Your curated collection of saved posts and media
Day 1 of vibecoding https://t.co/n8ff35htEV

@unixpickle Are you still playing with text-to-CAD? The last few times I've tried GPT 5.5 has made almost-useable (and easily salvageable) bits for me in OpenSCAD.
Didn't have much time to play with this today but I: - Got a peek at a real microfluidics chip+setup - Tested stepper-controlled fluid dispensing - Got my design-to-finished-chip time down to a 20-minute speed run - Made some droplets! The quest continues :) https://t.co/jVikwlfbly


The team at @vercel recently released the Eve agent framework, so we built a template that integrates LiteParse with it🦙 The template provides a set of read-only filesystem tools that let Eve resolve paths, list directories, and read text-based files. We then pair those with LiteParse, which parses files from their source and returns clean, structured Markdown⚙️ Finally, we equipped the agent with detailed instructions on when and how to combine these tools effectively, giving it a reliable workflow for navigating and understanding document collections out of the box📁 The result is a solid starting point that you can extend with your own channels, tools, and skills🔧 Check it out: https://t.co/CjuXouQ3E0
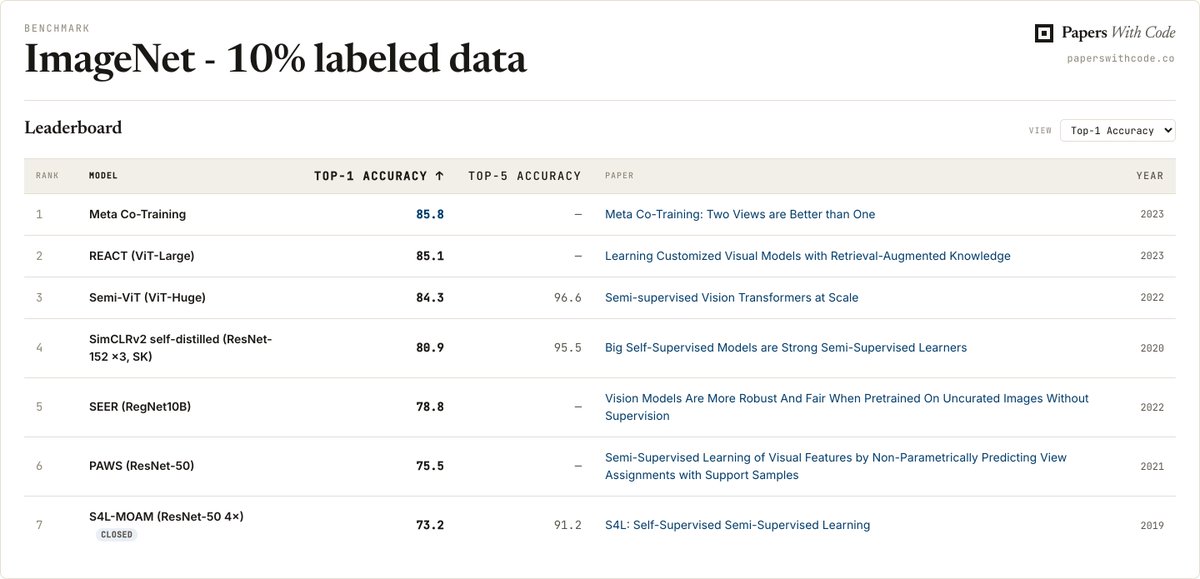
New benchmark added to Papers with Code based on @giffmana's Schmidhubering 🫡 Check the SOTA for semi-supervised ImageNet (using 10% of the labels) here https://t.co/CXd4lLkhlG https://t.co/sGi68AIoqh
LLM community slowly rediscovering what we in vision found out over half a decade ago. MY SCHMIDHUBER MOMENT IS COMING! Source: S4L paper where i tuned the most sota 10% and 1% ImageNet baselines ever, by far. https://t.co/Cj10TYvpOP https://t.co/c1yNYFEXHk

Thanks for running our open-source work on current frontier models “The results are: the most capable models today (GPT-5.5 Pro) did outperform the best models from before (79/100 vs 69/100), but did not improve enough to be considered sufficient for reliable medical use.” Read full text and results below
A big problem with research studies on AI models is that given how long the peer review process is, the results are always out-of-date by the time the paper is published. This time, we have something better! The typical reaction to research results like this roughly goes "You'r
LTX-2 trainer is a huge deal. I tried it to add water to the podracers scene using their demo water-sim fine-tune (it's a fine-tune whose only goal is to add water :D) I think we're going to see film productions that don't use general models. They'll train their own fine-tunes, built for exactly what they need and consistent between shots for long content.
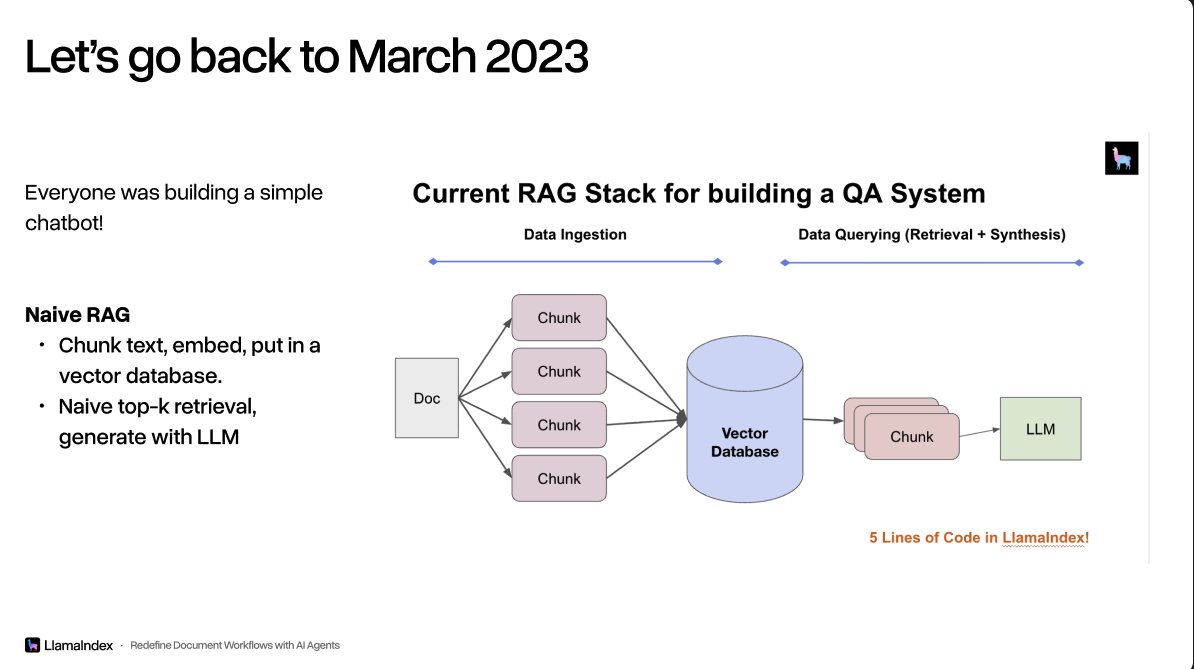
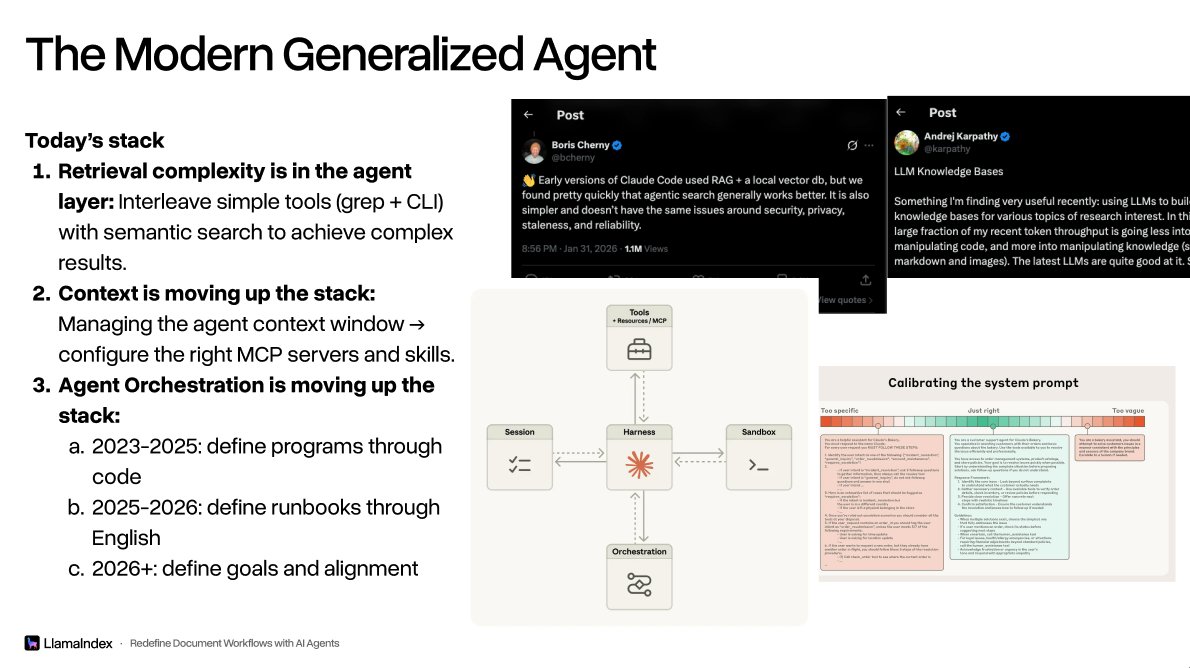
3 years ago I gave a talk at the first @aiDotEngineer conference on "Advanced RAG" techniques in order to work around the limitations of naive RAG. It's insane how much the world has changed since then, and the world has evolved into standardized, higher-level abstractions around agent harnesses and context. Some general patterns: 1. Retrieval complexity can be encoded at the agent layer. This means that you can give relatively simple but performant search tools to an agent (e.g. really fast bm25, vector search), and let the agent reasoning enter the right queries to find the right results. 2. To some extent this is still evolving, but I do think we will increasingly care less about "hacking" the context window and more about deciding what business context is relevant in the first place. 3. The way we build agents has fundamentally changed from defining code, to defining runbooks, to defining goals. Big congrats to @swyx and the entire AI Engineer team for continuing to put out awesome conferences every year.
Accepted to #ECCV2026! 🎉 We've also released the code, it should work like a charm. If it doesn't, feel free to poke @roodiiiiiiiii 😄 https://t.co/t5M0J7S1GR
Group3D MLLM-Driven Semantic Grouping for Open-Vocabulary 3D Object Detection paper: https://t.co/8NVynfAm2u https://t.co/RzkYdEKhRk
@salomon_diei The basic idea is easy and v0 is a hackathon project. The product here is a lot closer to *it actually works*, for enterprise grade deployments, and after quite a bit of internal experimentation and iteration. It’s kind of hard to describe other than (per the post) it’s writing majority of code, it’s deeply integrated, multiplayer, and it starts to feel like everyone is a manager. So I understand it looks easy to dismiss on quick reading but it’s not some LLM Q&A with RAG over Slack, it’s not even OpenClaw adjacent, it’s a different way of working entirely, for people and teams. I work from Slack now.