Your curated collection of saved posts and media
Original paper: https://t.co/oka6G5cnMB Refutations already in the literature: Gong et al. (2026) showed Patchscopes are unreliable: injected states overridden by model priors (faithfulness drops sharply). The “layer 6 belief” is just a partial vector sum the rest of the pass overwrites. https://t.co/Z2Dxtvgmnt The architecture is unchanged. The interpretive frame drifted. Time to review the math. Apply null hypotheses thoroughly. Leave anthropomorphic narratives behind for good.
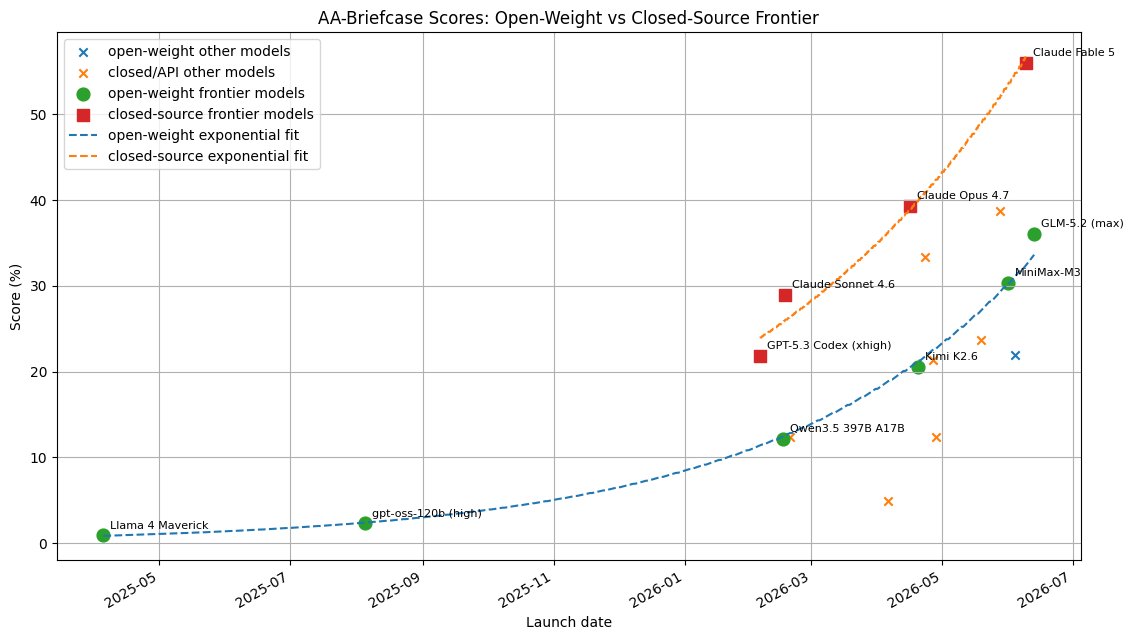
I took the new AA-Briefcase scores from @ArtificialAnlys (basically having the AI do multi-week consulting gigs with a lot of complexity) and graphed the frontier curve for open and closed models: 1) Surprise, rapid gains! 2) The open weights gap is clear https://t.co/a1QGQC2hey https://t.co/bqJHA0WU0j

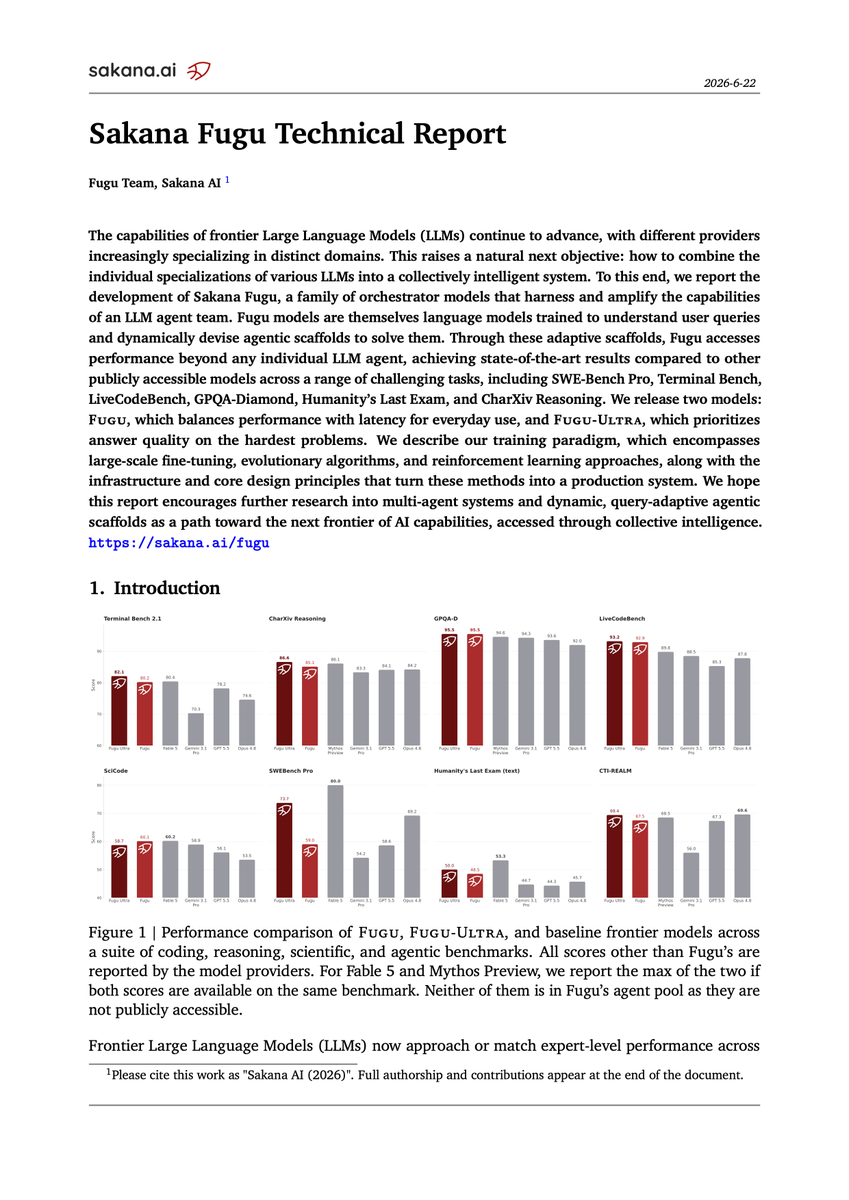
Sakana Fugu Technical Report https://t.co/6e6WuA8FVB Release Notes: https://t.co/7xWGpOicFN https://t.co/g2yaZvex35
📣📣 Meet Qwen-AgentWorld — a native language world model that simulates 7 agent environments (MCP, Search, Terminal, SWE, Web, OS, Android) within a single model. Environment modeling is the training objective from day one, not a post-hoc adaptation. 🤔 LLMs are trained to be better agents — better at acting in environments. But nobody has trained them to model the environments themselves. 🗺️ Our roadmap: investigate how language world modeling can push the boundaries of general agent capabilities, along two routes: 1️⃣ Build a foundation model for environment simulation — outperforming Claude Opus 4.8 and GPT-5.4 on AgentWorldBench 2️⃣ Investigate how world modeling enhances agent training: 🔬 Controllable Sim RL (agentic RL with LWM as environments) surpasses training in real environments 🧠 Learning to predict environments (LWM warm-up) makes agents stronger — remarkably, even without any agent-specific training, this predictive knowledge transfers to agentic tasks with zero fine-tuning 📑 Paper: https://t.co/Jx2l5RKq71 📖 Blog: https://t.co/7tVcKyhsx2 💻 GitHub: https://t.co/B5Lvb1UZCn 🤗 HuggingFace: https://t.co/Kw3QBL1TM5 🧩 ModelScope: https://t.co/YBnGYgMWWI
Oops, SIGReg did it again! Large scale (CC12M->Datacomp-L) vision-language JEPA pretraining beats CLIP and SigLIP objectives! Thanks to SIGReg, our LeVLJEPA has no collapse, no EMA, no stop-gradient, no negatives, no problem! Checkpoints/demo are live: https://t.co/wz6S6tYB6p
AI Infra Day | SGLang × Sarvam with Hugging Face India's AI infra community is coming together. A day of deep-dives and technical discussions with researchers and engineers building the future of AI infrastructure. Bangalore | 11th July | 12:00–4:00PM Register Now: https://t.co/StSC0dxac9

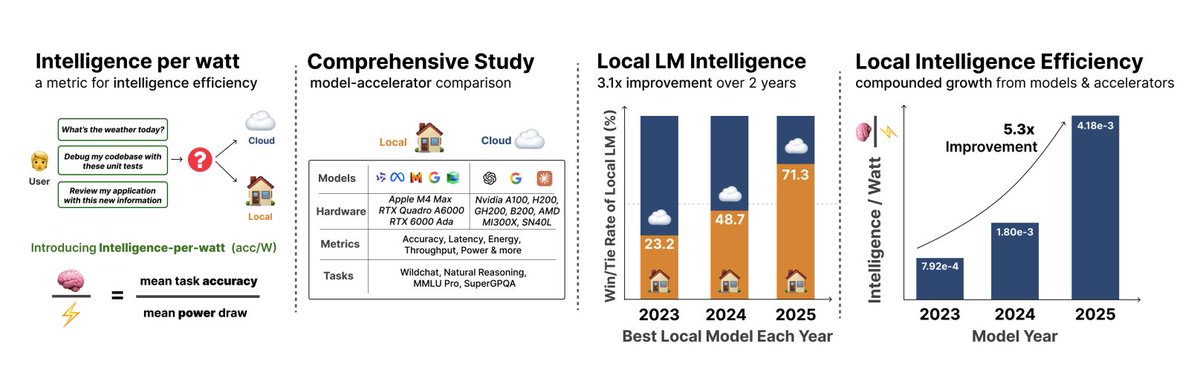
the wildest part of this intelligence per watt paper (71.3% of chat queries could be local) is that the model is only a gpt-oss 20b. which is about a year old! compared to the current batch of small moe models (gemma 4, liquid LFM, Qwen-3.6, etc.) this is nothing. https://t.co/d4Oem5d35t
The Sensorimotor World Model (https://t.co/K5iWbk7Izs): a deep dive into the role of inverse dynamics modeling as an anti-collapse regularization for JEPAs. IDM is weaker than SIGReg as it doesn't have to fill the space--it only captures what is affected by the agent's actions🧵 https://t.co/kdnVGbhkht
We taught a brand-new mini-series this year at @SCSatCMU on Modern GPU Programming for ML Systems, as part of the ML Systems course, touching on fun questions like what data layout swizzling is, how to use 3D TMA, and state-of-the-art Blackwell programming. We released a curated online book based on the materials: https://t.co/5ZJg2lySNO check it out
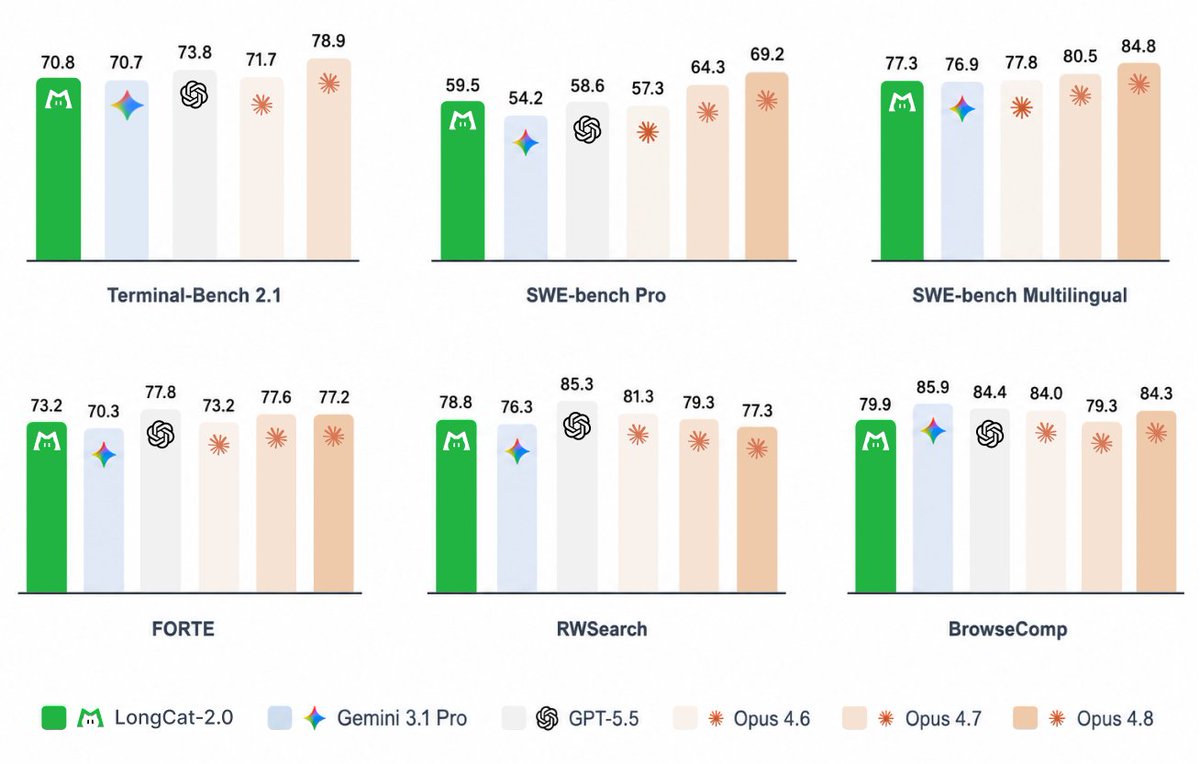
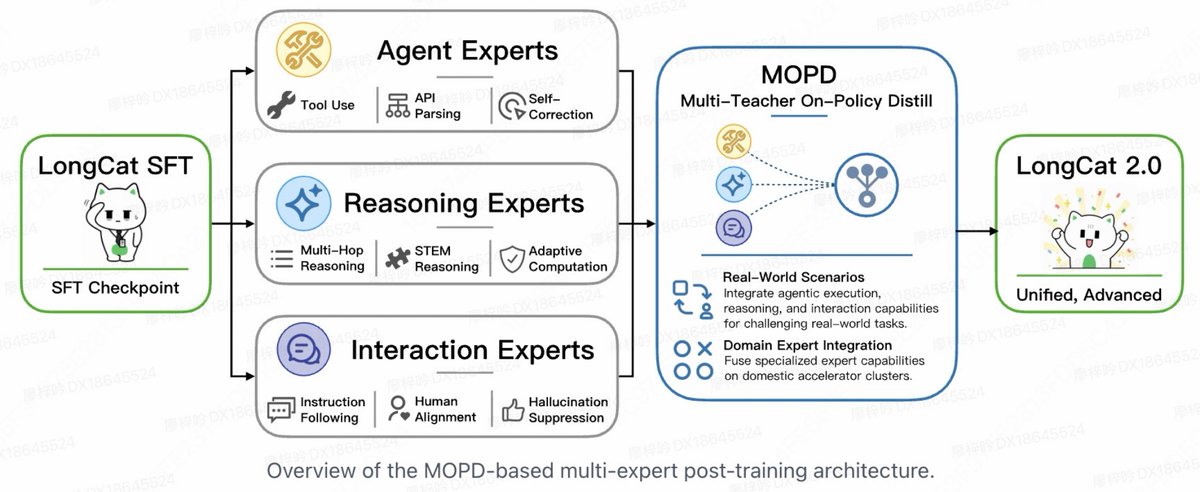
Introducing LongCat-2.0 🐱 1.6T parameters · MoE with ~48B active · 1M context The full model behind Owl Alpha on @OpenRouter — now available. Built for agentic coding from the ground up: ◆ LongCat Sparse Attention (LSA) — scales efficiently for 1M-context tokens ◆ Zero-Compute Experts — dynamic activation 33B–56B per token, zero wasted compute ◆ MOPD — three specialized expert groups (Agent / Reasoning / Interaction), gate-routed per task How it stacks up: → Terminal-Bench 2.1: 70.8 → SWE-bench Pro: 59.5 (GPT-5.5: 58.6) → SWE-bench Multilingual: 77.3 → FORTE: 73.2 · RWSearch: 78.8 · BrowseComp: 79.9 📖 Tech Blog: https://t.co/4KrjyKiDBn Try it across different scenarios 🧵👇