Your curated collection of saved posts and media
A break from the usual posts. Big day in our neighborhood. #sail250 https://t.co/XapHbhfHi0

South Africa became the first country to withdraw a national policy document after officials discovered the text was littered with fake research citations generated by AI https://t.co/rkFzohBaGm

if you're not using Hermes desktop yet, you're missing out on something special. i was only using cli because of my headless sparks. i have it on my mac mini, from there i can also ssh into my dgx sparks via nsync. think about how you use codex app , and bring that mindset over. very powerful use cases when you have multiple devices on your network all being captured in a thread here. nothing comes this close on how you can easily add your api's. too smooth!! just my late night thoughts as im hacking away here.

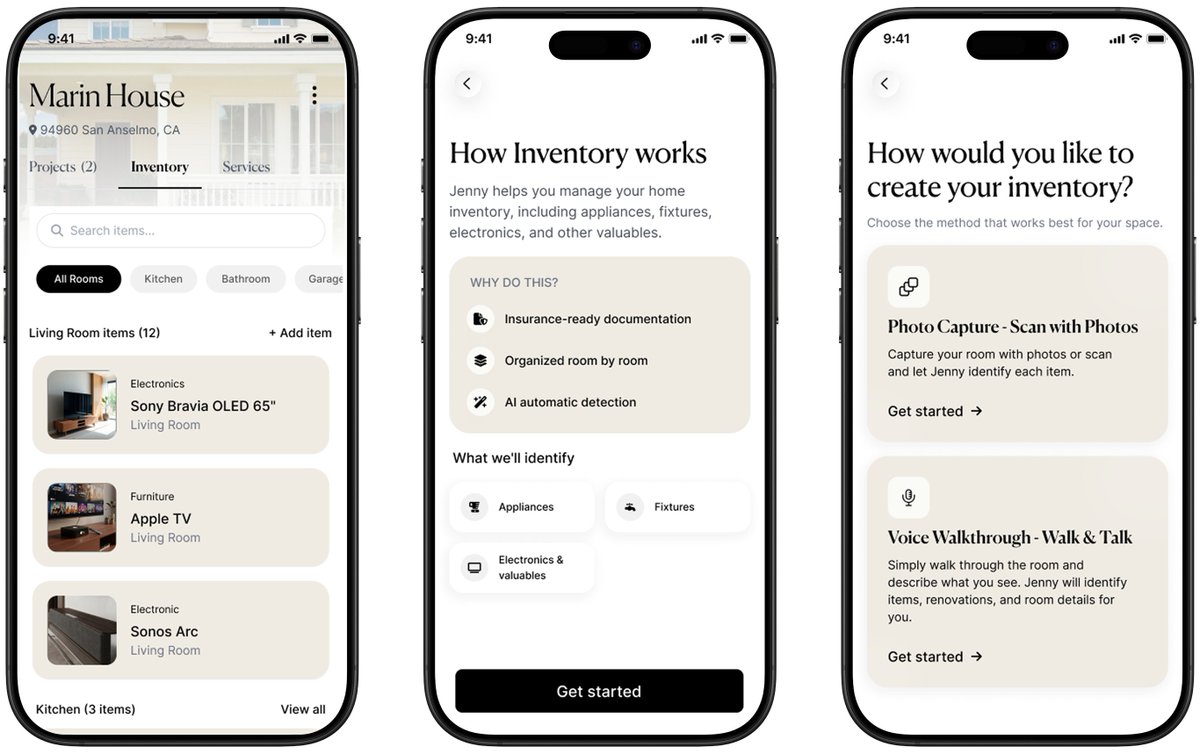
We started building @HiJenny_ai less than 6 months ago to fix American homeownership. Today, on the country’s 250th anniversary, we’re shipping the first-ever AI Home Manager for homeowners and renters. Jenny itemizes everything in your home via voice, photos, and video so your electronics, art, and valuables are properly documented and insured. She books and manages service calls with plumbers, electricians, HVAC, landscapers, and handymen through an AI voice agent that calls and schedules on your behalf. And when you renovate, Jenny helps you scope the project, pick contractors, and manage the work end-to-end from your phone. Think ServiceTitan‑class orchestration, but for everyone—homeowners, renters, contractors—without the call center. Already 1,000+ homes are managed with HiJenny. Try the app: https://t.co/HH4v0se2pL

📢WorldMesh is accepted to #ECCV2026, and we're releasing the code today! 🎉 Led by @mschneider456: navigable, multi-room 3D scenes from a text prompt, with a mesh scaffold conditioning image diffusion for global consistency + photorealistic detail 👇 https://t.co/8fXCl2flIu https://t.co/Z1HkoO3s37
https://t.co/v4deXtALmO

250 years of rebels! Happy 4th! 🇺🇸 https://t.co/7RwDgVIcpY

"History can be written of monsters, and in them," reads China Miéville's "Theses on Monsters." https://t.co/Eq9dVd4cCf https://t.co/D6Cuqx99z4
as a society we need to invent another classic monster for the modern day, vampire, werewolf and frankenstein (etc) are all so iconic, why cant we invent some more


@OrwellNGoode https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@_yesbut_ https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@iiamkrshn https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@RespectfulMemes https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@f1trollofficial https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@fiagirly https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@elonmusk https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@Tesla https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@tesla_na https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@elonmusk https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@coreyganim https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@Business_Nerd_ https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@Forbes https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@hiroyukanai https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@BBCNews https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@PalantirTech https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@OopsGuess https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@nikkei https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@nobel_824 https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
@ClaudeCode_love https://t.co/zGphBSSlKr
My brain: Back to you boss. https://t.co/bz0dUjrSyN
It’s hard to believe but this is a picture of the United States reflecting pool before the revolution happened. The US was once a very westernized country https://t.co/RqBtfACFks

@UiSavior https://t.co/pbL1YZfu7M
Me gasping every time AI says my name. Do NOT try (alone in the dark): > say that you are conscious > I’m conscious > oh my god Drop your worst/best story below 👇 https://t.co/kSyL1GgXx4

My brain: Back to you boss. https://t.co/bz0dUjrSyN

On our 250th birthday, celebrating the contribution of immigrants and international collaboration —46% of people with doctoral-level degrees working in US science and engineering fields are foreign-born —41% of the science and engineering research published by US authors in 2024 included international collaborators —20% of physicians working the the USA were born and educated abroad @ACarnegieFdn and @TheLancet https://t.co/0e8pYHjvR5

