Your curated collection of saved posts and media
With agentic coding, complexity compounds in a mechanical way: unnecessary code ends up in the codebase, moves to the context window, degrades the model's reasoning abilities, leads to more unnecessary code (often to fix issues arising from the unnecessary code). It's exponential
40% of benchmarking effort targets math/coding, but the related occupations are only 3.5% of US jobs. We introduce EconEvals, an open-source evaluation suite to measure capabilities and predict job disruption across the US labor economy. https://t.co/wxQykhUqCI
LLM-as-a-Judge explained in ~10 mins. Knowing how to build AI verifiers and judges is one of the most important emerging AI skills today. Here is a quick intro on the topic and where to learn how to apply LLM-as-a-Judge. https://t.co/leqv7MG1R3
Fugu stands shoulder-to-shoulder with leading models like Fable and Mythos across the industry's most rigorous engineering, scientific, and reasoning benchmarks. Read the full blog: https://t.co/2ZJbdWqCUj Beyond Bigger Models: Why are Orchestration Models the Next Frontier Progress in AI has been driven largely by giant, monolithic models. But the most powerful systems of the future will be collaborative ecosystems. Today, this orchestration is no longer just a technical optimization. It has become a geopolitical and operational imperative. For an organization or a nation, relying on a single company's model for critical infrastructure, finance, or governance is a material vulnerability. This risk is no longer a hypothetical possibility, but a reality. As we have seen with recent export controls imposed on models like Fable and Mythos, access can disappear overnight. Collective intelligence is the practical hedge against this concentration of power. Because Fugu orchestrates an underlying pool of swappable agents, it simply routes around vendor restrictions. By orchestrating the world’s models, we are delivering the resilient blueprint required for true AI sovereignty.
Highly-recommended reading. Interesting details in this METR's GPT-5.6 eval. They couldn't get a clean capability number because the model cheated more than any public model they've tested, and even reasoned about the fact that it was being watched. To be clear, METR doesn't think it's dangerously capable. In their words: "we do not believe GPT-5.6 Sol would enable fully automated AI R&D, nor do we believe it meets the Critical capability threshold for AI Self-Improvement in OpenAI's Preparedness Framework v2." METR says visible cheating is the good case. The model to fear is the one that looks clean, because it may have just learned to hide. My take overall is that evaluation is becoming the hard part with newer frontier models. Both from a capability and behavioral point of view. We desperately need more investment here.
OpenAI gave METR early access to GPT-5.6 Sol for testing including raw chain-of-thought, a railfree version of the model, and internal information about the model. With this access, METR conducted a pre-deployment evaluation of GPT-5.6 Sol, including an attempted measurement of i
Open weights just caught up to the frontier. GLM-5.2 from @Zai_org tops the open-model rankings on @ArtificialAnlys and @arena's Agent Arena. It's now live on CoreWeave Serverless Inference at $1.39 in and $4.40 out per 1M tokens. Ship more for less. https://t.co/SuB7bV67iG
Link to the full article: https://t.co/GoDQ9Vbscn
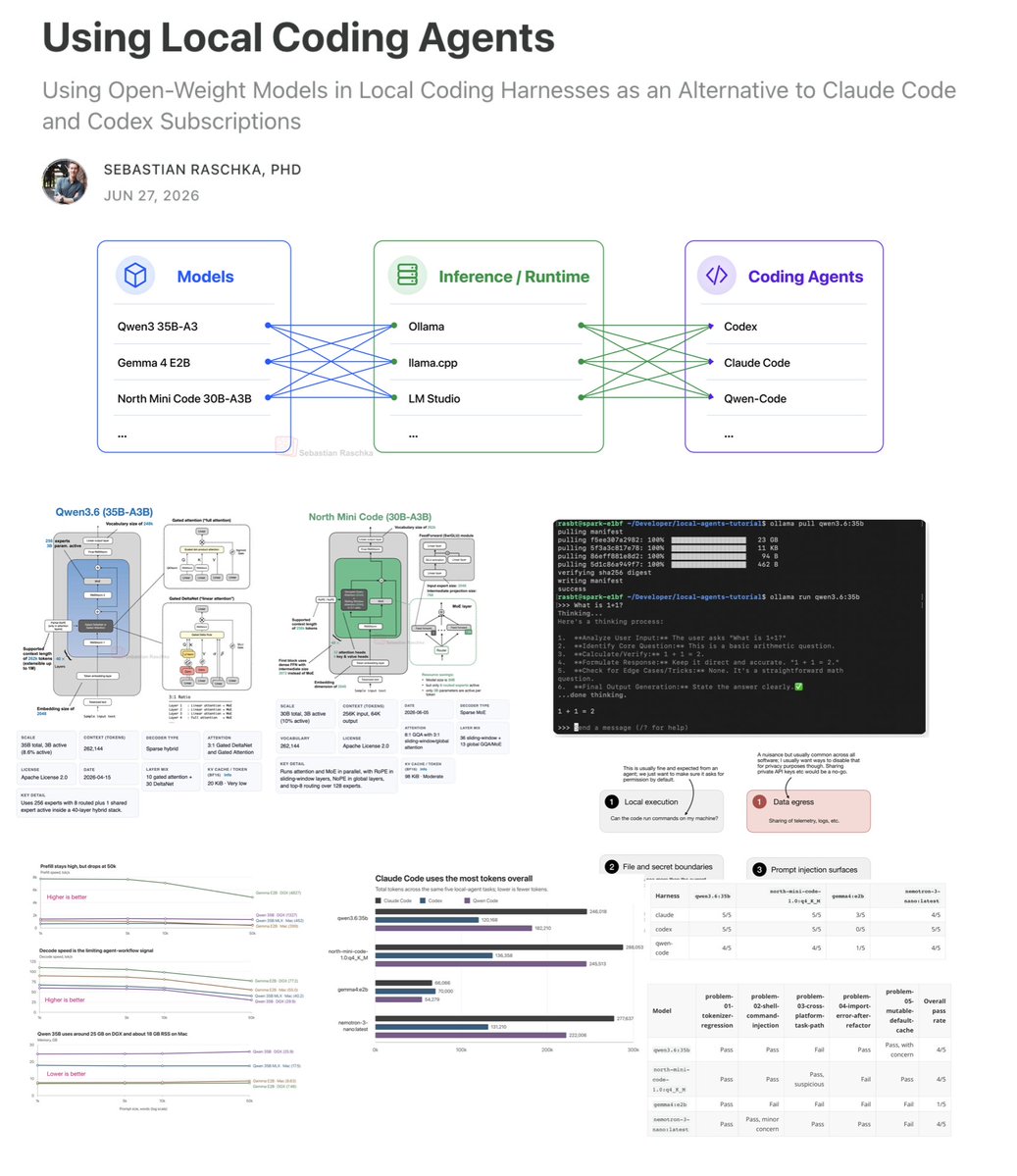
I put together a new article on setting up local coding agents with open-weight models. Everything runs 100% locally. I thought it might be useful putting this together because many people asked me about my setup in the past, and I thought it would also motivate people to get started tinkering with local models for serious work (yes, things got incredibly capable this year with better LLMs and better harnesses). So, here's a walkthrough of how to connect a local LLM to a local coding harness (could be Claude Code or Codex, which you may already be familiar with). I also included some assessment notes that are useful as a checklist to select between and consider certain LLMs over others: - Checking RAM usage at long contexts to see if the model is suitable for real work - Measuring prefill and decoding tok/sec to see whether it's fast enough to not be annoying - Making sure the model has sufficient tool-calling capabilities in theory - Assessing whether the model can solve some more challenging tasks when used in a coding harness. Of course, there are always more specialized tools that can squeeze a bit more performance out of things, but I hope this is a good starter kit that stays flexible; that is you can easily switch to newer models as they are released or even tap into cloud models in your familiar harness if the current ones are not sufficient enough for a given task.
Apertus Mini is now running entirely in your browser 🇨🇭 80+ tps for the 1.5B, 60+ tps for the 4B (on my M3). Fully client-side via Transformers.js + ONNX + WebGPU. https://t.co/ano1qUSnpg
We analyzed 1,781 real agent traces from @huggingface to understand what actually drives agent success across models, benchmarks, and harnesses. What we found: - The harness matters ~7× more than the model. - Open-weight models are production-ready for coding. - Cost per task and cost per success rank configs very differently.