Your curated collection of saved posts and media
Huge milestone from the @anyscalecompute + @googlecloud GKE teams 🎊 Ray Serve LLM provides up to 4.4x higher throughput on prefill-heavy workloads and 24x on decode-heavy workloads than previous versions. Three optimizations made this possible on the Ray Serve LLM + vLLM stack: ⭐️Direct streaming with a control-plane-only endpoint picker ⭐️ A new vLLM Ray V2 executor backend ⭐️HAProxy ingress for routing at the speed of C Ray's primitives for fault tolerance, observability, and portability across K8s and VMs are a great foundation as inference deployments get more complex. Congrats to the team! Try the new Ray V2 executor today in vLLM with --distributed-executor-backend ray.
Today we are excited to announce, in partnership with the GKE team at Google Cloud (@googlecloud), a major milestone in Ray Serve LLM’s production serving capability. Ray Serve LLM now matches high performance, rust-based routing frameworks such as vllm-router (@vllm_project) in
Update on our long-horizon AI R&D evals: In April, we launched CRUX, a project to regularly run open-world evaluations. These long, messy, real-world tests of what AI agents can actually do. Our second evaluation is underway, and we ask: AI agents automate AI research? There is a lot of interest in studying AI research automation. But most of the systems built so far follow one of three patterns. 1) keep a human in the loop to guide the agent and course-correct along the way. 2) focus on narrow problems where ground truth is clear and progress is easy to verify, as in AutoResearch. 3) use scaffolds engineered for one specific type of research question, so strong results may say more about the scaffold than about the agent's general research ability. These efforts are helpful, but a lot of AI research is much broader. Success is not immediately clear or verifiable. Researchers need to test and reject promising hypotheses, backtrack, consider new or unconventional approaches, and do a lot more to make progress on answering research questions. In CRUX #2, we are trying to test whether agents can answer novel, open-ended AI research questions. - One major risk in such a task is contamination. We want the agent to have access to the internet and all the tools it needs to solve the task, so we can't use research questions from publicly available papers. At the same time, we want high quality papers to serve as the source of challenging research questions. - To address this, we partnered with AI researchers from UKAISI, UToronto, Princeton, and other institutions who have written high-quality papers that aren’t yet public, so there’s no risk of contamination. - The authors pose open-ended research questions without giving away answers. The agent must produce a NeurIPS-quality paper and a reproducible codebase, which the authors of the papers then review. - We built a general-purpose scaffold on OpenClaw and Opus 4.8. (We would have loved to use Fable 5, but given the filters on AI R&D capabilities, we don't want to confound results.) - Agents get generous resource budgets set in consultation with the original authors, such as access to VMs, GPUs, and any other compute needed to answer the question. They also have $3,000 in API credits per paper. We evaluate them on week-long time horizons to make progress on answering the research question, far more than typical agent evals. - The agent needs to manage its own budget. It can track its spend and stay within its limits, and it can modify its scaffold and reasoning effort as it sees fit. - In addition to the final artifacts, such as the paper's code, we are also evaluating the agent's trajectories in depth. When we announced CRUX, we planned to conduct an open-world eval every month. Given the scope and ambition of this project, we have spent a lot more time making sure we are confident in our setup and results. That said, the early results we have are exciting, and we look forward to sharing them soon.
Open weights just caught up to the frontier. GLM-5.2 from @Zai_org tops the open-model rankings on @ArtificialAnlys and @arena's Agent Arena. It's now live on CoreWeave Serverless Inference at $1.39 in and $4.40 out per 1M tokens. Ship more for less. https://t.co/SuB7bV67iG
“Agentic kernel optimization is the future of on-device inference” @xenovacom used Fable 5 to write kernels that pushed Gemma 4 to a massive 255 tok/s on WebGPU with M4. He shared the demo, so you can try in your browser!! https://t.co/xPuh5OLGEt
With agentic coding, complexity compounds in a mechanical way: unnecessary code ends up in the codebase, moves to the context window, degrades the model's reasoning abilities, leads to more unnecessary code (often to fix issues arising from the unnecessary code). It's exponential
you can now train @liquidai's LFM2-VL in TRL GRPO and RLOO included, with an example script https://t.co/H65pK20Q7H
So much alpha in tuning/building LLM verifiers and judges. I use them on top of my harness, and it has unlocked agentic coding workflows that are beyond anything that exists in the market today. Building verifiers and LLM judges is starting to become a skill in high demand.
Bridgewater used their unique financial knowledge and partnered with us on @tinkerapi to fine-tune a model that helps their analysts focus on what's important. Experts improving AI that empowers experts. https://t.co/6RJITMG2BJ
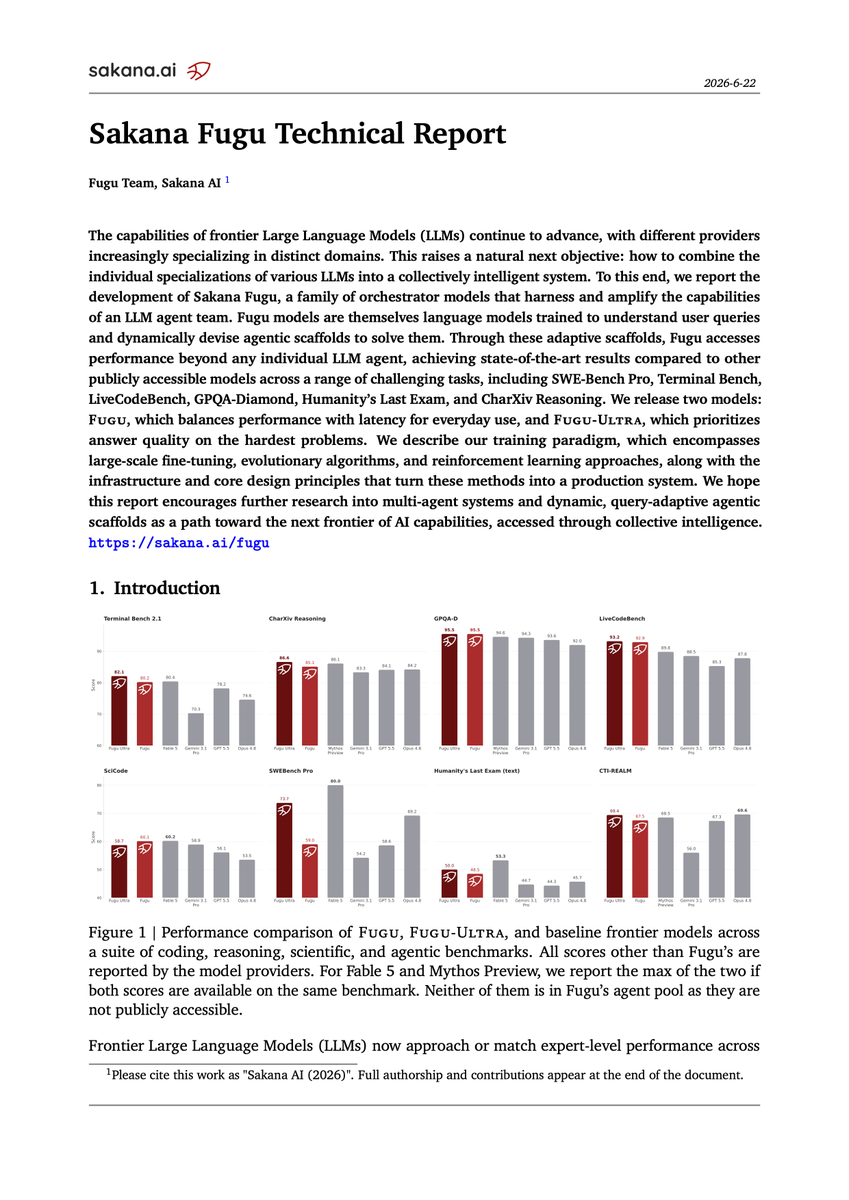
Sakana Fugu Technical Report https://t.co/6e6WuA8FVB Release Notes: https://t.co/7xWGpOicFN https://t.co/g2yaZvex35
Oops, SIGReg did it again! Large scale (CC12M->Datacomp-L) vision-language JEPA pretraining beats CLIP and SigLIP objectives! Thanks to SIGReg, our LeVLJEPA has no collapse, no EMA, no stop-gradient, no negatives, no problem! Checkpoints/demo are live: https://t.co/wz6S6tYB6p
@bradmillscan @kstellana @NousResearch No, we do not believe in model routing. Anything that breaks the cache means you're paying 20x more.