@Bayang_BM
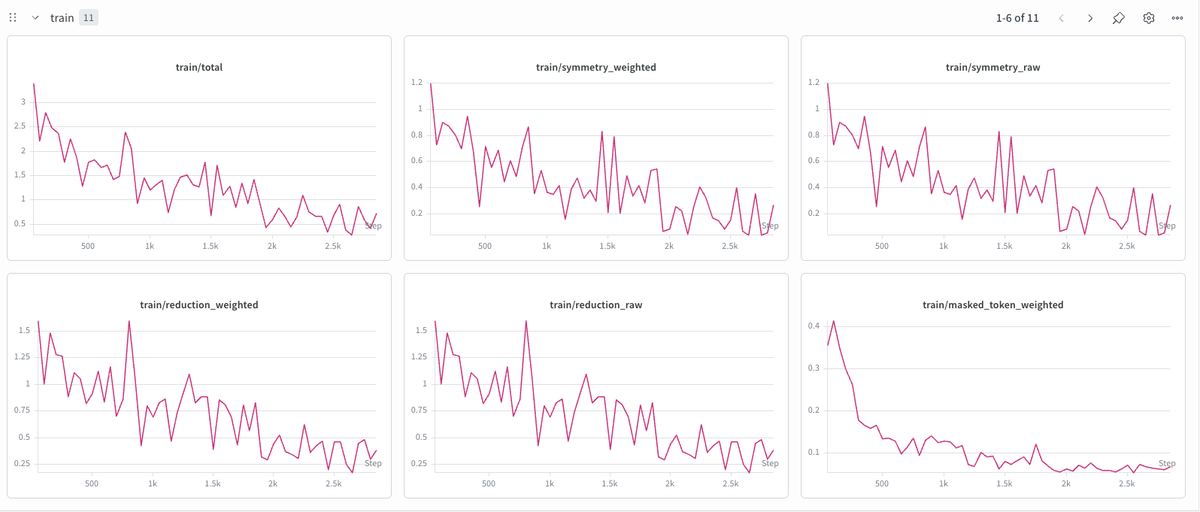
Now the masked_token_weighted is learning. We ablated the inpainting task, swapped MSE for SmoothL1Loss (more robust to outliers), and per-dim normalized the reconstruction targets, significantly reducing curvature-dim dominance. ref: https://t.co/FL5X61xpbQ https://t.co/0j03IXFXR2