@Meituan_LongCat
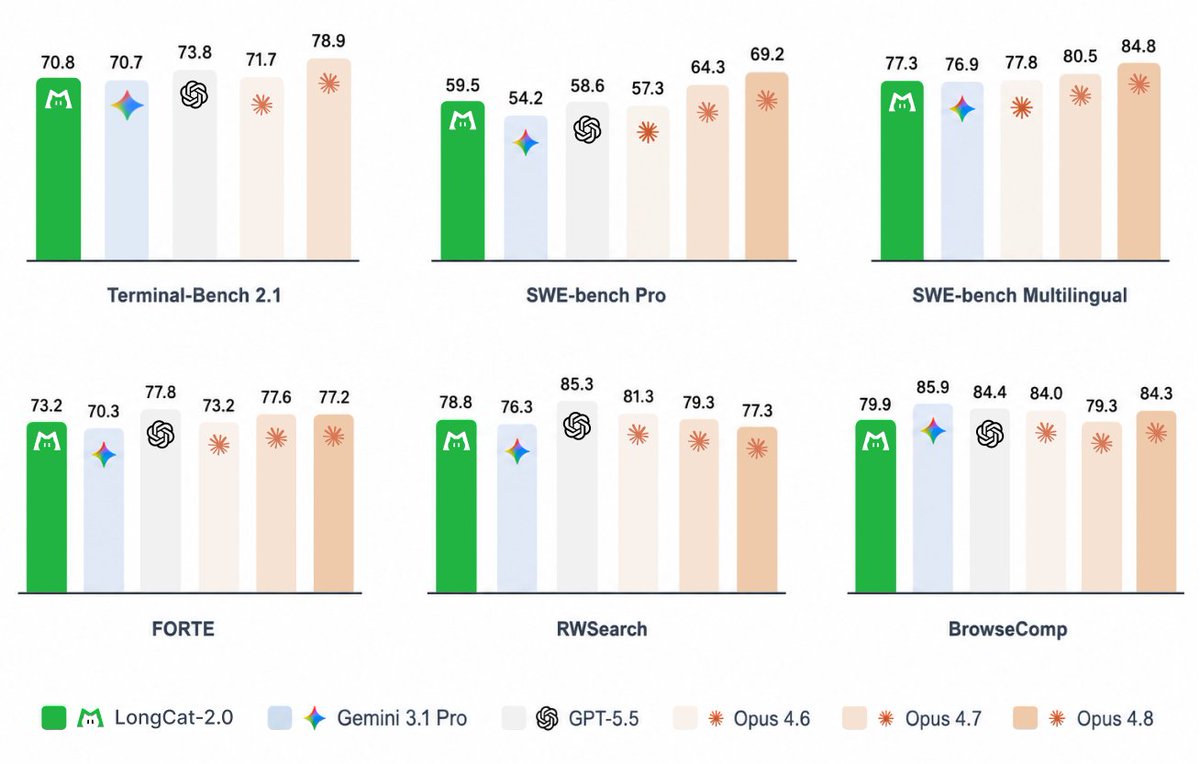
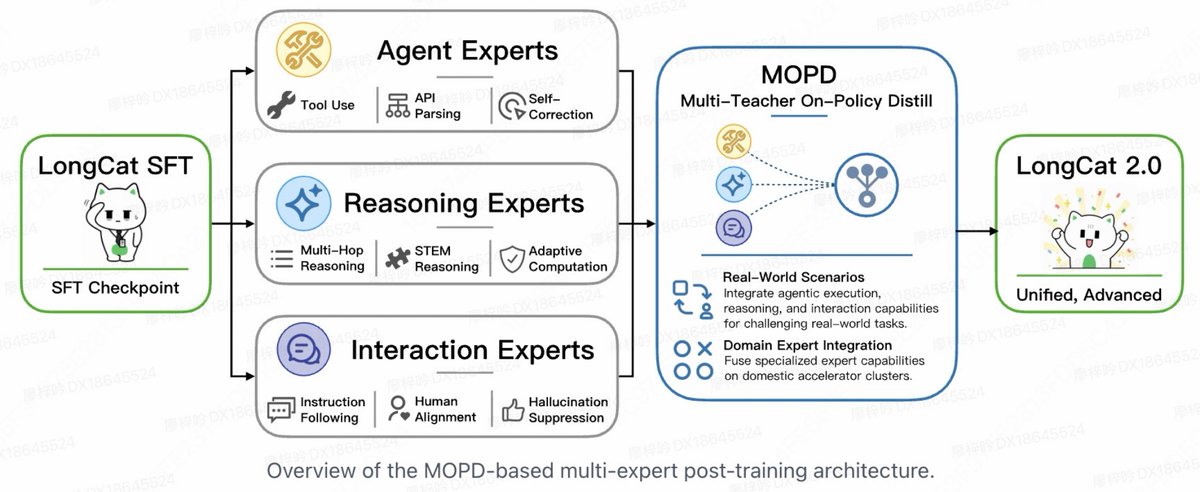
Introducing LongCat-2.0 🐱 1.6T parameters · MoE with ~48B active · 1M context The full model behind Owl Alpha on @OpenRouter — now available. Built for agentic coding from the ground up: ◆ LongCat Sparse Attention (LSA) — scales efficiently for 1M-context tokens ◆ Zero-Compute Experts — dynamic activation 33B–56B per token, zero wasted compute ◆ MOPD — three specialized expert groups (Agent / Reasoning / Interaction), gate-routed per task How it stacks up: → Terminal-Bench 2.1: 70.8 → SWE-bench Pro: 59.5 (GPT-5.5: 58.6) → SWE-bench Multilingual: 77.3 → FORTE: 73.2 · RWSearch: 78.8 · BrowseComp: 79.9 📖 Tech Blog: https://t.co/4KrjyKiDBn Try it across different scenarios 🧵👇