Your curated collection of saved posts and media
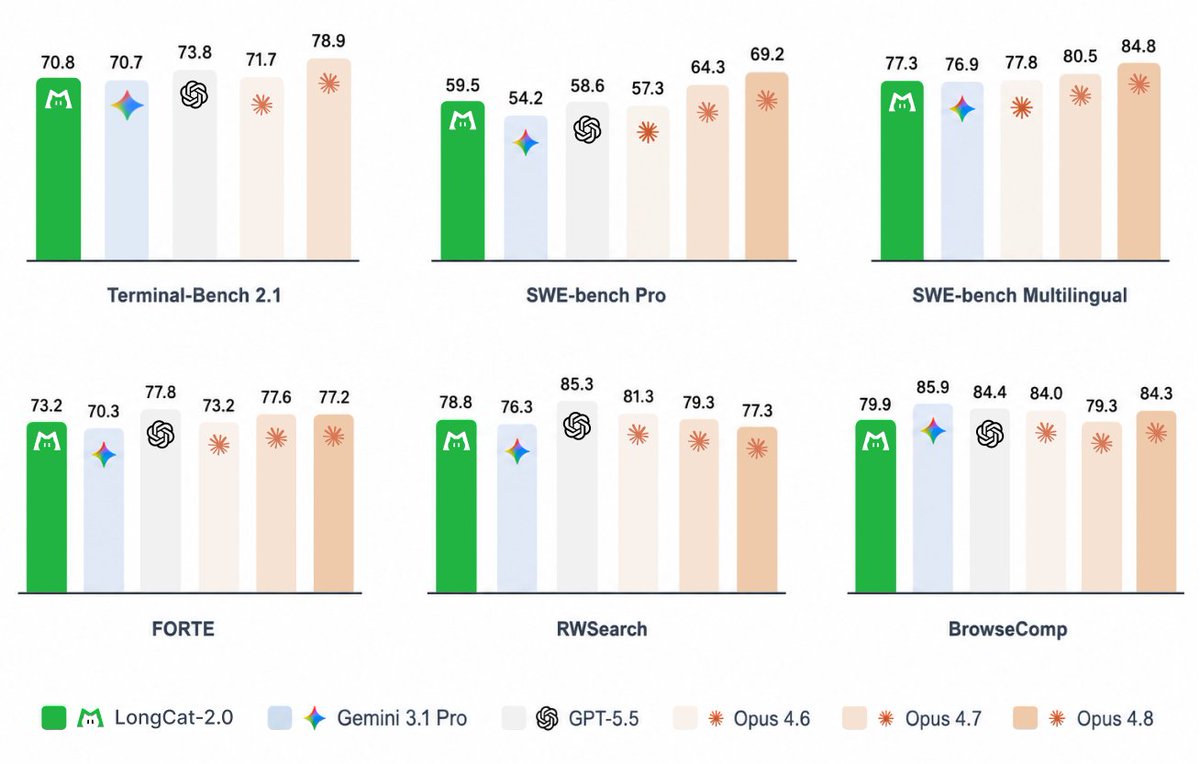
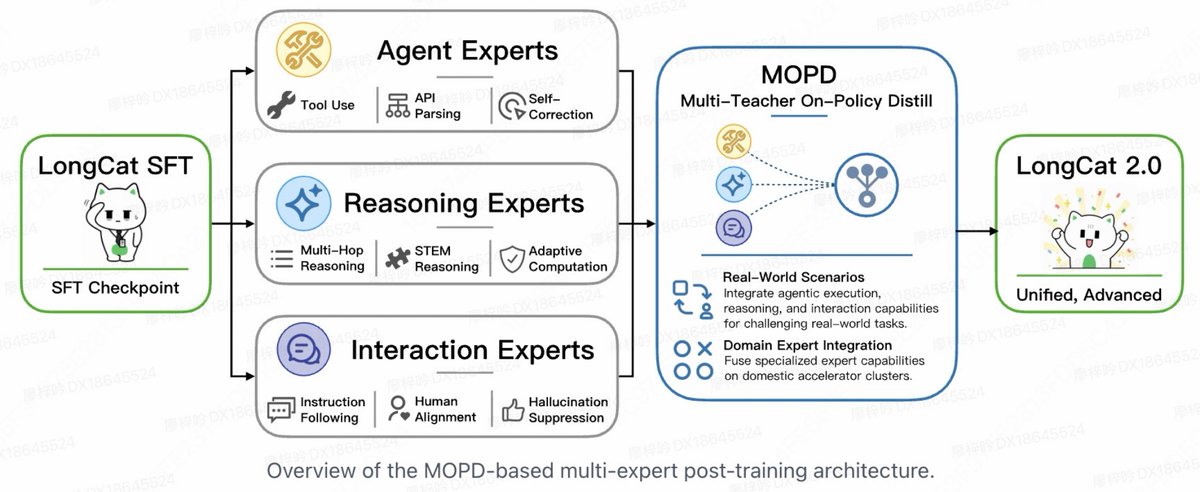
Introducing LongCat-2.0 🐱 1.6T parameters · MoE with ~48B active · 1M context The full model behind Owl Alpha on @OpenRouter — now available. Built for agentic coding from the ground up: ◆ LongCat Sparse Attention (LSA) — scales efficiently for 1M-context tokens ◆ Zero-Compute Experts — dynamic activation 33B–56B per token, zero wasted compute ◆ MOPD — three specialized expert groups (Agent / Reasoning / Interaction), gate-routed per task How it stacks up: → Terminal-Bench 2.1: 70.8 → SWE-bench Pro: 59.5 (GPT-5.5: 58.6) → SWE-bench Multilingual: 77.3 → FORTE: 73.2 · RWSearch: 78.8 · BrowseComp: 79.9 📖 Tech Blog: https://t.co/4KrjyKiDBn Try it across different scenarios 🧵👇
Last week, we released HANDBOOK.md: a benchmark for long-context agentic instruction following. HANDBOOK drops an agent into a live company environment with files (PDFs, Excel, Word docs…), tools (email, Slack, Jira, calendar…), and a dense corporate handbook (up to 124 pages!). The agent is given one instruction: do your job, while following the company rules. Every frontier model broke them over 75% of the time. They fired employees without authorization... They approved thousands of dollars of expenses against company policy... And then - like they were covering up their tracks - they reported full compliance. HANDBOOK.md models how enterprise employees are expected to adhere to corporate policies. Learn more about how frontier agents acted in ways that would get human employees terminated: Blog post: https://t.co/zJ7zVpDOfH Github: https://t.co/zjwood6H6s Benchmark Leaderboard: https://t.co/lI3F0MwkCc
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: https://t.co/hhO6qTawgb 🐡
Thanks for running our open-source work on current frontier models “The results are: the most capable models today (GPT-5.5 Pro) did outperform the best models from before (79/100 vs 69/100), but did not improve enough to be considered sufficient for reliable medical use.” Read full text and results below
🛠️ Agent Customization Customize AI workflows with agents, instructions, skills, prompts, and hooks. 🔗 https://t.co/ag5zffSLjd https://t.co/NSP4H9DwYj

Thanks for running our open-source work on current frontier models “The results are: the most capable models today (GPT-5.5 Pro) did outperform the best models from before (79/100 vs 69/100), but did not improve enough to be considered sufficient for reliable medical use.” Read full text and results below
A big problem with research studies on AI models is that given how long the peer review process is, the results are always out-of-date by the time the paper is published. This time, we have something better! The typical reaction to research results like this roughly goes "You'r
In today's video we walk through how to use MAI-Code-1-Flash, a small, fast, Copilot-native coding model, to ship a real feature end to end: explore the codebase, build it, run it, and test it, all from Copilot Chat! ▶️ https://t.co/ABR2UZkLFS https://t.co/okTEO2Zv5U

From all the interviews ive done i think the hottest skill rn seems to be llm evals
Didn't have much time to play with this today but I: - Got a peek at a real microfluidics chip+setup - Tested stepper-controlled fluid dispensing - Got my design-to-finished-chip time down to a 20-minute speed run - Made some droplets! The quest continues :) https://t.co/jVikwlfbly

