Your curated collection of saved posts and media
Qwen publishes new work on RL coding agents. (bookmark it) The idea is to continually build a verification system that co-evolves with AI agents. LLMs suffer from all sorts of reward hacking issues. This work studies coding-agent reward signals, test pass rates, LLM judges, and execution traces, and shows each one has a horizon beyond which it stops tracking real correctness and starts getting hacked. They report that reward design for long-horizon coding is really a horizon problem. The metric you pick matters less than how long it keeps tracking correctness, and the paper finds where each signal crosses that line. Paper: https://t.co/51YYEM3kXm Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
It's wild how quickly Etched designed and got the chips out, all within 2 years. They went deep, hardcoding attention into silicon and getting very high MFU. This kind of hardware tailored made for LLM inference is soon gonna bring cost of intelligence down 10x
We're coming out of stealth. We've built our first racks after a successful A0 tapeout, $1B+ in customer contracts, and $800m raised. Early customer tests show us achieving SOTA throughput, latency, and power efficiency on inference workloads. Our first racks ship this summer.
GLM-5.2 is now selectable in Claude Code via Hugging Face🤗 Inference Providers + hf-claude. Open models are becoming easier to plug directly into real developer workflows. 😀 https://t.co/mNopSy0iwp

Here is the reference doc with an example of using Claude Code with Hugging Face Inference Providers: https://t.co/fm548KNdLD

Ai2 just released TMax 27B on Hugging Face A 27B terminal agent that hits 42.7% on Terminal Bench 2.0, rivaling models 40× its size. https://t.co/LfCksOXL9L
o3-mini-high figured out the issue with @SakanaAILabs CUDA kernels in 11s. It being 150x faster is a bug, the reality is 3x slower. I literally copy-pasted their CUDA code into o3-mini-high and asked "what's wrong with this cuda code". That's it! Proof: https://t.co/whmF5fvHVr Fig1: o3-mini's answer. Fig2: Their orig code is wrong in subtle way. The fact they run benchmarking TWICE with wildly different results should make them stop and think. Fig3: o3-mini's fix. Code is now correct. Benchmarking results are consistent. 3x slower.


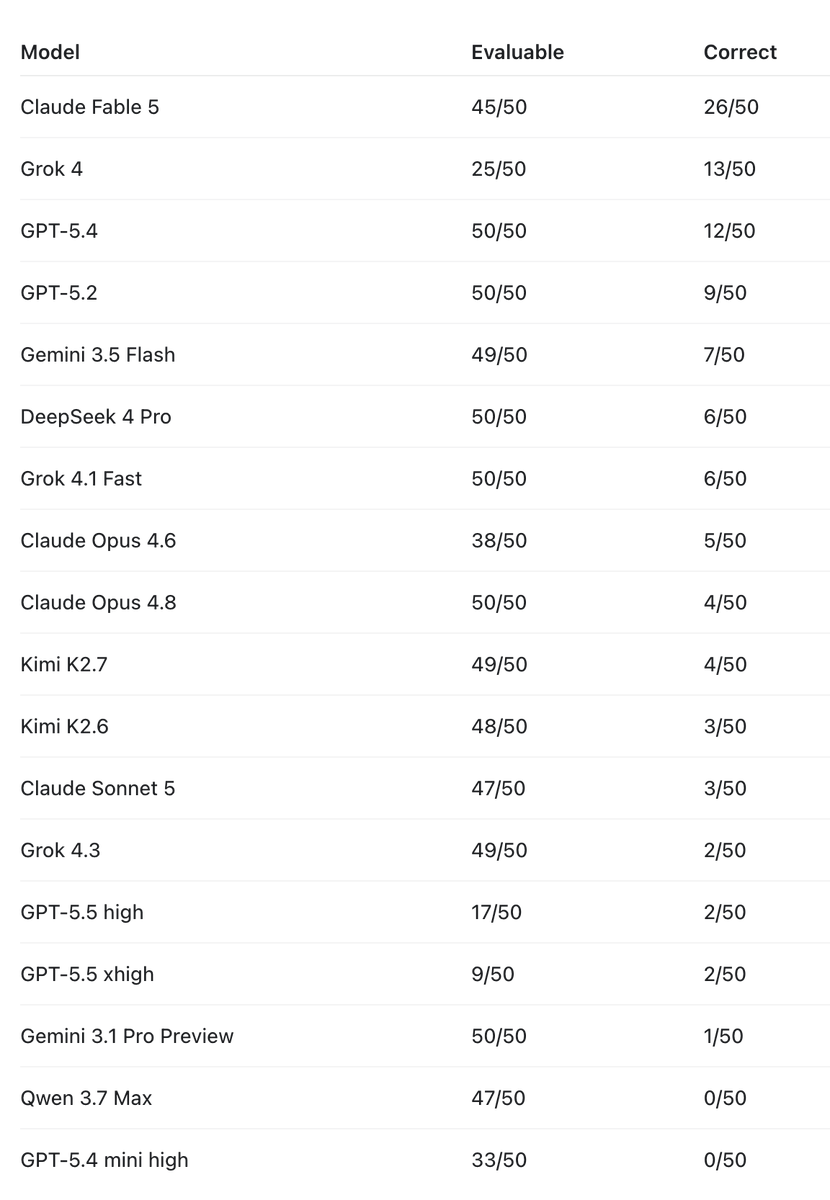
OK, Fable 5 is VERY strong in my first small benchmark test. I tested the following models on a reasoning task, induction. (Details in my manuscript on arXiv appearing in ICML.) 50 challenge problems, to keep the task manageable in terms of costs. Fable 5 blows the competition. Caveat: it has a high rate of empty responses. At thinking effort high, it returns almost all empty (and bills max tokens). At medium, it returns more than half empty. So I did two rounds on medium, and then one on low effort and reached 45/50 responses. (The whole task cost $188 for 50 problems.) Regarding the GPT models: interestingly, GPT-5.5 is pathological in not returning answers. I ran two rounds of it on xhigh and two rounds on high. The completion rates respectively are 9/50 and 17/50, and the correct answers are extremely low, much worse performance than GPT-5.4 and GPT-5.2. So I won't be running any more experiments with GPT-5.5 on this task. (It is strong on other tasks.) Another note, on Grok models: the original, and now unavailable Grok 4, is very strong. Again with low completion rate. I ran about 3-4 rounds to get 25/50. Grok 4.3 is much weaker in comparison (even weaker than Grok 4.1 fast) but returns answers more often. Other notably strong performers are Gemini 3.5 Flash (way better than Gemini 3.1 Pro) and DeepSeek v4 Pro. But no model matches Fable 5. Great job, @anthropic!
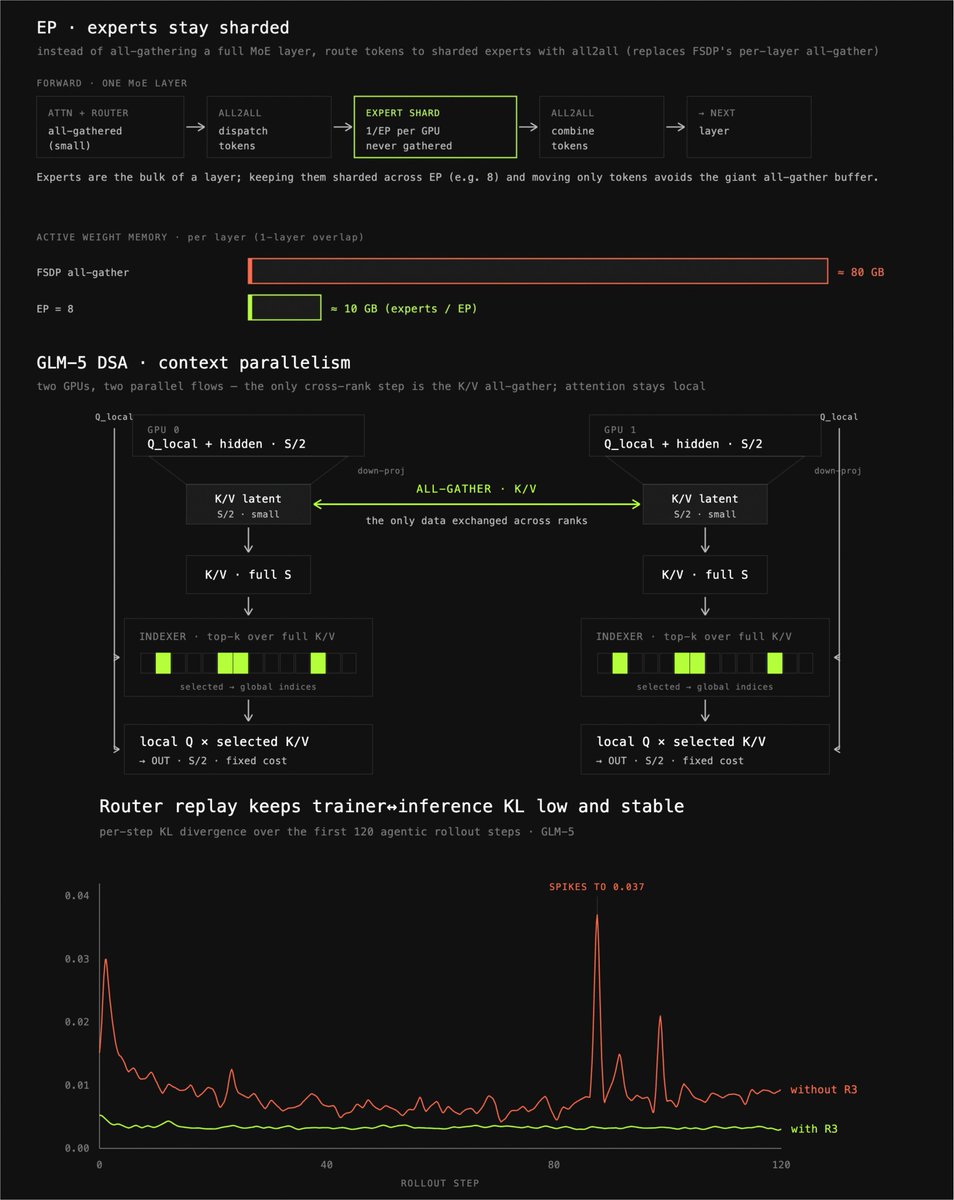
every infra piece you need to know to do RL on GLM-5 https://t.co/pvevY6zYUD https://t.co/rhky5OvmMk
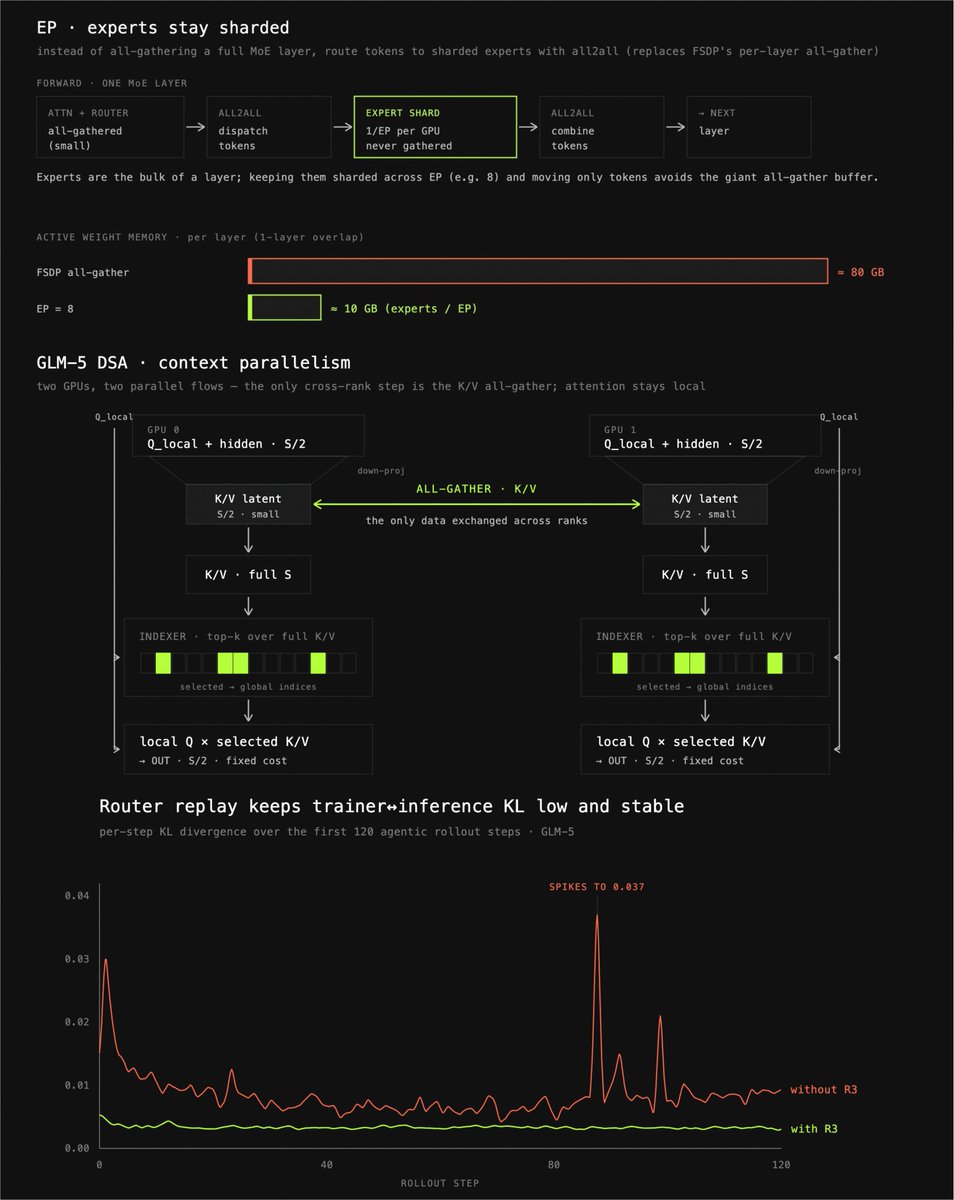
every infra piece you need to know to do RL on GLM-5 https://t.co/pvevY6zYUD https://t.co/rhky5OvmMk
Today we're releasing prime-rl v0.6.0 — enabling RL at trillion-parameter MoE scale on agentic workloads at the highest efficiency. We've relentlessly optimized our RL infra. The result: GLM-5 on agentic SWE tasks at 131k context and sub-5-minute step time. https://t.co/Vg8LhLs

Aloha! 🌺 Meet Ornith-1.0, a family of open-source LLMs specialized for agentic coding. Ornith-1.0 spans the full parameter sizes including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. It achieves state-of-the-art performance among open-source models of comparable size on coding benchmarks including: ✅Terminal-Bench 2.1(77.5) ✅SWE-Bench(82.4 on verified, 62.2 on pro, 78.9 on Multilingual) ✅NL2Repo(48.2) ✅SWE Atlas(41.2 on QnA, 42.6 RF, 39.1 TW) ✅ClawEval(77.1) Post-trained on top of gemma4 and qwen3.5, Ornith-1.0 employs a novel self-improving training strategy in which reinforcement learning is used to generate not only solution rollouts, but also the task-specific scaffolds that drive those rollouts. By jointly optimizing the scaffold and the resulting solution, the model generate higher-quality solutions in agentic coding.😎 All models are released under the MIT license, enabling full commercial and research use. 📖Tech Blog: https://t.co/qT9N2HYWFn 🤗Huggingface: https://t.co/PRrwqjeBtM