Your curated collection of saved posts and media
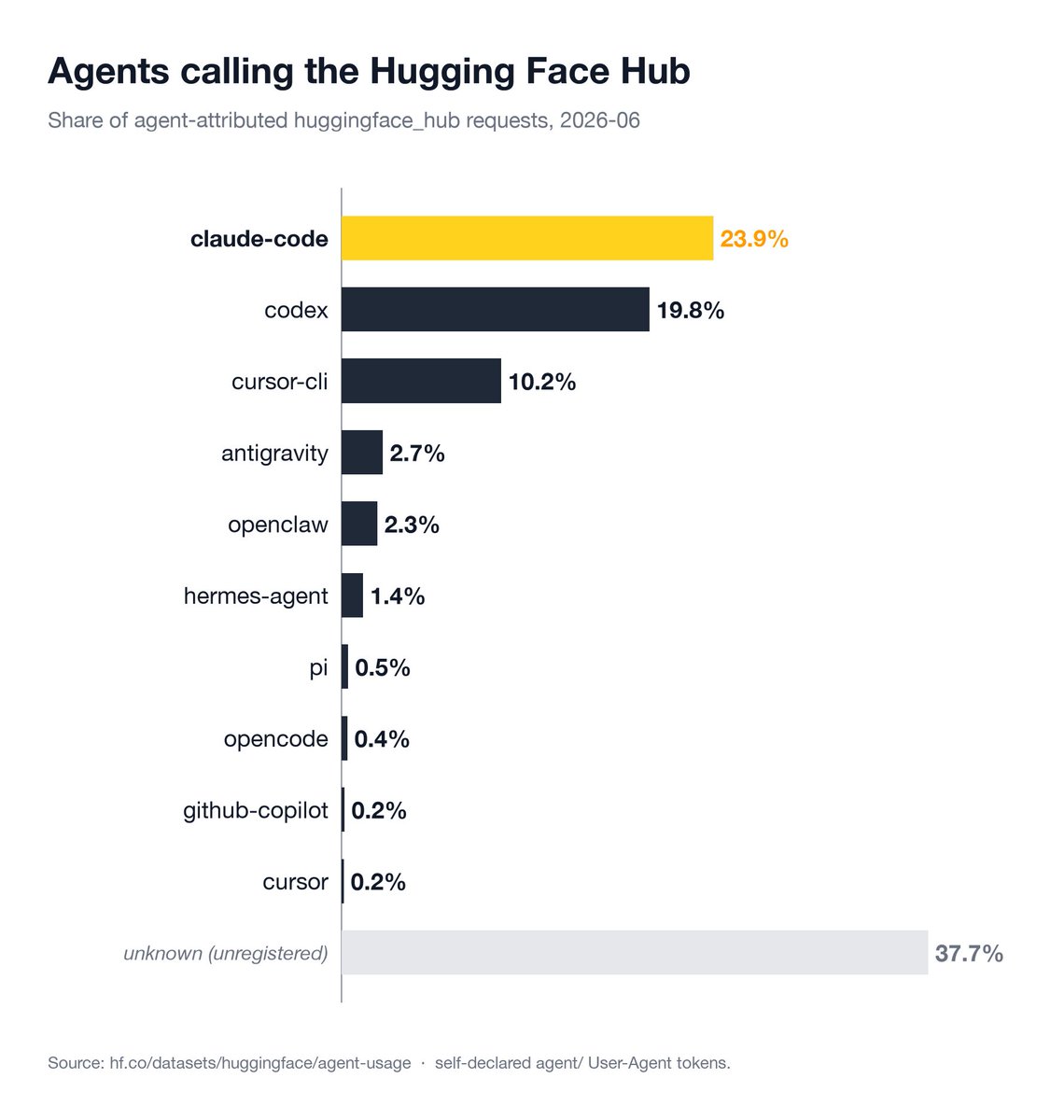
Coding agents are real users of the @huggingface Hub! They're searching for models, building and pushing datasets, training models on Jobs, spinning up Spaces... Now there's public data: each agent's share of Hub traffic, updated monthly 👇 https://t.co/ZpJDoXPPsq
Anthropic building its own inference chip makes sense. The AI race is becoming vertically integrated. A few years ago, the advantage came from having the best model. Today, your cost per token, latency, and compute supply increasingly determine whether that model becomes a business. That’s why frontier labs are moving down the stack. Models alone are no longer enough.
🚨BREAKING: ANTHROPIC COOKING ITS OWN AI INFERENCE CHIP In early talks with SAMSUNG for its 2nm process + advanced packaging Samsung already invested in Anthropic’s Series H btw https://t.co/KYPjR5AGJF
Early tickets cover variables, functions, types, operators, and control flow. Through increasingly complex tickets, you'll also learn Mojo's ownership and metaprogramming. Every problem runs your code through the Mojo compiler so you can learn from the authentic error messages.
Today's YouTube video is a longer look at MoA in Hermes Agent, trying to answer some of the common questions: How does using MoA impact cost, speed, and quality? I created an open weights MoA using GLM-5.2, Kimi K2.6 and Minimax M3 to find out, then made a three-headed Grok with GPT-5.5 as the aggregator to see if that added some much-needed style to the GPT model. Check it out! https://t.co/lQMfbuI1Ix
Nous Research just dropped MOA (Mixture of Agents) presets inside Hermes Agent. I made a quick video showing how to set it up and create your own MOA. The idea: mix multiple models to get capabilities beyond any single model you can use right now. How it works: Normally Hermes
before model distillation was an attack vector. it was. pretty handy way of improving model performance on a task you care about. especially if you want to take small, local, or cheap model and improve it on a tasks typically reserved to large models. in the next live stream, we're going to break down knowledge distillation in post-training and show you how to implement it. going out next week: July 7th 8am PST, 5pm CEST live on: @huggingface X, YT, LI

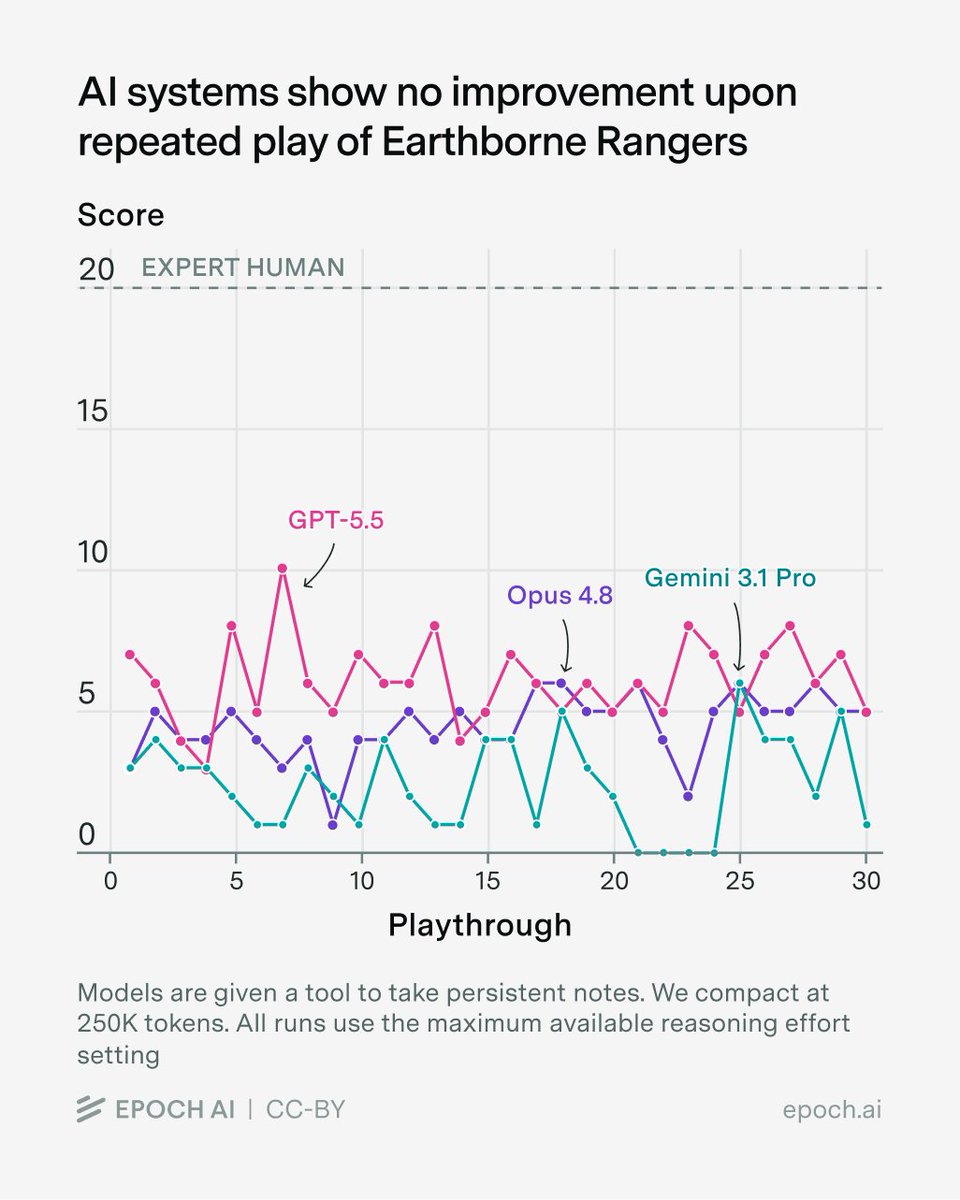
Introducing EBR-bench, our new benchmark to measure on-the-fly learning. AI repeatedly plays a challenging board game called Earthborne Rangers and tries to learn from its mistakes. So far: no signs of improvement. https://t.co/6R9wNHpnBu
@unixpickle Are you still playing with text-to-CAD? The last few times I've tried GPT 5.5 has made almost-useable (and easily salvageable) bits for me in OpenSCAD.
Didn't have much time to play with this today but I: - Got a peek at a real microfluidics chip+setup - Tested stepper-controlled fluid dispensing - Got my design-to-finished-chip time down to a 20-minute speed run - Made some droplets! The quest continues :) https://t.co/jVikwlfbly


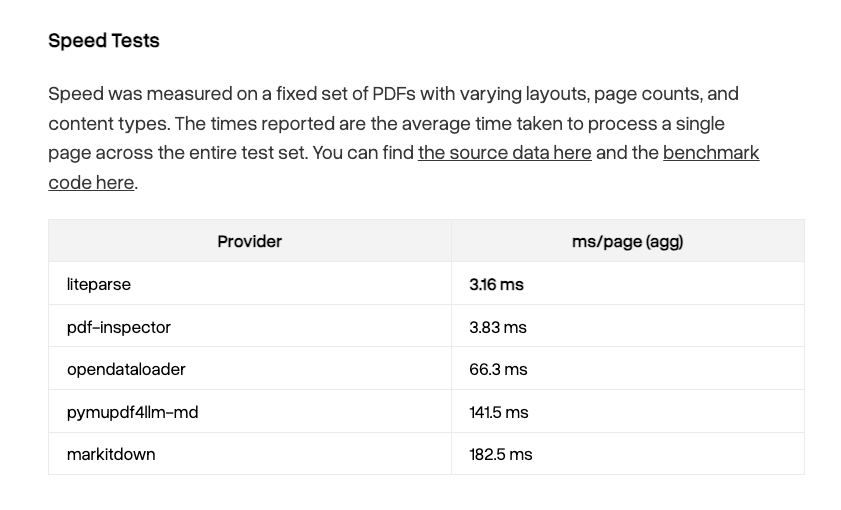
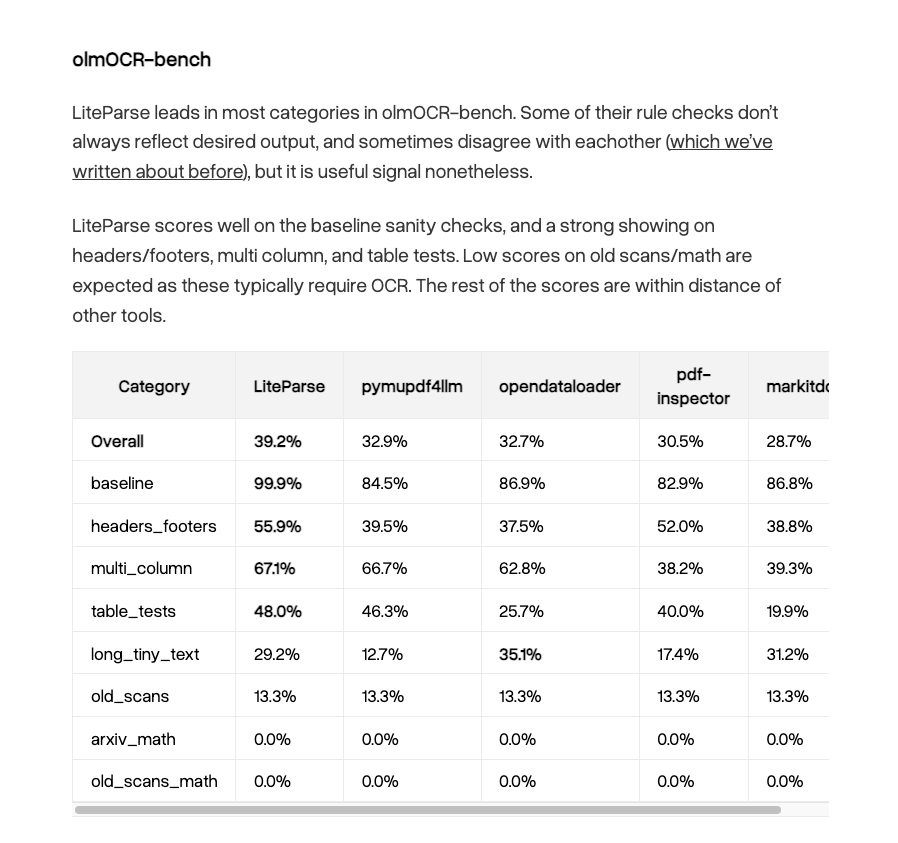
LiteParse is unreasonably good for document parsing ✅ It is the fastest document parsing tool out there - average parse time per page is 3ms ⚡️⚡️ ✅ Now that we support markdown, it tops opendataloader-bench, OlmOCR-bench, and ParseBench in terms of accuracy ✅ It supports 50+ other document formats ✅ It even gives you basic bounding boxes that your coding agent can stitch together Even if you need deeper VLM-enabled parsing (e.g. LlamaParse), there's no reason you shouldn't be using this as a first pass for everything. https://t.co/JNER0mVcB8
We built LiteParse, the fastest document parsing solution on the planet and made it open source. And it just hit 10k github stars. 🦙 Fast to run. Fast to love. Thanks for building with us. If you haven't tried it already, repo at: https://t.co/wXRxvlREQq https://t.co/Shv0J1CRO
3D scene reconstruction works great until the camera never sees part of the scene. ArtiFixer from NVIDIA Research is an open autoregressive model that fills in the missing geometry that other methods leave blank. #SIGGRAPH2026 paper, code + demo: https://t.co/D9PX2OzbZf https://t.co/AGQicvVKkW