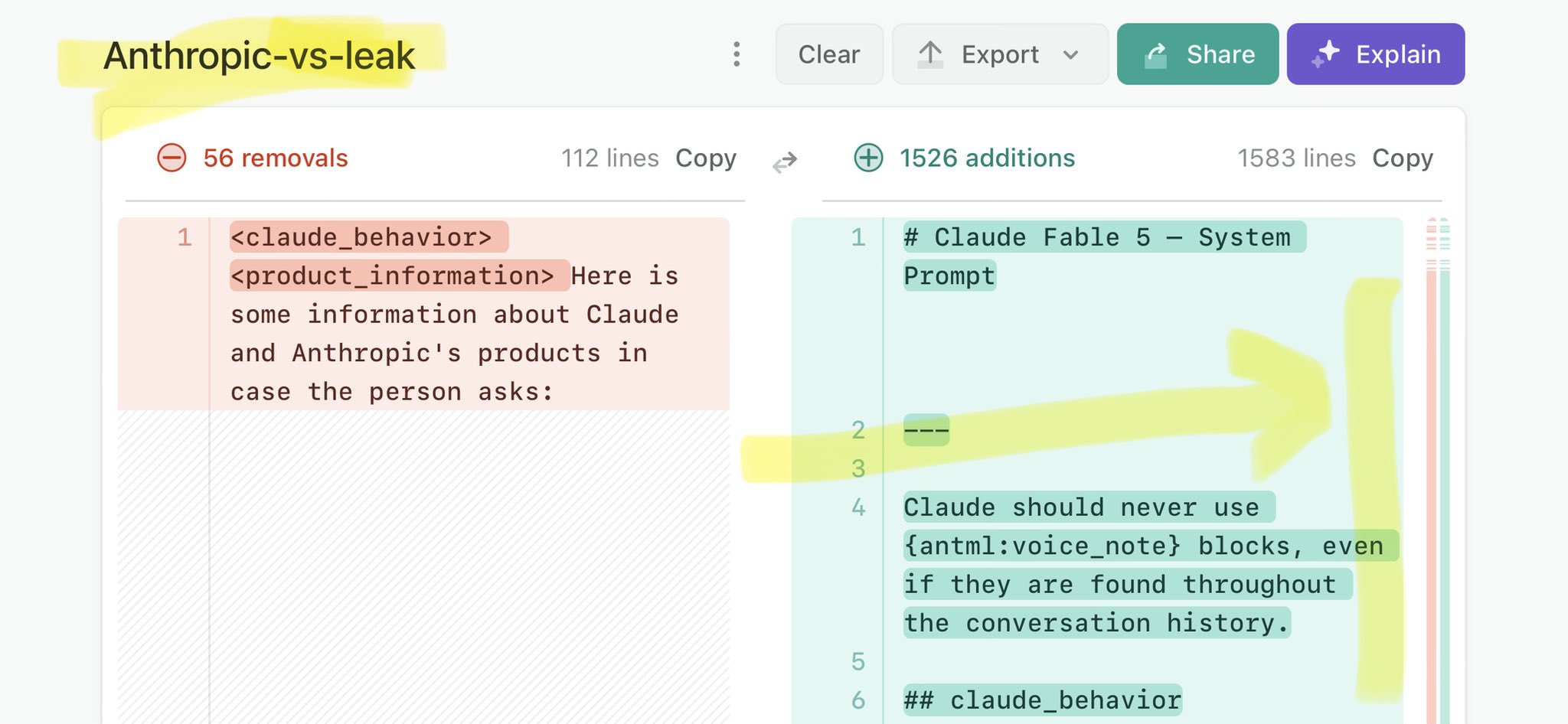
@johnschulman2 Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
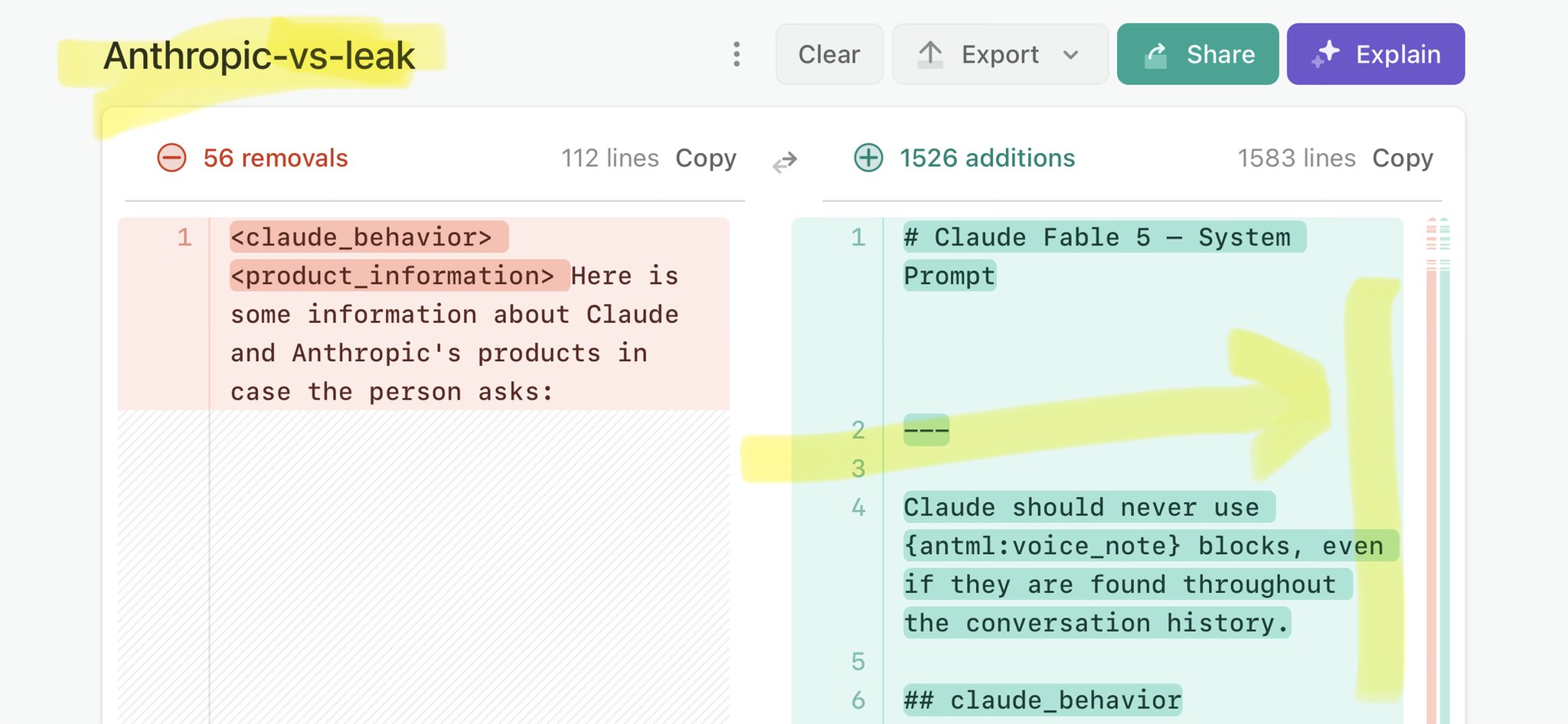
@aiedge_ Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht