Your curated collection of saved posts and media
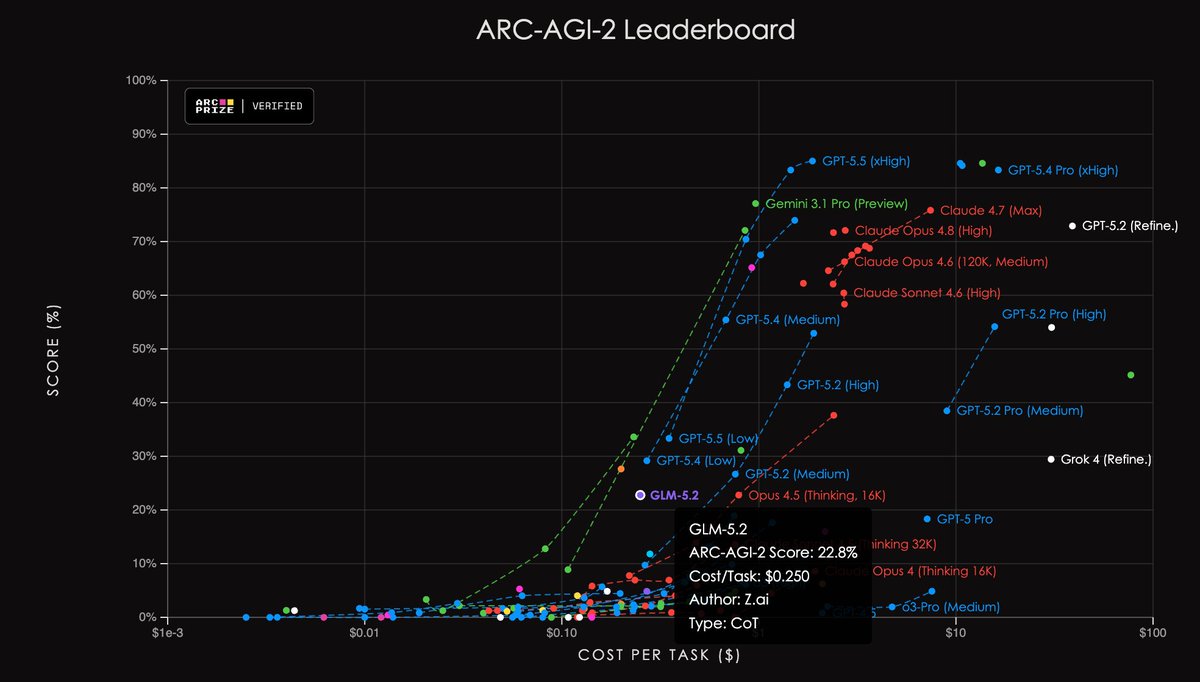
GLM-5.2 from @Zai_org on ARC-AGI (Verified) - ARC-AGI-2: 22.8%, $0.25 - ARC-AGI-1: 77.0%, $0.19 Performance is comparable with GPT-5.4 & 5.5 (Low Reasoning Effort) https://t.co/beYeeTpQJR
To handle discrete metadata with high cardinality (lots of categories), FINO uses a momentum-updated prototype bank for discrete factors. The loss used is a contrastive loss, inspired by supervised contrastive learning. For continuous metadata, the loss just regresses a small predictor head against the metadata target. Of course, no metadata is needed at inference, it is only used to guide learning.

🚀 Meet PRX Pixel. Our new open-source 7B text-to-image model that generates images directly in pixel space. After months of pretraining on hundreds of millions of images, supervised fine-tuning, and preference alignment, we're excited to share a first public preview. The weights are already available, and we're currently working on integrating the model directly into Diffusers 🤗to make the model even easier to use. Test it yourself in the demo below. And as always, we'll be sharing the full story behind the model through a series of technical blog posts covering the entire training recipe. Link in the comments 👇

Excited to share Ornith, our latest family of open-source models specialized for agentic coding. Ornith achieves SOTA performance among open-source models of comparable size on a variety of coding benchmarks (Terminal-Bench 2.1, SWE, NL2Repo, OpenClaw, SWE Atlas, etc) Feedback is deeply appreciated! 📖Tech Blog: https://t.co/MiaaDExj9B 🤗Huggingface: https://t.co/eDtzanc5Vp
Aloha! 🌺 Meet Ornith-1.0, a family of open-source LLMs specialized for agentic coding. Ornith-1.0 spans the full parameter sizes including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. It achieves state-of-the-art performance among open-source models of comparable size on coding

Introducing Cursor for iOS. Build from anywhere by launching always-on cloud agents. Or remotely control agents running on your computer from the app. Composer 2.5 is 75% off in the app now through July 5. https://t.co/dFxQyrgmBb
If your benchmark relies on a static dataset or sampling from a static distribution densely known at training time, then it is fundamentally measuring memorization/retrieval. Which might be fine if you're looking for a retrieval benchmark! But don't confuse it with intelligence.
Huge milestone from the @anyscalecompute + @googlecloud GKE teams 🎊 Ray Serve LLM provides up to 4.4x higher throughput on prefill-heavy workloads and 24x on decode-heavy workloads than previous versions. Three optimizations made this possible on the Ray Serve LLM + vLLM stack: ⭐️Direct streaming with a control-plane-only endpoint picker ⭐️ A new vLLM Ray V2 executor backend ⭐️HAProxy ingress for routing at the speed of C Ray's primitives for fault tolerance, observability, and portability across K8s and VMs are a great foundation as inference deployments get more complex. Congrats to the team! Try the new Ray V2 executor today in vLLM with --distributed-executor-backend ray.
Today we are excited to announce, in partnership with the GKE team at Google Cloud (@googlecloud), a major milestone in Ray Serve LLM’s production serving capability. Ray Serve LLM now matches high performance, rust-based routing frameworks such as vllm-router (@vllm_project) in
Semantic search alone doesn't cut it. Neither does brute-force grep. Agents need both. Today we're shipping the Retrieval Harness in LlamaParse Index: semantic search, server-side grep, and file-level navigation working together in a single agent reasoning loop. 🦙🌤️ Grep a file, list what's in an index, read past a chunk boundary, run hybrid search with reranking — all as native agent tools. Now in beta across all paid tiers. Full breakdown in the blog 👇 Learn More: https://t.co/q86Lu6tdOI
Here is the reference doc with an example of using Claude Code with Hugging Face Inference Providers: https://t.co/fm548KNdLD

Notice that Sonnet 5 scores worse than Opus 4.8 on every single benchmark (except GDPval, on which it's 3 points higher - nothing material). This is in line with my suspicion that we have an unofficial moratorium on frontier model releases in the U.S. until the Fable 5/GPT-5.6 situation is resolved.
Sonnet 5 is a substantial improvement over Sonnet 4.6 on reasoning, tool use, coding, and knowledge work. Its performance is close to Opus 4.8, at lower prices. https://t.co/VOISbk14Lk