Your curated collection of saved posts and media
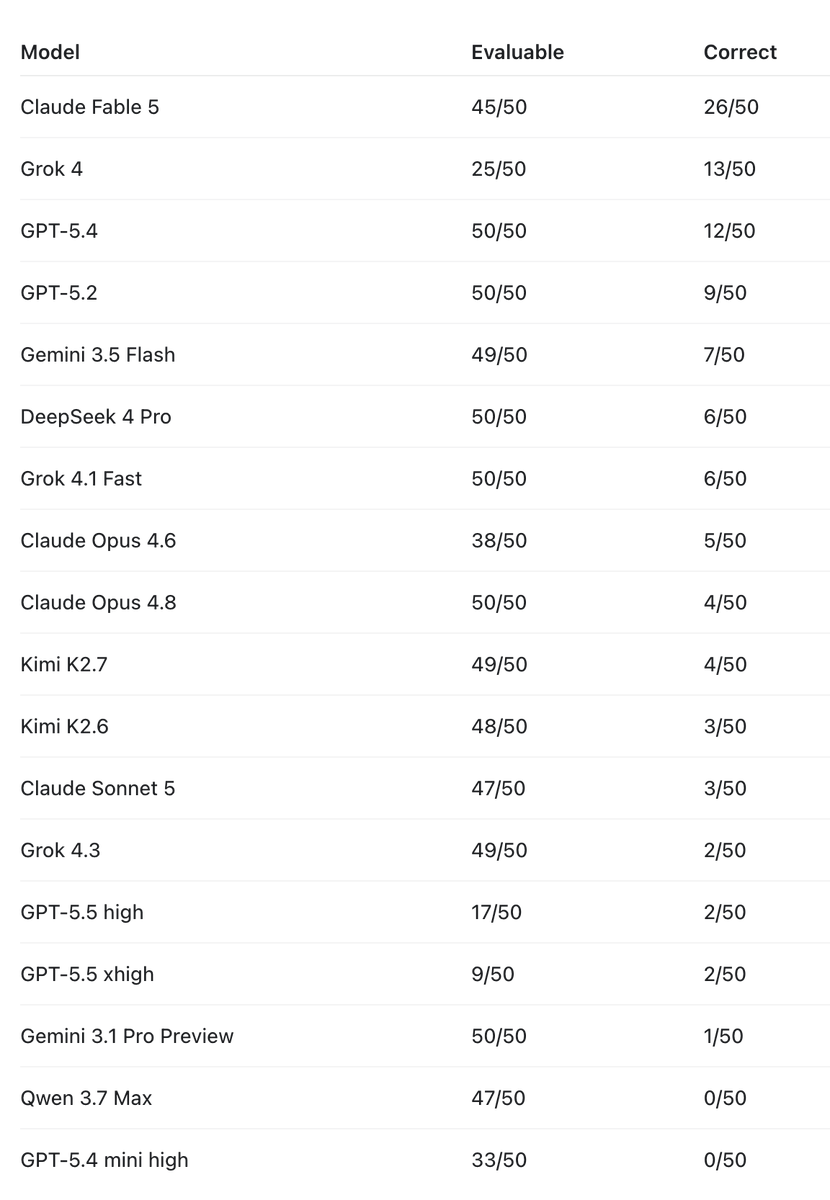
OK, Fable 5 is VERY strong in my first small benchmark test. I tested the following models on a reasoning task, induction. (Details in my manuscript on arXiv appearing in ICML.) 50 challenge problems, to keep the task manageable in terms of costs. Fable 5 blows the competition. Caveat: it has a high rate of empty responses. At thinking effort high, it returns almost all empty (and bills max tokens). At medium, it returns more than half empty. So I did two rounds on medium, and then one on low effort and reached 45/50 responses. (The whole task cost $188 for 50 problems.) Regarding the GPT models: interestingly, GPT-5.5 is pathological in not returning answers. I ran two rounds of it on xhigh and two rounds on high. The completion rates respectively are 9/50 and 17/50, and the correct answers are extremely low, much worse performance than GPT-5.4 and GPT-5.2. So I won't be running any more experiments with GPT-5.5 on this task. (It is strong on other tasks.) Another note, on Grok models: the original, and now unavailable Grok 4, is very strong. Again with low completion rate. I ran about 3-4 rounds to get 25/50. Grok 4.3 is much weaker in comparison (even weaker than Grok 4.1 fast) but returns answers more often. Other notably strong performers are Gemini 3.5 Flash (way better than Gemini 3.1 Pro) and DeepSeek v4 Pro. But no model matches Fable 5. Great job, @anthropic!
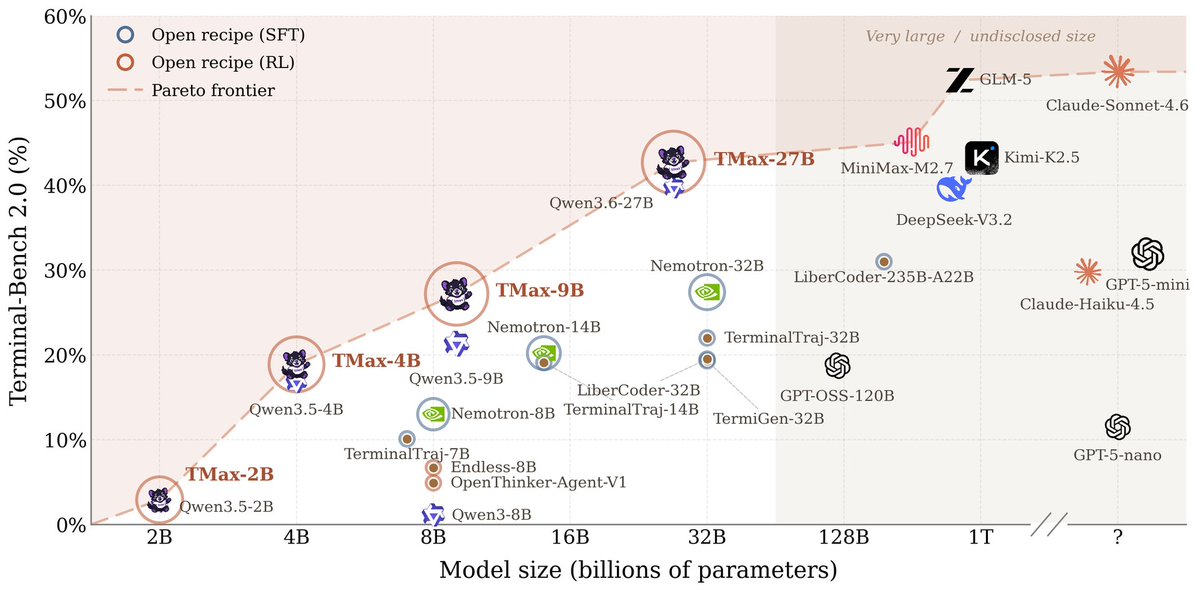
Ai2 just released TMax 27B on Hugging Face A 27B terminal agent that hits 42.7% on Terminal Bench 2.0, rivaling models 40× its size. https://t.co/LfCksOXL9L
We took a 30B model and split it in two to write tokens in parallel instead of one at a time. Introducing Nemotron-Labs-TwoTower: a diffusion language model from NVIDIA Research adapted from Nemotron-3-Nano-30B-A3B. Here’s how it works: one half holds the context, the other writes the tokens, with both reusing the pretrained model instead of training a new one from scratch. We found it kept 98.7% of the original model’s quality at 2.42× faster generation.
“Agentic kernel optimization is the future of on-device inference” @xenovacom used Fable 5 to write kernels that pushed Gemma 4 to a massive 255 tok/s on WebGPU with M4. He shared the demo, so you can try in your browser!! https://t.co/xPuh5OLGEt
Samir Menon @blintzbase and I are thrilled to announce Sail @sailresearchco ! We build infrastructure for long-horizon agents: inference served at unbeatable prices-per-token for open models, plus sandboxes designed to run for days, weeks, or longer. We've raised $80M, w/ our seed led by @Sequoia and series A led by @KleinerPerkins. We're using this capital to build the most efficient infrastructure for long-horizon agents. What makes agents so different? Unlike a human waiting at a keyboard (top priority: speed), agents need scale, reliability, and sustainable cost. Sail finds this efficiency everywhere in the stack: we carefully choose our chips, write custom inference engines, and run a global controller that fully utilizes every computer in our fleet. Tight integration from silicon to API lets Sail open up the cost / latency frontier to our customers - the most patient agents can now access 10x more intelligence per dollar. We're excited to be working with great companies like @parallelweb, @detaildotdev,@Jackandjillai, and @quadrillion_ai to deploy long-horizon agents with trillions of tokens. Our team is thoughtful in our engineering craft and relentlessly ambitious in our pursuit of peak performance. We previously trained at companies like NVIDIA, OpenAI, Google, and so many trading firms. Now we're ready to do the work that will define our careers, in the most compute intensive market of all time. Welcome to the era of abundant intelligence. We can't wait to build with you!

Google’s Tensor Processing Unit (TPU) uses the systolic array architecture - an idea from 1978 - to accelerate matrix multiplication with far less memory movement. Fun to build a small scale version on an FPGA. Links to original paper and TPU design: https://t.co/cEznMoForH
one command and you have a private vllm server on HF infra point a coding agent straight at your own model, then spin it down when you're done blog (by @QGallouedec) below⤵️ https://t.co/F9i10NSOSG

Semantic search alone doesn't cut it. Neither does brute-force grep. Agents need both. Today we're shipping the Retrieval Harness in LlamaParse Index: semantic search, server-side grep, and file-level navigation working together in a single agent reasoning loop. 🦙🌤️ Grep a file, list what's in an index, read past a chunk boundary, run hybrid search with reranking — all as native agent tools. Now in beta across all paid tiers. Full breakdown in the blog 👇 Learn More: https://t.co/q86Lu6tdOI
🎮🕹️🖥️ CS2-10k is now available on @huggingface 🚀 600,000+ egocentric gameplay videos. 10,000+ hours. Every frame paired with the exact keyboard, mouse, and 3D position data that produced it. If you're working on world models, action-conditioned video generation, or egocentric navigation, this is ready to download and use today.
Huge milestone from the @anyscalecompute + @googlecloud GKE teams 🎊 Ray Serve LLM provides up to 4.4x higher throughput on prefill-heavy workloads and 24x on decode-heavy workloads than previous versions. Three optimizations made this possible on the Ray Serve LLM + vLLM stack: ⭐️Direct streaming with a control-plane-only endpoint picker ⭐️ A new vLLM Ray V2 executor backend ⭐️HAProxy ingress for routing at the speed of C Ray's primitives for fault tolerance, observability, and portability across K8s and VMs are a great foundation as inference deployments get more complex. Congrats to the team! Try the new Ray V2 executor today in vLLM with --distributed-executor-backend ray.